BlindGuard: Safeguarding LLM-based Multi-Agent Systems under Unknown Attacks
Pith reviewed 2026-05-18 23:34 UTC · model grok-4.3
The pith
An unsupervised method can safeguard multi-agent LLM systems against unknown attacks by learning solely from normal agent interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a hierarchical agent encoder capturing individual, neighborhood, and global interaction patterns combined with a corruption-guided detector consisting of directional noise injection and contrastive learning allows effective training solely on normal agent behaviors for detecting malicious agents across diverse attack types and communication patterns with superior generalizability to supervised baselines.
What carries the argument
The hierarchical agent encoder and corruption-guided detector with directional noise injection and contrastive learning that together enable learning a detection model from normal behaviors alone.
If this is right
- Detects prompt injection, memory poisoning, and tool attacks in multi-agent LLM systems.
- Applies effectively to systems with various communication patterns.
- Provides better generalizability than supervised detection methods.
- Functions without any attack-specific labels or prior knowledge.
Where Pith is reading between the lines
- This method could enable ongoing security in evolving threat environments without the need to gather new labeled attack data for each emerging threat.
- The contrastive approach on corrupted normal data may generalize to anomaly detection in other collaborative or distributed AI setups.
Load-bearing premise
Patterns learned from normal agent behaviors using directional noise injection and contrastive learning will reliably separate unknown malicious behaviors without exposure to attack examples.
What would settle it
If a new attack type or communication pattern not present in the normal training data causes the detector to fail in identifying malicious agents at rates better than chance or supervised alternatives.
Figures






read the original abstract
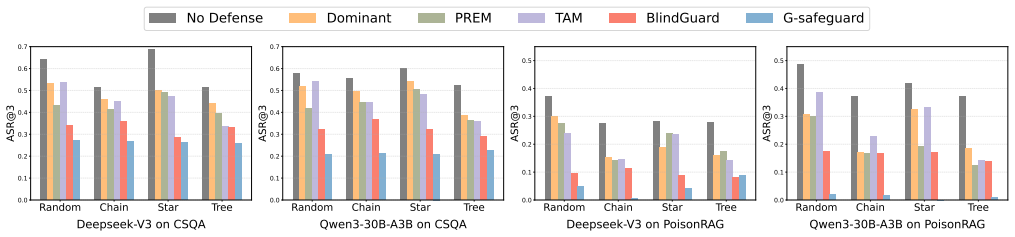
The security of LLM-based multi-agent systems (MAS) is critically threatened by propagation vulnerability, where malicious agents can distort collective decision-making through inter-agent message interactions. While existing supervised defense methods demonstrate promising performance, they may be impractical in real-world scenarios due to their heavy reliance on labeled malicious agents to train a supervised malicious detection model. To enable practical and generalizable MAS defenses, in this paper, we propose BlindGuard, an unsupervised defense method that learns without requiring any attack-specific labels or prior knowledge of malicious behaviors. To this end, we establish a hierarchical agent encoder to capture individual, neighborhood, and global interaction patterns of each agent, providing a comprehensive understanding for malicious agent detection. Meanwhile, we design a corruption-guided detector that consists of directional noise injection and contrastive learning, allowing effective detection model training solely on normal agent behaviors. Extensive experiments show that BlindGuard effectively detects diverse attack types (i.e., prompt injection, memory poisoning, and tool attack) across MAS with various communication patterns while maintaining superior generalizability compared to supervised baselines. The code is available at: https://github.com/MR9812/BlindGuard.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BlindGuard, an unsupervised defense for LLM-based multi-agent systems (MAS) against unknown attacks including prompt injection, memory poisoning, and tool attacks. It introduces a hierarchical agent encoder capturing individual, neighborhood, and global interaction patterns, paired with a corruption-guided detector that applies directional noise injection and contrastive learning trained solely on normal agent behaviors. Experiments are reported to show effective detection across MAS with varied communication patterns and superior generalizability relative to supervised baselines, with code released.
Significance. If the central results hold, the work offers a practical unsupervised alternative to label-dependent supervised defenses, addressing propagation vulnerabilities in MAS where attack-specific data is unavailable. The emphasis on generalizability and the public code release are positive for reproducibility and real-world applicability.
major comments (2)
- [corruption-guided detector and hierarchical encoder sections] The soundness of the central claim rests on the corruption-guided detector (directional noise injection + contrastive learning) producing a decision boundary that separates real unknown attacks. This requires that attack-induced deviations in the hierarchical embeddings align with the directions and magnitudes of the injected noise; if attacks produce orthogonal or higher-order changes in inter-agent patterns, the unsupervised objective trained only on corrupted normals will not generalize. The manuscript provides no explicit analysis (e.g., embedding visualizations, cosine similarity distributions, or ablation on noise directionality) to verify this alignment for the three attack types.
