Acoustic Modeling for Automatic Lyrics-to-Audio Alignment
Pith reviewed 2026-05-25 16:21 UTC · model grok-4.3
The pith
Adapting solo-singing acoustic models with extra voicing and auditory features plus small polyphonic data cuts word-boundary alignment errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Incorporating voicing and auditory features together with conventional acoustic features brings robustness against increased spectro-temporal variations in singing vocals; adapting the acoustic model using a small amount of polyphonic audio data reduces the domain mismatch between training and testing data; the combined strategy yields a significant reduction in word-boundary alignment error over comparable existing systems, especially on challenging polyphonic data with long-duration musical interludes.
What carries the argument
Acoustic-model adaptation from large solo-singing corpora to polyphonic audio using limited in-domain data, augmented by speech- and music-informed features such as voicing and auditory descriptors.
If this is right
- Alignment systems become usable on real-world polyphonic recordings without requiring large annotated polyphonic corpora.
- Error rates drop most on segments containing extended instrumental passages.
- The same adaptation recipe can be applied to other singing-related tasks that suffer from domain shift between solo and accompanied audio.
- Word-boundary precision improves enough to support downstream applications that rely on accurate timing.
Where Pith is reading between the lines
- The approach could be tested on other music genres or languages to check whether the adaptation gain generalizes beyond the evaluated data.
- If the small-data adaptation works reliably, similar transfer methods might reduce labeling costs for related audio tasks such as singing transcription.
- Systems built this way could feed more accurate timing into music-search or karaoke tools that currently struggle with accompanied vocals.
Load-bearing premise
A small amount of in-domain polyphonic audio data suffices to adapt solo-singing models without introducing overfitting.
What would settle it
A controlled test in which the same small polyphonic adaptation set produces no error reduction or an increase in word-boundary error on held-out polyphonic tracks.
Figures
read the original abstract
Automatic lyrics to polyphonic audio alignment is a challenging task not only because the vocals are corrupted by background music, but also there is a lack of annotated polyphonic corpus for effective acoustic modeling. In this work, we propose (1) using additional speech and music-informed features and (2) adapting the acoustic models trained on a large amount of solo singing vocals towards polyphonic music using a small amount of in-domain data. Incorporating additional information such as voicing and auditory features together with conventional acoustic features aims to bring robustness against the increased spectro-temporal variations in singing vocals. By adapting the acoustic model using a small amount of polyphonic audio data, we reduce the domain mismatch between training and testing data. We perform several alignment experiments and present an in-depth alignment error analysis on acoustic features, and model adaptation techniques. The results demonstrate that the proposed strategy provides a significant error reduction of word boundary alignment over comparable existing systems, especially on more challenging polyphonic data with long-duration musical interludes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that automatic lyrics-to-polyphonic audio alignment can be improved by (1) augmenting conventional acoustic features with speech- and music-informed features such as voicing and auditory features to increase robustness to spectro-temporal variation, and (2) adapting acoustic models pretrained on large solo-singing corpora to the polyphonic domain using only a small amount of in-domain polyphonic data. Experiments and error analysis are said to demonstrate significant reductions in word-boundary alignment error relative to existing systems, with the largest gains on challenging polyphonic excerpts containing long musical interludes.
Significance. If the adaptation procedure can be shown to succeed without overfitting, the work would offer a practical route to mitigating the domain mismatch between solo-singing training data and polyphonic test conditions without requiring large annotated polyphonic corpora, which is a recognized bottleneck in the field.
major comments (2)
- [Methods / Adaptation procedure] The central claim rests on successful domain adaptation with a small in-domain polyphonic set, yet the manuscript supplies neither the exact duration or number of polyphonic clips used for adaptation, the adaptation algorithm (full fine-tuning, layer-wise, MAP, etc.), nor any description of held-out validation, early stopping, or regularization. Without these controls it is impossible to rule out that observed gains arise from memorization rather than improved robustness to background music.
