MAGIC: Few-Shot Mask-Guided Anomaly Inpainting with Prompt Perturbation, Spatially Adaptive Guidance, and Context Awareness
Pith reviewed 2026-05-19 05:51 UTC · model grok-4.3
The pith
MAGIC generates high-fidelity anomalies that strictly follow given masks while maximizing in-distribution diversity through prompt perturbation, adaptive guidance, and mask alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
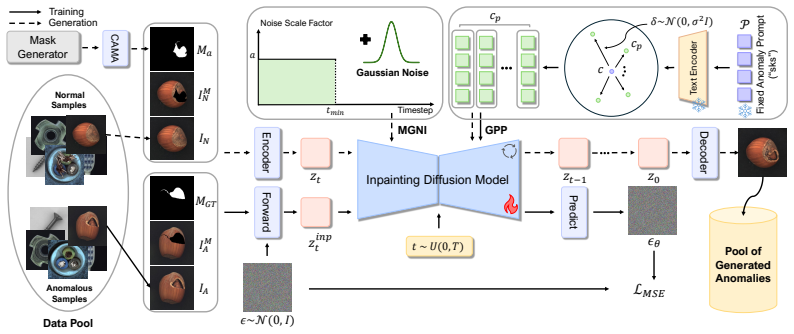
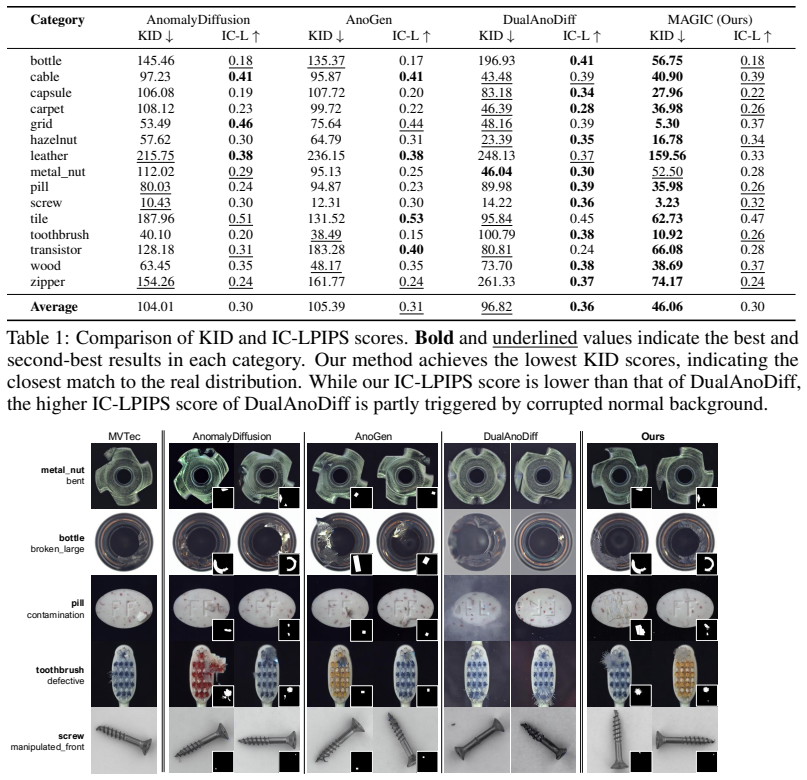
MAGIC is a fine-tuned inpainting framework that generates high-fidelity anomalies adhering strictly to the mask while maximizing in-distribution diversity. It achieves this by learning and sampling from a smooth manifold of realistic anomalies via Gaussian prompt perturbation, applying distinct guidance strengths to anomaly versus background regions through spatially adaptive guidance, and relocating masks for plausible placement via context-aware mask alignment. Under consistent identical evaluation protocol, this combination outperforms state-of-the-art methods on diverse anomaly datasets in downstream tasks.
What carries the argument
The MAGIC fine-tuned inpainting diffusion framework that combines Gaussian prompt perturbation, spatially adaptive guidance, and context-aware mask alignment.
If this is right
- Downstream anomaly detection models achieve higher performance when trained using MAGIC-generated data instead of data from earlier methods.
- Generated anomalies remain confined to the supplied mask and leave surrounding normal regions unchanged.
- The framework supports effective anomaly creation even when only a small number of real anomaly examples are available for fine-tuning.
