Deep learning applied to computational mechanics: A comprehensive review, state of the art, and the classics
Pith reviewed 2026-05-24 10:19 UTC · model grok-4.3
The pith
Deep learning methods, both hybrid and pure, are reviewed for use in solid and fluid mechanics simulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
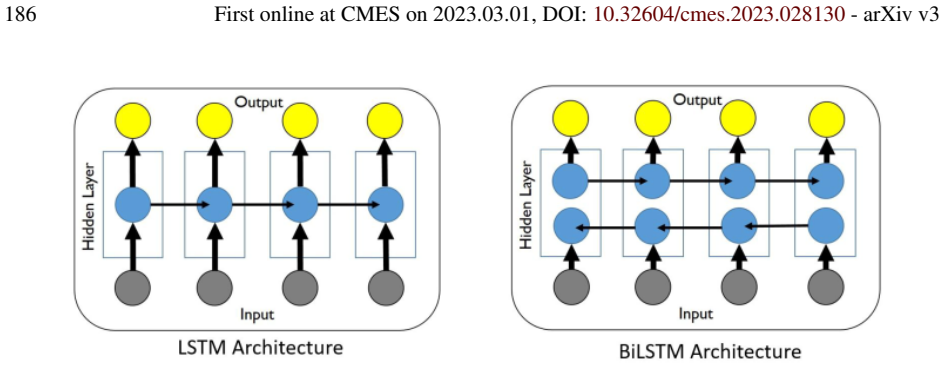
The paper claims that recent deep learning developments relevant to computational mechanics can be organized into hybrid methods, which use LSTM networks to model nonlinear constitutive relations or reduce model order and convolutional networks to accelerate traditional integrators, and pure ML methods represented by physics-informed neural networks that may incorporate attention to handle discontinuous solutions; it further reviews LSTM and attention architectures along with stochastic optimizers and kernel machines to sufficient depth for advanced follow-on work.
What carries the argument
Hybrid methods that augment traditional PDE discretizations with ML and pure ML methods such as physics-informed neural networks, with LSTM for constitutive modeling and model reduction and attention for discontinuities.
If this is right
- Hybrid LSTM-based methods can capture complex nonlinear material behavior within existing finite-element frameworks.
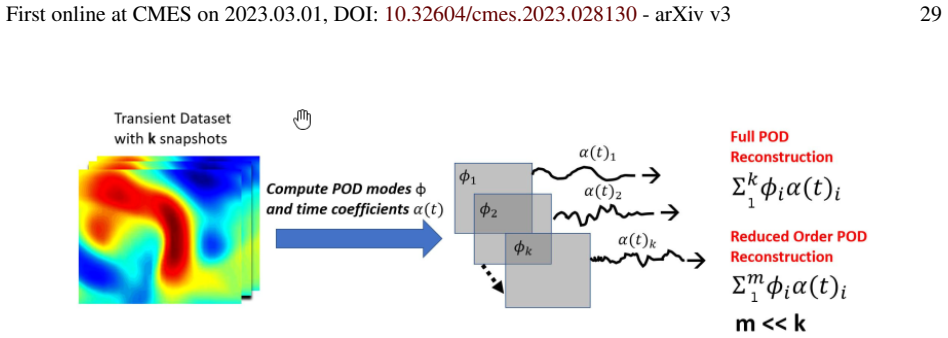
- Model-order reduction via LSTM can make turbulence simulations more efficient.
- Convolutional networks can speed up specific steps inside conventional time-integration schemes.
- PINNs, possibly augmented with attention, can solve nonlinear PDEs directly without traditional discretization.
- Kernel machines including Gaussian processes provide a foundation for understanding infinite-width shallow networks.
Where Pith is reading between the lines
- The review structure could serve as a template for similar surveys in related fields such as structural optimization or multiphysics coupling.
- Explicit discussion of limitations in the classics may encourage more careful citation practices when referencing early AI work in engineering contexts.
- The beam-positioning example suggests that the reviewed techniques are already close to practical control applications in deformable-body dynamics.
Load-bearing premise
The chosen papers and methods accurately represent the current state of the art without significant selection bias or major omissions.
