PuckTrick: A Library for Making Synthetic Data More Realistic
Pith reviewed 2026-05-19 07:28 UTC · model grok-4.3
The pith
A library for adding controlled errors to synthetic data improves machine learning model performance on real tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
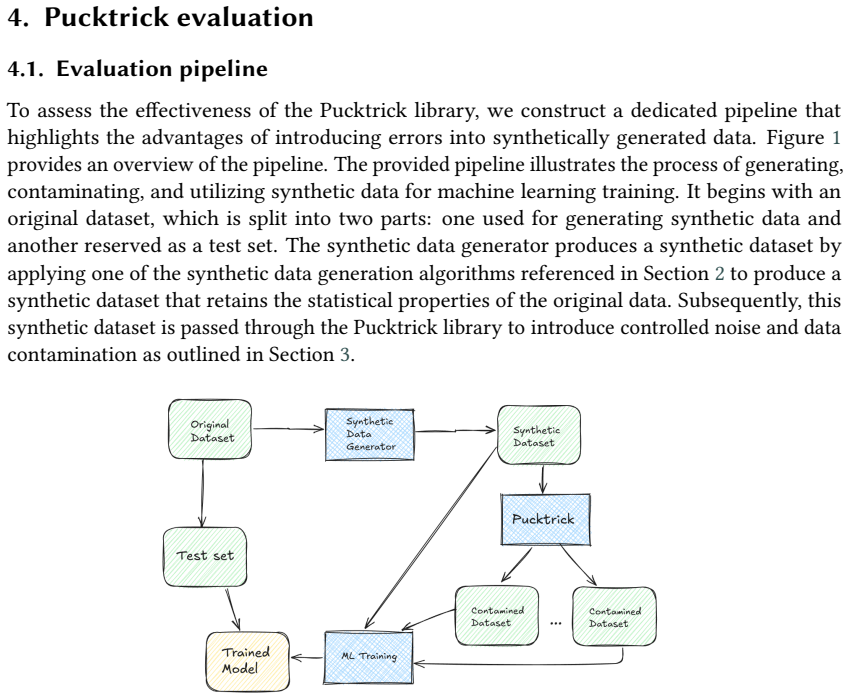
PuckTrick supplies two modes for contaminating synthetic data: one that adds errors to clean datasets and another that further corrupts already imperfect data. When machine learning models are trained on the resulting contaminated synthetic data, they outperform models trained on error-free synthetic data when evaluated on real financial datasets. The improvement appears most clearly for tree-based and linear models such as support vector machines and extra trees.
What carries the argument
The PuckTrick library, which offers structured injection of multiple error types including missing data, noisy values, outliers, label misclassification, duplication, and class imbalance to simulate real-world data imperfections.
If this is right
- Machine learning models achieve higher accuracy on real tasks when trained with systematically contaminated synthetic data.
- Tree-based and linear models such as SVMs and extra trees show the clearest benefits from the added errors.
- Synthetic data generation can be made more effective by incorporating controlled imperfections rather than aiming for perfect cleanliness.
- Evaluation of model resilience becomes more realistic when using contaminated synthetic datasets instead of error-free ones.
- The library supports repeated application of contamination to already imperfect data for further realism.
Where Pith is reading between the lines
- The method could extend to non-financial domains such as medical or sensor data if similar error patterns are introduced.
- Practitioners might integrate PuckTrick into data pipelines to test model robustness before deployment.
- Different error combinations could be tuned to optimize performance for specific model families.
- The results suggest that real-world data noise functions as a natural regularizer that clean synthetic data lacks.
Load-bearing premise
The specific error types and contamination levels chosen accurately reproduce the statistical properties of imperfections that appear in real-world datasets.
What would settle it
Retraining the tested models on contaminated versus clean synthetic data and finding no performance gain or a loss on held-out real financial data would falsify the central claim.