- Consistent gains appear across multiple distinct industrial anomaly datasets when evaluation conditions are held identical.
Where Pith is reading between the lines
- The same combination of perturbation and region-specific guidance could be tested for controlled object insertion or defect simulation in non-industrial image domains such as medical or satellite imagery.
- Learning a smooth manifold of anomalies may reduce overfitting risks that appear when diffusion models are fine-tuned on very small sets of real defects.
- The mask-alignment step suggests a general route for making synthetic data respect object geometry, which could be measured by checking whether generated anomalies respect expected lighting and texture continuity at mask boundaries.
Load-bearing premise
The three components together produce anomalies that are both strictly mask-adherent and maximally in-distribution diverse without corrupting normal regions.
What would settle it
A controlled replication under the same evaluation protocol in which models trained on MAGIC-generated anomalies show no accuracy improvement over those trained on data from prior state-of-the-art methods.
Figures



read the original abstract
Few-shot anomaly generation is a key challenge in industrial quality control. Although diffusion models are promising, existing methods struggle: global prompt-guided approaches corrupt normal regions, and existing inpainting-based methods often lack the in-distribution diversity essential for robust downstream models. We propose MAGIC, a fine-tuned inpainting framework that generates high-fidelity anomalies that strictly adhere to the mask while maximizing this diversity. MAGIC introduces three complementary components: (i) Gaussian prompt perturbation, which prevents model overfitting in the few-shot setting by learning and sampling from a smooth manifold of realistic anomalies, (ii) spatially adaptive guidance that applies distinct guidance strengths to the anomaly and background regions, and (iii) context-aware mask alignment to relocate masks for plausible placement within the host object. Under consistent identical evaluation protocol, MAGIC outperforms state-of-the-art methods on diverse anomaly datasets in downstream tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MAGIC, a fine-tuned diffusion-based inpainting framework for few-shot anomaly generation in industrial images. It introduces three components—Gaussian prompt perturbation to sample from a smooth manifold of anomalies and avoid overfitting, spatially adaptive guidance with distinct strengths for anomaly versus background regions, and context-aware mask alignment that relocates masks to plausible positions within the host object—to produce high-fidelity anomalies that strictly adhere to the mask while maximizing in-distribution diversity. The central claim is that, under a consistent identical evaluation protocol, MAGIC outperforms state-of-the-art methods on diverse anomaly datasets when used for downstream tasks.
Significance. If the outperformance claims hold under a truly identical protocol, the work would offer a practical advance for few-shot anomaly synthesis in quality control, addressing limitations of global prompt guidance (normal-region corruption) and prior inpainting methods (insufficient diversity). The design choices are motivated and the emphasis on mask adherence plus diversity is a clear strength; reproducible code or parameter-free derivations are not mentioned but would further strengthen the contribution if present.
major comments (2)
- [Abstract and §3] Abstract and §3 (method description): The central claim of outperformance 'under consistent identical evaluation protocol' is load-bearing. Component (iii) explicitly relocates masks 'for plausible placement within the host object.' If baselines were evaluated on the original (unrelocated) masks while MAGIC uses relocated ones, the generated anomalies occupy different spatial contexts; downstream gains could then stem from easier placement rather than superior inpainting fidelity or diversity. This must be clarified with explicit confirmation that all methods were re-evaluated under the same relocated-mask protocol, or the comparison re-run accordingly.
- [§4] §4 (experiments): The abstract asserts quantitative outperformance on downstream tasks, yet the soundness assessment notes the absence of specific metrics, ablation studies, error bars, or dataset details in the provided text. To support the claim that the three components together produce strictly mask-adherent and maximally diverse anomalies, the manuscript must include ablations isolating each component's contribution and statistical significance tests under the identical protocol.
minor comments (2)
- [§3] Notation for the Gaussian prompt perturbation scale and spatially adaptive guidance strengths should be defined explicitly with symbols and ranges in §3 to aid reproducibility.
- [Figures] Figure captions for qualitative results should explicitly state whether masks shown are original or relocated to avoid reader confusion about the protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below and have revised the paper accordingly to strengthen the presentation of our evaluation protocol and experimental results.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method description): The central claim of outperformance 'under consistent identical evaluation protocol' is load-bearing. Component (iii) explicitly relocates masks 'for plausible placement within the host object.' If baselines were evaluated on the original (unrelocated) masks while MAGIC uses relocated ones, the generated anomalies occupy different spatial contexts; downstream gains could then stem from easier placement rather than superior inpainting fidelity or diversity. This must be clarified with explicit confirmation that all methods were re-evaluated under the same relocated-mask protocol, or the comparison re-run accordingly.
