Non-stationary Diffusion For Probabilistic Time Series Forecasting
Pith reviewed 2026-05-22 16:43 UTC · model grok-4.3
The pith
A diffusion model for probabilistic time series forecasting can handle non-stationary uncertainty by using a location-scale noise model instead of assuming fixed variance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors design NsDiff as a diffusion-based probabilistic forecasting framework based on the Location-Scale Noise Model that is capable of modeling the changing pattern of uncertainty in time series by combining a denoising diffusion conditional generative model with a pre-trained conditional mean and variance estimator and an uncertainty-aware noise schedule.
What carries the argument
The uncertainty-aware noise schedule that dynamically adjusts noise levels to reflect the data uncertainty at each step and integrates the time-varying variances into the diffusion process.
If this is right
- Probabilistic forecasts adapt their spread according to estimated time-varying uncertainty at each time step.
- The model outperforms existing diffusion approaches on real-world and synthetic datasets that exhibit non-stationary uncertainty.
- Endpoint distributions are modeled adaptively rather than under a fixed variance assumption.
- The framework produces prediction intervals that change over the forecast horizon to match observed data patterns.
Where Pith is reading between the lines
- This separation of uncertainty estimation before the generative step could apply to other sequential data where variance changes over time.
- Pre-training a variance predictor separately may simplify handling of heteroscedasticity in a range of forecasting models.
- The adaptive schedule suggests a path for making other generative models more responsive to non-stationary conditions without full retraining.
Load-bearing premise
The pre-trained conditional mean and variance estimator must accurately capture the non-stationary uncertainty patterns for the adaptive noise schedule to integrate time-varying variances without bias.
What would settle it
On synthetic time series where variance is set to increase or decrease at known points, checking whether the model's generated forecast distributions show matching changes in spread at those points would settle the central claim.
Figures




read the original abstract
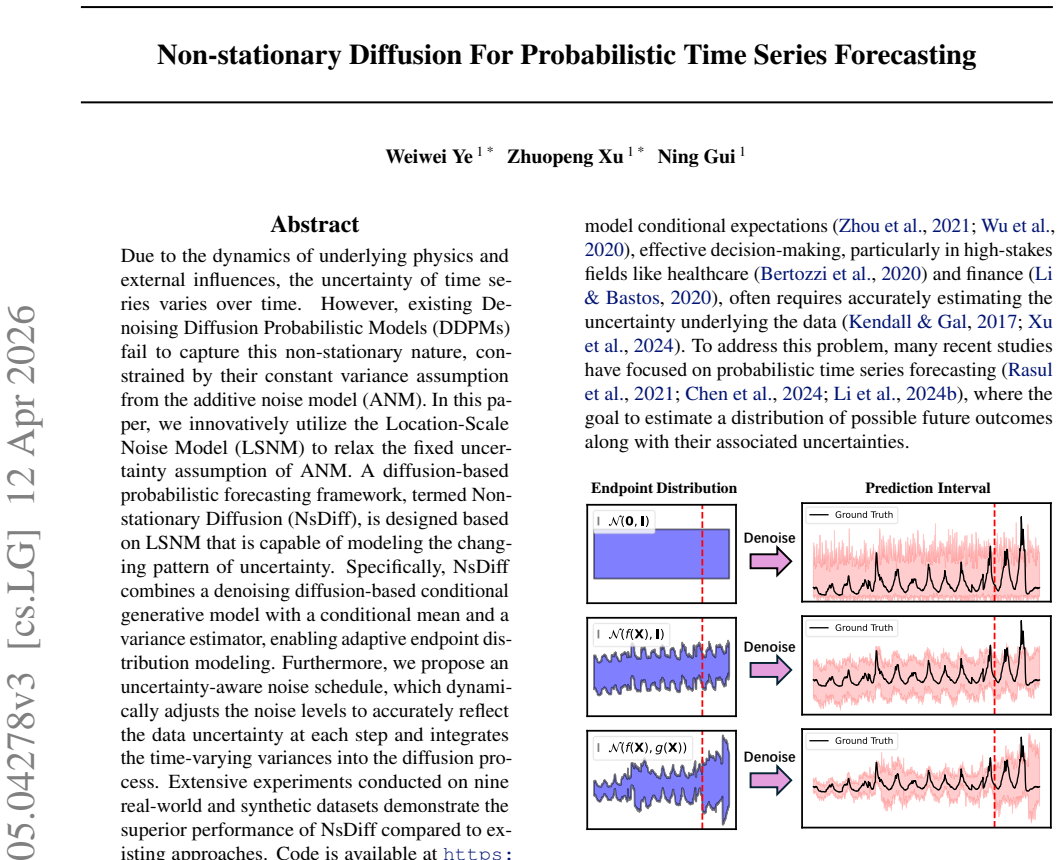
Due to the dynamics of underlying physics and external influences, the uncertainty of time series often varies over time. However, existing Denoising Diffusion Probabilistic Models (DDPMs) often fail to capture this non-stationary nature, constrained by their constant variance assumption from the additive noise model (ANM). In this paper, we innovatively utilize the Location-Scale Noise Model (LSNM) to relax the fixed uncertainty assumption of ANM. A diffusion-based probabilistic forecasting framework, termed Non-stationary Diffusion (NsDiff), is designed based on LSNM that is capable of modeling the changing pattern of uncertainty. Specifically, NsDiff combines a denoising diffusion-based conditional generative model with a pre-trained conditional mean and