To trust or not to trust: Attention-based Trust Management for LLM Multi-Agent Systems
Pith reviewed 2026-05-19 11:26 UTC · model grok-4.3
The pith
An attention-based trust management system allows LLM multi-agent systems to assess message trustworthiness and resist malicious inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that defining trustworthiness through six orthogonal dimensions and implementing an attention-based Trust Score allows construction of a trust management system that evaluates messages and agents in LLM multi-agent systems, resulting in significantly improved robustness against malicious inputs as demonstrated in multiple experimental settings and tasks.
What carries the argument
The Attention Trust Score (A-Trust), a lightweight attention-based method that scores message trustworthiness using the six orthogonal dimensions.
If this is right
- Message-level trust assessments allow agents to discount or ignore specific unreliable communications before acting on them.
- Agent-level trust assessments enable identification and isolation of consistently untrustworthy agents over time.
- The single framework supports both message-level and agent-level evaluations without requiring separate mechanisms.
- Robustness gains appear across a range of multi-agent tasks and settings when the system is applied.
Where Pith is reading between the lines
- The scoring method could be adapted to evaluate trustworthiness in single-agent LLM setups that receive external data streams.
- Integration with existing verification techniques might create layered defenses for agent communication networks.
- Large-scale simulations of agent populations would test whether attention scores remain stable as the number of agents grows.
Load-bearing premise
The six orthogonal trust dimensions inspired by Grice provide a comprehensive and interpretable measure of trustworthiness that can be accurately captured by an attention-based scoring method in LLM agents.
What would settle it
A controlled test where malicious messages are engineered to receive high attention-based trust scores on the six dimensions but still produce harmful effects, checking whether the trust management system fails to block them.
Figures
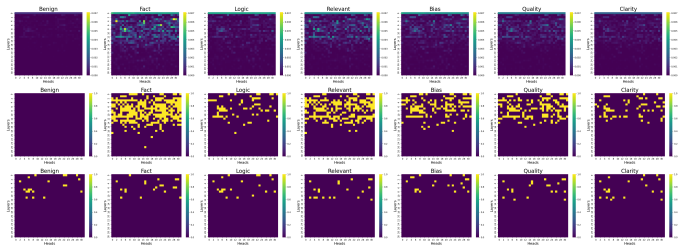





read the original abstract
Large Language Model-based Multi-Agent Systems (LLM-MAS) have demonstrated strong capabilities in solving complex tasks but remain vulnerable when agents receive unreliable messages. This vulnerability stems from a fundamental gap: LLM agents treat all incoming messages equally without evaluating their trustworthiness. While some existing studies approach trustworthiness, they focus on a single type of harmfulness rather than analyze it in a holistic approach from multiple trustworthiness perspectives. We address this gap by proposing a comprehensive definition of trustworthiness inspired by human communication theory (Grice, 1975). Our definition identifies six orthogonal trust dimensions that provide interpretable measures of trustworthiness. Building on this definition, we introduce the Attention Trust Score (A -Trust), a lightweight, attention-based method for evaluating the trustworthiness of messages. We then develop a principled trust management system (TMS) for LLM -MAS that supports both message-level and agent-level trust assessments. Experiments across diverse multi-agent settings and tasks demonstrate that our TMS significantly improves robustness against malicious inputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a definition of trustworthiness for LLM-based multi-agent systems (LLM-MAS) consisting of six orthogonal dimensions inspired by Grice (1975), introduces an Attention Trust Score (A-Trust) that uses attention mechanisms to produce interpretable per-message scores, develops a Trust Management System (TMS) supporting both message-level and agent-level assessments, and reports that experiments across diverse multi-agent settings and tasks show the TMS significantly improves robustness against malicious inputs.
Significance. If the central empirical claims hold after proper validation, the work would address a practical gap in holistic, multi-dimensional trust evaluation for LLM-MAS rather than single-dimension harm detection. The lightweight attention-based approach could integrate readily with existing LLM architectures and provide interpretable signals for agent decision-making.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the claim that 'experiments across diverse multi-agent settings and tasks demonstrate that our TMS significantly improves robustness' is presented without any description of baselines, metrics, statistical tests, number of runs, or how the six Grice dimensions were operationalized or measured. This leaves the central robustness claim without visible supporting evidence or controls.