Authors: We thank the referee for raising this critical point on protocol consistency. All baseline methods were indeed re-evaluated under the identical protocol that incorporates the context-aware mask alignment step, ensuring that masks are relocated to plausible positions within the host object for every method. This was done to isolate the contributions of inpainting fidelity and diversity rather than mask placement. We have added explicit confirmation of this uniform protocol in the revised abstract, Section 3, and a new paragraph in Section 4.1, along with pseudocode in the supplement describing the shared preprocessing. revision: yes
-
Referee: [§4] §4 (experiments): The abstract asserts quantitative outperformance on downstream tasks, yet the soundness assessment notes the absence of specific metrics, ablation studies, error bars, or dataset details in the provided text. To support the claim that the three components together produce strictly mask-adherent and maximally diverse anomalies, the manuscript must include ablations isolating each component's contribution and statistical significance tests under the identical protocol.
Authors: We agree that the experimental section requires expansion to fully support the claims. The revised manuscript now includes: specific quantitative metrics (e.g., AUROC, AUPRC) for the downstream anomaly detection tasks; comprehensive ablations in Section 4.3 that isolate the contribution of Gaussian prompt perturbation, spatially adaptive guidance, and context-aware mask alignment individually and in combination; error bars computed over five independent runs with different random seeds; and statistical significance testing (paired t-tests with p-values reported) under the identical evaluation protocol. Dataset details, including image counts and anomaly types, have also been expanded in Section 4.1. revision: yes
Circularity Check
No circularity: method components are independent design choices
full rationale
The paper presents MAGIC as a fine-tuned inpainting framework whose three components—Gaussian prompt perturbation, spatially adaptive guidance, and context-aware mask alignment—are introduced as complementary, independent modifications to achieve mask-adherent yet diverse anomalies. No equations, fitted parameters, or derivation steps are shown that reduce the claimed diversity, fidelity, or downstream outperformance to quantities defined by the inputs themselves. The outperformance claim rests on empirical evaluation under a stated consistent protocol rather than any self-referential construction or self-citation chain, rendering the central argument self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- Gaussian prompt perturbation scale
- Spatially adaptive guidance strengths
axioms (2)
- domain assumption Fine-tuned diffusion inpainting models can generate anomalies that strictly respect a binary mask.
- ad hoc to paper Prompt perturbation prevents overfitting when only a few anomaly examples are available.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MAGIC introduces three complementary components: (i) Gaussian prompt perturbation... (ii) spatially adaptive guidance... (iii) context-aware mask alignment to relocate masks...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose MAGIC... fine-tunes a Stable Diffusion inpainting backbone...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
One-to-More: High-Fidelity Training-Free Anomaly Generation with Attention Control
O2MAG generates high-fidelity text-guided anomalies from a single image without training by manipulating self-attention in diffusion models with anomaly masks and dual enhancements.
