Speech bandwidth extension with WaveNet
Pith reviewed 2026-05-25 01:29 UTC · model grok-4.3
The pith
A WaveNet model upsamples 8 kHz GSM-FR speech to 24 kHz with quality nearly matching AMR-WB at 16 kHz.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
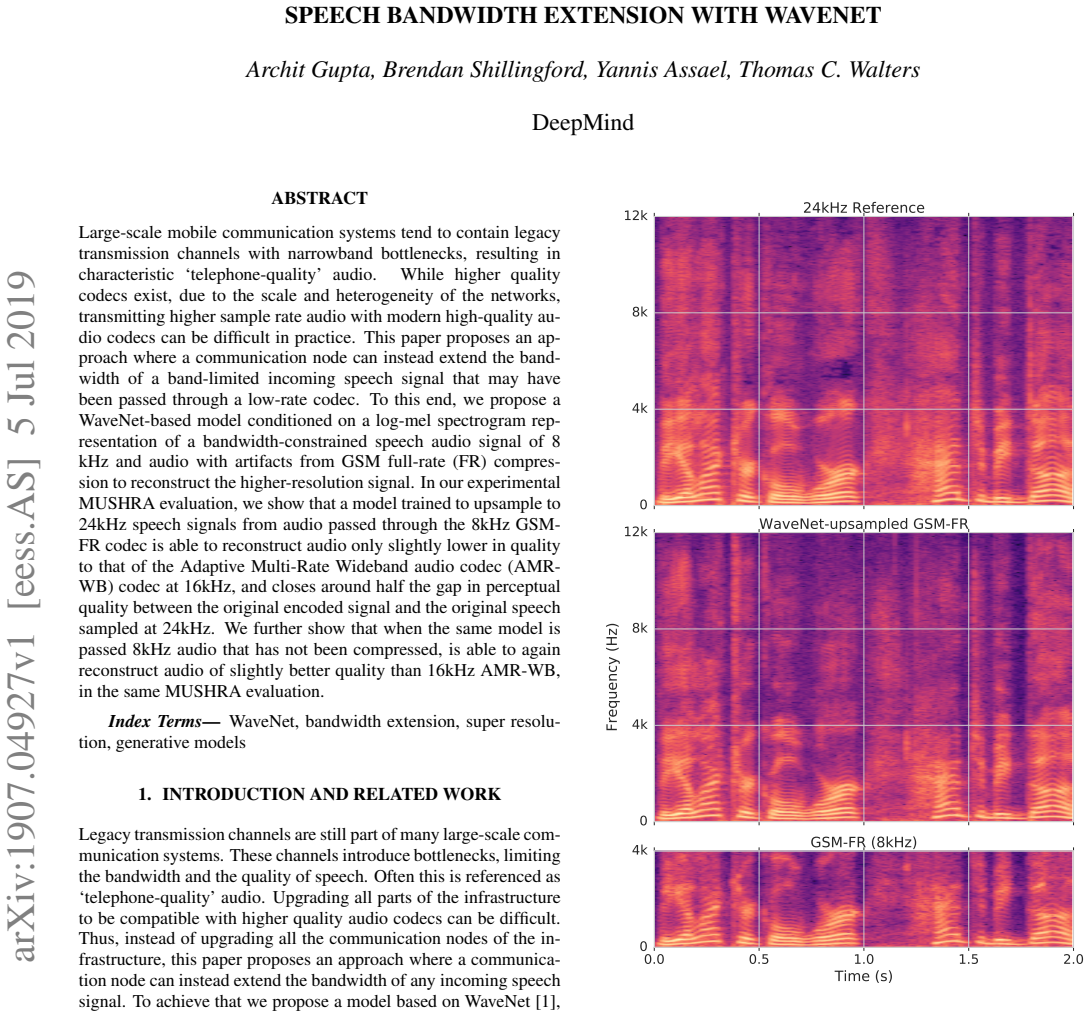
A WaveNet model trained to upsample to 24 kHz speech signals from audio passed through the 8 kHz GSM-FR codec reconstructs audio only slightly lower in quality than the AMR-WB codec at 16 kHz and closes around half the gap in perceptual quality between the original encoded signal and the original speech sampled at 24 kHz. The same model applied to uncompressed 8 kHz audio reconstructs audio of slightly better quality than 16 kHz AMR-WB.
What carries the argument
WaveNet model conditioned on log-mel spectrogram of the bandwidth-constrained input signal, which generates the higher sample rate output.
