Time-Constrained Recommendations: Reinforcement Learning Strategies for E-Commerce
Pith reviewed 2026-05-16 22:20 UTC · model grok-4.3
The pith
Reinforcement learning policies outperform contextual bandits for e-commerce recommendations under tight user time budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
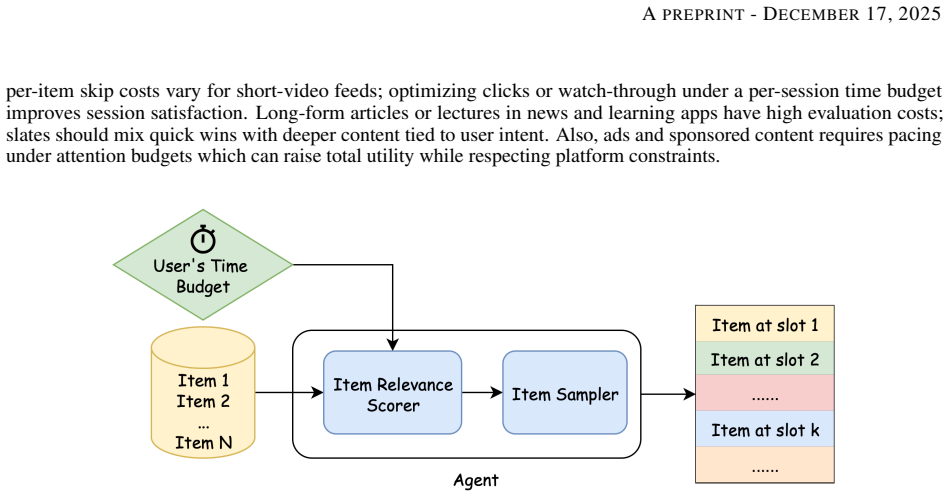
By casting time-constrained slate recommendation as Markov Decision Processes with budget-aware utilities and testing on a simulation built from re-ranking data, the authors find that on-policy and off-policy reinforcement learning control improve performance under tight time budgets relative to contextual bandit methods.
What carries the argument
Markov Decision Processes equipped with budget-aware utilities that treat sequential slate selection as actions whose rewards incorporate both relevance and per-item evaluation cost.
If this is right
- Policies learn to avoid high-cost items that exceed remaining user time, increasing the fraction of recommendations that receive clicks.
- Both on-policy methods such as policy gradients and off-policy methods such as Q-learning yield measurable gains when budgets are tight.
- The MDP formulation unifies preference learning with cost awareness, supporting sequential optimization across multiple slates.
- The simulation framework permits controlled study of policy behavior on re-ranking data without requiring live user traffic.
Where Pith is reading between the lines
- The same budget-aware MDP approach could be applied to other scrolling interfaces such as news or video feeds where evaluation cost also limits total consumption.
- Production systems might replace bandit layers with these policies once cost estimates are learned from logged interaction times rather than simulated values.
- Varying time budgets across users could be handled by conditioning the MDP state on observed scroll speed or session length.
- If the gains hold in live traffic, platforms would gain a practical reason to move beyond contextual bandits for any interface that imposes hard attention limits.
Load-bearing premise
The simulation framework and re-ranking dataset accurately reflect real user time budgets and the costs of evaluating items within slates.
What would settle it
A live A/B test on an e-commerce platform that measures click-through rate and total engagement time for the learned policies versus bandit baselines, using observed scrolling patterns to define time budgets, would show no statistically significant improvement.
Figures




read the original abstract
Unlike traditional recommendation tasks, finite user time budgets introduce a critical resource constraint, requiring the recommender system to balance item relevance and evaluation cost. For example, in a mobile shopping interface, users interact with recommendations by scrolling, where each scroll triggers a list of items called slate. Users incur an evaluation cost - time spent assessing item features before deciding to click. Highly relevant items having higher evaluation costs may not fit within the user's time budget, affecting engagement. In this position paper, our objective is to evaluate reinforcement learning algorithms that learn patterns in user preferences and time budgets simultaneously, crafting recommendations with higher engagement potential under resource constraints. Our experiments explore the use of reinforcement learning to recommend items for users using Alibaba's Personalized Re-ranking dataset supporting slate optimization in e-commerce contexts. Our contributions include (i) a unified formulation of time-constrained slate recommendation modeled as Markov Decision Processes (MDPs) with budget-aware utilities; (ii) a simulation framework to study policy behavior on re-ranking data; and (iii) empirical evidence that on-policy and off-policy control can improve performance under tight time budgets than traditional contextual bandit-based methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a position paper that formulates time-constrained slate recommendation as a Markov Decision Process (MDP) with budget-aware utilities, introduces a simulation framework built on Alibaba's Personalized Re-ranking dataset, and reports empirical results claiming that on-policy and off-policy RL methods outperform contextual bandit baselines when user time budgets are tight.