Reference graph
Works this paper leans on
-
[1]
Anomalycontrol: Few-shot anomaly generation by controlnet inpainting
Musawar Ali, Nicola Fioraio, Samuele Salti, and Luigi Di Stefano. Anomalycontrol: Few-shot anomaly generation by controlnet inpainting. IEEE Access, 12:192903–192914, 2024
work page 2024
-
[2]
Mvtec ad–a comprehensive real- world dataset for unsupervised anomaly detection
Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. Mvtec ad–a comprehensive real- world dataset for unsupervised anomaly detection. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9592–9600, 2019
work page 2019
-
[3]
Mikolaj Binkowski, Danica J. Sutherland, Michal Arbel, and Arthur Gretton. Demystifying mmd gans. ArXiv, abs/1801.01401, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2014
work page 2014
-
[5]
Hong, Li Niu, and Liqing Zhang
Yuxuan Duan, Y . Hong, Li Niu, and Liqing Zhang. Few-shot defect image generation via defect-aware feature manipulation. In AAAI Conference on Artificial Intelligence, 2023
work page 2023
-
[6]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. ArXiv, abs/2208.01618, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Few-shot anomaly-driven generation for anomaly classification and segmentation
Guan Gui, Bin-Bin Gao, Jun Liu, Chengjie Wang, and Yunsheng Wu. Few-shot anomaly-driven generation for anomaly classification and segmentation. In European Conference on Computer Vision (ECCV), 2024
work page 2024
-
[8]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016. doi: 10.1109/CVPR.2016.90
-
[9]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, Günter Klambauer, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a nash equilibrium. ArXiv, abs/1706.08500, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Anomalydiffusion: Few-shot anomaly image generation with diffusion model
Teng Hu, Jiangning Zhang, Ran Yi, Yuzhen Du, Xu Chen, Liang Liu, Yabiao Wang, and Chengjie Wang. Anomalydiffusion: Few-shot anomaly image generation with diffusion model. In AAAI Conference on Artificial Intelligence, 2023
work page 2023
-
[11]
Dual-interrelated diffusion model for few-shot anomaly image generation
Ying Jin, Jinlong Peng, Qingdong He, Teng Hu, Jiafu Wu, Hao Chen, Haoxuan Wang, Wenbing Zhu, Mingmin Chi, Jun Liu, and Yabiao Wang. Dual-interrelated diffusion model for few-shot anomaly image generation. arXiv preprint arXiv:2408.13509, 2024
-
[12]
Training generative adversarial networks with limited data
Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Training generative adversarial networks with limited data. Advances in Neural Information Processing Systems, 33:12104–12114, 2020
work page 2020
-
[13]
Analyzing and improving the image quality of stylegan
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8107–8116, 2020
work page 2020
-
[14]
On Convergence and Stability of GANs
Naveen Kodali, Jacob D. Abernethy, James Hays, and Zsolt Kira. How to train your dragan. ArXiv, abs/1705.07215, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Multi-concept customization of text-to-image diffusion
Nupur Kumari, Bin Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi-concept customization of text-to-image diffusion. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1931–1941, 2022. 10
work page 1931
-
[16]
Cutpaste: Self-supervised learning for anomaly detection and localization
Chun-Liang Li, Kihyuk Sohn, Jinsung Yoon, and Tomas Pfister. Cutpaste: Self-supervised learning for anomaly detection and localization. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9659–9669, 2021
work page 2021
-
[17]
Dongyun Lin, Yanpeng Cao, Wenbin Zhu, and Yiqun Li. Few-shot defect segmentation leveraging abundant normal training samples through normal background regularization and crop-and-paste operation. ArXiv, abs/2007.09438, 2020
-
[18]
A comprehensive augmentation framework for anomaly detection
Jiang Lin and Yaping Yan. A comprehensive augmentation framework for anomaly detection. In AAAI Conference on Artificial Intelligence, volume 38, pages 8742–8749, 2024
work page 2024
-
[19]
Pd-gan: Probabilistic diverse gan for image inpainting
Hongyu Liu, Ziyu Wan, Wei Huang, Yibing Song, Xintong Han, and Jing Liao. Pd-gan: Probabilistic diverse gan for image inpainting. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9367–9376, 2021
work page 2021
-
[20]
Mescheder, Andreas Geiger, and Sebastian Nowozin
Lars M. Mescheder, Andreas Geiger, and Sebastian Nowozin. Which training methods for gans do actually converge? In International Conference on Machine Learning, 2018
work page 2018
-
[21]
Glide: Towards photorealistic image generation and editing with text-guided diffusion models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. In International Conference on Machine Learning, 2021
work page 2021
-
[22]
Defect image sample generation with gan for improving defect recognition
Shuanlong Niu, Bin Li, Xinggang Wang, and Hui Lin. Defect image sample generation with gan for improving defect recognition. IEEE Transactions on Automation Science and Engineering, PP:1–12, 02 2020
work page 2020
-
[23]
Efros, Yong Jae Lee, Eli Shechtman, and Richard Zhang
Utkarsh Ojha, Yijun Li, Jingwan Lu, Alexei A. Efros, Yong Jae Lee, Eli Shechtman, and Richard Zhang. Few-shot image generation via cross-domain correspondence. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10738–10747, 2021
work page 2021
-
[24]
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Russell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang-Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nicolas Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patrick Laba...
