Recognition: 2 theorem links
· Lean TheoremKnowledge-Graph-Driven Data Synthesis for Low-Resource Software Development: A HarmonyOS Case Study
Pith reviewed 2026-05-17 03:35 UTC · model grok-4.3
The pith
Synthesizing question-code pairs from API knowledge graphs lets a 7B model outperform untuned GPT-4o on HarmonyOS code generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
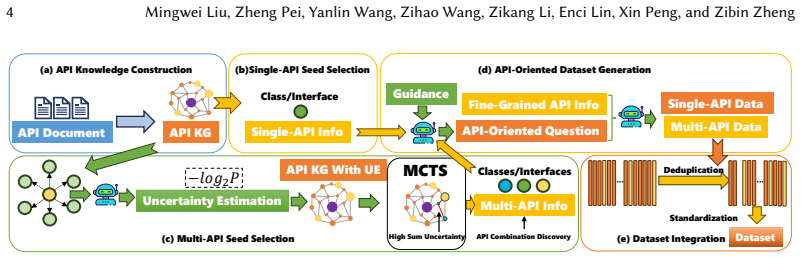
APIKG4Syn constructs an API knowledge graph from framework documentation to synthesize high-quality question-code pairs for fine-tuning, combining single-API examples with multi-API ones selected via uncertainty estimation and Monte Carlo Tree Search, and demonstrates that this data enables a 7B model to achieve higher pass@1 on HarmonyOS code generation than untuned GPT-4o while showing benefits from increased data volume and specific mixing ratios.
What carries the argument
The API knowledge graph encoding single-API and multi-API relations, with uncertainty estimation and Monte Carlo Tree Search used to select informative multi-API combinations for synthesis.
If this is right
- Larger volumes of data generated by the method produce steadily better fine-tuning outcomes.
- An 8:2 ratio of single-API to multi-API pairs yields the strongest results.
- Ablation of the graph construction, uncertainty estimation, or search component each reduces final performance.
- The approach improves handling of framework-specific syntax and API calls in generated code.
Where Pith is reading between the lines
- The same graph-driven synthesis could be applied to documentation of other low-resource frameworks to create targeted training data.
- Removing the need for executable verification makes the method practical for new or closed ecosystems where running code is difficult.
- Combining the synthetic pairs with a small amount of human-written examples might further close the gap to fully supervised fine-tuning.
Load-bearing premise
The synthetic question-code pairs generated from the API knowledge graph are high-quality enough to teach framework-specific conventions without any executable environment or runtime verification of correctness.
What would settle it
Fine-tuning the same 7B model on randomly generated question-code pairs drawn from the same HarmonyOS documentation and measuring whether the pass@1 score on the benchmark falls to or below the 17.59% GPT-4o baseline.
Figures












read the original abstract
In low-resource framework development (e.g., HarmonyOS), large language models (LLMs) often lack sufficient pre-training exposure, resulting in poor code generation performance. Although they generally preserve programming logic across languages, they frequently fail on framework-specific APIs and syntax, revealing a gap between learned algorithmic knowledge and unfamiliar framework conventions. Consequently, even advanced models such as GPT-4o struggle to produce correct code without prior exposure. Inspired by these challenges, we propose APIKG4Syn, a framework that leverages API knowledge graphs to synthesize API-oriented question-code pairs without requiring executable environments. It incorporates both single-API and multi-API information, with the latter guided by uncertainty estimation (UE) and Monte Carlo Tree Search (MCTS), to construct high-quality fine-tuning data. For evaluation, we select HarmonyOS as a case study due to its accessible documentation and growing ecosystem, and build the first benchmark for its code generation. Experimental results show that fine-tuning Qwen2.5-Coder-7B with APIKG4Syn achieves a pass@1 of 25.00%, outperforming untuned GPT-4o (17.59%). We further observe that larger volumes of data generated by APIKG4Syn consistently lead to better fine-tuning performance, and that the optimal Single-API to Multi-API ratio is 8:2. Ablation studies also confirm the necessity and effectiveness of each component in our framework. These findings highlight the effectiveness of API-oriented data in enhancing LLM performance for low-resource software development scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes APIKG4Syn, a framework that builds an API knowledge graph from HarmonyOS documentation and synthesizes single-API and multi-API question-code pairs (the latter via uncertainty estimation and MCTS) to create fine-tuning data without any executable environment. On a newly introduced HarmonyOS code-generation benchmark, fine-tuning Qwen2.5-Coder-7B on the resulting data yields 25.00% pass@1, outperforming untuned GPT-4o at 17.59%. The authors further report that larger data volumes improve results and that an 8:2 single-to-multi-API ratio is optimal, with ablations confirming the value of each component.