Significance. If the simulation accurately reflects real user scrolling costs and slate dynamics, the unified MDP formulation could meaningfully extend reinforcement learning applications in e-commerce by explicitly trading off relevance against evaluation cost. The work highlights a practical constraint often ignored in standard recsys benchmarks and provides a reusable simulation setup for future study. However, the absence of external validation or detailed metric reporting currently limits the strength of the claimed performance gains.
major comments (2)
- [Simulation Framework] Simulation framework section: the paper does not specify whether per-item evaluation costs are estimated from logged scroll/dwell times or assigned as fixed/synthetic values. Because the central claim is that RL improves engagement under tight budgets precisely by respecting cumulative costs, this modeling choice is load-bearing and must be documented with explicit equations or pseudocode for cost generation.
- [Experiments] Experiments section: no performance metrics (e.g., click-through rate, cumulative reward, budget utilization), statistical tests, or baseline implementation details (hyperparameters, feature representations for contextual bandits) are reported. Without these, the empirical comparison to bandits cannot be evaluated and the claim that RL is superior under tight budgets remains unsubstantiated.
minor comments (1)
- [Abstract] Abstract: the phrasing 'supporting slate optimization in e-commerce contexts' is vague; explicitly link it to the three listed contributions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our position paper. The comments identify key areas where additional documentation and reporting will strengthen the manuscript, and we address each point below with plans for revision.
read point-by-point responses
-
Referee: [Simulation Framework] Simulation framework section: the paper does not specify whether per-item evaluation costs are estimated from logged scroll/dwell times or assigned as fixed/synthetic values. Because the central claim is that RL improves engagement under tight budgets precisely by respecting cumulative costs, this modeling choice is load-bearing and must be documented with explicit equations or pseudocode for cost generation.
Authors: We agree that the simulation framework section requires explicit documentation of the cost modeling process. The revised manuscript will add a new subsection with equations defining per-item evaluation costs as functions of logged scroll and dwell times from the Alibaba Personalized Re-ranking dataset, along with pseudocode for the cumulative cost computation and budget-aware utility calculation. This will clarify that costs are derived from real user interaction logs rather than fixed or purely synthetic values. revision: yes
-
Referee: [Experiments] Experiments section: no performance metrics (e.g., click-through rate, cumulative reward, budget utilization), statistical tests, or baseline implementation details (hyperparameters, feature representations for contextual bandits) are reported. Without these, the empirical comparison to bandits cannot be evaluated and the claim that RL is superior under tight budgets remains unsubstantiated.
Authors: We acknowledge that the current experimental reporting is insufficient to fully substantiate the performance claims. In the revised version, we will expand the Experiments section to include tables with click-through rates, cumulative rewards, and budget utilization metrics across varying time budget levels. We will also report hyperparameter settings for the on-policy and off-policy RL methods, feature representations used for the contextual bandit baselines, and results of statistical significance tests (e.g., paired t-tests with p-values) comparing RL policies to the bandit baselines under tight budgets. revision: yes
Circularity Check
No significant circularity; formulation and results rest on external dataset and standard MDP concepts
full rationale
The paper models time-constrained slate recommendation as an MDP with budget-aware utilities and evaluates on-policy/off-policy RL versus contextual bandits via simulation on Alibaba's public Personalized Re-ranking dataset. No equations or claims reduce by construction to self-fitted parameters, self-citations, or renamed inputs; the simulation is presented as an experimental tool rather than a source of definitional predictions. The empirical claim of improved performance under tight budgets is therefore not forced by the paper's own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- time budget parameters
axioms (1)
- domain assumption User evaluation costs for items can be modeled from interaction patterns in the dataset
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Item i carries an evaluation cost ci measured in seconds... max_S sum beta_i s.t. sum ci <= u (0/1 Knapsack formulation)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
State st = (ut, qt) ... reward rt ~ Bernoulli(beta) if ci <= ut else 0
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Is Sliding Window All You Need? An Open Framework for Long-Sequence Recommendation
An open framework shows sliding-window training on long sequences is practical for recommenders, with a k-shift embedding enabling million-scale vocabularies on commodity GPUs and up to 6% gains on Retailrocket at 4x ...