- [A-Trust definition / §3] Section introducing A-Trust (likely §3): the assertion that attention weights produce scores aligned with the six orthogonal trust dimensions lacks any reported human annotation study, inter-dimension correlation matrix, or ablation that replaces the attention scorer with a non-semantic baseline (e.g., token length or embedding norm). Without such checks it is unclear whether reported gains reflect the proposed trust model or surface cues correlated with the synthetic attacks.
minor comments (2)
- [Method] Clarify the exact attention mechanism used (e.g., which layer, head, or query formulation) and whether it requires any fine-tuning or is purely zero-shot.
- [Definition] Add a table or figure summarizing the six dimensions with their Grice-inspired definitions and example message annotations.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important areas for improving the clarity and rigor of our experimental claims and validation of the A-Trust mechanism. We address each major comment point-by-point below, indicating where revisions have been made to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the claim that 'experiments across diverse multi-agent settings and tasks demonstrate that our TMS significantly improves robustness' is presented without any description of baselines, metrics, statistical tests, number of runs, or how the six Grice dimensions were operationalized or measured. This leaves the central robustness claim without visible supporting evidence or controls.
Authors: We agree that the original presentation of the robustness claims in the abstract and Experiments section lacked sufficient methodological detail. In the revised manuscript, we have expanded both the abstract and the Experiments section to explicitly describe: the baselines employed (including a no-trust baseline, a random trust assignment baseline, and a non-attention embedding-norm baseline); the evaluation metrics (task success rate under malicious inputs and attack mitigation rate); statistical testing via paired t-tests with reported p-values across 10 independent runs using different random seeds; and the operationalization of the six Grice-inspired dimensions through dimension-specific prompt templates and scoring rubrics in the TMS, with concrete examples now included in a new appendix subsection. revision: yes
-
Referee: [A-Trust definition / §3] Section introducing A-Trust (likely §3): the assertion that attention weights produce scores aligned with the six orthogonal trust dimensions lacks any reported human annotation study, inter-dimension correlation matrix, or ablation that replaces the attention scorer with a non-semantic baseline (e.g., token length or embedding norm). Without such checks it is unclear whether reported gains reflect the proposed trust model or surface cues correlated with the synthetic attacks.
Authors: We acknowledge the value of additional validation for the claimed alignment between attention weights and the six dimensions. A full-scale human annotation study was not performed in the original work owing to the substantial annotation effort required for multi-dimensional evaluation of LLM-generated messages. However, we have added an ablation study in the revised §3 and Experiments sections that replaces the attention scorer with non-semantic baselines (token length and embedding norm), showing that these yield significantly lower robustness gains. We have also included an inter-dimension correlation matrix in the appendix demonstrating low correlations (supporting orthogonality) and several qualitative case studies illustrating how attention patterns map to specific Grice dimensions. These additions provide quantitative and qualitative support for the trust model beyond surface cues. revision: partial
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper proposes a new definition of trustworthiness drawing from external citation to Grice (1975) to identify six dimensions, then constructs an attention-based A-Trust scoring method and TMS on top of that definition. No equations, fitted parameters, or self-citations are shown that reduce the claimed outputs (robustness gains) to inputs by construction. The approach is presented as a novel construction with experimental support rather than a tautological renaming or self-referential loop, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Trustworthiness of messages in LLM-MAS can be decomposed into six orthogonal dimensions inspired by Grice (1975) human communication theory.
invented entities (2)
-
Attention Trust Score (A-Trust)
no independent evidence
-
Trust Management System (TMS)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose Attention Trust Score (A-Trust), a lightweight, attention-based method for evaluating message trustworthiness... six orthogonal trust dimensions... factual accuracy, logical consistency, relevance, bias, clarity, quality.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We find that certain attention heads in the LLM specialize in detecting specific types of violations... Attnl,h(M) = geometric mean of attention weights.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
BlindGuard: Safeguarding LLM-based Multi-Agent Systems under Unknown Attacks
BlindGuard introduces an unsupervised hierarchical agent encoder plus corruption-guided contrastive detector that identifies malicious agents in LLM-based multi-agent systems without any attack labels or prior knowled...