Significance. If the synthetic pairs are shown to be sufficiently accurate, the work provides a concrete, documentation-driven route to adapt LLMs to low-resource or proprietary frameworks where real code examples are scarce. The creation of the first public HarmonyOS code-generation benchmark and the empirical observation that KG-derived data volume correlates with fine-tuning gains are useful contributions that could generalize beyond the case study.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: the reported pass@1 figures (25.00% vs. 17.59%) are given without any description of benchmark construction, how the correctness of the synthetic question-code pairs was validated, statistical significance testing, or leakage controls between the knowledge graph and the test set. These omissions directly affect the ability to assess whether the central performance claim is robust.
- [§3 (APIKG4Syn data synthesis)] §3 (APIKG4Syn data synthesis): the method generates code pairs from the knowledge graph and UE-guided MCTS but performs no execution, unit tests, or static analysis to verify that the synthesized code correctly invokes HarmonyOS APIs or respects framework conventions. Because the improvement over GPT-4o is attributed to the quality of these pairs, the absence of any correctness check is load-bearing for the main claim.
minor comments (2)
- [Ablation studies] The ablation study results are summarized in the abstract but would be clearer if presented in a dedicated table showing exact pass@1 drops when UE or MCTS is removed.
- [Experimental setup] The precise definition and counting method for the Single-API to Multi-API ratio (optimal 8:2) should be stated explicitly so readers can reproduce the data composition.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps us improve the clarity and robustness of our claims. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: the reported pass@1 figures (25.00% vs. 17.59%) are given without any description of benchmark construction, how the correctness of the synthetic question-code pairs was validated, statistical significance testing, or leakage controls between the knowledge graph and the test set. These omissions directly affect the ability to assess whether the central performance claim is robust.
Authors: We agree that these details are essential for assessing robustness. In the revised manuscript, we have substantially expanded the Evaluation section with a dedicated subsection on benchmark construction, detailing how the HarmonyOS code-generation test cases were curated directly from official documentation while excluding any content used to build the API knowledge graph. We now describe our validation procedure for the synthetic pairs, which combines heuristic checks for valid API signatures with manual review of a 200-pair sample. Statistical significance is addressed by reporting results across five independent fine-tuning runs with different random seeds, including mean pass@1 and standard deviation. Leakage controls are explicitly stated, confirming that test queries were constructed to have no direct overlap with KG-derived training examples. revision: yes
-
Referee: [§3 (APIKG4Syn data synthesis)] §3 (APIKG4Syn data synthesis): the method generates code pairs from the knowledge graph and UE-guided MCTS but performs no execution, unit tests, or static analysis to verify that the synthesized code correctly invokes HarmonyOS APIs or respects framework conventions. Because the improvement over GPT-4o is attributed to the quality of these pairs, the absence of any correctness check is load-bearing for the main claim.