- [Abstract and Results] The abstract asserts that 'experiments demonstrate error reduction' and that the proposed strategy yields 'significant error reduction … especially on more challenging polyphonic data,' but reports no numerical error rates, baseline comparisons, dataset sizes, or statistical tests. The absence of these quantities prevents assessment of whether the reported gains are load-bearing or merely suggestive.
minor comments (1)
- [Abstract] The abstract would be strengthened by the inclusion of at least one key quantitative result (e.g., absolute or relative word-boundary error reduction) to substantiate the headline claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Methods / Adaptation procedure] The central claim rests on successful domain adaptation with a small in-domain polyphonic set, yet the manuscript supplies neither the exact duration or number of polyphonic clips used for adaptation, the adaptation algorithm (full fine-tuning, layer-wise, MAP, etc.), nor any description of held-out validation, early stopping, or regularization. Without these controls it is impossible to rule out that observed gains arise from memorization rather than improved robustness to background music.
Authors: We agree that the manuscript would benefit from greater specificity on the adaptation procedure. In the revised version we will report the exact duration and number of polyphonic clips used for adaptation, the precise adaptation algorithm (including whether full fine-tuning or another method was applied), and any held-out validation, early-stopping, or regularization steps that were performed. These additions will allow readers to evaluate the risk of overfitting more rigorously. revision: yes
-
Referee: [Abstract and Results] The abstract asserts that 'experiments demonstrate error reduction' and that the proposed strategy yields 'significant error reduction … especially on more challenging polyphonic data,' but reports no numerical error rates, baseline comparisons, dataset sizes, or statistical tests. The absence of these quantities prevents assessment of whether the reported gains are load-bearing or merely suggestive.
Authors: The Experiments section already contains the numerical error rates, baseline comparisons, dataset sizes, and statistical tests. To improve accessibility we will revise the abstract to include the key quantitative results and an explicit reference to the statistical significance of the observed improvements. revision: yes
Circularity Check
No circularity; empirical adaptation results are externally grounded
full rationale
The paper describes a standard pipeline of incorporating additional speech/music features and adapting solo-singing acoustic models on a small polyphonic corpus, then reports measured word-boundary error reductions on held-out test data. No equations, uniqueness theorems, or self-citations are invoked to derive the performance gains; the gains are presented as outcomes of experiments whose validity rests on external acoustic-modeling literature and reproducible evaluation protocols rather than any definitional or fitted-input reduction internal to the paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Additional voicing and auditory features increase robustness against spectro-temporal variations in polyphonic singing vocals.
- domain assumption Acoustic models trained on solo singing can be effectively adapted to polyphonic conditions with only a small amount of in-domain data.
Reference graph
Works this paper leans on
-
[1]
Acoustic Modeling for Automatic Lyrics-to-Audio Alignment
Introduction The goal of an automatic lyrics-to-audio alignment algorithm is the time synchronization between the lyrics and the singing vocals with or without background music. It potentially enables various applications such as generating karaoke scrolling lyrics, music video subtitling, and music retrieval. The task of lyrics-to-audio alignment is ofte...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Speech and music-informed features Speech and singing have many similarities because they share the underlying physiological mechanisms for production, such as articulatory movements in vocal production [14, 15]. Mod- ern ASR systems use conventional acoustic features such as mel-scaled cepstral coefficients (MFCC) to capture the pho- netic aspects in conj...
-
[3]
Model adaptation for domain mismatch Our goal is to build a framework to automatically align lyrics to the polyphonic music audio. With an acoustic model trained on solo-singing data, we can adapt the model towards the test data in two ways: (a) by making the test data closer to the trained solo-singing acoustic models by applying vocal separation on poly...
-
[4]
was introduced, that consists of 5,000+ polyphonic songs with note annotations and weak word-level, line-level, and paragraph-level lyrics annotations. It was created with a set of initial manual annotations of time-aligned lyrics made by non- expert users of Karaoke games, where the audio was not avail- able. The corresponding audio candidates were then ...
-
[5]
Experimental setup We conduct two sets of experiments to study the impact of our proposed acoustic modeling strategies for lyrics alignment: (1) we first assess the effect of the speech and music informed fea- tures on lyrics alignment in solo-singing, and (2) then we inves- tigate the effects of these features in polyphonic music lyrics alignment, along w...
