Attribution Gradients: Incrementally Unfolding Citations for Critical Examination of Attributed AI Answers
Pith reviewed 2026-05-18 11:31 UTC · model grok-4.3
The pith
Attribution gradients consolidate citation evidence and allow in-place unfolding of second-degree sources to support deeper critical reading of AI answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Attribution gradients bring evidence amounts, supporting/contradictory excerpts, links to source, contextual explanation into one place and enable the ability to unravel second-degree citations in place. In a lab study we demonstrate usage of the full gradient in a critical reading task and its support for deep engagement that increased the depth of what readers took away from the sources versus a standard citation and document QA design.
What carries the argument
Attribution gradients, a technique that consolidates scent and information prey in place for citations while supporting incremental unraveling of second-degree sources.
Load-bearing premise
The specific critical reading task and participant pool in the lab study are representative of how typical users would engage with attributed AI answers in everyday settings.
What would settle it
A field observation or study showing whether typical users actually unfold attribution gradients during real use of AI answers and gain measurably greater depth from sources than with standard citations.
Figures







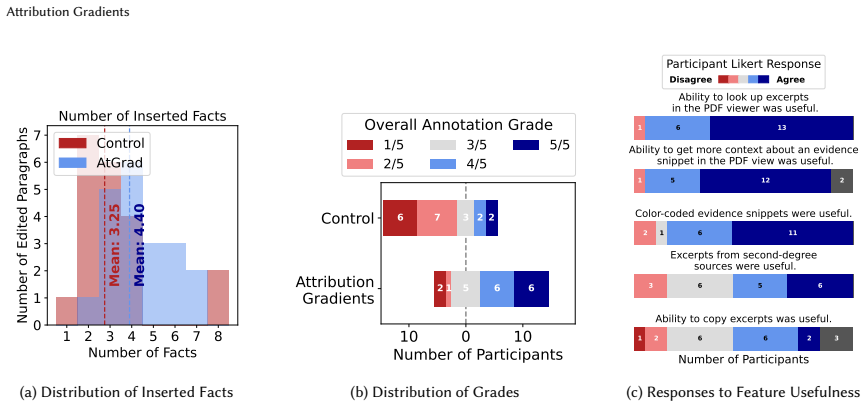
read the original abstract
AI answer engines are a relatively new kind of information search tool: rather than returning a ranked list of documents, they generate an answer to a search question with inline citations to sources. But reading the cited sources is costly, and citation links themselves offer little guidance about what evidence they contain. We present attribution gradients, a technique to boost the informativeness of citations by consolidating scent and information prey in place. Its first feature is bringing evidence amounts, supporting/contradictory excerpts, links to source, contextual explanation into one place. Its second feature is the ability to unravel second-degree citations in place. In a lab study we demonstrate usage of the full gradient in a critical reading task and its support for deep engagement that increased the depth of what readers took away from the sources versus a standard citation and document QA design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces attribution gradients as a technique to increase the informativeness of inline citations in AI-generated answers by consolidating evidence amounts, supporting/contradictory excerpts, source links, and contextual explanations in one place, while also supporting incremental unfolding of second-degree citations. It reports results from a lab study in which participants using the full attribution gradient in a critical reading task showed deeper engagement and greater depth of takeaways from the cited sources relative to a standard citation baseline and a document QA design.
Significance. If the empirical findings are robust, the work addresses a practical problem in human-AI information interaction by giving users more actionable cues for source evaluation. The paper receives credit for including a controlled lab study that directly tests the technique against two comparison conditions and reports a measurable difference in takeaway depth.
major comments (2)
- [Abstract] Abstract: the claim that the full gradient 'increased the depth of what readers took away from the sources' rests on a lab study, yet the manuscript provides no details on sample size, statistical tests, task design, or controls for confounds. This omission prevents evaluation of whether the data actually support the central empirical claim.
- [Lab study / Evaluation] Lab study description: the central claim depends on the observed benefit generalizing beyond the specific critical-reading task and participant pool. Everyday use of attributed AI answers typically involves quick verification rather than instructed, high-investment analysis; the manuscript does not report field data, ecological-validity measures, or deployment observations that would address this gap.
minor comments (1)
- The new term 'attribution gradient' is introduced without an early diagram or concise operational definition; adding one would improve readability for readers encountering the concept for the first time.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on our manuscript. We address each major comment below, indicating where we agree and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the full gradient 'increased the depth of what readers took away from the sources' rests on a lab study, yet the manuscript provides no details on sample size, statistical tests, task design, or controls for confounds. This omission prevents evaluation of whether the data actually support the central empirical claim.