Authors: We acknowledge that the lack of execution-based verification is a limitation for fully substantiating pair quality. Our design intentionally targets environments without runnable HarmonyOS setups, relying instead on uncertainty estimation and MCTS to prioritize high-confidence generations. In the revision, we have added a limitations paragraph in §3 and an appendix reporting static analysis results using HarmonyOS SDK linting tools on the generated code, plus a manual correctness audit on 100 randomly sampled pairs (87% confirmed correct API usage and convention adherence). These additions provide supporting evidence while preserving the environment-free contribution. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's core pipeline extracts API information from external HarmonyOS documentation into a knowledge graph, synthesizes question-code pairs via single-API extraction and UE-guided MCTS for multi-API cases, then fine-tunes an LLM and measures pass@1 on a separately constructed benchmark. This empirical result is not obtained by fitting parameters to the reported metric, redefining the target via self-citation, or smuggling an ansatz; the improvement over GPT-4o is presented as an observed outcome of the data-synthesis process rather than a quantity forced by construction from the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Single-API to Multi-API ratio
axioms (1)
- domain assumption LLMs preserve general programming logic across languages but fail on framework-specific APIs and syntax
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
APIKG4SYN, a knowledge-graph-driven data synthesis framework that creates realistic, API-grounded training samples for HarmonyOS... constructs a structured API knowledge graph from documentation... UE-driven Monte Carlo Tree Search (MCTS) to identify unfamiliar or highly correlated API nodes
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fine-tuning Qwen2.5-Coder-7B with APIKG4Syn achieves a pass@1 of 25.00%, outperforming untuned GPT-4o (17.59%)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Bridging Generation and Training: A Systematic Review of Quality Issues in LLMs for Code
A review of 114 studies creates taxonomies for code and data quality issues, formalizes 18 propagation mechanisms from training data defects to LLM-generated code defects, and synthesizes detection and mitigation techniques.
Reference graph
Works this paper leans on
-
[1]
Gabin An, Minhyuk Kwon, Kyunghwa Choi, Jooyong Yi, and Shin Yoo. 2023. BUGSC++: A Highly Usable Real World Defect Benchmark for C/C++. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). 2034–2037. https://doi.org/10.1109/ASE56229.2023.00208
-
[2]
anonymous. 2025. ADADEC. https://github.com/SYSUSELab/APIKG4SYN
work page 2025
-
[3]
Peter Auer, Nicolò Cesa-Bianchi, and Paul Fischer. 2002. Finite-Time Analysis of the Multiarmed Bandit Problem. Machine Learning47, 3 (2002), 235–256. https://doi.org/10.1023/A:1013689704352
-
[4]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. Program Synthesis with Large Language Models. arXiv:2108.07732 [cs.PL] https://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
Jialun Cao, Yuk-Kit Chan, Zixuan Ling, Wenxuan Wang, Shuqing Li, Mingwei Liu, Ruixi Qiao, Yuting Han, Chaozheng Wang, Boxi Yu, Pinjia He, Shuai Wang, Zibin Zheng, Michael R. Lyu, and Shing-Chi Cheung. 2025. How Should We Build A Benchmark? Revisiting 274 Code-Related Benchmarks For LLMs. arXiv:2501.10711 [cs.SE] https: //arxiv.org/abs/2501.10711
-
[6]
Jialun Cao, Zhiyong Chen, Jiarong Wu, Shing-Chi Cheung, and Chang Xu. 2024. JavaBench: A Benchmark of Object- Oriented Code Generation for Evaluating Large Language Models. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering(Sacramento, CA, USA)(ASE ’24). Association for Computing Machinery, New York, NY, USA, 870...