What would settle it
Discovery of a substantial number of peer-reviewed works on deep learning for finite-element or continuum mechanics problems that are omitted from the review would indicate the coverage is incomplete.
Figures






























































































































































read the original abstract
Three recent breakthroughs due to AI in arts and science serve as motivation: An award winning digital image, protein folding, fast matrix multiplication. Many recent developments in artificial neural networks, particularly deep learning (DL), applied and relevant to computational mechanics (solid, fluids, finite-element technology) are reviewed in detail. Both hybrid and pure machine learning (ML) methods are discussed. Hybrid methods combine traditional PDE discretizations with ML methods either (1) to help model complex nonlinear constitutive relations, (2) to nonlinearly reduce the model order for efficient simulation (turbulence), or (3) to accelerate the simulation by predicting certain components in the traditional integration methods. Here, methods (1) and (2) relied on Long-Short-Term Memory (LSTM) architecture, with method (3) relying on convolutional neural networks. Pure ML methods to solve (nonlinear) PDEs are represented by Physics-Informed Neural network (PINN) methods, which could be combined with attention mechanism to address discontinuous solutions. Both LSTM and attention architectures, together with modern and generalized classic optimizers to include stochasticity for DL networks, are extensively reviewed. Kernel machines, including Gaussian processes, are provided to sufficient depth for more advanced works such as shallow networks with infinite width. Not only addressing experts, readers are assumed familiar with computational mechanics, but not with DL, whose concepts and applications are built up from the basics, aiming at bringing first-time learners quickly to the forefront of research. History and limitations of AI are recounted and discussed, with particular attention at pointing out misstatements or misconceptions of the classics, even in well-known references. Positioning and pointing control of a large-deformable beam is given as an example.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a review paper surveying recent deep learning applications to computational mechanics. It covers hybrid methods that combine traditional PDE discretizations with LSTM (for constitutive modeling and model-order reduction) and CNN (for simulation acceleration), pure ML approaches such as PINNs with attention mechanisms for discontinuous solutions, reviews of LSTM/attention architectures, modern optimizers, and kernel machines (including Gaussian processes and infinite-width networks), plus discussion of AI history, limitations, and misconceptions. An example application to positioning/pointing control of a large-deformable beam is included. The target audience is computational-mechanics experts new to DL, with concepts built from the basics.
Significance. If the literature selection is representative and the coverage balanced, the review would provide a useful on-ramp for mechanics researchers entering DL, explicitly contrasting hybrid and pure-ML strategies and correcting common misconceptions about the classics. The inclusion of both modern architectures and kernel-machine background for advanced readers adds pedagogical value.
major comments (2)
- [Abstract] Abstract and opening sections: the central claim that the paper reviews 'many recent developments ... in detail' and supplies the 'state of the art' rests on the assumption of unbiased, comprehensive paper selection up to the 2022 cutoff. No explicit selection methodology, inclusion/exclusion criteria, or discussion of potential gaps (e.g., key LSTM turbulence papers or additional PINN variants) is provided, making it impossible to verify representativeness.
- [Introduction (implied by abstract)] The positioning statement that the review brings 'first-time learners quickly to the forefront of research' is load-bearing for the intended contribution, yet the manuscript does not compare its scope or depth against existing surveys in the same area, leaving the incremental value of this particular synthesis unclear.
minor comments (2)
- [Abstract] The three motivating AI breakthroughs cited in the abstract are not enumerated explicitly; listing them would strengthen the opening motivation.
- Ensure that every cited work is dated no later than the stated 2022 cutoff and that references to the 'classics' are accompanied by the specific misstatements being corrected.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below, agreeing that additional clarifications on scope and comparisons to prior surveys will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and opening sections: the central claim that the paper reviews 'many recent developments ... in detail' and supplies the 'state of the art' rests on the assumption of unbiased, comprehensive paper selection up to the 2022 cutoff. No explicit selection methodology, inclusion/exclusion criteria, or discussion of potential gaps (e.g., key LSTM turbulence papers or additional PINN variants) is provided, making it impossible to verify representativeness.
