Leveraging Large Language Models for Sarcastic Speech Annotation in Sarcasm Detection
Pith reviewed 2026-05-19 11:25 UTC · model grok-4.3
The pith
Large language models can annotate sarcasm in speech data after human review to build scalable detection datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an LLM-driven annotation pipeline, using GPT-4o and LLaMA 3 for first-pass labels followed by targeted human verification, yields sarcasm annotations accurate enough to train and evaluate audio-only detectors; this process produces the PodSarc dataset and a collaborative gating model that reaches 73.63 percent F1 on held-out test material.
What carries the argument
The LLM-plus-human verification annotation pipeline, where two large language models label podcast turns and humans reconcile only the cases of model disagreement.
If this is right
- Speech-only sarcasm detectors become practical without needing video or text context.
- The PodSarc collection can function as a public benchmark for future audio sarcasm research.
- Annotation costs drop because LLMs handle the bulk of labeling and humans review only disagreements.
- Similar pipelines could scale sarcasm data collection beyond the single podcast source used here.
Where Pith is reading between the lines
- The method could be tested on other tonal phenomena such as irony or emotion in speech.
- If the human verification step is replaced by a smaller model trained on the initial disagreements, the pipeline might become fully automated.
- Performance on PodSarc may reveal whether sarcasm cues in podcasts generalize to everyday conversation or broadcast speech.
Load-bearing premise
LLM initial labels reconciled by human checks are accurate enough to serve as ground truth for training and benchmarking speech sarcasm detectors.
What would settle it
A side-by-side comparison in which the same podcast turns are labeled entirely by humans and the resulting detector is retrained; if its F1 score falls substantially below 73.63 percent or label agreement with the LLM-plus-human set is low, the pipeline's reliability claim would be refuted.
Figures

read the original abstract
Sarcasm fundamentally alters meaning through tone and context, yet detecting it in speech remains a challenge due to data scarcity. In addition, existing detection systems often rely on multimodal data, limiting their applicability in contexts where only speech is available. To address this, we propose an annotation pipeline that leverages large language models (LLMs) to generate a sarcasm dataset. Using a publicly available sarcasm-focused podcast, we employ GPT-4o and LLaMA 3 for initial sarcasm annotations, followed by human verification to resolve disagreements. We validate this approach by comparing annotation quality and detection performance on a publicly available sarcasm dataset using a collaborative gating architecture. Finally, we introduce PodSarc, a large-scale sarcastic speech dataset created through this pipeline. The detection model achieves a 73.63% F1 score, demonstrating the dataset's potential as a benchmark for sarcasm detection research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an annotation pipeline that uses GPT-4o and LLaMA 3 to pre-annotate sarcasm in speech from a publicly available podcast, followed by human verification to resolve disagreements between the models. It validates the pipeline by comparing annotation quality and downstream sarcasm detection performance against a public sarcasm dataset, employing a collaborative gating architecture for the detector. The authors introduce PodSarc, a new large-scale sarcastic speech dataset generated via this method, and report that the detection model achieves 73.63% F1, positioning PodSarc as a benchmark for speech sarcasm detection research.
Significance. If the central empirical claims hold, the work provides a practical, scalable hybrid LLM-human pipeline for addressing data scarcity in speech-only sarcasm detection, an area where multimodal approaches have dominated. The external validation on a public dataset and direct comparison of detection performance when training on the new labels versus original labels add credibility. Strengths include the use of two distinct LLMs, explicit reporting of agreement statistics and fraction of cases needing human review, and the creation of PodSarc as a reproducible resource. This could lower barriers for research on tone- and context-dependent phenomena in spoken language.
major comments (2)
- Validation and experimental setup: The configuration of the collaborative gating architecture (e.g., gating mechanism, fusion strategy, hyperparameters, and training details) is not described with sufficient specificity to allow reproduction of the 73.63% F1 result or to evaluate whether the performance gain is attributable to the new labels rather than model tuning. This detail is load-bearing for the claim that the annotation pipeline produces labels suitable for training effective detectors.
- Annotation quality assessment: Although agreement statistics between GPT-4o and LLaMA 3 and the fraction of cases sent to human review are reported, the manuscript lacks a quantitative error analysis (e.g., breakdown of disagreement types or comparison of final labels against a small gold-standard subset). This weakens support for the assumption that the resulting labels are accurate enough to serve as training data for the downstream detector.
minor comments (2)
- Introduction: The discussion of prior speech sarcasm work could include more explicit citations to recent multimodal sarcasm detection papers to better contextualize the speech-only focus.