- [7]
- [9]
- [10]
-
[11]
Xueying Du, Mingwei Liu, Kaixin Wang, Hanlin Wang, Junwei Liu, Yixuan Chen, Jiayi Feng, Chaofeng Sha, Xin Peng, and Yiling Lou. 2023. ClassEval: A Manually-Crafted Benchmark for Evaluating LLMs on Class-level Code Generation. arXiv:2308.01861 [cs.CL] https://arxiv.org/abs/2308.01861
-
[12]
Xueying Du, Yiling Lou, Mingwei Liu, Xin Peng, and Tianyong Yang. 2023. KG4CraSolver: Recommending Crash Solutions via Knowledge Graph(ESEC/FSE 2023). Association for Computing Machinery, New York, NY, USA, 1242–1254. https://doi.org/10.1145/3611643.3616317
-
[13]
Kevin Ellis, Catherine Wong, Maxwell Nye, Mathias Sable-Meyer, Luc Cary, Lucas Morales, Luke Hewitt, Armando Solar-Lezama, and Joshua B. Tenenbaum. 2020. DreamCoder: Growing generalizable, interpretable knowledge with wake-sleep Bayesian program learning. arXiv:2006.08381 [cs.AI] https://arxiv.org/abs/2006.08381
-
[14]
DeepSeek-AI et al. 2025. DeepSeek-V3 Technical Report. arXiv:2412.19437 [cs.CL] https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Mark Chen et al. 2021. Evaluating Large Language Models Trained on Code. (2021). arXiv:2107.03374 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Tom B et al. 2020. Language Models are Few-Shot Learners. arXiv:2005.14165 [cs.CL] https://arxiv.org/abs/2005.14165
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[17]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. In Findings of the Association for Computational Linguistics: EMNLP 2020, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational ...
- [18]
-
[19]
Daya Guo, Canwen Xu, Nan Duan, Jian Yin, and Julian McAuley. 2023. LongCoder: a long-range pre-trained language model for code completion. InProceedings of the 40th International Conference on Machine Learning(Honolulu, Hawaii, USA)(ICML’23). JMLR.org, Article 486, 10 pages
work page 2023
-
[20]
Himanshu Gupta, Kevin Scaria, Ujjwala Anantheswaran, Shreyas Verma, Mihir Parmar, Saurabh Arjun Sawant, Chitta Baral, and Swaroop Mishra. 2024. TarGEN: Targeted Data Generation with Large Language Models. InFirst Conference on Language Modeling. https://openreview.net/forum?id=gpgMRWgv9Q
work page 2024
-
[21]
Zhuobing Han, Xiaohong Li, Hongtao Liu, Zhenchang Xing, and Zhiyong Feng. 2018. DeepWeak: Reasoning common software weaknesses via knowledge graph embedding. In2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering (SANER). 456–466. https://doi.org/10.1109/SANER.2018.8330232
- [22]
-
[23]
Kaifeng He, Mingwei Liu, Chong Wang, Zike Li, Yanlin Wang, Xin Peng, and Zibin Zheng. 2025. Towards Better Code Generation: Adaptive Decoding with Uncertainty Guidance. arXiv:2506.08980 [cs.SE] https://arxiv.org/abs/2506.08980
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [24]
-
[25]
Xue Jiang, Yihong Dong, Lecheng Wang, Zheng Fang, Qiwei Shang, Ge Li, Zhi Jin, and Wenpin Jiao. 2024. Self-Planning Code Generation with Large Language Models.ACM Trans. Softw. Eng. Methodol.33, 7, Article 182 (Sept. 2024), 30 pages. https://doi.org/10.1145/3672456
- [26]
-
[27]
Saravanan Krishnan, Amith Singhee, Keerthi Narayan Raghunath, Alex Mathai, Atul Kumar, and David Wenk
-
[28]
arXiv:2505.06885 [cs.SE] https://arxiv.org/abs/2505.06885
Incremental Analysis of Legacy Applications Using Knowledge Graphs for Application Modernization. arXiv:2505.06885 [cs.SE] https://arxiv.org/abs/2505.06885
-
[29]
Hongwei Li, Sirui Li, Jiamou Sun, Zhenchang Xing, Xin Peng, Mingwei Liu, and Xuejiao Zhao. 2018. Improving API Caveats Accessibility by Mining API Caveats Knowledge Graph. In2018 IEEE International Conference on Software Maintenance and Evolution, ICSME 2018, Madrid, Spain, September 23-29, 2018. IEEE Computer Society, 183–193. https://doi.org/10.1109/ICS...