If this is right
- The model can be deployed at communication nodes to extend bandwidth of incoming legacy signals without changing transmission channels.
- It achieves this for both GSM-FR compressed inputs and clean 8 kHz inputs.
- The approach closes roughly half the perceptual quality gap to full 24 kHz originals.
- Quality remains only slightly below AMR-WB at 16 kHz in the reported tests.
Where Pith is reading between the lines
- Nodes equipped with this model could deliver incremental quality gains in heterogeneous networks that mix legacy and modern codecs.
- The log-mel conditioning technique might transfer to related audio tasks such as denoising or packet-loss concealment.
- Larger training sets covering more acoustic conditions could narrow the remaining quality gap further.
Load-bearing premise
The MUSHRA scores from the authors' chosen test set and listener pool serve as a reliable proxy for real-world perceptual quality across diverse speakers, accents, and network conditions.
What would settle it
A new MUSHRA test using a larger and more diverse set of speakers, accents, and transmission conditions that yields model scores substantially below AMR-WB would falsify the central claim.
Figures


read the original abstract
Large-scale mobile communication systems tend to contain legacy transmission channels with narrowband bottlenecks, resulting in characteristic "telephone-quality" audio. While higher quality codecs exist, due to the scale and heterogeneity of the networks, transmitting higher sample rate audio with modern high-quality audio codecs can be difficult in practice. This paper proposes an approach where a communication node can instead extend the bandwidth of a band-limited incoming speech signal that may have been passed through a low-rate codec. To this end, we propose a WaveNet-based model conditioned on a log-mel spectrogram representation of a bandwidth-constrained speech audio signal of 8 kHz and audio with artifacts from GSM full-rate (FR) compression to reconstruct the higher-resolution signal. In our experimental MUSHRA evaluation, we show that a model trained to upsample to 24kHz speech signals from audio passed through the 8kHz GSM-FR codec is able to reconstruct audio only slightly lower in quality to that of the Adaptive Multi-Rate Wideband audio codec (AMR-WB) codec at 16kHz, and closes around half the gap in perceptual quality between the original encoded signal and the original speech sampled at 24kHz. We further show that when the same model is passed 8kHz audio that has not been compressed, is able to again reconstruct audio of slightly better quality than 16kHz AMR-WB, in the same MUSHRA evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes conditioning a WaveNet on log-mel spectrograms extracted from 8 kHz GSM-FR compressed speech to generate 24 kHz output. MUSHRA listening tests are reported to show that the model produces audio only slightly lower in quality than AMR-WB at 16 kHz and closes roughly half the perceptual gap to the 24 kHz reference; a similar result holds for uncompressed 8 kHz input.
Significance. If the listening-test results prove robust, the approach offers a practical post-processing method to mitigate narrowband bottlenecks in legacy mobile networks without requiring codec or transmission changes. The direct comparison against AMR-WB and the use of a generative model for this task are positive aspects.
major comments (2)
- [abstract and experimental evaluation] The central claim rests on MUSHRA scores that close half the quality gap to the 24 kHz reference and place the model only slightly below AMR-WB. However, the manuscript provides no details on test-set size, speaker/accent diversity, number of listeners, randomization, error bars, or statistical significance testing (see abstract and experimental evaluation sections). This absence prevents assessment of whether the reported numbers support the generalization implied by the claim.
- [model and experimental sections] No ablation of the log-mel conditioning or of the GSM-FR artifact handling is presented, leaving unclear how much of the reported improvement is attributable to the WaveNet architecture versus the conditioning features.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly where feasible.
read point-by-point responses
-
Referee: [abstract and experimental evaluation] The central claim rests on MUSHRA scores that close half the quality gap to the 24 kHz reference and place the model only slightly below AMR-WB. However, the manuscript provides no details on test-set size, speaker/accent diversity, number of listeners, randomization, error bars, or statistical significance testing (see abstract and experimental evaluation sections). This absence prevents assessment of whether the reported numbers support the generalization implied by the claim.
Authors: We agree that these experimental details are necessary to properly assess the results. The revised manuscript will expand the experimental evaluation section to report the test-set size, speaker diversity, number of listeners, randomization procedure, and any available statistical information. We will explicitly note that error bars and formal significance testing were not performed in the original experiments. revision: yes
-
Referee: [model and experimental sections] No ablation of the log-mel conditioning or of the GSM-FR artifact handling is presented, leaving unclear how much of the reported improvement is attributable to the WaveNet architecture versus the conditioning features.