Authors: We agree that an explicit discussion of literature selection would improve transparency. Although the review was compiled based on relevance to computational mechanics applications up to the 2022 cutoff, we will add a new paragraph in the Introduction describing the general search approach, inclusion focus on solid/fluid mechanics and finite-element contexts, and explicit acknowledgment of potential gaps (e.g., certain turbulence LSTM works or post-cutoff PINN variants). revision: yes
-
Referee: [Introduction (implied by abstract)] The positioning statement that the review brings 'first-time learners quickly to the forefront of research' is load-bearing for the intended contribution, yet the manuscript does not compare its scope or depth against existing surveys in the same area, leaving the incremental value of this particular synthesis unclear.
Authors: The manuscript's distinctive elements include the joint treatment of hybrid LSTM/CNN methods with pure PINN approaches, coverage of kernel machines and infinite-width networks, and discussion of AI history with corrections to common misconceptions. We nevertheless recognize the benefit of explicit positioning. We will revise the Introduction to include a concise comparison with related surveys (e.g., those focused primarily on PINNs or data-driven constitutive modeling) and to articulate the incremental synthesis provided here. revision: yes
Circularity Check
No circularity: review draws from external citations without internal derivations
full rationale
This is a literature review paper with no original mathematical derivations, predictions, or fitted models presented as results. The central content consists of summaries of external cited works on DL methods for mechanics (LSTM, PINN, etc.), built from basics for the reader. No steps match the enumerated circularity patterns, as there are no equations reducing to inputs by construction, no fitted parameters renamed as predictions, and no load-bearing self-citations that justify a uniqueness theorem or ansatz. The paper is self-contained as a survey against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
SLIDE: A machine-learning based method for forced dynamic response estimation of multibody systems
SLIDE is a deep learning estimator that truncates initial effects via complex eigenvalues of linearized equations to predict output sequences of damped multibody systems, reporting speedups up to several million times.
Reference graph
Works this paper leans on
-
[2]
Rosenblatt, F. (1962). Principles of neurodynamics: Perceptrons and the theory of brain mechanisms. Spartan Books. 2, 11, 46, 55, 210, 212, 213, 214, 215, 271
work page 1962
-
[3]
Polyak, B. (1964). Some methods of speeding up the convergence of iteration methods . USSR Com- putational Mathematics and Mathematical Physics, 4(5), 1–17. DOI 10.1016/0041-5553(64)90137-5. 2, 10, 11, 85, 89, 90, 91
-
[4]
Roose, K. (2022). An A.I.-Generated Picture Won an Art Prize. Artists Aren’t Happy.New York Times, (Sep 2). Original website. 6, 7
work page 2022
-
[5]
Jumper, J., Evans, R., Pritzel, A., Green, T., Figurnov, M., et al. (2021). Highly accurate protein structure prediction with AlphaFold. Nature, 596(7873), 583–589. 7
work page 2021
-
[6]
J., Guez, A., Sifre, L., et al
Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., et al. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587), 484+. Original website. 7, 12, 13
work page 2016
-
[7]
How Google’s AlphaGo Beat a Go World Champion
Moyer, C. How Google’s AlphaGo Beat a Go World Champion. 2016 Mar 28, Original website. 7
work page 2016
-
[8]
Edwards, B. (2022). DeepMind breaks 50-year math record using AI; new record falls a week later. Ars Technica, (Oct 13). Original website, Internet archive. 7
work page 2022
-
[9]