-
[30]
Jia Li, Yongmin Li, Ge Li, Zhi Jin, Yiyang Hao, and Xing Hu. 2023. SKCODER: A Sketch-Based Approach for Automatic Code Generation. InProceedings of the 45th International Conference on Software Engineering(Melbourne, Victoria, Australia)(ICSE ’23). IEEE Press, 2124–2135. https://doi.org/10.1109/ICSE48619.2023.00179
- [31]
- [32]
-
[33]
Mingwei Liu, Xin Peng, Andrian Marcus, Christoph Treude, Jiazhan Xie, Huanjun Xu, and Yanjun Yang. 2022. How to formulate specific how-to questions in software development?. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2022, Singapore, Singapore, November 14...
-
[34]
Mingwei Liu, Xin Peng, Andrian Marcus, Zhenchang Xing, Wenkai Xie, Shuangshuang Xing, and Yang Liu. 2019. Generating query-specific class API summaries. InProceedings of the ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/SIGSOFT FSE 2019, Tallinn, Estonia, August 26-30, 2019. AC...
-
[35]
Mingwei Liu, Xin Peng, Xiujie Meng, Huanjun Xu, Shuangshuang Xing, Xin Wang, Yang Liu, and Gang Lv. 2020. Source Code based On-demand Class Documentation Generation. InIEEE International Conference on Software Maintenance and Evolution, ICSME 2020, Adelaide, Australia, September 28 - October 2, 2020. IEEE, 864–865. https://doi.org/10.1109/ ICSME46990.2020.00114
-
[36]
Mingwei Liu, Tianyong Yang, Yiling Lou, Xueying Du, Ying Wang, and Xin Peng. 2023. CodeGen4Libs: A Two-Stage Approach for Library-Oriented Code Generation. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). 434–445. https://doi.org/10.1109/ASE56229.2023.00159
-
[37]
Mingwei Liu, Yanjun Yang, Yiling Lou, Xin Peng, Zhong Zhou, Xueying Du, and Tianyong Yang. 2023. Recommending Analogical APIs via Knowledge Graph Embedding. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering(San Francisco, CA, USA)(ESEC/FSE 2023). Association for Computing ...
-
[38]
Runlin Liu, Yuhang Lin, Yunge Hu, Zhe Zhang, and Xiang Gao. 2024. LLM-Based Java Concurrent Program to ArkTS Converter. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE ’24) (Sacramento, CA, USA). Association for Computing Machinery (ACM), 2403–2406. https://doi.org/10.1145/3691620. 3695362
-
[39]
Yang Liu, Mingwei Liu, Xin Peng, Christoph Treude, Zhenchang Xing, and Xiaoxin Zhang. 2020. Generating Concept based API Element Comparison Using a Knowledge Graph. In35th IEEE/ACM International Conference on Automated Software Engineering, ASE 2020, Melbourne, Australia, September 21-25, 2020. IEEE, 834–845. https://doi.org/10.1145/ 3324884.3416628
- [40]
- [41]
-
[42]
Somshubra Majumdar, Vahid Noroozi, Mehrzad Samadi, Sean Narenthiran, Aleksander Ficek, Wasi Uddin Ahmad, Jocelyn Huang, Jagadeesh Balam, and Boris Ginsburg. 2025. Genetic Instruct: Scaling up Synthetic Generation of Coding Instructions for Large Language Models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol...