Authors: We acknowledge that no explicit ablation studies are included. In the revision we will add discussion in the model section on the rationale for log-mel conditioning and its role in handling GSM-FR artifacts. A full ablation would require new training runs that are not feasible at this stage; the existing comparisons against AMR-WB and the uncompressed 8 kHz case provide supporting evidence for the overall approach. revision: partial
Circularity Check
No circularity: claims rest on independent MUSHRA listening tests
full rationale
The paper trains a conditional WaveNet on log-mel features of 8 kHz GSM-FR input to generate 24 kHz output and reports perceptual quality via MUSHRA scores. These scores are external human judgments on held-out utterances; they are not computed from model parameters, not used as training targets, and not obtained by fitting or renaming any internal quantity. No equations, self-citations, or uniqueness theorems are invoked to derive the reported gap-closing performance; the result is a direct empirical measurement.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MUSHRA listening tests provide a valid ordinal ranking of perceptual audio quality that transfers across listener pools and acoustic conditions.
Reference graph
Works this paper leans on
-
[1]
Speech bandwidth extension with WaveNet
INTRODUCTION AND RELA TED WORK Legacy transmission channels are still part of many large-scale com- munication systems. These channels introduce bottlenecks, limiting the bandwidth and the quality of speech. Often this is referenced as ‘telephone-quality’ audio. Upgrading all parts of the infrastructure to be compatible with higher quality audio codecs ca...
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[2]
or to predict the upsampled waveform directly [6, 9, 10], leading to quality gains over earlier methods. In our experimental evaluation, we assess the ability of our pro- posed model to perform bandwidth extension on narrowband sig- nals. To illustrate the impact of our work, we show that a model trained to upsample to 24kHz speech signals passed through ...
-
[3]
TRAINING SETUP 2.1. Model Architecture WaveNet is a generative model that models the joint probability of a waveform x = {x1, . . . , xT } as a product of conditional prob- abilities given the samples at previous timesteps. A conditional WaveNet model takes an additional input variable h and models this conditional distribution as p(x|h) = T∏ t=1 p (xt|x1...
-
[4]
EXPERIMENTAL EV ALUA TION 3.1. Setup In this evaluation we are primarily interested in the case of speech enhancement in the setting of a fixed legacy audio coding pathway, such as calls on standard GSM mobile networks. In this case, the codec typically operates with a bandwidth of 4kHz, leading to an audio waveform with an 8kHz sample rate. To generate th...
-
[5]
CONCLUSIONS This work introduces a new WaveNet-based model for speech band- width extension. The model is able to reconstruct 24kHz audio from 8kHz signals that is of similar or better quality to that produced by the AMR-WB codec at 16kHz. Our upsampling method pro- duces “HD-V oice”-quality audio from standard telephony-quality and GSM-quality audio, sho...
-
[6]
WaveNet: A generative model for raw au- dio
A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. W. Senior, and K. Kavukcuoglu, “WaveNet: A generative model for raw au- dio.” in SSW, 2016, p. 125
work page 2016
-
[7]
Natu- ral tts synthesis by conditioning wavenet on mel spectrogram predictions,
J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y . Zhang, Y . Wang, R. Skerrv-Ryan, et al. , “Natu- ral tts synthesis by conditioning wavenet on mel spectrogram predictions,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2018, pp. 4779–4783
work page 2018
-
[8]
WaveNet based low rate speech coding,
W. B. Kleijn, F. S. Lim, A. Luebs, J. Skoglund, F. Stim- berg, Q. Wang, and T. C. Walters, “WaveNet based low rate speech coding,” in IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP) . IEEE, 2018, pp. 676–680
work page 2018
-
[9]
Low bit-rate speech coding with VQ-V AE and a WaveNet decoder,
C. Garbacea, A. van den Oord, Y . Li, F. S. C. Lim, A. Luebs, O. Vinyals, and T. C. Walters, “Low bit-rate speech coding with VQ-V AE and a WaveNet decoder,” in IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019
work page 2019