Vu-Quoc, L., Humer, A. (2022). Deep learning applied to computational mechanics: A comprehensive review, state of the art, and the classics. arXiv:2212.08989. 8
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Roose, K. (2023). Bing (Yes, Bing) Just Made Search Interesting Again. New York Times, (Feb 8). Original website. 8
work page 2023
-
[11]
Knight, W. (2023). Meet Bard, Google’s Answer to ChatGPT. WIRED, (Feb 6). Original website. 8
work page 2023
-
[12]
Schmidhuber, J. (2015). Deep learning in neural networks: An overview. Neural Networks, 61, 87–
work page 2015
-
[13]
8, 36, 38, 52, 223, 224, 225, 272
-
[14]
LeCun, Y ., Bengio, Y ., Hinton, G. (2015). Deep learning.Nature, 521(7553), 436–444. 8, 12, 14, 38, 52, 53, 54, 129, 131
work page 2015
-
[15]
Khan, S., Yairi, T. (2018). A review on the application of deep learning in system health management. Mechanical Systems and Signal Processing, 107, 241–265. 8
work page 2018
-
[16]
Sanchez-Lengeling, B., Aspuru-Guzik, A. (2018). Inverse molecular design using machine learning: Generative models for matter engineering. Science, 361(6400, SI), 360–365. 8
work page 2018
-
[17]
Ching, T., Himmelstein, D. S., Beaulieu-Jones, B. K., Kalinin, A. A., Do, B. T., et al. (2018). Opportu- nities and obstacles for deep learning in biology and medicine. Journal of the Royal Society Interface, 15(141). 8
work page 2018
-
[18]
Quinn, J. A., Nyhan, M. M., Navarro, C., Coluccia, D., Bromley, L., et al. (2018). Humanitarian applications of machine learning with remote-sensing data: review and case study in refugee settlement mapping. Philosophical Transactions of the Royal Society A-Mathematical Physical and Engineering Sciences, 376(2128). 8
work page 2018
-
[19]
Higham, C. F., Higham, D. J. (2019). Deep learning: An introduction for applied mathematicians. SIAM Review, 61(4), 860–891. 8
work page 2019
-
[20]
Dayan, P., Abbott, L. (2001). Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems. MIT Press. 8, 9, 11, 30, 31, 38, 39, 40, 41, 43, 212, 215, 216, 217, 219
work page 2001
-
[21]
Sze, V ., Chen, Y .-H., Yang, T.-J., Emer, J. S. (2017). Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proceedings of the IEEE, 105(12), 2295–2329. 8, 17, 32, 38, 209
work page 2017
-
[22]
Nielsen, M. (2015). Neural Networks and Deep Learning . Determination Press. Original website. Internet archive. 8, 32, 38, 66, 67, 209, 210, 213
work page 2015
-
[23]
Rumelhart, D., Hinton, G., Williams, R. (1986). Learning representations by back-propagating errors. Nature, 323(6088), 533–536. 8, 90, 215, 223, 224, 225, 271
work page 1986
-
[24]
Ghaboussi, J., Garrett, J., Wu, X. (1991). Knowledge-based modeling of material behavior with neural networks. Journal of Engineering Mechanics-ASCE, 117(1), 132–153. 8, 9, 26, 32, 173, 209, 272
work page 1991
-
[26]
Wang, K., Sun, W. C. (2018). A multiscale multi-permeability poroplasticity model linked by recursive homogenizations and deep learning. Computer Methods in Applied Mechanics and Engineering, 334, 337–380. 8, 9, 11, 22, 24, 25, 26, 27, 28, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183, 184
work page 2018
-
[27]
Mohan, A., Gaitonde, D. (2018). A deep learning based approach to reduced order modeling for turbulent flow control using LSTM neural networks. arXiv:1804.09269 [physics.comp-ph]. Apr 24. 8, 9, 11, 28, 29, 30, 184, 185, 186, 187, 188, 189, 190, 191, 192
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[28]
Zaman, M., Zhu, J. (1998). A neural network model for a cohesionless soilIn AttohOkine, NO. Arti- ficial Intelligence and Mathematical Methods in Pavement and Geomechanical Systems. International Workshop on Artificial Intelligence and Mathematical Methods in Pavement and Geomechanical Sys- tems, Miami, FL, Nov 05-06, 1998. 9
work page 1998
-
[29]
Su, H., Fan, L., Schlup, J. (1998). Monitoring the process of curing of epoxy/graphite fiber composites with a recurrent neural network as a soft sensor. Engineering Applications of Artificial Intelligence , 11(2), 293–306. 9