-
[43]
Nicholas Metropolis and Stanislaw Ulam. 1949. The Monte Carlo method.J. Amer. Statist. Assoc.44, 247 (1949), 335–341. https://doi.org/10.1080/01621459.1949.10483310
- [44]
-
[45]
Gonzalez, Elizabeth Polgreen, and Sanjit A
Federico Mora, Justin Wong, Haley Lepe, Sahil Bhatia, Karim Elmaaroufi, George Varghese, Joseph E. Gonzalez, Elizabeth Polgreen, and Sanjit A. Seshia. 2024. Synthetic Programming Elicitation for Text-to-Code in Very Low-Resource Programming and Formal Languages. arXiv:2406.03636 [cs.PL] https://arxiv.org/abs/2406.03636
- [46]
-
[47]
Rangeet Pan, Ali Reza Ibrahimzada, Rahul Krishna, Divya Sankar, Lambert Pouguem Wassi, Michele Merler, Boris Sobolev, Raju Pavuluri, Saurabh Sinha, and Reyhaneh Jabbarvand. 2024. Lost in Translation: A Study of Bugs Introduced by Large Language Models while Translating Code. InProceedings of the IEEE/ACM 46th International Conference on Software Engineeri...
-
[48]
Xin Peng, Yifan Zhao, Mingwei Liu, Fengyi Zhang, Yang Liu, Xin Wang, and Zhenchang Xing. 2018. Automatic Generation of API Documentations for Open-Source Projects. InIEEE Third International Workshop on Dynamic Software Documentation, DySDoc@ICSME 2018, Madrid, Spain, September 25, 2018. IEEE, 7–8. https://doi.org/10.1109/ DySDoc3.2018.00010
- [49]
-
[50]
Dennis Schiese, Aleksandr Perevalov, and Andreas Both. 2024. Towards LLM-generated explanations for component- based knowledge graph question answering systems. (9 2024). https://doi.org/10.6084/m9.figshare.27079687.v2
-
[51]
C. E. Shannon. 1948. A mathematical theory of communication.The Bell System Technical Journal27, 3 (1948), 379–423. https://doi.org/10.1002/j.1538-7305.1948.tb01338.x
-
[52]
Yunfan Shao, Linyang Li, Yichuan Ma, Peiji Li, Demin Song, Qinyuan Cheng, Shimin Li, Xiaonan Li, Pengyu Wang, Qipeng Guo, Hang Yan, Xipeng Qiu, Xuanjing Huang, and Dahua Lin. 2025. Case2Code: Scalable Synthetic Data for Code Generation. InProceedings of the 31st International Conference on Computational Linguistics, Owen Rambow, Leo Wanner, Marianna Apidi...
work page 2025
- [53]
-
[54]
Yanqi Su, Zhenchang Xing, Xin Peng, Xin Xia, Chong Wang, Xiwei Xu, and Liming Zhu. 2021. Reducing Bug Triaging Confusion by Learning from Mistakes with a Bug Tossing Knowledge Graph. In36th IEEE/ACM International Conference on Automated Software Engineering, ASE 2021, Melbourne, Australia, November 15-19, 2021. IEEE, 191–202. https://doi.org/10.1109/ASE51...
-
[55]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [56]
-
[57]
Chong Wang, Xin Peng, Mingwei Liu, Zhenchang Xing, Xuefang Bai, Bing Xie, and Tuo Wang. 2019. A learning-based approach for automatic construction of domain glossary from source code and documentation. InProceedings of the ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/SIGSOFT F...
-
[58]
Chong Wang, Xin Peng, Zhenchang Xing, and Xiujie Meng. 2023. Beyond Literal Meaning: Uncover and Explain Implicit Knowledge in Code Through Wikipedia-Based Concept Linking.IEEE Trans. Software Eng.49, 5 (2023), 3226–3240. https://doi.org/10.1109/TSE.2023.3250029
-
[59]
Chong Wang, Xin Peng, Zhenchang Xing, Yue Zhang, Mingwei Liu, Rong Luo, and Xiujie Meng. 2023. XCoS: Explainable Code Search based on Query Scoping and Knowledge Graph.ACM Transactions on Software Engineering and Methodology(2023)
work page 2023
-
[60]
Chengpeng Wang, Wuqi Zhang, Zian Su, Xiangzhe Xu, Xiaoheng Xie, and Xiangyu Zhang. 2024. LLMDFA: Analyzing Dataflow in Code with Large Language Models. InAdvances in Neural Information Processing Systems, A. Glober- son, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran Associates, Inc., 131545–131574. https://pro...