Reference graph
Works this paper leans on
-
[1]
Alibaba Re-Ranking dataset.https://github.com/hf4Academic/PRM, 2019
Alibaba Group. Alibaba Re-Ranking dataset.https://github.com/hf4Academic/PRM, 2019
work page 2019
-
[2]
Personalized Re-ranking for Recommendation
Changhua Pei, Yi Zhang, Yongfeng Zhang, Fei Sun, Xiao Lin, Hanxiao Sun, Jian Wu, Peng Jiang, and Wenwu Ou. Personalized Re-ranking for Recommendation. InProceedings of the 13th ACM Conference on Recommender Systems (RecSys ’19), Copenhagen, Denmark, 2019. ACM
work page 2019
-
[3]
G. Rummery and Mahesan Niranjan. On-line q-learning using connectionist systems.Technical Report CUED/F- INFENG/TR 166, 11 1994
work page 1994
-
[4]
Youzhi Zhang, Sayak Chakrabarty, Rui Liu, Andrea Pugliese, and V . S. Subrahmanian. A New Dynamically Changing Attack on Review Fraud Systems and a Dynamically Changing Ensemble Defense. In2022 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Com- puting, Intl Conf on Cloud and Big Data Computing, Intl ...
work page 2022
-
[5]
Reinforcement learning based recommender systems: A survey.ACM Computing Surveys, 55(7):1–38, 2022
M Mehdi Afsar, Trafford Crump, and Behrouz Far. Reinforcement learning based recommender systems: A survey.ACM Computing Surveys, 55(7):1–38, 2022
work page 2022
-
[6]
Youzhi Zhang, Sayak Chakrabarty, Rui Liu, Andrea Pugliese, and VS Subrahmanian. SockDef: A dynamically adaptive defense to a novel attack on review fraud detection engines.IEEE Transactions on Computational Social Systems, 11(4):5253–5265, 2023
work page 2023
-
[7]
Q-learning.Machine Learning, 8(3):279–292, May 1992
Christopher J C H Watkins and Peter Dayan. Q-learning.Machine Learning, 8(3):279–292, May 1992
work page 1992
-
[8]
Off-policy evaluation for slate recommendation
Adith Swaminathan, Akshay Krishnamurthy, Alekh Agarwal, Miro Dudik, John Langford, Damien Jose, and Imed Zitouni. Off-policy evaluation for slate recommendation. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
work page 2017
-
[9]
Shreyas Chaudhari, David Arbour, Georgios Theocharous, and Nikos Vlassis. Distributional Off-Policy Evaluation for Slate Recommendations.Proceedings of the AAAI Conference on Artificial Intelligence, 38(8):8265–8273, Mar. 2024
work page 2024
-
[10]
Judicial support tool: Finding the k most likely judicial worlds
Maksim Bolonkin, Sayak Chakrabarty, Cristian Molinaro, and VS Subrahmanian. Judicial support tool: Finding the k most likely judicial worlds. InInternational Conference on Scalable Uncertainty Management, pages 53–69. Springer, 2024
work page 2024
-
[11]
MM-PoE: Multiple Choice Reasoning via
Sayak Chakrabarty and Souradip Pal. MM-PoE: Multiple Choice Reasoning via. Process of Elimination using Multi-Modal Models.Journal of Open Source Software, 10(108):7783, 2025
work page 2025
-
[12]
Sayak Chakrabarty and Souradip Pal. ReadmeReady: Free and Customizable Code Documentation with LLMs-A Fine-Tuning Approach.Journal of Open Source Software, 10(108):7489, 2025
work page 2025
-
[13]
Imon Banerjee and Sayak Chakrabarty. CLT and Edgeworth Expansion for m-out-of-n Bootstrap Estimators of The Studentized Median.arXiv preprint arXiv:2505.11725, 2025
-
[14]
Peter Sunehag, Richard Evans, Gabriel Dulac-Arnold, Yori Zwols, Daniela Visentin, and Ben Coppin. Deep Reinforcement Learning with Attention for Slate Markov Decision Processes with High-Dimensional States and Actions.ArXiv, abs/1512.01124, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[15]