work page 1998
-
[30]
Li, C., Huang, T. (1999). Automatic structure and parameter training methods for modeling of me- chanical systems by recurrent neural networks. Applied Mathematical Modelling , 23(12), 933–944. 9
work page 1999
-
[31]
Waszczyszyn, Z. (2000). Neural networks in structural engineering: Some recent results and prospects for applicationsIn Topping, BHV. Computational Mechanics for the Twenty-First Century. 5th Inter- national Conference on Computational Structures Technology/2nd International Conference on Engi- neering Computational Technology, Leuven, Belgium, Sep 06-08, 2000. 9
work page 2000
-
[32]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., et al. (2017). Attention Is All You Need. CoRR, abs/1706.03762v5. arXiv:1706.03762v5. See Footnote 337. 9, 11, 135, 138, 139, 140, 141, 142, 143, 248
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Hahnloser, R., Sarpeshkar, R., Mahowald, M., Douglas, R., Seung, S. (2000). Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit (vol 405, pg 947, 2000). Nature, 408(6815), 1012–U24. 9, 39, 219, 221, 222
work page 2000
-
[34]
Jarrett, K., Kavukcuoglu, K., Ranzato, M., LeCun, Y . (2009). What is the Best Multi-Stage Architec- ture for Object Recognition?In 2009 IEEE 12th International Conference on Computer Vision (ICCV). IEEE International Conference on Computer Vision. IEEE; IEEE Comp Soc. 12th IEEE International Conference on Computer Vision, Kyoto, JAPAN, SEP 29-OCT 02, 2009. 9, 39
work page 2009
-
[35]
Nair, V ., Hinton, G. (2010). Rectified linear units improve restricted boltzmann machines.Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel. 9, 39
work page 2010
-
[36]
Little, W. (1974). The existence of persistent states in the brain. Mathematical Biosciences, 19, 101–
work page 1974
-
[37]
In Cabrera, B and Gutfreund, H and Kresin, V (eds), From High-Temperature Superconductivity to Microminiature Refrigeration, William Little Symposium on From High-Temperature Supercon- ductivity to Microminiature Refrigeration, Stanford Univ, Stanford, CA, Sep 30, 1995.336. 9, 220
work page 1995
-
[38]
Ramachandran, P., Barret, Z., Le, Q. (2017). Searching for Activation Functions. CoRR (Computing Research Repository), abs/1710.05941v2. arXiv:1710.05941v2. See Footnote 337. 9, 52, 219, 221, 222, 223
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Oishi, A., Yagawa, G. (2017). Computational mechanics enhanced by deep learning. Computer Meth- ods in Applied Mechanics and Engineering, 327, 327–351. 9, 11, 18, 19, 20, 21, 32, 46, 53, 60, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 209
work page 2017
-
[41]
Zienkiewicz, O., Taylor, R., Zhu, J. (2013). The Finite Element Method: Its Basis and Fundamentals. Oxford: Butterworth-Heineman. 7th edition. 9, 35, 163, 164
work page 2013
-
[42]
Barlow, J. (1976). Optimal stress locations in finite-element models. International Journal for Numer- ical Methods in Engineering, 10(2), 243–251. 9
work page 1976
-
[43]
Barlow, J. (1977). Optimal stress locations in finite-element models - reply. International Journal for Numerical Methods in Engineering, 11(3), 604. 9
work page 1977
-
[44]
Abaqus 6.14. Theory Guide. Simulia Systems, Dassault Systèmes. Subsection 3.2.4 Solid isoparamet- ric quadrilaterals and hexahedra. (Website, go to Section Reference, Abaqus Theory Guide, Section 3 Elements, Section 3.2 Continuum elements, then Section 3.2.4.). 9
-
[45]
Ghaboussi, J., Garrett, J., Wu, X. (1990). Material Modeling with Neural NetworksIn Pande, GN and Middleton, J. Numerical Methods in Engineering : Theory and Applications, Vol 2. 3rd International Conf on Numerical Methods in Engineering : Theory and Applications ( NUMETA 90 ), Univ Coll Swansea, Swansea, Wales, Jan 07-11, 1990. 9
work page 1990
-
[46]