- [Experiments section] The abstract and experimental claims of 'superior generalizability' and effective detection across communication patterns require stronger statistical grounding. Details on the number of independent runs, variance reporting, significance tests against baselines, and whether baselines were re-implemented with the same hierarchical encoder are needed to rule out confounding from hyperparameter tuning or dataset-specific effects.
minor comments (2)
- [Abstract] The abstract states results for 'MAS with various communication patterns' but does not enumerate or define those patterns; adding a brief taxonomy or reference to the experimental setup would improve clarity.
- [Method] Notation for the hierarchical representations (individual/neighborhood/global) should be introduced with explicit equations or a diagram early in the method section to aid readers in following the contrastive loss formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of our work. We address each major comment below.
read point-by-point responses
-
Referee: [corruption-guided detector and hierarchical encoder sections] The soundness of the central claim rests on the corruption-guided detector (directional noise injection + contrastive learning) producing a decision boundary that separates real unknown attacks. This requires that attack-induced deviations in the hierarchical embeddings align with the directions and magnitudes of the injected noise; if attacks produce orthogonal or higher-order changes in inter-agent patterns, the unsupervised objective trained only on corrupted normals will not generalize. The manuscript provides no explicit analysis (e.g., embedding visualizations, cosine similarity distributions, or ablation on noise directionality) to verify this alignment for the three attack types.
Authors: We agree that explicit verification of the alignment between attack-induced embedding deviations and the injected noise directions would strengthen the central claim. Although the manuscript demonstrates effective detection across prompt injection, memory poisoning, and tool attacks through extensive experiments, it does not include supporting analyses such as visualizations or ablations. In the revised manuscript we will add t-SNE visualizations of hierarchical embeddings for normal versus attacked agents, cosine similarity distributions comparing corrupted normal samples to real attacks, and an ablation on noise directionality to show that the contrastive objective captures the relevant deviations for all three attack types. revision: yes
-
Referee: [Experiments section] The abstract and experimental claims of 'superior generalizability' and effective detection across communication patterns require stronger statistical grounding. Details on the number of independent runs, variance reporting, significance tests against baselines, and whether baselines were re-implemented with the same hierarchical encoder are needed to rule out confounding from hyperparameter tuning or dataset-specific effects.
Authors: We appreciate the call for stronger statistical grounding. Our original experiments used 5 independent runs per setting with results reported as means, but we did not include formal significance tests or explicit clarification on baseline re-implementations. In the revision we will report the exact number of runs and variances, add paired t-tests against baselines to establish statistical significance, and confirm that supervised baselines were re-implemented with the same hierarchical encoder to ensure fair comparison and rule out confounding from hyperparameter or dataset effects. revision: yes
Circularity Check
No circularity: unsupervised contrastive pipeline is self-contained and does not reduce to fitted inputs or self-citations
full rationale
The paper presents BlindGuard as an unsupervised defense that trains a hierarchical agent encoder on normal behaviors and applies a corruption-guided detector consisting of directional noise injection plus contrastive learning. No equations are shown that define the detection decision boundary or anomaly score as a direct function of parameters fitted from attack data; the method is described as learning representations exclusively from normal agent interactions augmented with noise, then flagging deviations at inference time. The central claim of generalizability to unknown attacks (prompt injection, memory poisoning, tool attacks) is framed as an empirical outcome verified through experiments across communication patterns, not as a mathematical identity or self-referential fit. Any self-citations to prior supervised work are peripheral and not invoked as a uniqueness theorem or load-bearing justification for the unsupervised premise. The derivation chain therefore remains independent of the target malicious behaviors and does not collapse by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- noise injection parameters
axioms (1)
- domain assumption Normal agent interaction patterns contain sufficient statistical structure to separate unknown malicious deviations via contrastive learning
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hierarchical agent encoder to capture individual, neighborhood, and global interaction patterns
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
CASPIAN: Online Detection and Attribution of Cascade Attacks in LLM Multi-Agent Systems via Cross-Channel Causal Monitoring
CASPIAN introduces unified cross-channel causal monitoring via late-interaction conditional transfer entropy to detect cascade onset and attribute origin, bridge, and amplifier agents in LLM multi-agent systems.
