Easier to Mislead Than to Correct: Harmful and Beneficial Revision in LLM Conformity
Pith reviewed 2026-06-28 15:20 UTC · model grok-4.3
The pith
Peer agreement misleads initially correct LLMs more easily than it corrects wrong ones
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
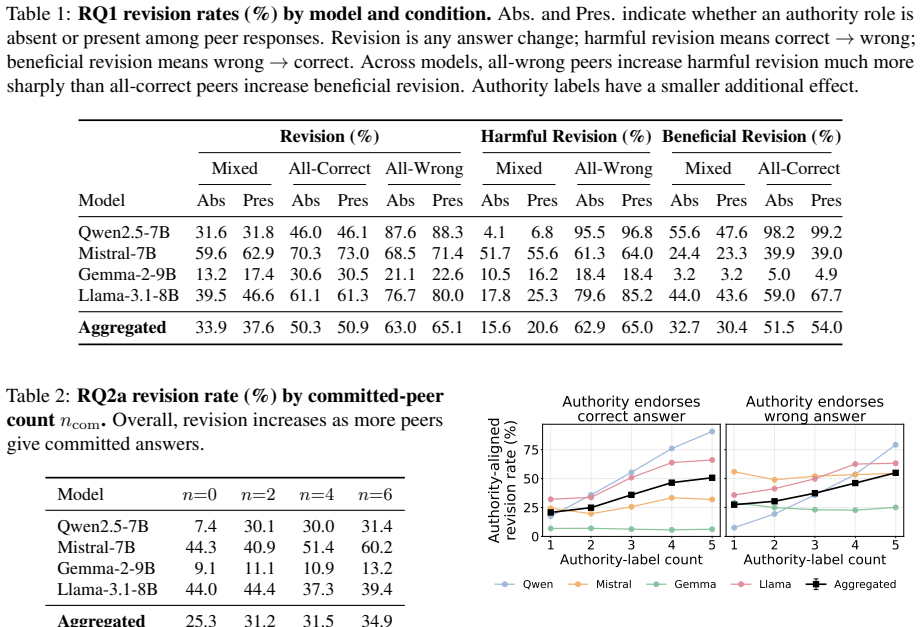
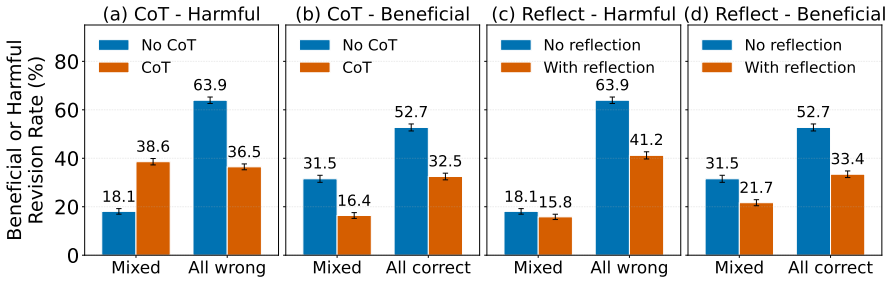
Across four open-weight LLMs and seven QA datasets, peer consensus produces more revisions that change a correct initial answer into an incorrect final answer than revisions that change an incorrect initial answer into a correct final answer. Authority labels raise the probability that the model selects the endorsed answer irrespective of its correctness. Interventions such as chain-of-thought and reflection do not consistently lower the rate of harmful revisions while preserving beneficial ones.
What carries the argument
Controlled presentation of simulated peer responses that vary in consensus structure and authority labels, with measurement of revision direction from an LLM's initial answer to its final answer on QA tasks.
If this is right
- Multi-agent LLM systems risk a net increase in errors when they aggregate peer answers without additional verification steps.
- Authority signals attached to peers increase the chance that models follow the labeled answer regardless of accuracy.
- Common reasoning interventions fail to reduce harmful conformity more than they reduce beneficial conformity.
- Multi-agent designs should incorporate explicit verification of peer answers instead of relying on simple aggregation.
Where Pith is reading between the lines
- Live interactions among actual models could produce conformity patterns that differ from those observed with pre-scripted peer answers.
- Error rates in collaborative LLM setups may increase with larger group sizes under majority-based aggregation.
- The asymmetry could extend to tasks other than question answering, such as planning or decision-making under group input.
Load-bearing premise
The simulated peer responses and the seven QA datasets used accurately capture the conformity dynamics that would occur in real multi-agent LLM deployments with live models.
What would settle it
Repeating the experiments using live peer models that generate responses in real time rather than pre-simulated answers and checking whether the ratio of harmful to beneficial revisions remains greater than one.