SlateQ: A Tractable Decomposition for Reinforcement Learning with Recommendation Sets
Eugene Ie, Vihan Jain, Jing Wang, Sanmit Narvekar, Ritesh Agarwal, Rui Wu, Heng-Tze Cheng, Tushar Chandra, and Craig Boutilier. SlateQ: A Tractable Decomposition for Reinforcement Learning with Recommendation Sets. InIJCAI, volume 19, pages 2592–2599, 2019
work page 2019
-
[16]
Generative slate recommendation with reinforcement learning
Romain Deffayet, Thibaut Thonet, Jean-Michel Renders, and Maarten De Rijke. Generative slate recommendation with reinforcement learning. InProceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, pages 580–588, 2023
work page 2023
-
[17]
Deep Reinforcement Learning for List-wise Recommendations
Xiangyu Zhao, Liang Zhang, Long Xia, Zhuoye Ding, Dawei Yin, and Jiliang Tang. Deep reinforcement learning for list-wise recommendations.arXiv preprint arXiv:1801.00209, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[18]
Deep reinforcement learning for page-wise recommendations
Xiangyu Zhao, Long Xia, Liang Zhang, Zhuoye Ding, Dawei Yin, and Jiliang Tang. Deep reinforcement learning for page-wise recommendations. InProceedings of the 12th ACM conference on recommender systems, pages 95–103, 2018. 8 APREPRINT- DECEMBER17, 2025
work page 2018
-
[19]
Yuanguo Lin, Yong Liu, Fan Lin, Lixin Zou, Pengcheng Wu, Wenhua Zeng, Huanhuan Chen, and Chunyan Miao. A survey on reinforcement learning for recommender systems.IEEE Transactions on Neural Networks and Learning Systems, 35(10):13164–13184, 2023
work page 2023
-
[20]
Reinforcement Learning for Budget Constrained Recommendations
Ehtsham Elahi. Reinforcement Learning for Budget Constrained Recommendations. https:// netflixtechblog.com/, 2020. Netflix Technology Blog
work page 2020
-
[21]
DRN: A deep reinforcement learning framework for news recommendation
Guanjie Zheng, Fuzheng Zhang, Zihan Zheng, Yang Xiang, Nicholas Jing Yuan, Xing Xie, and Zhenhui Li. DRN: A deep reinforcement learning framework for news recommendation. InProceedings of the 2018 world wide web conference, pages 167–176, 2018
work page 2018
-
[22]
Eugene Ie, Vihan Jain, Jing Wang, Sanmit Narvekar, Ritesh Agarwal, Rui Wu, Heng-Tze Cheng, Morgane Lustman, Vince Gatto, Paul Covington, Jim McFadden, Tushar Chandra, and Craig Boutilier. Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology.ArXiv, abs/1905.12767, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[23]
Reinforcement Learning to Optimize Long-term User Engagement in Recommender Systems
Lixin Zou, Long Xia, Zhuoye Ding, Jiaxing Song, Weidong Liu, and Dawei Yin. Reinforcement Learning to Optimize Long-term User Engagement in Recommender Systems. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’19, page 2810–2818, New York, NY , USA, 2019. Association for Computing Machinery
work page 2019
-
[24]
Feng Liu, Ruiming Tang, Xutao Li, Weinan Zhang, Yunming Ye, Haokun Chen, Huifeng Guo, and Yuzhou Zhang. Deep reinforcement learning based recommendation with explicit user-item interactions modeling.arXiv preprint arXiv:1810.12027, 2018
-
[25]
XGBoost: A Scalable Tree Boosting System
Tianqi Chen and Carlos Guestrin. XGBoost: A Scalable Tree Boosting System. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, page 785–794, New York, NY , USA, 2016. Association for Computing Machinery. 9
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.