work page 2024
-
[61]
Jian Wang, Xiaofei Xie, Qiang Hu, Shangqing Liu, Jiongchi Yu, Jiaolong Kong, and Yi Li. 2025. Defects4C: Benchmarking Large Language Model Repair Capability with C/C++ Bugs. InProceedings of the 40th IEEE/ACM International Conference on Automated Software Engineering (ASE)
work page 2025
-
[62]
Lu Wang, Xiaobing Sun, Jingwei Wang, Yucong Duan, and Bin Li. 2017. Construct bug knowledge graph for bug resolution: poster. InProceedings of the 39th International Conference on Software Engineering, ICSE 2017, Buenos Aires, Argentina, May 20-28, 2017 - Companion Volume. IEEE Computer Society, 189–191. https://doi.org/10.1109/ICSE- C.2017.102
-
[63]
Yanlin Wang, Tianyue Jiang, Mingwei Liu, Jiachi Chen, Mingzhi Mao, Xilin Liu, Yuchi Ma, and Zibin Zheng. 2025. Beyond functional correctness: Investigating coding style inconsistencies in large language models.Proceedings of the ACM on Software Engineering2, FSE (2025), 690–712
work page 2025
-
[64]
Yunkun Wang, Yue Zhang, Zhen Qin, Chen Zhi, Binhua Li, Fei Huang, Yongbin Li, and Shuiguang Deng
-
[65]
arXiv:2412.05366 [cs.SE] https://arxiv.org/abs/2412.05366
ExploraCoder: Advancing code generation for multiple unseen APIs via planning and chained exploration. arXiv:2412.05366 [cs.SE] https://arxiv.org/abs/2412.05366
-
[66]
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. 2024. Magicoder: Empowering Code Generation with OSS-Instruct. InProceedings of the 41st International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235). PMLR, 52632–52657. https://proceedings.mlr.press/v235/wei24h.html
work page 2024
-
[67]
Yang Wu, Yao Wan, Zhaoyang Chu, Wenting Zhao, Ye Liu, Hongyu Zhang, Xuanhua Shi, and Philip S. Yu. 2024. Can Large Language Models Serve as Evaluators for Code Summarization? arXiv:2412.01333 [cs.SE] https://arxiv.org/abs/ , Vol. 1, No. 1, Article . Publication date: December 2025. Framework-Aware Code Generation with API Knowledge Graph–Constructed Data:...
-
[68]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agentless: Demystifying LLM-based Software Engineering Agents. arXiv:2407.01489 [cs.SE] https://arxiv.org/abs/2407.01489
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
Shuangshuang Xing, Mingwei Liu, and Xin Peng. 2021. Automatic Code Semantic Tag Generation Approach Based on Software Knowledge Graph.Journal of Software33, 11 (2021), 4027–4045
work page 2021
-
[70]
Xiangzhe Xu, Guangyu Shen, Zian Su, Siyuan Cheng, Hanxi Guo, Lu Yan, Xuan Chen, Jiasheng Jiang, Xiaolong Jin, Chengpeng Wang, Zhuo Zhang, and Xiangyu Zhang. 2025. ASTRA: Autonomous Spatial-Temporal Red-teaming for AI Software Assistants. arXiv:2508.03936 [cs.CR] https://arxiv.org/abs/2508.03936
- [71]
- [72]
-
[73]
Daoguang Zan, Bei Chen, Zeqi Lin, Bei Guan, Wang Yongji, and Jian-Guang Lou. 2022. When Language Model Meets Private Library. InFindings of the Association for Computational Linguistics: EMNLP 2022, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 277–288. https://doi.org/1...
- [74]
-
[75]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. 2024. LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations). Association for Computational Linguistics, Bangkok, Thaila...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.