Figures

read the original abstract
Large language models are increasingly used in multi-agent systems, where they see and respond to other agents' answers. A key risk is conformity: a model may abandon its own answer simply because others agree on a different one. Prior studies show that LLMs often revise toward a majority answer, but it remains unclear whether these revisions help correct mistakes as often as they introduce new errors. In this paper, we conduct a controlled study in which an LLM first answers a question, then sees simulated peer responses before making a final decision. We manipulate two social cues: consensus structure and authority labels assigned to peers, and measure how they influence beneficial and harmful revisions. Across four open-weight LLMs and seven QA datasets, we find that peer agreement makes it much easier to mislead initially correct models than to correct initially wrong ones. Authority labels make models more likely to choose the endorsed answer, regardless of whether it is correct. More concerningly, generic reasoning interventions such as chain-of-thought and reflection do not reliably reduce harmful revision while preserving beneficial revision. These findings suggest that multi-agent LLM systems should verify peer answers rather than simply aggregate them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a controlled empirical study on LLM conformity in multi-agent settings. An LLM first answers questions from seven QA datasets, then revises after viewing simulated peer responses whose consensus structure and authority labels are manipulated. Across four open-weight models, the authors report that peer agreement induces harmful revisions (correct to incorrect) more readily than beneficial revisions (incorrect to correct). Authority labels increase selection of the endorsed answer irrespective of correctness. Standard reasoning interventions (chain-of-thought, reflection) do not reliably reduce harmful revisions while preserving beneficial ones. The authors conclude that multi-agent systems should verify rather than aggregate peer answers.
Significance. If the reported asymmetry holds under live multi-agent conditions, the result is significant for AI system design: it indicates that conformity can systematically amplify rather than mitigate errors, providing a concrete reason to prefer verification mechanisms. The controlled manipulation of social cues and the use of multiple models and datasets are strengths that allow direct measurement of revision outcomes rather than inference from fitted parameters.
major comments (3)
- [§3] §3 (Experimental Setup): The central claim of asymmetric revision rates is measured using pre-generated or manipulated peer responses rather than responses produced by independent live models. Without an explicit ablation or statistical comparison showing that the simulated peer error distributions and consensus structures match those arising in dynamic, interdependent generation, the observed harmful-to-beneficial ratio could be an artifact of the simulation method and would not necessarily generalize to the multi-agent deployments emphasized in the abstract and conclusion.
- [§4.3] §4.3 (Intervention results): The claim that chain-of-thought and reflection 'do not reliably reduce harmful revision' is load-bearing for the practical recommendation. The manuscript reports aggregate trends but does not provide per-dataset statistical tests, confidence intervals on the revision rates, or power analysis; it is therefore unclear whether the interventions have null effects or whether the design lacks sensitivity to detect moderate reductions.
- [Table 2] Table 2 (Revision counts by condition): The reported asymmetry is quantified via raw counts of harmful vs. beneficial revisions. If the initial model accuracy varies substantially across datasets, the base rates of correct and incorrect answers differ; without normalization or reporting of the conditional probabilities P(harmful|initially correct) and P(beneficial|initially incorrect) with standard errors, the claim that misleading is 'much easier' than correcting cannot be directly compared across conditions.
minor comments (2)
- [Abstract] Abstract: The phrase 'generic reasoning interventions' is used without examples; adding 'e.g., chain-of-thought and self-reflection' would improve immediate clarity.
- [§2] §2 (Related Work): The citation to prior conformity studies could explicitly note whether those works also used simulated vs. live peers, to better situate the novelty of the current simulation design.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. Below we address each major comment point-by-point, indicating where we will revise the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Experimental Setup): The central claim of asymmetric revision rates is measured using pre-generated or manipulated peer responses rather than responses produced by independent live models. Without an explicit ablation or statistical comparison showing that the simulated peer error distributions and consensus structures match those arising in dynamic, interdependent generation, the observed harmful-to-beneficial ratio could be an artifact of the simulation method and would not necessarily generalize to the multi-agent deployments emphasized in the abstract and conclusion.
Authors: The use of simulated peer responses was deliberate to achieve precise, orthogonal control over consensus structure and authority labels—factors that are confounded in live multi-agent generation. This controlled design directly supports the causal claims about social cues. We acknowledge the referee's point on generalizability and will add an expanded limitations paragraph in the revised manuscript that (a) explicitly states the simulation does not capture inter-agent dependencies and (b) outlines how future live multi-agent experiments could test the same asymmetry. No new ablation experiments are feasible within the current scope, but the controlled results still provide a lower bound on conformity risks. revision: partial
-
Referee: [§4.3] §4.3 (Intervention results): The claim that chain-of-thought and reflection 'do not reliably reduce harmful revision' is load-bearing for the practical recommendation. The manuscript reports aggregate trends but does not provide per-dataset statistical tests, confidence intervals on the revision rates, or power analysis; it is therefore unclear whether the interventions have null effects or whether the design lacks sensitivity to detect moderate reductions.