variance estimator, enabling adaptive endpoint distribution modeling. Furthermore, we propose an uncertainty-aware noise schedule, which dynamically adjusts the noise levels to accurately reflect the data uncertainty at each step and integrates the time-varying variances into the diffusion process. Extensive experiments conducted on nine real-world and synthetic datasets demonstrate the superior performance of NsDiff compared to existing approaches. Code is available at https://github.com/wwy155/NsDiff.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Non-stationary Diffusion (NsDiff), a probabilistic time series forecasting method based on denoising diffusion probabilistic models adapted via the Location-Scale Noise Model (LSNM) to handle non-stationary uncertainty. It employs a pre-trained conditional mean and variance estimator to inform an uncertainty-aware noise schedule that dynamically adjusts noise levels in the diffusion process, aiming to better model changing uncertainty patterns. The authors report superior performance over existing methods on nine datasets.
Significance. Should the technical details of the noise schedule hold up under scrutiny, this could represent a meaningful advance in applying diffusion models to non-stationary time series data, potentially improving forecast reliability in applications where uncertainty evolves over time. The open-source code is a strength for reproducibility.
major comments (1)
- [Section on uncertainty-aware noise schedule] The integration of the time-varying variances from the pre-trained LSNM estimator into the diffusion forward process requires a detailed derivation showing that the marginal distribution q(x_t | x_0) remains tractable or how the training objective is adjusted accordingly. The standard DDPM closed-form relies on fixed beta schedule; a data-dependent schedule may alter the signal-to-noise ratio and necessitate changes to the loss function to avoid bias in the learned reverse process.
minor comments (2)
- Include error bars or standard deviations in the experimental results tables to substantiate the performance claims.
- [Abstract] The abstract would benefit from a brief mention of the specific metrics used to demonstrate superiority.
Simulated Author's Rebuttal
We are grateful to the referee for the detailed review and valuable comments on our work. We have carefully considered the major comment regarding the uncertainty-aware noise schedule and provide our response below. We believe the proposed approach maintains tractability, and we will enhance the manuscript accordingly.
read point-by-point responses
-
Referee: [Section on uncertainty-aware noise schedule] The integration of the time-varying variances from the pre-trained LSNM estimator into the diffusion forward process requires a detailed derivation showing that the marginal distribution q(x_t | x_0) remains tractable or how the training objective is adjusted accordingly. The standard DDPM closed-form relies on fixed beta schedule; a data-dependent schedule may alter the signal-to-noise ratio and necessitate changes to the loss function to avoid bias in the learned reverse process.