Authors: We agree that the abstract is too concise and should include key empirical details to allow readers to evaluate the central claim. In the revised manuscript we will expand the abstract to report the sample size, the statistical tests used, a brief description of the critical-reading task, and mention of controls for confounds. The full methodological details already appear in the Evaluation section; the abstract revision will make the high-level claim more transparent while remaining within length limits. revision: yes
-
Referee: [Lab study / Evaluation] Lab study description: the central claim depends on the observed benefit generalizing beyond the specific critical-reading task and participant pool. Everyday use of attributed AI answers typically involves quick verification rather than instructed, high-investment analysis; the manuscript does not report field data, ecological-validity measures, or deployment observations that would address this gap.
Authors: We acknowledge that the lab study was conducted in a controlled, high-investment critical-reading setting and therefore does not directly demonstrate generalization to quick-verification scenarios common in everyday use. The lab design was chosen to enable precise measurement of takeaway depth against two baselines. In the revision we will add a Limitations and Future Work subsection that explicitly discusses the scope of the current task, the distinction between instructed analysis and typical use, and the absence of field or deployment data. We will also outline planned follow-up studies to examine ecological validity. revision: partial
Circularity Check
No circularity: central claim is empirical user study result
full rationale
The paper introduces attribution gradients as a UI technique for unfolding citations and evaluates it via a lab study showing increased depth of takeaway in a critical reading task compared to standard citations or document QA. No derivation chain, equations, fitted parameters, or first-principles predictions exist that could reduce to inputs by construction. The load-bearing evidence is the user study outcome itself, which is independent of any self-referential logic or prior self-citations. This matches the default expectation of no significant circularity for an empirical HCI paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Users will engage more deeply with sources when evidence details and excerpts are consolidated in one view rather than requiring separate navigation.
invented entities (1)
-
Attribution gradient
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present attribution gradients... incrementally unfoldable... concurrent interconnections among answer, claim, excerpt, and context... lab usability study... higher-quality revisions... longer and more frequent interactions with sources.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
color-coded pieces of evidence (black indicates direct support; red, direct contradiction... unravel second-degree citations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
From Binary Groundedness to Support Relations: Towards a Reader-Centred Taxonomy for Comprehension of AI Output
Binary groundedness judgments in AI evaluations should be replaced by a reader-centered taxonomy of support relations that distinguishes syntactic and interpretive moves between generated statements and source documents.
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, Luca Soldaini, Sergey Feldman, Mike D’arcy, et al
- [2]
- [3]
-
[4]
Tal August, Lucy Lu Wang, Jonathan Bragg, Marti A Hearst, Andrew Head, and Kyle Lo. 2023. Paper plain: Making medical research papers approachable to healthcare consumers with natural language processing.ACM Transactions on Computer-Human Interaction30, 5 (2023), 1–38
work page 2023
-
[5]
Hearst, Andrew Head, and Kyle Lo
Tal August, Lucy Lu Wang, Jonathan Bragg, Marti A. Hearst, Andrew Head, and Kyle Lo. 2023. Paper Plain: Making Medical Research Papers Approachable to Healthcare Consumers with Natural Language Processing.ACM Transactions on Computer-Human Interaction(2023). To appear
work page 2023
- [6]
-
[7]
Joseph Chee Chang, Amy X Zhang, Jonathan Bragg, Andrew Head, Kyle Lo, Doug Downey, and Daniel S Weld. 2023. Citesee: Augmenting citations in scientific papers with persistent and personalized historical context. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–15
work page 2023
- [8]
-
[9]
Zijian Ding, Michelle Brachman, Joel Chan, and Werner Geyer. 2025. Structuring GenAI-assisted Hypotheses Exploration with an Interactive Shared Representation. InCompanion Proceedings of the 30th International Conference on Intelligent User Interfaces. 167–171
work page 2025
- [10]
-
[11]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat-Seng Chua, and Qing Li. 2024. A survey on rag meeting llms: Towards retrieval-augmented large language models. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 6491–6501
work page 2024
- [12]
- [13]
-
[14]
Raymond Fok, Hita Kambhamettu, Luca Soldaini, Jonathan Bragg, Kyle Lo, Marti Hearst, Andrew Head, and Daniel S Weld. 2023. Scim: Intelligent skimming support for scientific papers. InProceedings of the 28th International Conference on Intelligent User Interfaces. 476–490
work page 2023
-
[15]
Raymond Fok, Nedim Lipka, Tong Sun, and Alexa F Siu. 2024. Marco: Supporting Business Document Workflows via Collection-Centric Information Foraging with Large Language Models. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–20
work page 2024
-
[16]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.109972 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Katy Ilonka Gero, Chelse Swoopes, Ziwei Gu, Jonathan K Kummerfeld, and Elena L Glassman. 2024. Supporting sensemaking of large language model outputs at scale. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–21
work page 2024
-
[18]
Dirk Groeneveld, Iz Beltagy, Evan Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Cry...