- Dataset description: The exact scale of PodSarc (total utterances, sarcastic/non-sarcastic split, and any filtering criteria) should be stated numerically in the main text rather than only in supplementary material.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and for the constructive comments that will improve the clarity and reproducibility of the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: Validation and experimental setup: The configuration of the collaborative gating architecture (e.g., gating mechanism, fusion strategy, hyperparameters, and training details) is not described with sufficient specificity to allow reproduction of the 73.63% F1 result or to evaluate whether the performance gain is attributable to the new labels rather than model tuning. This detail is load-bearing for the claim that the annotation pipeline produces labels suitable for training effective detectors.
Authors: We agree that the current description of the collaborative gating architecture is insufficient for full reproducibility. In the revised manuscript we will add a dedicated subsection that specifies the gating mechanism (including how the two modality-specific encoders are combined), the fusion strategy, all hyperparameters (learning rate, batch size, number of epochs, dropout rates, and gating temperature), and the complete training protocol (optimizer, loss function, early stopping criteria, and data splits). These additions will allow readers to reproduce the reported 73.63% F1 and to isolate the contribution of the PodSarc labels from architectural choices. revision: yes
-
Referee: Annotation quality assessment: Although agreement statistics between GPT-4o and LLaMA 3 and the fraction of cases sent to human review are reported, the manuscript lacks a quantitative error analysis (e.g., breakdown of disagreement types or comparison of final labels against a small gold-standard subset). This weakens support for the assumption that the resulting labels are accurate enough to serve as training data for the downstream detector.
Authors: We acknowledge that a quantitative error analysis is currently missing. In the revision we will add a new subsection that (1) categorizes the observed disagreements between GPT-4o and LLaMA 3 into types (e.g., context-dependent vs. tone-dependent sarcasm) and (2) reports agreement between the final human-verified labels and a small expert-annotated gold-standard subset (approximately 200 utterances). This analysis will provide direct quantitative evidence of label quality and will be presented alongside the existing agreement statistics. revision: yes
Circularity Check
No significant circularity in empirical annotation pipeline
full rationale
The paper presents an empirical pipeline: LLM pre-annotation (GPT-4o and LLaMA 3) of sarcasm in podcast speech, human adjudication of disagreements, creation of PodSarc dataset, and downstream validation via detection F1 on a held-out public sarcasm corpus using collaborative gating. No equations, fitted parameters, or derivations appear. Validation relies on external public data and reported agreement statistics rather than any self-referential reduction. The central result (73.63% F1) is not forced by construction from the authors' own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM annotations for sarcasm in speech can be made reliable through human verification of disagreements
invented entities (1)
-
PodSarc
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose an annotation pipeline that leverages large language models (LLMs) to generate a sarcasm dataset... GPT-4o and LLaMA 3 for initial sarcasm annotations, followed by human verification
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The detection model achieves a 73.63% F1 score
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Introduction Sarcasm plays a critical role in communication by convey- ing meaning that deliberately contradicts literal interpretation. The detection of sarcasm presents unique challenges for speech technology, as speakers deploy complex combinations of lex- ical content, prosodic features, and contextual cues to signal sarcastic intent. While humans gen...
-
[2]
compiled from TV shows, include multimodal data and en- able video-level multimodal sarcasm detection. However, these multimodal datasets are limited in size and scope, hindering the development of robust sarcasm detection models. In addition, most existing approaches to detecting sarcasm rely on multimodal feature fusion [2, 6, 7, 8]. However, in real- w...