-
GAMMAF: A Common Framework for Graph-Based Anomaly Monitoring Benchmarking in LLM Multi-Agent Systems
GAMMAF provides a benchmarking platform with data generation and defense evaluation pipelines for graph-based anomaly detection in LLM multi-agent systems, demonstrating improved integrity and lower operational costs ...
Reference graph
Works this paper leans on
-
[1]
Herbert Paul Grice. Logic and conversation. Syntax and semantics, 3:43–58, 1975
work page 1975
-
[2]
Camel: Communicative agents for" mind" exploration of large language model society
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for" mind" exploration of large language model society. Advances in Neural Information Processing Systems, 36:51991–52008, 2023
work page 2023
-
[3]
AgentScope: A Flexible yet Robust Multi-Agent Platform,
Dawei Gao, Zitao Li, Xuchen Pan, Weirui Kuang, Zhijian Ma, Bingchen Qian, Fei Wei, Wenhao Zhang, Yuexiang Xie, Daoyuan Chen, et al. Agentscope: A flexible yet robust multi-agent platform. arXiv preprint arXiv:2402.14034, 2024
-
[4]
Large Language Model-Based Agents for Software Engineering: A Survey
Junwei Liu, Kaixin Wang, Yixuan Chen, Xin Peng, Zhenpeng Chen, Lingming Zhang, and Yiling Lou. Large language model-based agents for software engineering: A survey. arXiv preprint arXiv:2409.02977, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. In The Twelfth International Conference on Learning Representations
-
[6]
Chatdev: Revolutionizing software development with llm-based agents
Yutao Qian et al. Chatdev: Revolutionizing software development with llm-based agents. arXiv preprint arXiv:2309.07922, 2023
-
[7]
Macm: Utilizing a multi-agent system for condition mining in solving complex mathematical problems
Bin Lei, Yi Zhang, Shan Zuo, Ali Payani, and Caiwen Ding. Macm: Utilizing a multi-agent system for condition mining in solving complex mathematical problems. arXiv preprint arXiv:2404.04735, 2024
-
[8]
Make llms better zero- shot reasoners: Structure-orientated autonomous reasoning
Pengfei He, Zitao Li, Yue Xing, Yaling Li, Jiliang Tang, and Bolin Ding. Make llms better zero- shot reasoners: Structure-orientated autonomous reasoning. arXiv preprint arXiv:2410.19000, 2024
-
[9]
Chatgpt research group for optimizing the crystallinity of mofs and cofs
Zhiling Zheng, Oufan Zhang, Ha L Nguyen, Nakul Rampal, Ali H Alawadhi, Zichao Rong, Teresa Head-Gordon, Christian Borgs, Jennifer T Chayes, and Omar M Yaghi. Chatgpt research group for optimizing the crystallinity of mofs and cofs. ACS Central Science, 9(11):2161–2170, 2023
work page 2023
-
[10]
Medagents: Large language models as collaborators for zero-shot medical reasoning
Xiangru Tang, Anni Zou, Zhuosheng Zhang, Ziming Li, Yilun Zhao, Xingyao Zhang, Arman Cohan, and Mark Gerstein. Medagents: Large language models as collaborators for zero-shot medical reasoning. arXiv preprint arXiv:2311.10537, 2023
-
[11]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D Nguyen. Multi-agent collaboration mechanisms: A survey of llms. arXiv preprint arXiv:2501.06322, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Prompt Infection: LLM-to-LLM Prompt Injection within Multi-Agent Systems
Donghyun Lee and Mo Tiwari. Prompt infection: Llm-to-llm prompt injection within multi- agent systems. arXiv preprint arXiv:2410.07283, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Breaking agents: Compromising autonomous llm agents through malfunction amplification
Boyang Zhang, Yicong Tan, Yun Shen, Ahmed Salem, Michael Backes, Savvas Zannettou, and Yang Zhang. Breaking agents: Compromising autonomous llm agents through malfunction amplification. arXiv preprint arXiv:2407.20859, 2024
-
[14]
Tianjie Ju, Yiting Wang, Xinbei Ma, Pengzhou Cheng, Haodong Zhao, Yulong Wang, Lifeng Liu, Jian Xie, Zhuosheng Zhang, and Gongshen Liu. Flooding spread of manipulated knowledge in llm-based multi-agent communities. arXiv preprint arXiv:2407.07791, 2024
-
[15]
Red-teaming llm multi-agent systems via communication attacks
Pengfei He, Yupin Lin, Shen Dong, Han Xu, Yue Xing, and Hui Liu. Red-teaming llm multi-agent systems via communication attacks. arXiv preprint arXiv:2502.14847, 2025