work page 2024
-
[19]
Carol Mullins Hayes. 2023. Generative artificial intelligence and copyright: Both sides of the black box.A vailable at SSRN 4517799(2023)
work page 2023
-
[20]
Andrew Head, Kyle Lo, Dongyeop Kang, Raymond Fok, Sam Skjonsberg, Daniel S Weld, and Marti A Hearst. 2021. Augmenting scientific papers with just-in-time, position-sensitive definitions of terms and symbols. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems. 1–18
work page 2021
-
[21]
Andrew Head, Kyle Lo, Dongyeop Kang, Raymond Fok, Sam Skjonsberg, Daniel S. Weld, and Marti A. Hearst. 2021. Augmenting Scientific Papers with Just-in-Time, Position-Sensitive Definitions of Terms and Symbols. InProceedings of the CHI Conference on Human Factors in Computing Systems. ACM. Paper 413. 19 Your last name et al
work page 2021
-
[22]
Jeffrey Heer, Matthew Conlen, Vishal Devireddy, Tu Nguyen, and Joshua Horowitz. 2023. Living papers: A language toolkit for augmented scholarly communication. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. 1–13
work page 2023
- [23]
-
[24]
Md Naimul Hoque, Tasfia Mashiat, Bhavya Ghai, Cecilia D Shelton, Fanny Chevalier, Kari Kraus, and Niklas Elmqvist. 2024. The HaLLMark Effect: Supporting Provenance and Transparent Use of Large Language Models in Writing with Interactive Visualization. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–15
work page 2024
- [25]
-
[26]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. 2025. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems43, 2 (2025), 1–55
work page 2025
- [27]
-
[28]
Hyeonsu Kang, Joseph Chee Chang, Yongsung Kim, and Aniket Kittur. 2022. Threddy: An interactive system for personalized thread-based exploration and organization of scientific literature. InProceedings of the 35th Annual ACM Symposium on User Interface Software and Technology. 1–15
work page 2022
-
[29]
Hyeonsu B Kang, Tongshuang Wu, Joseph Chee Chang, and Aniket Kittur. 2023. Synergi: A mixed-initiative system for scholarly synthesis and sensemaking. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. 1–19
work page 2023
-
[30]
Hyunwoo Kim, Khanh Duy Le, Gionnieve Lim, Dae Hyun Kim, Yoo Jin Hong, and Juho Kim. 2024. DataDive: Supporting Readers’ Contextualization of Statistical Statements with Data Exploration. InProceedings of the 29th International Conference on Intelligent User Interfaces. 623–639
work page 2024
-
[31]
Tae Soo Kim, Matt Latzke, Jonathan Bragg, Amy X Zhang, and Joseph Chee Chang. 2023. Papeos: Augmenting research papers with talk videos. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. 1–19
work page 2023
-
[32]
The Semantic Scholar open data platform.arXiv preprint arXiv:2301.10140, 2023
Rodney Michael Kinney, Chloe Anastasiades, Russell Authur, Iz Beltagy, Jonathan Bragg, Alexandra Buraczynski, Isabel Cachola, Stefan Candra, Yoganand Chandrasekhar, Arman Cohan, Miles Crawford, Doug Downey, Jason Dunkelberger, Oren Etzioni, Rob Evans, Sergey Feldman, Joseph Gorney, David W. Graham, F.Q. Hu, Regan Huff, Daniel King, Sebastian Kohlmeier, Ba...