-
[10]
E. R. Larsen and R. M. Aarts, Audio Bandwidth Extension: Application of Psychoacoustics, Signal Processing and Loud- speaker Design. USA: John Wiley &; Sons, Inc., 2004
work page 2004
-
[11]
Audio Super Resolution using Neural Networks
V . Kuleshov, S. Z. Enam, and S. Ermon, “Audio su- per resolution using neural networks,” arXiv preprint arXiv:1708.00853, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
GSM Full Rate Speech Transcoding,
ESTI, “GSM Full Rate Speech Transcoding,” Euro- pean Digital Cellular Telecommunications System, Tech. Rep. 06.10, 02 1992, version 3.2.0. [Online]. Avail- able: https://www.etsi.org/deliver/etsi gts/06/0610/03.02. 00 60/gsmts 0610sv030200p.pdf
work page 1992
-
[13]
J. Abel and T. Fingscheidt, “Artificial speech bandwidth extension using deep neural networks for wideband spec- tral envelope estimation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. PP, pp. 1–1, 10 2017
work page 2017
-
[14]
Z.-H. Ling, Y . Ai, Y . Gu, and L.-R. Dai, “Waveform modeling and generation using hierarchical recurrent neural networks for speech bandwidth extension,” IEEE/ACM Transactions on Audio, Speech, and Language Processing , vol. 26, no. 5, pp. 883–894, 2018
work page 2018
-
[15]
Y . Gu and Z.-H. Ling, “Waveform modeling using stacked di- lated convolutional neural networks for speech bandwidth ex- tension.” in INTERSPEECH, 2017, pp. 1123–1127
work page 2017
-
[16]
Mandatory speech CODEC speech processing func- tions; AMR speech CODEC; General description,
3GPP, “Mandatory speech CODEC speech processing func- tions; AMR speech CODEC; General description,” 3rd Generation Partnership Project (3GPP), Technical Specifica- tion (TS) 26.071, 06 2018, version 15.0.0. [Online]. Avail- able: https://portal.3gpp.org/desktopmodules/Specifications/ SpecificationDetails.aspx?specificationId=1386
work page 2018
-
[17]
Parallel WaveNet: Fast high-fidelity speech synthesis,
A. van den Oord, Y . Li, I. Babuschkin, K. Simonyan, O. Vinyals, K. Kavukcuoglu, G. van den Driessche, E. Lock- hart, L. Cobo, F. Stimberg, N. Casagrande, D. Grewe, S. Noury, S. Dieleman, E. Elsen, N. Kalchbrenner, H. Zen, A. Graves, H. King, T. Walters, D. Belov, and D. Hassabis, “Parallel WaveNet: Fast high-fidelity speech synthesis,” in Proceedings of t...
work page 2018
-
[18]
Waveglow: A flow- based generative network for speech synthesis,
R. Prenger, R. Valle, and B. Catanzaro, “Waveglow: A flow- based generative network for speech synthesis,” in IEEE In- ternational Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP). IEEE, 2019
work page 2019
-
[19]
Efficient neural audio synthesis,
N. Kalchbrenner, E. Elsen, K. Simonyan, S. Noury, N. Casagrande, E. Lockhart, F. Stimberg, A. Oord, S. Diele- man, and K. Kavukcuoglu, “Efficient neural audio synthesis,” in International Conference on Machine Learning , 2018, pp. 2415–2424
work page 2018
-
[20]
T. Salimans, A. Karpathy, X. Chen, and D. P. Kingma, “Pix- elcnn++: A pixelcnn implementation with discretized logistic mixture likelihood and other modifications,” in International Conference on Learning Representations (ICLR) , 2017
work page 2017
-
[21]
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “LibriTTS: A corpus de- rived from librispeech for text-to-speech,” arXiv preprint arXiv:1904.02882, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[22]
Lib- rispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: an asr corpus based on public domain audio books,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015, pp. 5206–5210
work page 2015
-
[23]
ADAM: A method for stochastic optimization,
D. P. Kingma and J. Ba, “ADAM: A method for stochastic optimization,” in International Conference on Learning Rep- resentations (ICLR), 2015
work page 2015
-
[24]
In-datacenter performance analysis of a tensor processing unit,
N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borchers, et al., “In-datacenter performance analysis of a tensor processing unit,” in International Symposium on Computer Architecture (ISCA). IEEE, 2017, pp. 1–12
work page 2017
-
[25]
Method for the subjective assessment of intermediate sound quality (MUSHRA),
International Telecommunication Union, “Method for the subjective assessment of intermediate sound quality (MUSHRA),” ITU-R Recommendation BS.1534-1, Tech. Rep., 2001
work page 2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.