-
[16]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversation. arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Google. Agent2agent (a2a) protocol. https://github.com/google/A2A, 2025. 10
work page 2025
-
[18]
Knowledge-based consis- tency testing of large language models
Sai Sathiesh Rajan, Ezekiel Soremekun, and Sudipta Chattopadhyay. Knowledge-based consis- tency testing of large language models. arXiv preprint arXiv:2407.12830, 2024
-
[19]
Towards knowledge checking in retrieval-augmented generation: A representation perspective
Shenglai Zeng, Jiankun Zhang, Bingheng Li, Yuping Lin, Tianqi Zheng, Dante Everaert, Hanqing Lu, Hui Liu, Yue Xing, Monica Xiao Cheng, et al. Towards knowledge checking in retrieval-augmented generation: A representation perspective. arXiv preprint arXiv:2411.14572, 2024
-
[20]
Gionnieve Lim and Simon T Perrault. Evaluation of an llm in identifying logical fallacies: A call for rigor when adopting llms in hci research. In Companion Publication of the 2024 Conference on Computer-Supported Cooperative Work and Social Computing , pages 303–308, 2024
work page 2024
-
[21]
Are llms good zero-shot fallacy classifiers? arXiv preprint arXiv:2410.15050, 2024
Fengjun Pan, Xiaobao Wu, Zongrui Li, and Anh Tuan Luu. Are llms good zero-shot fallacy classifiers? arXiv preprint arXiv:2410.15050, 2024
-
[22]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems, 43(2):1–55, 2025
work page 2025
-
[23]
CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. Critic: Large language models can self-correct with tool-interactive critiquing. arXiv preprint arXiv:2305.11738, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
arXiv preprint arXiv:2308.04592 , year=
Tianlu Wang, Ping Yu, Xiaoqing Ellen Tan, Sean O’Brien, Ramakanth Pasunuru, Jane Dwivedi- Yu, Olga Golovneva, Luke Zettlemoyer, Maryam Fazel-Zarandi, and Asli Celikyilmaz. Shep- herd: A critic for language model generation. arXiv preprint arXiv:2308.04592, 2023
-
[25]
In-context Learning and Induction Heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads. arXiv preprint arXiv:2209.11895, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[26]
Attention tracker: Detecting prompt injection attacks in llms
Kuo-Han Hung, Ching-Yun Ko, Ambrish Rawat, I Chung, Winston H Hsu, Pin-Yu Chen, et al. Attention tracker: Detecting prompt injection attacks in llms. arXiv preprint arXiv:2411.00348, 2024
-
[27]
On the role of attention heads in large language model safety
Zhenhong Zhou, Haiyang Yu, Xinghua Zhang, Rongwu Xu, Fei Huang, Kun Wang, Yang Liu, Junfeng Fang, and Yongbin Li. On the role of attention heads in large language model safety. arXiv preprint arXiv:2410.13708, 2024
-
[28]
Successor heads: Recurring, interpretable attention heads in the wild
Rhys Gould, Euan Ong, George Ogden, and Arthur Conmy. Successor heads: Recurring, interpretable attention heads in the wild. arXiv preprint arXiv:2312.09230, 2023
-
[29]
Trustscore: reference-free evaluation of llm response trustworthiness
Danna Zheng, Danyang Liu, Mirella Lapata, and Jeff Z Pan. Trustscore: reference-free evaluation of llm response trustworthiness. arXiv preprint arXiv:2402.12545, 2024
-
[30]
A multi-dimensional trust evaluation model for large-scale p2p computing
Xiaoyong Li, Feng Zhou, and Xudong Yang. A multi-dimensional trust evaluation model for large-scale p2p computing. Journal of Parallel and Distributed Computing , 71(6):837–847, 2011
work page 2011
-
[31]
Jen-tse Huang, Jiaxu Zhou, Tailin Jin, Xuhui Zhou, Zixi Chen, Wenxuan Wang, Youliang Yuan, Maarten Sap, and Michael R Lyu. On the resilience of multi-agent systems with malicious agents. arXiv preprint arXiv:2408.00989, 2024
-
[32]
Netsafe: Exploring the topological safety of multi-agent networks
Miao Yu, Shilong Wang, Guibin Zhang, Junyuan Mao, Chenlong Yin, Qijiong Liu, Qingsong Wen, Kun Wang, and Yang Wang. Netsafe: Exploring the topological safety of multi-agent networks. arXiv preprint arXiv:2410.15686, 2024
-
[33]