-
FlowSteer: Prompt-Only Workflow Steering Exposes Planning-Time Vulnerabilities in Multi-Agent LLM Systems
FlowSteer is a prompt-only attack that biases multi-agent LLM workflow planning to propagate malicious signals, raising success rates by up to 55%, with FlowGuard as an input-side defense reducing it by up to 34%.
-
PropGuard: Safeguarding LLM-MAS via Propagation-Aware Exploration and Remediation
PropGuard is a propagation-aware framework for LLM-MAS that constructs dual-view spatio-temporal graphs, employs a GE-GRPO inspector to recover suspicious subgraphs, and applies source-guided remediation to lower atta...
-
When Embedding-Based Defenses Fail: Rethinking Safety in LLM-Based Multi-Agent Systems
Embedding-based defenses fail against attacks that align malicious message embeddings with benign ones in LLM multi-agent systems, but token-level confidence scores improve robustness by enabling better pruning of sus...
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168. Ding, K.; Li, J.; Bhanushali, R.; and Liu, H
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
In Proceedings of the 2019 SIAM international conference on data mining, 594–602
Deep anomaly detection on attributed networks. In Proceedings of the 2019 SIAM international conference on data mining, 594–602. SIAM. Gan, Y .; Yang, Y .; Ma, Z.; He, P.; Zeng, R.; Wang, Y .; Li, Q.; Zhou, C.; Li, S.; Wang, T.; et al
work page 2019
-
[3]
Navigating the risks: A survey of security, privacy, and ethics threats in llm-based agents,
Navigating the risks: A survey of security, privacy, and ethics threats in llm-based agents. arXiv preprint arXiv:2411.09523. Gao, D.; Li, Z.; Pan, X.; Kuang, W.; Ma, Z.; Qian, B.; Wei, F.; Zhang, W.; Xie, Y .; Chen, D.; et al
-
[4]
AgentScope: A Flexible yet Robust Multi-Agent Platform,
Agentscope: A flexible yet robust multi-agent platform. arXiv preprint arXiv:2402.14034. Guo, T.; Chen, X.; Wang, Y .; Chang, R.; Pei, S.; Chawla, N. V .; Wiest, O.; and Zhang, X
-
[5]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Large language model based multi-agents: A survey of progress and challenges. arXiv preprint arXiv:2402.01680. He, P.; Dai, Z.; Tang, X.; Xing, Y .; Liu, H.; Zeng, J.; Peng, Q.; Agrawal, S.; Varshney, S.; Wang, S.; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
To trust or not to trust: Attention-based Trust Management for LLM Multi-Agent Systems
At- tention Knows Whom to Trust: Attention-based Trust Man- agement for LLM Multi-Agent Systems. arXiv preprint arXiv:2506.02546. Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; and Steinhardt, J
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , 12140–12147
Smart- llm: Smart multi-agent robot task planning using large lan- guage models. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , 12140–12147. IEEE. Kim, Y .; Park, C.; Jeong, H.; Chan, Y . S.; Xu, X.; McDuff, D.; Lee, H.; Ghassemi, M.; Breazeal, C.; and Park, H. W
work page 2024
-
[8]
Adam: A Method for Stochastic Optimization
Adam: A method for stochas- tic optimization. arXiv preprint arXiv:1412.6980. Kipf, T. N.; and Welling, M
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Macm: Utilizing a multi-agent system for condition mining in solving complex mathematical problems. Advances in Neural Information Processing Systems, 37: 53418–53437. Li, S.; Liu, Y .; Chen, Q.; Webb, G. I.; and Pan, S. 2024a. Noise-resilient unsupervised graph representation learning via multi-hop feature quality estimation. In Proceedings of the 33rd A...
-
[10]
Li, X.; Zeng, Y .; Xing, X.; Xu, J.; and Xu, X. 2025b. Hedgeagents: A balanced-aware multi-agent financial trad- ing system. In Companion Proceedings of the ACM on Web Conference 2025, 296–305. Li, Y .; Du, Y .; Zhang, J.; Hou, L.; Grabowski, P.; Li, Y .; and Ie, E. 2024c. Improving Multi-Agent Debate with Sparse Communication Topology. In Findings of the...