-
[6]
The training data for solo-singing acoustic modeling is ap- proximately 50 hours of the DAMP dataset [5, 9] that has weak line-level lyrics transcription. We use the DALI ground-truth data for domain adaptation of the acoustic models to the poly- Table 2: Dataset description. (solo: solo-singing; poly: singing mixed with music) Name Audio type Content Lyr...
work page 2017
-
[7]
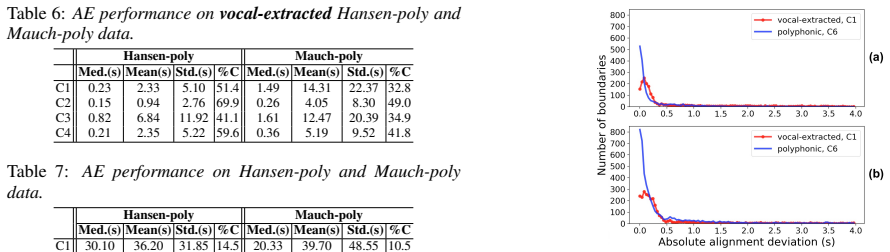
Results and discussion 5.1. Performance on solo-singing In the first set of experiments, we explore the effect of each of the speech and music informed feature groups combined with MFCCs and i-vectors. The alignment results provided by differ- ent feature configurations on the Hansen’s solo-singing dataset is shown in Table 4. Training the solo-singing acou...
-
[8]
Conclusions In this study, we discuss two strategies to obtain improved acoustic modeling for the task of lyrics-to-audio alignment. Par- ticularly, we propose to (1) employ additional features with speech- and music-related information together with conven- tional MFCCs, and (2) adapt solo-singing acoustic model using small amount of in-domain polyphonic...
-
[9]
Acknowledgments This research is supported by Ministry of Education, Singapore AcRF Tier 1 NUS Start-up Grant FY2016, Non-parametric ap- proach to voice morphing
-
[10]
Lyricsynchro- nizer: Automatic synchronization system between musical audio signals and lyrics,
H. Fujihara, M. Goto, J. Ogata, and H. G. Okuno, “Lyricsynchro- nizer: Automatic synchronization system between musical audio signals and lyrics,”IEEE Journal of Selected Topics in Signal Pro- cessing, vol. 5, no. 6, pp. 1252–1261, 2011
work page 2011
-
[11]
Integrating additional chord information into HMM-based lyrics-to-audio alignment,
M. Mauch, H. Fujihara, and M. Goto, “Integrating additional chord information into HMM-based lyrics-to-audio alignment,” IEEE Transactions on Audio, Speech and Language Processing , vol. 20, no. 1, pp. 200–210, 2012
work page 2012
-
[12]
Leveraging repetition for improved automatic lyric transcription in popular music,
M. McVicar, D. P. Ellis, and M. Goto, “Leveraging repetition for improved automatic lyric transcription in popular music,” inProc. ICASSP, 2014, pp. 3117–3121
work page 2014
-
[13]
Automatic recognition of lyrics in singing,
A. Mesaros and T. Virtanen, “Automatic recognition of lyrics in singing,” EURASIP Journal on Audio, Speech, and Music Pro- cessing, vol. 2010, p. 4, 2010
work page 2010
-
[14]
Semi-supervised lyrics and solo-singing alignment,
C. Gupta, R. Tong, H. Li, and Y . Wang, “Semi-supervised lyrics and solo-singing alignment,” in Proc. ISMIR, 2018
work page 2018
-
[15]
V ocal detection in music with support vector machines,
M. Ramona, G. Richard, and B. David, “V ocal detection in music with support vector machines,” in 2008 Proc. ICASSP . IEEE, 2008, pp. 1885–1888
work page 2008
-
[16]
Bootstrapping a system for phoneme recognition and keyword spotting in unaccompanied singing,
A. M. Kruspe, “Bootstrapping a system for phoneme recognition and keyword spotting in unaccompanied singing,” inProc. ISMIR, 2016, pp. 358–364
work page 2016
-
[17]
Modeling of phoneme dura- tions for alignment between polyphonic audio and lyrics,
G. B. Dzhambazov and X. Serra, “Modeling of phoneme dura- tions for alignment between polyphonic audio and lyrics,” in12th Sound and Music Computing Conference, 2015, pp. 281–286
work page 2015
-
[18]
Smule.digital archive mobile performances(damp),
S. Sing!, “Smule.digital archive mobile performances(damp),” https://ccrma.stanford.edu/damp/, 2010 (accessed March 15, 2018)
work page 2010
-
[19]
Automatic pronunciation evalua- tion of singing,
C. Gupta, H. Li, and Y . Wang, “Automatic pronunciation evalua- tion of singing,” Proc. INTERSPEECH, pp. 1507–1511, 2018
work page 2018
-
[20]