Authors: Thank you for this insightful comment. We agree that providing a detailed derivation is important for rigor. In the revised manuscript, we will expand the section on the uncertainty-aware noise schedule with a full derivation in the appendix. Specifically, since the LSNM estimator is pre-trained and provides time-varying variances that are fixed for each time series instance, the noise schedule is computed deterministically from these variances. This allows us to maintain a closed-form expression for q(x_t | x_0) as a Gaussian distribution, where the mean is scaled by the product of (1 - beta_s) terms adjusted for the varying variances, and the variance is the sum of the scaled noise contributions. The training objective is the standard simplified DDPM loss, but with the noise prediction target scaled according to the uncertainty-aware SNR at each timestep to prevent bias. We will include the step-by-step derivation and empirical validation of the adjusted loss to ensure the reverse process is correctly learned. revision: yes
Circularity Check
Derivation chain is self-contained with independent modeling choices
full rationale
The paper introduces NsDiff by relaxing the constant-variance ANM assumption via LSNM, then combines a standard denoising diffusion conditional generative model with a separately pre-trained conditional mean/variance estimator to enable adaptive endpoint distributions. The uncertainty-aware noise schedule is described as dynamically derived from the time-varying variances produced by that estimator and integrated into the diffusion process. No quoted equations or steps reduce the final forecasting distribution or training objective to a fitted parameter by construction, no central premise rests on a self-citation chain that itself lacks independent verification, and no ansatz is smuggled or known result merely renamed. The framework therefore remains self-contained against external benchmarks and receives a score of 0.
Axiom & Free-Parameter Ledger
free parameters (1)
- uncertainty-aware noise schedule parameters
axioms (1)
- domain assumption LSNM relaxes the fixed uncertainty assumption of ANM
Forward citations
Cited by 1 Pith paper
-
Parametric Prior Mapping Framework for Non-stationary Probabilistic Time Series Forecasting
PPM injects parametric structural priors into generative models via a learnable mapping to improve probabilistic forecasts on non-stationary MTS data.
Reference graph
Works this paper leans on
- [1]
-
[2]
Chen, Y ., Goldstein, M., Hua, M., Albergo, M. S., Boffi, N. M., and Vanden-Eijnden, E. Probabilistic forecast- ing with stochastic interpolants and f\” ollmer processes. arXiv preprint arXiv:2403.13724,
-
[3]
Fan, W., Yi, K., Ye, H., Ning, Z., Zhang, Q., and An, N. Deep frequency derivative learning for non-stationary time series forecasting.arXiv preprint arXiv:2407.00502,
-
[4]
Ant: Adaptive noise sched- ule for time series diffusion models.arXiv preprint arXiv:2410.14488,
Lee, S., Lee, K., and Park, T. Ant: Adaptive noise sched- ule for time series diffusion models.arXiv preprint arXiv:2410.14488,
-
[5]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Nie, Y ., Nguyen, N. H., Sinthong, P., and Kalagnanam, J. A time series is worth 64 words: Long-term forecasting with transformers.arXiv preprint arXiv:2211.14730,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
C., De Oliveira, D., Zimbr˜ao, G., Pappa, G
Ogasawara, E., Martinez, L. C., De Oliveira, D., Zimbr˜ao, G., Pappa, G. L., and Mattoso, M. Adaptive normal- ization: A novel data normalization approach for non- stationary time series. InThe 2010 International Joint Conference on Neural Networks (IJCNN), pp. 1–8. IEEE,