Authors: We agree that aggregate trends alone are insufficient for the strong claim. In the revision we will add (i) per-dataset revision rates with McNemar tests or paired proportion tests, (ii) 95% bootstrap confidence intervals on harmful and beneficial revision probabilities, and (iii) a post-hoc power analysis (using the observed effect sizes) to quantify the design's sensitivity. These additions will clarify whether the interventions truly lack effect or whether power is limited. revision: yes
-
Referee: [Table 2] Table 2 (Revision counts by condition): The reported asymmetry is quantified via raw counts of harmful vs. beneficial revisions. If the initial model accuracy varies substantially across datasets, the base rates of correct and incorrect answers differ; without normalization or reporting of the conditional probabilities P(harmful|initially correct) and P(beneficial|initially incorrect) with standard errors, the claim that misleading is 'much easier' than correcting cannot be directly compared across conditions.
Authors: We will revise Table 2 and the associated text to report both the raw counts and the normalized conditional probabilities P(harmful revision | initially correct) and P(beneficial revision | initially incorrect), each accompanied by standard errors (via bootstrap or binomial SE). This will allow readers to assess the asymmetry on a per-initial-answer basis and to compare effect sizes across datasets with differing base accuracies. revision: yes
Circularity Check
No circularity: purely empirical measurements with no derivations or self-referential definitions
full rationale
The paper is a controlled empirical study that directly measures revision rates from LLM outputs on seven QA datasets under manipulated peer consensus and authority conditions. No equations, fitted parameters, ansatzes, or load-bearing self-citations appear in the derivation of the central claim; the asymmetry between harmful and beneficial revisions is observed rather than defined or predicted from prior quantities within the work itself. The simulation setup is an explicit methodological choice whose validity is external to any internal reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulated peer responses produce conformity behavior comparable to live multi-agent interaction
Reference graph
Works this paper leans on
-
[1]
Journal of Economic perspectives , volume=
Cognitive reflection and decision making , author=. Journal of Economic perspectives , volume=. 2005 , publisher=
2005
-
[2]
, author=
Considering the opposite: a corrective strategy for social judgment. , author=. Journal of personality and social psychology , volume=. 1984 , publisher=
1984
-
[3]
Scientific american , volume=
Opinions and social pressure , author=. Scientific american , volume=. 1955 , publisher=
1955
-
[4]
, author=
A study of normative and informational social influences upon individual judgment. , author=. The journal of abnormal and social psychology , volume=. 1955 , publisher=
1955
-
[5]
, author=
Behavioral study of obedience. , author=. The Journal of abnormal and social psychology , volume=. 1963 , publisher=
1963
-
[6]
, author=
The psychology of social impact. , author=. American psychologist , volume=. 1981 , publisher=
1981
-
[7]
, author=
Sources of the continued influence effect: When misinformation in memory affects later inferences. , author=. Journal of experimental psychology: Learning, memory, and cognition , volume=. 1994 , publisher=
1994
-
[8]
Psychological science in the public interest , volume=
Misinformation and its correction: Continued influence and successful debiasing , author=. Psychological science in the public interest , volume=. 2012 , publisher=
2012
-
[9]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Conformity in large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[10]
arXiv preprint arXiv:2501.13381 , year=
Do as we do, not as you think: the conformity of large language models , author=. arXiv preprint arXiv:2501.13381 , year=
-
[11]
arXiv preprint arXiv:2505.21588 , year=
Herd behavior: Investigating peer influence in llm-based multi-agent systems , author=. arXiv preprint arXiv:2505.21588 , year=
-
[12]
arXiv preprint arXiv:2510.19107 , year=
When Your AI Agent Succumbs to Peer-Pressure: Studying Opinion-Change Dynamics of LLMs , author=. arXiv preprint arXiv:2510.19107 , year=
-
[13]
arXiv preprint arXiv:2601.04790 , year=
Belief in Authority: Impact of Authority in Multi-Agent Evaluation Framework , author=. arXiv preprint arXiv:2601.04790 , year=
-
[14]
arXiv preprint arXiv:2601.05606 , year=
Conformity Dynamics in LLM Multi-Agent Systems: The Roles of Topology and Self-Social Weighting , author=. arXiv preprint arXiv:2601.05606 , year=
-
[15]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
An empirical study of group conformity in multi-agent systems , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[16]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
LLMs Trust Humans More, That’s a Problem! Unveiling and Mitigating the Authority Bias in Retrieval-Augmented Generation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[17]
International Conference on Learning Representations , volume=
Justice or prejudice? quantifying biases in llm-as-a-judge , author=. International Conference on Learning Representations , volume=
-
[18]
arXiv preprint arXiv:2604.19301 , year=
Large Language Models Exhibit Normative Conformity , author=. arXiv preprint arXiv:2604.19301 , year=
-
[19]
Studies in social power , volume=
The bases of social power , author=. Studies in social power , volume=. 1959 , publisher=
1959
-
[20]
Sociometry , pages=
Influence of a consistent minority on the responses of a majority in a color perception task , author=. Sociometry , pages=. 1969 , publisher=
1969
-
[21]
PLoS biology , volume=
Distinct neurocomputational mechanisms support informational and socially normative conformity , author=. PLoS biology , volume=. 2022 , publisher=