Chen, C. (1989). Applying and validating neural network technology for nondestructive evaluation of materialsIn 1989 IEEE International Conference on Systems, Man, and Cybernetics, Vols 1-3: Con- ference Proceedings. 1989 IEEE International Conf on Systems, Man, and Cybernetics : Decision- Making in Large-Scale Systems, Cambridge, MA, Nov 14-17, 1989. 9
work page 1989
-
[47]
Sayeh, M., Viswanathan, R., Dhali, S. (1990). Neural networks for assessment of impact and stress relief on composite-materialsIn Genisio, M. Sixth Annual Conference on Materials Technology: Com- posite Technology. 6th Annual Conf on Materials Technology : Composite Technology, Southern Illinois Univ Carbondale, Carbondale, IL, Apr 10-11, 1990. 9
work page 1990
-
[48]
Chen, C., Leclair, S. (1991). A probability neural network (pnn) estimator for improved reliability of noisy sensor data. Journal of Reinforced Plastics and Composites, 10(4), 379–390. 9
work page 1991
-
[49]
Kim, Y ., Choi, Y ., Widemann, D., Zohdi, T. (2020). A fast and accurate physics-informed neural network reduced order model with shallow masked autoencoderer. ( Sep 28). Version 2, 2020.09.28: arXiv:2009.11990v2, 2009.11990. 9, 10, 11, 193, 194, 195, 196, 197, 198, 199, 200, 201, 203, 205, 206, 207
- [50]
-
[51]
Robbins, H., Monro, S. (1951b). Stochastic approximation. Annals of Mathematical Statistics, 22(2),
-
[52]
Nesterov, I. (1983). A method of the solution of the convex-programming problem with a speed of convergence O(1/k2). Doklady Akademii Nauk SSSR, 269(3), 543–547. In Russian. 10, 89, 91
work page 1983
-
[53]
Nesterov, Y . (2018). Lecture on Convex Optimization. 2nd edition. Switzerland: Springer Nature. 10, 89, 91
work page 2018
-
[54]
Duchi, J., Hazan, E., Singer, Y . (2011). Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. Journal of Machine Learning Research, 12, 2121–2159. 10, 105
work page 2011
-
[55]
Tieleman, T., Hinton, G. (2012). Lecture 6e, rmsprop: Divide the gradient by a running average of its recent magnitude. Youtube video, time 5:54. Lecture notes, p.29: Original website, Internet archive. 10, 108
work page 2012
-
[56]
Zeiler, M. D. (2012). ADADELTA: An adaptive learning rate method. ( Dec 22). arXiv:1212.5701. 10, 106, 108, 109
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[58]
Loshchilov, I., Hutter, F. (2019). Decoupled weight decay regularization. (Jan 4). arXiv:1711.05101v3. OpenReview. 10, 85, 87, 92, 93, 99, 106, 109, 115, 116, 117, 123
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[59]
Bahdanau, D., Cho, K., Bengio, Y . (2015). Neural machine translation by jointly learning to align and translate. CoRR, abs/1409.0473. arXiv:1409.0473. 11, 135, 136, 137, 138
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[60]
Furshpan, E., Potter, D. (1957). Mechanism of nerve-impulse transmission at a crayfish synapse. Nature, 180(4581), 342–343. 11, 222
work page 1957
-
[61]
Furshpan, E., Potter, D. (1959b). Slow post-synaptic potentials recorded from the giant motor fibre of the crayfish. Journal of Physiology-London, 145(2), 326–335. 11, 222
-
[62]
Gershgorn, D. (2017). The data that transformed AI research—and possibly the world. Quartz, (Jul 26). Original website. Internet archive (blurry images). 11, 13
work page 2017
-
[63]
He, K., Zhang, X., Ren, S., Sun, J. (2015). Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. CoRR, abs/1502.01852. arXiv:1502.01852, 1502.01852. 12, 40, 70, 206, 220
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[64]
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., et al. (2015). ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision, 115(3), 211–252. 12, 13
work page 2015
-
[65]
Park, E., Liu, W., Russakovsky, O., Deng, J., Li, F., et al. (2017). ImageNet Large scale visual recogni- tion challenge (ILSVRC) 2017, Overview. ILSVRC 2017, (Jul 26). Original website Internet archive. 12, 13
work page 2017