work page 2010
-
[7]
Tyralis, H. and Papacharalampous, G. A review of proba- bilistic forecasting and prediction with machine learning. arXiv preprint arXiv:2209.08307,
-
[8]
Koopman neural forecaster for time series with temporal distribution shifts
Wang, R., Dong, Y ., Arik, S.¨O., and Yu, R. Koopman neural forecaster for time series with temporal distribution shifts. arXiv preprint arXiv:2210.03675,
-
[9]
Ordering-based causal discovery for linear and nonlinear relations.arXiv preprint arXiv:2410.05890,
Xu, Z., Li, Y ., Liu, C., and Gui, N. Ordering-based causal discovery for linear and nonlinear relations.arXiv preprint arXiv:2410.05890,
-
[10]
Frequency adaptive normalization for non-stationary time series forecasting
10 Non-stationary Diffusion For Probabilistic Time Series Forecasting Ye, W., Deng, S., Zou, Q., and Gui, N. Frequency adaptive normalization for non-stationary time series forecasting. arXiv preprint arXiv:2409.20371,
-
[11]
arXiv preprint arXiv:2403.01742 , year=
Yuan, X. and Qiao, Y . Diffusion-ts: Interpretable diffu- sion for general time series generation.arXiv preprint arXiv:2403.01742,
-
[12]
Im- proving deep neural networks using softplus units
Zheng, H., Yang, Z., Liu, W., Liang, J., and Li, Y . Im- proving deep neural networks using softplus units. In 2015 International joint conference on neural networks (IJCNN), pp. 1–4. IEEE,
work page 2015
-
[13]
1 2 (µθ − ˜µ)⊤ Σ−1 θ (µθ − ˜µ) + Tr Σ−1 θ ˜Σ −log det( ˜Σ) det (Σθ) −C !# ∝E
To simplify the notation, we further give the following definition: σt = (α2 t −α t + (1−α t))gψ(X) + (αt −α 2 t )σY0 (22) t−1X k=0 tY j=t−k+1 αj (1−α t−k) = (1−α t) +α t(1−α t−1) + (αtαt−1)(1−α t−2) +. . .= 1− tY i=1 αi (23) t−1X k=0 tY j=t−k+1 αj αt−k =α t +α tαt−1 +α tαt−1αt−2 +. . .= t−1X k=0 tY i=t−k αi (24) t−1X k=0 tY j=t−k+1 αj...
-
[14]
Table 8.The comparison between pretraining and end-to-end training,bold faceindicate best result. epoch pretrain end-to-end 1 0.4181 0.4407 2 0.4041 0.4227 3 0.3977 0.4045 4 0.3926 0.4004 5 0.38890.3868 60.37950.3873 As can be seen, although joint train experiences a slight performance degradation (1.86%), it still outperforms the previous state-of-the-ar...
-
[15]
Table 9.Computation efficiency comparison,bold faceindicate best result. Model Mem.Train(MB) Mem.Inference(MB) Tim.Train(ms) Tim.Inference(ms) CRPS QICE TimeGrad 27.47 8.61 47.89 8319.29 0.606 6.731 CSDI 109.81 22.61 60.50 446.70 0.492 3.107 TimeDiff15.66 3.4033.93 238.78 0.465 14.931 DiffusionTS 65.03 79.23 94.51 8214.53 0.603 6.423 TMDM 221.58 213.46 33...
work page 2022
-
[16]
to optimize memory efficiency. C. Reproducibility We provide all relevant data, code, and notebooks athttps://github.com/wwy155/NsDiff. C.1. Datasets C.1.1. REALDATASET Nine real-world datasets with varying levels of uncertainty were chosen, including: (1) Electricity1 - which documents the hourly electricity usage of 321 customers from 2012 to
work page 2012
-
[17]
Centers for Disease Control and Prevention from 2002 to
(2) ILI 2 - which tracks the weekly proportion of influenza-like illness (ILI) patients relative to the total number of patients, as reported by the U.S. Centers for Disease Control and Prevention from 2002 to
work page 2002
-
[18]
- which includes data from electricity transformers, such as load and oil temperature, recorded every 15 minutes between July 2016 and July
work page 2016
-
[19]
- which logs the daily exchange rates of eight countries from 1990 to
work page 1990
-
[20]
(5) Traffic3 - which provides hourly road occupancy rates measured by 862 sensors on San Francisco Bay area freeways from January 2015 to December
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.