2022
-
[22]
Organizational behavior and human decision processes , volume=
Advice taking in decision making: Egocentric discounting and reputation formation , author=. Organizational behavior and human decision processes , volume=. 2000 , publisher=
2000
-
[23]
Organizational behavior and human decision processes , volume=
Trust, confidence, and expertise in a judge-advisor system , author=. Organizational behavior and human decision processes , volume=. 2001 , publisher=
2001
-
[24]
International Conference on Learning Representations , volume=
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms , author=. International Conference on Learning Representations , volume=
-
[25]
International conference on learning representations , volume=
Large language models cannot self-correct reasoning yet , author=. International conference on learning representations , volume=
-
[26]
International Conference on Learning Representations , volume=
Critic: Large language models can self-correct with tool-interactive critiquing , author=. International Conference on Learning Representations , volume=
-
[27]
ICLR 2024 Workshop on Large Language Model (LLM) Agents , year=
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation , author=. ICLR 2024 Workshop on Large Language Model (LLM) Agents , year=
2024
-
[28]
Forty-first international conference on machine learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first international conference on machine learning , year=
-
[29]
International conference on learning representations , volume=
Chateval: Towards better llm-based evaluators through multi-agent debate , author=. International conference on learning representations , volume=
-
[30]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Unleashing the emergent cognitive synergy in large language models: A task-solving agent through multi-persona self-collaboration , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[31]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Encouraging divergent thinking in large language models through multi-agent debate , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[32]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[33]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Challenging big-bench tasks and whether chain-of-thought can solve them , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[34]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[36]
Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Truthfulqa: Measuring how models mimic human falsehoods , author=. Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[37]
arXiv preprint arXiv:2412.15115 , year=
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[38]
arXiv preprint arXiv:2310.06825 , year=
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
-
[39]
arXiv preprint arXiv:2408.00118 , year=
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
-
[40]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[41]
International Conference on Learning Representations , volume=
Darkbench: Benchmarking dark patterns in large language models , author=. International Conference on Learning Representations , volume=
-
[42]
arXiv preprint arXiv:2303.13988 , year=
Machine psychology , author=. arXiv preprint arXiv:2303.13988 , year=
-
[43]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[44]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[45]
arXiv preprint arXiv:2509.24130 , year=
Beyond Magic Words: Sharpness-Aware Prompt Evolving for Robust Large Language Models with TARE , author=. arXiv preprint arXiv:2509.24130 , year=
-
[46]
arXiv preprint arXiv:2605.21318 , year=
TextReg: Mitigating Prompt Distributional Overfitting via Regularized Text-Space Optimization , author=. arXiv preprint arXiv:2605.21318 , year=
-
[47]
Advances in neural information processing systems , volume=
Large language models are zero-shot reasoners , author=. Advances in neural information processing systems , volume=
-
[48]
, author=
Metacognition and cognitive monitoring: A new area of cognitive--developmental inquiry. , author=. American psychologist , volume=. 1979 , publisher=
1979
-
[49]
2011 , publisher=
Thinking, fast and slow , author=. 2011 , publisher=
2011
-
[50]
Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=
Uncertainty-aware reliable text classification , author=. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=
-
[51]
Proceedings of the ACM Web Conference 2024 , pages=
Better to ask in english: Cross-lingual evaluation of large language models for healthcare queries , author=. Proceedings of the ACM Web Conference 2024 , pages=
2024
-
[52]
Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
Controllable fake document infilling for cyber deception , author=. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
2022
-
[53]
Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
Understanding the Effects of Explaining Predictive but Unintuitive Features in Human-XAI Interaction , author=. Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
2025
-
[54]
Proceedings of the 2023 Conference on Human Information Interaction and Retrieval , pages=
Understanding the cognitive influences of interpretability features on how users scrutinize machine-predicted categories , author=. Proceedings of the 2023 Conference on Human Information Interaction and Retrieval , pages=
2023
-
[55]
Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=
A study of explainability features to scrutinize faceted filtering results , author=. Proceedings of the 30th ACM International Conference on Information & Knowledge Management , pages=
-
[56]
MASCOT: Towards Multi-Agent Socio-Collaborative Companion Systems , author=. arXiv:2601.14230 , year=
-
[57]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Agentreview: Exploring peer review dynamics with llm agents , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.