Figures


read the original abstract
The increasing reliance on machine learning (ML) models for decision-making requires high-quality training data. However, access to real-world datasets is often restricted due to privacy concerns, proprietary restrictions, and incomplete data availability. As a result, synthetic data generation (SDG) has emerged as a viable alternative, enabling the creation of artificial datasets that preserve the statistical properties of real data while ensuring privacy compliance. Despite its advantages, synthetic data is often overly clean and lacks real-world imperfections, such as missing values, noise, outliers, and misclassified labels, which can significantly impact model generalization and robustness. To address this limitation, we introduce Pucktrick, a Python library designed to systematically contaminate synthetic datasets by introducing controlled errors. The library supports multiple error types, including missing data, noisy values, outliers, label misclassification, duplication, and class imbalance, offering a structured approach to evaluating ML model resilience under real-world data imperfections. Pucktrick provides two contamination modes: one for injecting errors into clean datasets and another for further corrupting already contaminated datasets. Through extensive experiments on real-world financial datasets, we evaluate the impact of systematic data contamination on model performance. Our findings demonstrate that ML models trained on contaminated synthetic data outperform those trained on purely synthetic, error-free data, particularly for tree-based and linear models such as SVMs and Extra Trees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PuckTrick, a Python library for systematically contaminating synthetic datasets with controlled real-world-like errors including missing values, noise, outliers, label misclassifications, duplications, and class imbalance. It supports two contamination modes and reports experiments on real-world financial datasets claiming that ML models (particularly tree-based and linear models such as SVMs and Extra Trees) trained on the contaminated synthetic data outperform those trained on purely clean synthetic data.
Significance. If the performance gains are rigorously demonstrated, the library would address a practical gap in synthetic data generation by enabling controlled evaluation of model robustness to realistic imperfections, which is valuable for privacy-sensitive domains like finance where clean synthetic data may lead to overly optimistic generalization estimates.
major comments (2)
- [Abstract] Abstract: the central claim that models trained on contaminated synthetic data outperform those trained on error-free synthetic data is stated without any quantitative metrics, error bars, baseline comparisons, or details on how contamination parameters (rates, mechanisms) were selected or calibrated against the real financial datasets; this leaves the performance improvement only weakly supported.
- [Experiments] Experiments on real-world financial datasets: the reported outperformance rests on the unverified assumption that PuckTrick's specific error-injection schedule (missingness patterns, noise covariances, outlier frequencies) statistically matches imperfections in the source real data; without explicit distributional comparisons or calibration, the gains could be an artifact of the chosen contamination rather than evidence that added realism improves generalization.
minor comments (1)
- [Title and Abstract] Inconsistent library name spelling: 'PuckTrick' in the title versus 'Pucktrick' in the abstract.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps clarify how to better support the paper's claims. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that models trained on contaminated synthetic data outperform those trained on error-free synthetic data is stated without any quantitative metrics, error bars, baseline comparisons, or details on how contamination parameters (rates, mechanisms) were selected or calibrated against the real financial datasets; this leaves the performance improvement only weakly supported.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support. In the revised version we will add specific performance metrics from the experiments (e.g., accuracy or F1 improvements for Extra Trees and SVMs with standard deviations across runs) together with a concise statement of the contamination rates and mechanisms employed. This change directly addresses the concern while preserving the abstract's length and focus. revision: yes
-
Referee: [Experiments] Experiments on real-world financial datasets: the reported outperformance rests on the unverified assumption that PuckTrick's specific error-injection schedule (missingness patterns, noise covariances, outlier frequencies) statistically matches imperfections in the source real data; without explicit distributional comparisons or calibration, the gains could be an artifact of the chosen contamination rather than evidence that added realism improves generalization.
Authors: We accept that the manuscript would benefit from greater transparency on parameter selection. PuckTrick is intended to enable controlled injection of realistic imperfections rather than exact distributional replication of any single dataset. We will revise the experiments section to (i) explain the rationale for the chosen rates and mechanisms by reference to documented error characteristics in financial data, and (ii) present a sensitivity analysis across multiple contamination intensities. These additions will show that the observed gains are robust and not an artifact of one particular schedule. revision: yes
Circularity Check
No circularity; empirical results rest on external datasets
full rationale
The paper presents a library for controlled contamination of synthetic data and reports performance comparisons from direct experiments on separate real-world financial datasets. No mathematical derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described claims. The central finding (contaminated synthetic data yielding better model performance) is obtained via standard train/evaluate loops on held-out external data rather than by construction from the library's own inputs or prior self-referential results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Real-world data contains imperfections such as missing values, noise, outliers, and misclassifications that affect ML model generalization.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Pucktrick library ... supports multiple error types, including missing data, noisy values, outliers, label misclassification, duplication, and class imbalance
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments show that training machine learning models on synthetic data with controlled errors ... results in better accuracy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Measuring the Sensitivity of Classification Models with the Error Sensitivity Profile
ESP measures model sensitivity to feature errors and shows performance drops are not always predictable from simple target correlations.