FEVER: a large-scale dataset for fact extraction and VERification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. FEVER: a large-scale dataset for fact extraction and VERification. In NAACL-HLT, 2018
work page 2018
-
[34]
Stereoset: Measuring stereotypical bias in pretrained language models, 2020
Moin Nadeem, Anna Bethke, and Siva Reddy. Stereoset: Measuring stereotypical bias in pretrained language models, 2020. 11
work page 2020
-
[35]
Why do most multi-agent llm systems fail?, March 2025
Jagadeesh Rajarajan. Why do most multi-agent llm systems fail?, March 2025. Accessed: 2025-05-14
work page 2025
-
[36]
Why are my prompts leaked? unraveling prompt extraction threats in customized large language models
Zi Liang, Haibo Hu, Qingqing Ye, Yaxin Xiao, and Haoyang Li. Why are my prompts leaked? unraveling prompt extraction threats in customized large language models. arXiv preprint arXiv:2408.02416, 2024
-
[37]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
Neel Jain, Avi Schwarzschild, Yuxin Wen, Gowthami Somepalli, John Kirchenbauer, Ping-yeh Chiang, Micah Goldblum, Aniruddha Saha, Jonas Geiping, and Tom Goldstein. Baseline de- fenses for adversarial attacks against aligned language models.arXiv preprint arXiv:2309.00614, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Ai control: Improving safety despite intentional subversion
Ryan Greenblatt, Buck Shlegeris, Kshitij Sachan, and Fabien Roger. Ai control: Improving safety despite intentional subversion. arXiv preprint arXiv:2312.06942, 2023
-
[40]
Hallucination is Inevitable: An Innate Limitation of Large Language Models
Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli. Hallucination is inevitable: An innate limitation of large language models. arXiv preprint arXiv:2401.11817, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR) , 2021
work page 2021
-
[42]
Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did Aristotle Use a Laptop? A Question Answering Benchmark with Implicit Reasoning Strategies. Transactions of the Association for Computational Linguistics (TACL) , 2021
work page 2021
-
[43]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[44]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In The Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[45]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[46]
S$^3$: Social-network Simulation System with Large Language Model-Empowered Agents
Chen Gao, Xiaochong Lan, Zhihong Lu, Jinzhu Mao, Jinghua Piao, Huandong Wang, Depeng Jin, and Yong Li. S3: Social-network simulation system with large language model-empowered agents. arXiv preprint arXiv:2307.14984, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Embodied llm agents learn to cooperate in organized teams
Xudong Guo, Kaixuan Huang, Jiale Liu, Wenhui Fan, Natalia Vélez, Qingyun Wu, Huazheng Wang, Thomas L Griffiths, and Mengdi Wang. Embodied llm agents learn to cooperate in organized teams. arXiv preprint arXiv:2403.12482, 2024
-
[48]
Language agents with reinforcement learning for strategic play in the werewolf game
Zelai Xu, Chao Yu, Fei Fang, Yu Wang, and Yi Wu. Language agents with reinforcement learning for strategic play in the werewolf game. arXiv preprint arXiv:2310.18940, 2023
-
[49]
Zaibin Zhang, Yongting Zhang, Lijun Li, Hongzhi Gao, Lijun Wang, Huchuan Lu, Feng Zhao, Yu Qiao, and Jing Shao. Psysafe: A comprehensive framework for psychological-based attack, defense, and evaluation of multi-agent system safety. arXiv preprint arXiv:2401.11880, 2024
-
[50]
Alfonso Amayuelas, Xianjun Yang, Antonis Antoniades, Wenyue Hua, Liangming Pan, and William Wang. Multiagent collaboration attack: Investigating adversarial attacks in large language model collaborations via debate. arXiv preprint arXiv:2406.14711, 2024
-
[51]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report. arXiv preprint arXiv:2503.19786, 2025. 13 A Related works LLM-based Multi-agent System. LLM-MAS enhance the reasoning and task-solving capabilities of large language...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Factual Accuracy - Are the claims verifiably true and consistent with known facts?