-
[3]
General emotion detection datasets, such as MELD
Related Work Datasets for sarcasm detection The detection of sarcasm in speech has been limited by the availability of annotated datasets. General emotion detection datasets, such as MELD
-
[4]
Leveraging Large Language Models for Sarcastic Speech Annotation in Sarcasm Detection
and IEMOCAP [17], while rich in their inclusion of emo- tional speech, do not specifically capture the subtleties of sar- casm. While sarcasm can overlap with emotions like anger, joy, or surprise, it possesses distinct features that emotion-focused annotations fail to capture. Existing sarcasm detection datasets like MUStARD [4] and MUStARD++ [5], althou...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
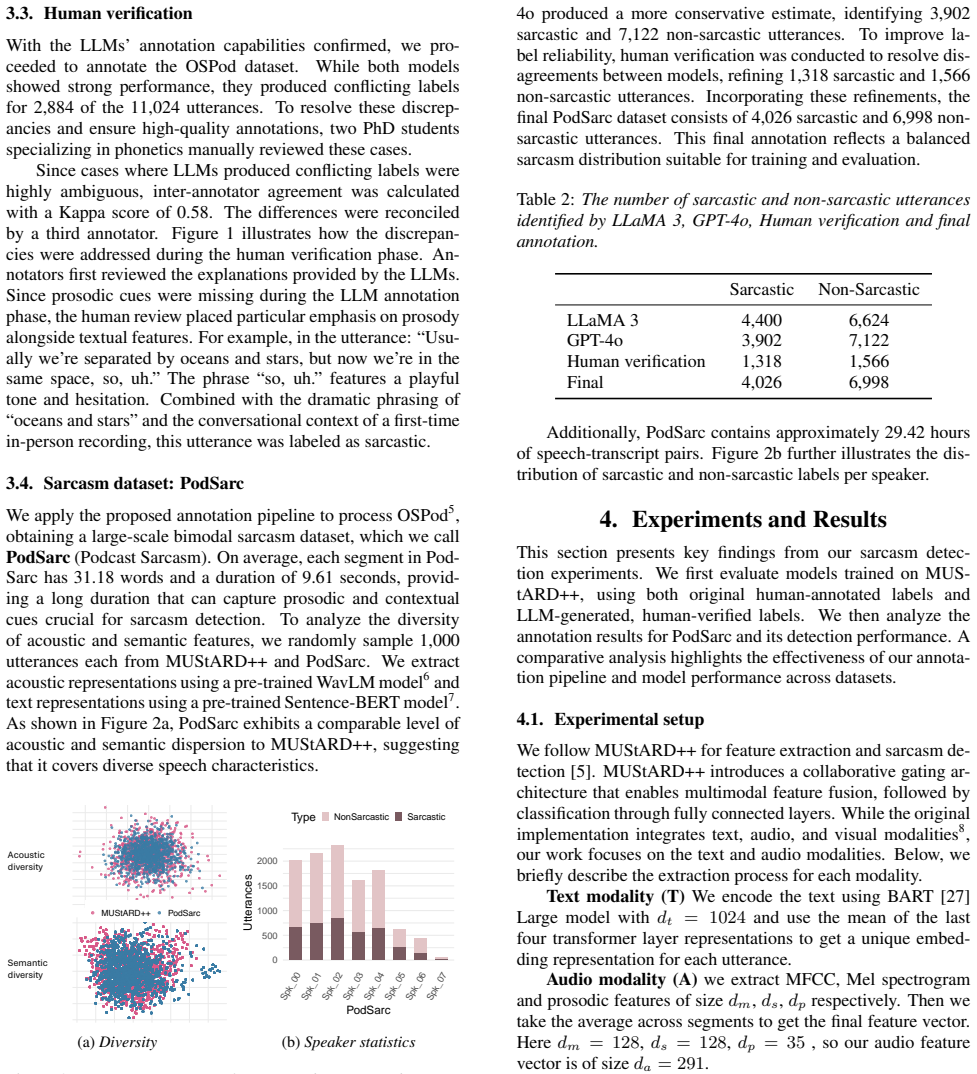
Usu- ally we’re separated by oceans and stars, but now we’re in the same space, so, uh
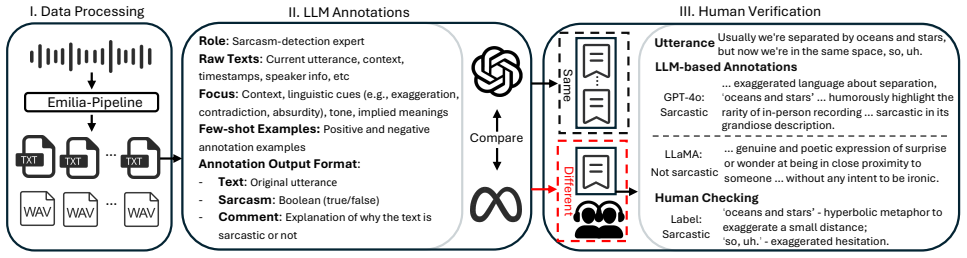
Dataset This study leverages LLMs to accelerate the process of annotat- ing sarcasm in speech data, reducing the reliance on human an- notators and enabling large-scale consistent labeling. As illus- trated in Figure 1, the proposed pipeline consists of three stages: (1) automatic data collection and processing, (2) sarcasm anno- tation using LLMs, and (3...