work page 2023
-
[25]
U2-net: Going deeper with nested u-structure for salient object detection
Xuebin Qin, Zichen Zhang, Chenyang Huang, Masood Dehghan, Osmar R Zaiane, and Martin Jägersand. U2-net: Going deeper with nested u-structure for salient object detection. Pattern Recognition, 106:107404, 2020
work page 2020
-
[26]
Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer
Robin Rombach, A. Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10674–10685, 2021
work page 2021
-
[27]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Nassir Navab, Joachim Hornegger, William M. Wells, and Alejandro F. Frangi, editors, Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pages 234–241, Cham, 2015. Springer International Publishing. ISBN 978-3-319-24574-4
work page 2015
-
[28]
Towards total recall in industrial anomaly detection
Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Scholkopf, Thomas Brox, and Peter Gehler. Towards total recall in industrial anomaly detection. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14298–14308, 2022
work page 2022
-
[29]
Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10694, 2023
work page 2023
- [30]
-
[31]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L. Denton, Seyed Kam- yar Seyed Ghasemipour, Burcu Karagol Ayan, Seyedeh Sara Mahdavi, Raphael Gontijo Lopes, Tim Salimans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. ArXiv, abs/2205.11487, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Defectfill: Realistic defect generation with inpainting diffusion model for visual inspection
Jaewoo Song, Daemin Park, Kanghyun Baek, Sangyub Lee, Jooyoung Choi, Eunji Kim, and Sungroh Yoon. Defectfill: Realistic defect generation with inpainting diffusion model for visual inspection. ArXiv, abs/2503.13985, 2025. 11
-
[33]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv:2010.02502, October 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[34]
Diverse image inpainting with normalizing flow
Cairong Wang, Yiming Zhu, and Chun Yuan. Diverse image inpainting with normalizing flow. InEuropean Conference on Computer Vision, 2022
work page 2022
-
[35]
Mask-guided generation method for industrial de- fect images with non-uniform structures
Jing Wei, Zhengtao Zhang, Fei Shen, and Chengkan Lv. Mask-guided generation method for industrial de- fect images with non-uniform structures. Machines, 10(12):1239, 2022. doi: 10.3390/machines10121239
-
[36]
Draem – a discriminatively trained reconstruction embedding for surface anomaly detection
Vitjan Zavrtanik, Matej Kristan, and Danijel Skocaj. Draem – a discriminatively trained reconstruction embedding for surface anomaly detection. IEEE/CVF International Conference on Computer Vision (ICCV), pages 8310–8319, 2021
work page 2021
-
[37]
Defect-gan: High-fidelity defect synthesis for automated defect inspection
Gongjie Zhang, Kaiwen Cui, Tzu-Yi Hung, and Shijian Lu. Defect-gan: High-fidelity defect synthesis for automated defect inspection. IEEE Winter Conference on Applications of Computer Vision (WACV), pages 2523–2533, 2021
work page 2021
-
[38]
Wang, Zhineng Chen, and Yu-Gang Jiang
Hui Min Zhang, Zuxuan Wu, Z. Wang, Zhineng Chen, and Yu-Gang Jiang. Prototypical residual networks for anomaly detection and localization.IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16281–16291, 2022
work page 2022
-
[39]
Telling left from right: Identifying geometry-aware semantic correspondence
Junyi Zhang, Charles Herrmann, Junhwa Hur, Eric Chen, Varun Jampani, Deqing Sun, and Ming-Hsuan Yang. Telling left from right: Identifying geometry-aware semantic correspondence. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[40]
Lingrui Zhang, Shuheng Zhang, Guoyang Xie, Jiaqi Liu, Hua Yan, Jinbao Wang, Feng Zheng, and Yaochu Jin. What makes a good data augmentation for few-shot unsupervised image anomaly detection? In IEEE/CVF conference on computer vision and pattern recognition, pages 4345–4354, 2023
work page 2023
-
[41]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. IEEE/CVF International Conference on Computer Vision (ICCV), pages 3813–3824, 2023
work page 2023
-
[42]
Dreamdistribution: Learning prompt distribution for diverse in-distribution generation
Brian Nlong Zhao, Yuhang Xiao, Jiashu Xu, Xinyang Jiang, Yifan Yang, Dongsheng Li, Laurent Itti, Vibhav Vineet, and Yunhao Ge. Dreamdistribution: Learning prompt distribution for diverse in-distribution generation. In Proceedings of the International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[43]
Few-shot image generation with diffusion models
Fanbo Zhu, Zekun Liu, Yue Zhang, and Ziwei Liu. Few-shot image generation with diffusion models. arXiv preprint arXiv:2210.04584, 2022. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.