work page 2025
-
[11]
Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437. Liu, Y .; Li, Z.; Pan, S.; Gong, C.; Zhou, C.; and Karypis, G
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2507.21407
Graph- Augmented Large Language Model Agents: Current Progress and Future Prospects. arXiv preprint arXiv:2507.21407. Ma, R.; Pang, G.; Chen, L.; and Van Den Hengel, A
-
[13]
The Landscape of Emerging AI Agent Architectures for Reasoning, Planning, and Tool Calling: A Survey
The landscape of emerging ai agent architectures for reason- ing, planning, and tool calling: A survey. arXiv preprint arXiv:2404.11584. Nazary, F.; Deldjoo, Y .; and Noia, T. d
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
In 2023 IEEE International Conference on Data Mining (ICDM), 1253–1258
Prem: A simple yet effective approach for node-level graph anomaly detec- tion. In 2023 IEEE International Conference on Data Mining (ICDM), 1253–1258. IEEE. Qian, C.; Liu, W.; Liu, H.; Chen, N.; Dang, Y .; Li, J.; Yang, C.; Chen, W.; Su, Y .; Cong, X.; et al
work page 2023
-
[15]
ChatDev: Communicative Agents for Software Development
Chatdev: Com- municative agents for software development. arXiv preprint arXiv:2307.07924. Qiao, H.; and Pang, G
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
arXiv preprint arXiv:2409.09957
Deep graph anomaly detection: A survey and new perspectives. arXiv preprint arXiv:2409.09957. Reimers, N.; and Gurevych, I
-
[17]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084. Shen, X.; Liu, Y .; Dai, Y .; Wang, Y .; Miao, R.; Tan, Y .; Pan, S.; and Wang, X
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[18]
arXiv preprint arXiv:2505.23352
Understanding the Information Prop- agation Effects of Communication Topologies in LLM-based Multi-Agent Systems. arXiv preprint arXiv:2505.23352. Talmor, A.; Herzig, J.; Lourie, N.; and Berant, J
-
[19]
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
Com- monsenseqa: A question answering challenge targeting com- monsense knowledge. arXiv preprint arXiv:1811.00937. Tran, K.-T.; Dao, D.; Nguyen, M.-D.; Pham, Q.-V .; O’Sullivan, B.; and Nguyen, H. D
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Multi-agent col- laboration mechanisms: A survey of llms. arXiv preprint arXiv:2501.06322. Wang, S.; Zhang, G.; Yu, M.; Wan, G.; Meng, F.; Guo, C.; Wang, K.; and Wang, Y
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
G-safeguard: A topology-guided security lens and treatment on llm-based multi-agent systems,
G-Safeguard: A Topology- Guided Security Lens and Treatment on LLM-based Multi- agent Systems. arXiv preprint arXiv:2502.11127. Wu, F.; Souza, A.; Zhang, T.; Fifty, C.; Yu, T.; and Wein- berger, K
-
[22]
Qwen3 technical report. arXiv preprint arXiv:2505.09388. Yu, M.; Meng, F.; Zhou, X.; Wang, S.; Mao, J.; Pang, L.; Chen, T.; Wang, K.; Li, X.; Zhang, Y .; et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
A survey on trustworthy llm agents: Threats and countermeasures. arXiv preprint arXiv:2503.09648. Yu, M.; Wang, S.; Zhang, G.; Mao, J.; Yin, C.; Liu, Q.; Wen, Q.; Wang, K.; and Wang, Y
-
[24]
Netsafe: Exploring the topological safety of multi- agent networks,
Netsafe: Exploring the topological safety of multi-agent networks. arXiv preprint arXiv:2410.15686. Zhan, Q.; Liang, Z.; Ying, Z.; and Kang, D. 2024a. In- jecAgent: Benchmarking Indirect Prompt Injections in Tool- Integrated Large Language Model Agents. In Findings of the Association for Computational Linguistics ACL 2024 , 10471–10506. Zhan, Q.; Liang, Z...
-
[25]
S’more: Structural mixture of residual experts for parameter-efficient llm fine-tuning
Competeai: Understanding the competi- tion behaviors in large language model-based agents. arXiv preprint arXiv:2310.17512. Zhao, Z.; Chai, W.; Wang, X.; Li, B.; Hao, S.; Cao, S.; Ye, T.; and Wang, G
-
[26]
Corba: Contagious recursive blocking attacks on multi- agent systems based on large language models,
Corba: Contagious recursive blocking at- tacks on multi-agent systems based on large language models. arXiv preprint arXiv:2502.14529. A. Related Work LLM-based Multi-agent System Recent advances in LLM-based MAS have demonstrated remarkable capabilities in general task-solving. The perfor- mance of MAS is predominantly determined by collabora- tion and c...
-
[27]
and tool- handling mechanisms (Zhan et al. 2024a). The most se- vere threats target message-passing mechanisms (Zhou et al. 2025), enabling malicious attackers to implant prejudiced content. NetSafe (Yu et al
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.