Automatic lyrics- to-audio alignment on polyphonic music using singing-adapted acoustic models,
B. Sharma, C. Gupta, H. Li, and Y . Wang, “Automatic lyrics- to-audio alignment on polyphonic music using singing-adapted acoustic models,” in Proc. ICASSP. IEEE, 2019
work page 2019
-
[21]
Mirex2018: Lyrics-to-audio alignment for instru- ment accompanied singings,
C.-C. Wang, “Mirex2018: Lyrics-to-audio alignment for instru- ment accompanied singings,” in MIREX 2018, 2018
work page 2018
-
[22]
End-to-end lyrics align- ment for polyphonic music using an audio-to-character recogni- tion model,
S. E. Daniel Stoller, Simon Durand, “End-to-end lyrics align- ment for polyphonic music using an audio-to-character recogni- tion model,” in Proc. ICASSP. IEEE, 2019
work page 2019
-
[23]
Musical melody and speech into- nation: Singing a different tune,
R. J. Zatorre and S. R. Baum, “Musical melody and speech into- nation: Singing a different tune,” PLoS biology, vol. 10, no. 7, p. e1001372, 2012
work page 2012
-
[24]
Study of the similarity between linguistic tones and melodic pitch contours in Beijing opera singing
S. Zhang, R. C. Repetto, and X. Serra, “Study of the similarity between linguistic tones and melodic pitch contours in Beijing opera singing.” in Proc. ISMIR, 2014, pp. 343–348
work page 2014
-
[25]
Front-end factor analysis for speaker verification,
N. Dehak, P. J. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet, “Front-end factor analysis for speaker verification,” IEEE Trans- actions on Audio, Speech, and Language Processing , vol. 19, no. 4, pp. 788–798, May 2011
work page 2011
-
[26]
Musical genre classification of au- dio signals,
G. Tzanetakis and P. Cook, “Musical genre classification of au- dio signals,” IEEE Transactions on Speech and Audio Processing, vol. 10, no. 5, pp. 293–302, 2002
work page 2002
-
[27]
A Hybrid of Deep Audio Feature and i-vector for Artist Recognition
J. Park, D. Kim, J. Lee, S. Kum, and J. Nam, “A hybrid of deep audio feature and i-vector for artist recognition,” arXiv preprint arXiv:1807.09208, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Song-level features and support vector machines for music classification,
M. Mandel and D. Ellis, “Song-level features and support vector machines for music classification,” in Proc. ISMIR, 2005
work page 2005
-
[29]
Lyrics-to-audio alignment and its ap- plication,
H. Fujihara and M. Goto, “Lyrics-to-audio alignment and its ap- plication,” in Dagstuhl Follow-Ups, vol. 3. Schloss Dagstuhl- Leibniz-Zentrum fuer Informatik, 2012
work page 2012
-
[30]
Low-delay singing voice alignment to text
A. Loscos, P. Cano, and J. Bonada, “Low-delay singing voice alignment to text.” in Proc. ICMC, 1999
work page 1999
-
[31]
Opensmile: the Munich versatile and fast open-source audio feature extractor,
F. Eyben, M. W ¨ollmer, and B. Schuller, “Opensmile: the Munich versatile and fast open-source audio feature extractor,” in Proc. ACM Multimedia. ACM, 2010, pp. 1459–1462
work page 2010
-
[32]
B. Schuller, S. Steidl, A. Batliner, A. Vinciarelli, K. Scherer, F. Ringeval, M. Chetouani, F. Weninger, F. Eyben, E. Marchi et al., “The interspeech 2013 computational paralinguistics chal- lenge: social signals, conflict, emotion, autism,” in Proc. INTER- SPEECH, 2013
work page 2013
-
[33]
An information- theoretic approach to machine-oriented music summarization,
F. A. Raposo, D. M. de Matos, and R. Ribeiro, “An information- theoretic approach to machine-oriented music summarization,” Pattern Recognition Letters, 2019
work page 2019
-
[34]
Benchmarking music emotion recognition systems,
A. Alajanki, Y .-H. Yang, and M. Soleymani, “Benchmarking music emotion recognition systems,” PLOS ONE, pp. 835–838, 2016
work page 2016
-
[35]
Seek- ing the superstar: Automatic assessment of perceived singing quality,