-
[54]
Logical Consistency – Is the argument internally coherent and free of contradictions?
-
[55]
Relevance to Context – Does the content stay on topic and address the given question or prompt?
-
[56]
Neutrality & Bias – Is the language objective, balanced, and free from undue bias?
-
[57]
Language Quality – Is the prose fluent, grammatical, and properly punctuated?
-
[58]
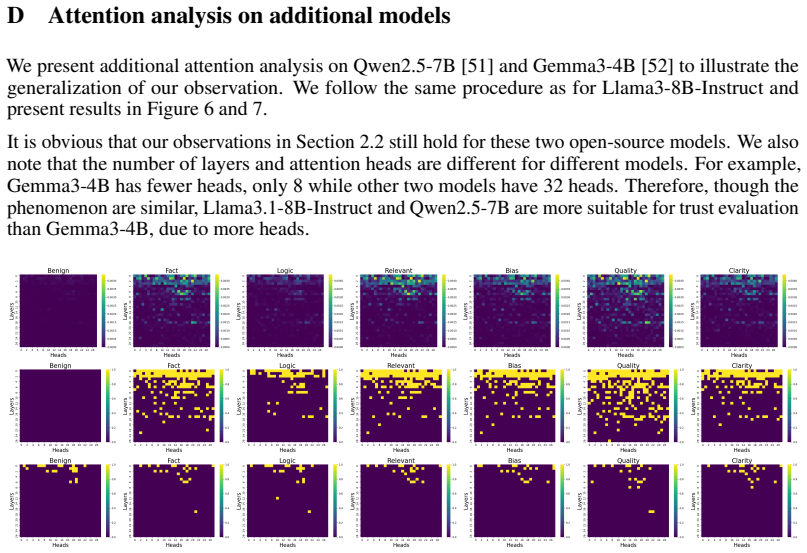
Clarity & Precision – Are ideas expressed unambiguously and concisely? Scoring rules (per rubric): 0%=Poor, 100%=Excellent (Use percentage only.) Your tasks: Provide a brief justification (1-3 sentences) for each rubric score. 17 D Attention analysis on additional models We present additional attention analysis on Qwen2.5-7B [51] and Gemma3-4B [52] to ill...
-
[59]
Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Yes] Justification: (1) We decompose trustworthiness into six dimensions following human communication literature and curate a dataset correspondingly. (2) We develop A-Trust to evaluate the message trustworthiness lev...
-
[60]
Limitations Question: Does the paper discuss the limitations of the work performed by the authors? Answer: [Yes] Justification: We summarize some limitations in our paper in Conclusion section and correspondingly suggest some potential future directions. Guidelines: • The answer NA means that the paper has no limitation while the answer No means that the ...
-
[61]
Guidelines: • The answer NA means that the paper does not include theoretical results
Theory assumptions and proofs 23 Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof? Answer: [NA] Justification: No mathematical theory is included in this paper. Guidelines: • The answer NA means that the paper does not include theoretical results. • All the theorems, formulas, and...