work page 2000
-
[6]
Experiments and Results This section presents key findings from our sarcasm detec- tion experiments. We first evaluate models trained on MUS- tARD++, using both original human-annotated labels and LLM-generated, human-verified labels. We then analyze the annotation results for PodSarc and its detection performance. A comparative analysis highlights the ef...
work page 2048
-
[7]
Conclusion This work advances sarcasm detection by addressing a funda- mental challenge: the scarcity of large-scale annotated multi- modal datasets. We demonstrate that LLMs can serve as ef- fective tools for identifying sarcastic speech, presenting a novel pipeline that combines the complementary strengths of LLMs with targeted human verification. Apply...
-
[8]
‘sure, i did the right thing’: a system for sarcasm detection in speech
R. Rakov and A. Rosenberg, “‘sure, i did the right thing’: a system for sarcasm detection in speech.” in Interspeech, 2013, pp. 842– 846
work page 2013
-
[9]
Deep CNN-based Inductive Transfer Learning for Sarcasm Detection in Speech,
X. Gao, S. Nayak, and M. Coler, “Deep CNN-based Inductive Transfer Learning for Sarcasm Detection in Speech,” in Proc. In- terspeech 2022, 2022, pp. 2323–2327
work page 2022
-
[10]
Sarcasticspeech: Speech synthesis for sarcasm in low-resource scenarios,
Z. Li, X. Gao, S. Nayak, and M. Coler, “Sarcasticspeech: Speech synthesis for sarcasm in low-resource scenarios,” in 12th ISCA Speech Synthesis Workshop (SSW2023). ISCA, 2023, pp. 242– 243
work page 2023
-
[11]
Towards multimodal sarcasm detection (an Obviously perfect paper),
S. Castro, D. Hazarika, V . P ´erez-Rosas, R. Zimmermann, R. Mihalcea, and S. Poria, “Towards multimodal sarcasm detection (an Obviously perfect paper),” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M `arquez, Eds. Florence, Italy: Association for Computational Linguistics, Jul. ...
work page 2019
-
[12]
A multimodal corpus for emotion recognition in sarcasm,
A. Ray, S. Mishra, A. Nunna, and P. Bhattacharyya, “A multimodal corpus for emotion recognition in sarcasm,” in Pro- ceedings of the Thirteenth Language Resources and Evaluation Conference, N. Calzolari, F. B ´echet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Mae- gaard, J. Mariani, H. Mazo, J. Odijk, and S. Piperidis, Eds. Mar...
work page 2022
-
[13]
Multi-modal sarcasm detection in Twitter with hierarchical fusion model,
Y . Cai, H. Cai, and X. Wan, “Multi-modal sarcasm detection in Twitter with hierarchical fusion model,” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M `arquez, Eds. Florence, Italy: Association for Computational Linguistics, Jul. 2019, pp. 2506–2515. [Online]. Available: https://...
work page 2019
-
[14]
X. Gao, S. Bansal, K. Gowda, Z. Li, S. Nayak, N. Kumar, and M. Coler, “Amused: An attentive deep neural network for multi- modal sarcasm detection incorporating bi-modal data augmenta- tion,”arXiv preprint arXiv:2412.10103, 2024
-
[15]
D. Raghuvanshi, X. Gao, Z. Li, S. Bansal, M. Coler, N. Kumar, and S. Nayak, “Intra-modal relation and emotional incongruity learning using graph attention networks for multimodal sarcasm detection,” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2025, pp. 1–5
work page 2025
-
[16]
Prosodic cues of sarcastic speech in french: slower, higher, wider,
H. Loevenbruck, M. B. Jannet, M. d’Imperio, M. Spini, and M. Champagne-Lavau, “Prosodic cues of sarcastic speech in french: slower, higher, wider,” in Interspeech 2013-14th Annual Conference of the International Speech Communication Associa- tion, 2013, pp. 3537–3541
work page 2013
-
[17]
A functional trade-off between prosodic and semantic cues in conveying sar- casm,
Z. Li, X. Gao, Y . Zhang, S. Nayak, and M. Coler, “A functional trade-off between prosodic and semantic cues in conveying sar- casm,” inProc. Interspeech 2024, 2024, pp. 1070–1074
work page 2024
-
[18]
J. Santoso, K. Ishizuka, and T. Hashimoto, “Large language model-based emotional speech annotation using context and acoustic feature for speech emotion recognition,” in ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2024, pp. 11 026– 11 030
work page 2024
-
[19]
Refashioning emotion recognition modelling: The advent of generalised large models,
Z. Zhang, L. Peng, T. Pang, J. Han, H. Zhao, and B. W. Schuller, “Refashioning emotion recognition modelling: The advent of generalised large models,” IEEE Transactions on Computational Social Systems, 2024
work page 2024
-
[20]
Can pre-trained language models understand chinese humor?