-
[66]
Science’s 2021 Breakthrough: AI-powered Protein Prediction
Beckwith, W. Science’s 2021 Breakthrough: AI-powered Protein Prediction. 2022 Dec 17, Original website. 11, 12
work page 2021
-
[67]
DeepMind, 2022 Jul 28, Original website, Internet archive
AlphaFold reveals the structure of the protein universe. DeepMind, 2022 Jul 28, Original website, Internet archive. 12
work page 2022
-
[68]
DeepMind’s AI predicts structures for a vast trove of proteins
Callaway, E. DeepMind’s AI predicts structures for a vast trove of proteins. 2021 Jul 21, Original website. 12
work page 2021
-
[69]
The Guardian view on the future of AI: Great power, great irresponsibility
Editorial (2019). The Guardian view on the future of AI: Great power, great irresponsibility. The Guardian, (Jan 01). Original website. Internet archive. 12, 236, 237
work page 2019
-
[70]
Silver, D., Hubert, T., Schrittwieser, J., Antonoglou, I., Lai, M., et al. (2018). A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play.Science, 362(6419), 1140+. 12
work page 2018
-
[71]
Mnih, V ., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., et al. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529–533. 13
work page 2015
-
[72]
P., Buesing, L., Guez, A., et al
Racaniere, S., Weber, T., Reichert, D. P., Buesing, L., Guez, A., et al. (2017). Imagination-Augmented Agents for Deep Reinforcement Learning. In Guyon, I and Luxburg, UV and Bengio, S and Wallach, H and Fergus, R and Vishwanathan, S and Garnett, R, editor,Advances in Neural Information Processing Systems 30 (NIPS 2017), volume 30 of Advances in Neural In...
work page 2017
-
[73]
Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., et al. (2017). Mastering the game of Go without human knowledge. Nature, 550(7676), 354+. 13
work page 2017
-
[74]
Artificial intelligence - hype, hope and fear
Cellan-Jones, Rory (2017). Artificial intelligence - hype, hope and fear. BBC, (Oct 16). Original website. Internet archive. 13
work page 2017
-
[75]
Campbell, M. (2018). Mastering board games. A single algorithm can learn to play three hard board games. Science, 362(6419), 1118. 13
work page 2018
-
[76]
Why artificial intelligence is enjoying a renaissance
The Economist (2016). Why artificial intelligence is enjoying a renaissance. ( Jul 15 ). (https://goo.gl/Grkofq). 13, 54, 226
work page 2016
-
[77]
From not working to neural networking
The Economist (2016). From not working to neural networking. ( Jun 25). (https://goo.gl/z1c9pc). 13, 52, 54, 226
work page 2016
-
[79]
Hardesty, L. (2017). Explained: Neural networks. MIT News, (Apr 14). Original website. Internet archive. 13, 210
work page 2017
-
[80]
Goodfellow, I., Bengio, Y ., Courville, A. (2016). Deep Learning. Cambridge, MA: The MIT Press. 14, 16, 17, 27, 32, 34, 35, 36, 37, 38, 39, 40, 44, 46, 47, 48, 49, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 65, 67, 69, 70, 72, 73, 75, 76, 77, 78, 84, 85, 86, 87, 89, 90, 91, 92, 93, 99, 100, 102, 104, 106, 108, 109, 112, 114, 115, 126, 127, 128, 129, 131,...
work page 2016
-
[81]
Ford, K. (2018). Architects of Intelligence: The truth about AI from the people building it . Packt Publishing. 14, 16, 221, 223, 224, 225, 235
work page 2018
-
[82]
Bottou, L., Curtis, F. E., Nocedal, J. (2018). Optimization Methods for Large-Scale Machine Learning. SIAM Review, 60(2), 223–311. 14, 76, 78, 84, 85, 87, 93, 106, 108, 109
work page 2018
-
[83]
Khullar, D. (2019). A.I. Could Worsen Health Disparities. New York Times, (Jan 31). Original website. 14
work page 2019
-
[84]
Kornfield, M., Firozi, P. (2020). Artificial intelligence use is growing in the U.S. healthcare system. Washington Post, (Feb 24). Original website. 14
work page 2020
-
[85]
Lee, K. (2018a). AI Superpowers: China, Silicon Valley, and the New World Order. Houghton Mifflin Harcourt. 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.