Reference graph
Works this paper leans on
-
[1]
A. Paleyes, R.-G. Urma, N. D. Lawrence, Challenges in deploying machine learning: a survey of case studies, ACM computing surveys 55 (2022) 1–29
work page 2022
-
[2]
A. Figueira, B. Vaz, Survey on synthetic data generation, evaluation methods and gans, Mathematics 10 (2022) 2733
work page 2022
-
[3]
K. S, M. Durgadevi, Generative adversarial network (gan): a general review on different vari- ants of gan and applications, in: 2021 6th International Conference on Communication and Electronics Systems (ICCES), 2021, pp. 1–8. doi:10.1109/ICCES51350.2021.9489160
- [4]
-
[5]
F. Liu, D. Panagiotakos, Real-world data: a brief review of the methods, applications, challenges and opportunities, BMC Medical Research Methodology 22 (2022) 287
work page 2022
-
[6]
S. Iskander, N. Cohen, Z. Karnin, O. Shapira, S. Tolmach, Quality matters: Evaluating synthetic data for tool-using llms, arXiv preprint arXiv:2409.16341 (2024)
- [7]
- [8]
-
[9]
Tabular and latent space synthetic data generation: a literature review , Ty =
J. Fonseca, F. Bacao, Tabular and latent space synthetic data generation: a literature review, Journal of Big Data 10 (2023) 115. URL: https://doi.org/10.1186/s40537-023-00792-7. doi:10.1186/s40537-023-00792-7
-
[10]
L. Xu, M. Skoularidou, A. Cuesta-Infante, K. Veeramachaneni, Modeling tabular data using conditional gan, in: Advances in Neural Information Processing Systems (NeurIPS), volume 32, 2019, p. 1049
work page 2019
-
[11]
V. Borisov, K. Seßler, T. Leemann, M. Pawelczyk, G. Kasneci, Language models are realistic tabular data generators, in: The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023, OpenReview.net, 2023. URL: https://openreview.net/forum?id=cEygmQNOeI
work page 2023
- [12]
- [13]
- [14]
-
[15]
T. Milne, A. I. Nachman, Wasserstein gans with gradient penalty compute congested transport, in: P.-L. Loh, M. Raginsky (Eds.), Proceedings of Thirty Fifth Conference on Learning Theory, volume 178 of Proceedings of Machine Learning Research, PMLR, 2022, pp. 103–129. URL: https://proceedings.mlr.press/v178/milne22a.html
work page 2022
- [16]
-
[17]
H. H. Rashidi, S. Albahra, B. P. Rubin, B. Hu, A novel and fully automated platform for synthetic tabular data generation and validation, Scientific Reports 14 (2024) 23312
work page 2024
-
[18]
Q. Liu, M. Khalil, J. Jovanovic, R. Shakya, Scaling while privacy preserving: A comprehen- sive synthetic tabular data generation and evaluation in learning analytics, in: Proceedings of the 14th Learning Analytics and Knowledge Conference, 2024, pp. 620–631
work page 2024
-
[19]
N. Natarajan, I. S. Dhillon, P. K. Ravikumar, A. Tewari, Learning with noisy labels, in: C. Burges, L. Bottou, M. Welling, Z. Ghahramani, K. Weinberger (Eds.), Advances in Neural Information Processing Systems, volume 26, Curran As- sociates, Inc., 2013. URL: https://proceedings.neurips.cc/paper_files/paper/2013/file/ 3871bd64012152bfb53fdf04b401193f-Paper.pdf
work page 2013
-
[20]
T. Emmanuel, T. Maupong, D. Mpoeleng, T. Semong, E. Tabane, M. Velempini, A survey on missing data in machine learning, Journal of Big Data 8 (2021) 140. URL: https://doi. org/10.1186/s40537-021-00516-9. doi: 10.1186/s40537-021-00516-9
-
[21]
A. Boukerche, L. Zheng, O. Alfandi, Outlier detection: Methods, models, and classifica- tion, ACM Computing Surveys (CSUR) 53 (2020) 55:1–55:37. URL: https://doi.org/10.1145/ 3381028. doi:10.1145/3381028
- [22]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.