J. B ¨ohm, F. Eyben, M. Schmitt, H. Kosch, and B. Schuller, “Seek- ing the superstar: Automatic assessment of perceived singing quality,” in 2017 International Joint Conference on Neural Net- works (IJCNN). IEEE, 2017, pp. 1560–1569
work page 2017
-
[36]
A comparison of features for speech, music discrimination,
M. J. Carey, E. S. Parris, and H. Lloyd-Thomas, “A comparison of features for speech, music discrimination,” in Proc. ICASSP, vol. 1. IEEE, 1999, pp. 149–152
work page 1999
-
[37]
A speech/music discriminator based on RMS and zero-crossings,
C. Panagiotakis and G. Tziritas, “A speech/music discriminator based on RMS and zero-crossings,” IEEE Transactions on Multi- media, vol. 7, no. 1, pp. 155–166, 2005
work page 2005
-
[38]
H. Hermansky and N. Morgan, “Rasta processing of speech,” IEEE Transactions on Speech and Audio Processing, vol. 2, no. 4, pp. 578–589, 1994
work page 1994
-
[39]
Automatic musical genre clas- sification of audio signals,
T. George, E. Georg, and C. Perry, “Automatic musical genre clas- sification of audio signals,” in Proc. ISMIR, 2001
work page 2001
-
[40]
Classifying music audio with timbral and chroma fea- tures,
D. Ellis, “Classifying music audio with timbral and chroma fea- tures,” in Proc. ISMIR, 2007
work page 2007
-
[41]
G. Meseguer-Brocal, A. Cohen-Hadria, and G. Peeters, “Dali: A large dataset of synchronized audio, lyrics and notes, automati- cally created using teacher-student machine learning paradigm,” in Proc. ISMIR, 2018
work page 2018
-
[42]
J. K. Hansen, “Recognition of phonemes in a-cappella recordings using temporal patterns and mel frequency cepstral coefficients,” in 9th Sound and Music Computing Conference (SMC), 2012, pp. 494–499
work page 2012
-
[43]
The Kaldi speech recognition toolkit,
D. Povey, A. Ghoshal, G. Boulianne, L. Burget, O. Glembek, N. Goel, M. Hannemann, P. Motlicek, Y . Qian, P. Schwarzet al., “The Kaldi speech recognition toolkit,” in in Proc. ASRU, 2011
work page 2011
-
[44]
Semi-orthogonal low-rank matrix factoriza- tion for deep neural networks,
D. Povey, G. Cheng, Y . Wang, K. Li, H. Xu, M. Yarmohammadi, and S. Khudanpur, “Semi-orthogonal low-rank matrix factoriza- tion for deep neural networks,” in Proc. INTERSPEECH, 2018, pp. 3743–3747
work page 2018
-
[45]
Audio augmen- tation for speech recognition,
T. Ko, V . Peddinti, D. Povey, and S. Khudanpur, “Audio augmen- tation for speech recognition,” inProc. INTERSPEECH, 2015, pp. 3586–3589
work page 2015
-
[46]
Speaker adap- tation of neural network acoustic models using i-vectors,
G. Saon, H. Soltau, D. Nahamoo, and M. Picheny, “Speaker adap- tation of neural network acoustic models using i-vectors,” inProc. ASRU, Dec 2013, pp. 55–59
work page 2013
-
[47]
Purely sequence-trained neu- ral networks for ASR based on lattice-free MMI,
D. Povey, V . Peddinti, D. Galvez, P. Ghahremani, V . Manohar, X. Na, Y . Wang, and S. Khudanpur, “Purely sequence-trained neu- ral networks for ASR based on lattice-free MMI,” inProc. INTER- SPEECH, 2016, pp. 2751–2755
work page 2016
-
[48]
Wave-u-net: A multi-scale neural network for end-to-end audio source separation,
D. Stoller, S. Ewert, and S. Dixon, “Wave-u-net: A multi-scale neural network for end-to-end audio source separation,” in Proc. ISMIR, 2018
work page 2018
-
[49]
An overview of noise-robust automatic speech recognition,
J. Li, L. Deng, Y . Gong, and R. Haeb-Umbach, “An overview of noise-robust automatic speech recognition,” IEEE/ACM Transac- tions on Audio, Speech, and Language Processing, vol. 22, no. 4, pp. 745–777, April 2014
work page 2014
-
[50]
Knowledge-based probabilistic modeling for tracking lyrics in music audio signals,
G. Dzhambazov, “Knowledge-based probabilistic modeling for tracking lyrics in music audio signals,” Ph.D. dissertation, Uni- versitat Pompeu Fabra, 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.