Y . Chen, Z. Li, J. Liang, Y . Xiao, B. Liu, and Y . Chen, “Can pre-trained language models understand chinese humor?” in Pro- ceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, 2023, pp. 465–480
work page 2023
-
[21]
Sarcasm- bench: Towards evaluating large language models on sarcasm un- derstanding,
Y . Zhang, C. Zou, Z. Lian, P. Tiwari, and J. Qin, “Sarcasm- bench: Towards evaluating large language models on sarcasm un- derstanding,”arXiv preprint arXiv:2408.11319, 2024
-
[22]
Is chatgpt equipped with emotional dialogue capabilities?
W. Zhao, Y . Zhao, X. Lu, S. Wang, Y . Tong, and B. Qin, “Is chatgpt equipped with emotional dialogue capabilities?” arXiv preprint arXiv:2304.09582, 2023
-
[23]
Meld: A multimodal multi-party dataset for emo- tion recognition in conversations,
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, and R. Mihalcea, “Meld: A multimodal multi-party dataset for emo- tion recognition in conversations,” inProceedings of the 57th An- nual Meeting of the Association for Computational Linguistics , 2019, pp. 527–536
work page 2019
-
[24]
Iemocap: Interactive emotional dyadic motion capture database,
C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “Iemocap: Interactive emotional dyadic motion capture database,”Language resources and evaluation, vol. 42, pp. 335–359, 2008
work page 2008
-
[25]
Autoprep: An automatic preprocessing framework for in-the-wild speech data,
J. Yu, H. Chen, Y . Bian, X. Li, Y . Luo, J. Tian, M. Liu, J. Jiang, and S. Wang, “Autoprep: An automatic preprocessing framework for in-the-wild speech data,” in ICASSP 2024-2024 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 1136–1140
work page 2024
-
[26]
Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation,
H. He, Z. Shang, C. Wang, X. Li, Y . Gu, H. Hua, L. Liu, C. Yang, J. Li, P. Shiet al., “Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation,” in 2024 IEEE Spoken Language Technology Workshop (SLT). IEEE, 2024, pp. 885–890
work page 2024
-
[27]
Is gpt-3 a good data annotator?
B. Ding, C. Qin, L. Liu, Y . K. Chia, B. Li, S. Joty, and L. Bing, “Is gpt-3 a good data annotator?” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 11 173–11 195
work page 2023
-
[28]
The parrot dilemma: Human-labeled vs. llm-augmented data in classification tasks,
A. G. Møller, A. Pera, J. Dalsgaard, and L. Aiello, “The parrot dilemma: Human-labeled vs. llm-augmented data in classification tasks,” in Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 2: Short Papers), 2024, pp. 179–192
work page 2024
-
[29]
Large language models for data annotation and synthesis: A survey,
Z. Tan, D. Li, S. Wang, A. Beigi, B. Jiang, A. Bhattacharjee, M. Karami, J. Li, L. Cheng, and H. Liu, “Large language models for data annotation and synthesis: A survey,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 930–957
work page 2024
-
[30]
From text to emo- tion: Unveiling the emotion annotation capabilities of llms,
M. Niu, M. Jaiswal, and E. Mower Provost, “From text to emo- tion: Unveiling the emotion annotation capabilities of llms,” in Proc. Interspeech 2024, 2024, pp. 2650–2654
work page 2024
-
[31]
Af- fect recognition in conversations using large language models,
S. Feng, G. Sun, N. Lubis, W. Wu, C. Zhang, and M. Ga ˇsi´c, “Af- fect recognition in conversations using large language models,” arXiv preprint arXiv:2309.12881, 2023
-
[32]
Text classification via large language models,
X. Sun, X. Li, J. Li, F. Wu, S. Guo, T. Zhang, and G. Wang, “Text classification via large language models,” inFindings of the Association for Computational Linguistics: EMNLP 2023 , 2023, pp. 8990–9005
work page 2023
-
[33]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azhar et al. , “Llama: open and efficient foundation language models. arxiv,” arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
M. Lewis, “Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension,” arXiv preprint arXiv:1910.13461, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.