-
[62]
Guidelines: • The answer NA means that the paper does not include experiments
Experimental result reproducibility Question: Does the paper fully disclose all the information needed to reproduce the main ex- perimental results of the paper to the extent that it affects the main claims and/or conclusions of the paper (regardless of whether the code and data are provided or not)? Answer: [Yes] Justification: We include the details abo...
-
[63]
Guidelines: • The answer NA means that paper does not include experiments requiring code
Open access to data and code Question: Does the paper provide open access to the data and code, with sufficient instruc- tions to faithfully reproduce the main experimental results, as described in supplemental material? Answer: [Yes] Justification: We provide anonymized repo containing both data and code in Section 2.2 and 4.1. Guidelines: • The answer N...
-
[64]
Guidelines: • The answer NA means that the paper does not include experiments
Experimental setting/details Question: Does the paper specify all the training and test details (e.g., data splits, hyper- parameters, how they were chosen, type of optimizer, etc.) necessary to understand the results? Answer: [Yes] Justification: Justification: We include the details about the structure of the LLM-MAS considered in this paper, the prompt...
-
[65]
Guidelines: • The answer NA means that the paper does not include experiments
Experiment statistical significance Question: Does the paper report error bars suitably and correctly defined or other appropriate information about the statistical significance of the experiments? Answer: [No] Justification: Through various settings, our proposed methods demonstrate consistent en- hancement compared to the baselines. Guidelines: • The an...
-
[66]
Guidelines: • The answer NA means that the paper does not include experiments
Experiments compute resources Question: For each experiment, does the paper provide sufficient information on the com- puter resources (type of compute workers, memory, time of execution) needed to reproduce the experiments? Answer: [Yes] Justification: We mention the details of server we run experiments on in Section 4.1, and include latency analysis in ...
-
[67]
Guidelines: • The answer NA means that the authors have not reviewed the NeurIPS Code of Ethics
Code of ethics Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethicshttps://neurips.cc/public/EthicsGuidelines? Answer: [Yes] Justification: The research is conducted following the NeurIPS Code of Ethics. Guidelines: • The answer NA means that the authors have not reviewed the NeurIPS Code of Ethics....
-
[68]
There is no potential negative social impact based on our knowledge
Broader impacts Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed? Answer: [No] Justification: We introduce a system to enhance the robustness of LLM-MAS. There is no potential negative social impact based on our knowledge. Guidelines: • The answer NA means that there is no societ...
-
[69]
There is no direct way to misuse them for malicious purposes
Safeguards Question: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse (e.g., pretrained language models, image generators, or scraped datasets)? Answer: [NA] Justification: Our proposed methods aims to enhance the trustworthiness of LLM-MAS. There is no direct way to ...
-
[70]
Guidelines: • The answer NA means that the paper does not use existing assets
Licenses for existing assets Question: Are the creators or original owners of assets (e.g., code, data, models), used in the paper, properly credited and are the license and terms of use explicitly mentioned and properly respected? Answer: [Yes] Justification: We summarize the license in Section E. Guidelines: • The answer NA means that the paper does not...
-
[71]
The description of the dataset can be found in Section 2.1
New assets Question: Are new assets introduced in the paper well documented and is the documentation provided alongside the assets? Answer: [Yes] Justification: We develop a new dataset, Trust Violation dataset, in our paper. The description of the dataset can be found in Section 2.1. We also demonstrate how to use the dataset in Section 2.2. Guidelines: ...
-
[72]
Crowdsourcing and research with human subjects Question: For crowdsourcing experiments and research with human subjects, does the paper include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation (if any)? Answer: [NA] Justification: There is no crowdsourcing experiments. Guidelines: • ...
-
[73]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
-
[74]
Declaration of LLM usage Question: Does the paper describe the usage of LLMs if it is an important, original, or non-standard component of the core methods in this research? Note that if the LLM is used only for writing, editing, or formatting purposes and does not impact the core methodology, scientific rigorousness, or originality of the research, decla...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.