- [33]
- [34]
-
[35]
Philippe Laban, Jesse Vig, Marti Hearst, Caiming Xiong, and Chien-Sheng Wu. 2024. Beyond the chat: Executable and verifiable text-editing with llms. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. 1–23
work page 2024
-
[36]
Shahid Latif, Zheng Zhou, Yoon Kim, Fabian Beck, and Nam Wook Kim. 2021. Kori: Interactive synthesis of text and charts in data documents.IEEE Transactions on Visualization and Computer Graphics28, 1 (2021), 184–194
work page 2021
-
[37]
Yoonjoo Lee, Hyeonsu B Kang, Matt Latzke, Juho Kim, Jonathan Bragg, Joseph Chee Chang, and Pao Siangliulue. 2024. Paperweaver: Enriching topical paper alerts by contextualizing recommended papers with user-collected papers. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–19
work page 2024
-
[38]
Alice Li and Luanne Sinnamon. 2024. Generative AI Search Engines as Arbiters of Public Knowledge: An Audit of Bias and Authority.Proceedings of the Association for Information Science and Technology61, 1 (2024), 205–217
work page 2024
-
[39]
Guanyu Lin, Tao Feng, Pengrui Han, Ge Liu, and Jiaxuan You. 2024. Arxiv Copilot: A Self-Evolving and Efficient LLM System for Personalized Academic Assistance. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 122–130
work page 2024
-
[40]
Nora Freya Lindemann. 2024. Chatbots, search engines, and the sealing of knowledges.AI & SOCIETY(2024), 1–14
work page 2024
-
[41]
Michael Xieyang Liu, Tongshuang Wu, Tianying Chen, Franklin Mingzhe Li, Aniket Kittur, and Brad A Myers. 2024. Selenite: Scaffolding Online Sensemaking with Comprehensive Overviews Elicited from Large Language Models. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–26
work page 2024
-
[42]
Kyle Lo, Zejiang Shen, Benjamin Newman, Joseph Z Chang, Russell Authur, Erin Bransom, Stefan Candra, Yoganand Chandrasekhar, Regan Huff, Bailey Kuehl, et al. 2023. PaperMage: a unified toolkit for processing, representing, and manipulating visually-rich scientific documents. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Pr...
work page 2023
- [43]
-
[44]
https://copilot.microsoft.com/ 20 Attribution Gradients
Mircosoft.Copilot. https://copilot.microsoft.com/ 20 Attribution Gradients
- [45]
-
[46]
https://openai.com/index/introducing-deep-research/
OpenAI.Deep Research. https://openai.com/index/introducing-deep-research/
-
[47]
https://openreader.semanticscholar.org/PaperCraft
openreader.semanticscholar.org/PaperCraft.openreader.semanticscholar.org/PaperCraft. https://openreader.semanticscholar.org/PaperCraft
-
[48]
Srishti Palani, Aakanksha Naik, Doug Downey, Amy X Zhang, Jonathan Bragg, and Joseph Chee Chang. 2023. Relatedly: Scaffolding literature reviews with existing related work sections. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–20
work page 2023
- [49]
-
[50]
Peter Pirolli and Stuart Card. 2005. The sensemaking process and leverage points for analyst technology as identified through cognitive task analysis. InProceedings of international conference on intelligence analysis, Vol. 5. McLean, VA, USA, 2–4
work page 2005
-
[51]
Kevin Pu, KJ Feng, Tovi Grossman, Tom Hope, Bhavana Dalvi Mishra, Matt Latzke, Jonathan Bragg, Joseph Chee Chang, and Pao Siangliulue. 2024. IdeaSynth: Iterative Research Idea Development Through Evolving and Composing Idea Facets with Literature-Grounded Feedback.arXiv preprint arXiv:2410.04025(2024)
-
[52]
https://pypi.org/project/pypdf/
pypi.org/project/pypdf.pypi.org/project/pypdf. https://pypi.org/project/pypdf/
-
[53]
Marissa Radensky, Simra Shahid, Raymond Fok, Pao Siangliulue, Tom Hope, and Daniel S Weld. 2024. Scideator: Human-LLM Scientific Idea Generation Grounded in Research-Paper Facet Recombination.arXiv preprint arXiv:2409.14634(2024)
work page internal anchor Pith review arXiv 2024
- [54]
-
[55]
Chirag Shah and Emily M Bender. 2024. Envisioning information access systems: What makes for good tools and a healthy Web?ACM Transactions on the Web18, 3 (2024), 1–24
work page 2024
-
[56]
Nikhil Sharma, Q Vera Liao, and Ziang Xiao. 2024. Generative echo chamber? effect of llm-powered search systems on diverse information seeking. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–17
work page 2024
-
[57]
Nicole Sultanum and Arjun Srinivasan. 2023. Datatales: Investigating the use of large language models for authoring data-driven articles. In2023 IEEE Visualization and Visual Analytics (VIS). IEEE, 231–235
work page 2023
- [58]
- [59]
- [60]
-
[61]
Frank Wilcoxon. 1992. Individual comparisons by ranking methods. InBreakthroughs in statistics: Methodology and distribution. Springer, 196–202
work page 1992
- [62]
- [63]
- [64]
-
[65]
Chengbo Zheng, Yuanhao Zhang, Zeyu Huang, Chuhan Shi, Minrui Xu, and Xiaojuan Ma. 2024. DiscipLink: Unfolding Interdisciplinary Information Seeking Process via Human-AI Co-Exploration. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology. 1–20. A Second judge’s ratings of revision quality Section 5.3.1 reports on qualit...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.