Recognition: 2 theorem links
· Lean TheoremAgenticSZZ: Temporal Knowledge Graph-Guided Agentic Bug-Inducing Commit Identification
Pith reviewed 2026-05-16 08:23 UTC · model grok-4.3
The pith
AgenticSZZ reframes bug-inducing commit identification as a temporal graph search problem solved by an LLM agent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By converting bug-inducing commit identification from a blame-based ranking task into a temporal graph search problem, AgenticSZZ constructs a TKG that encodes commits with temporal and structural edges and then deploys an LLM agent to navigate that graph using tools for candidate exploration and causal analysis, thereby recovering bug origins that lie beyond direct blame results.
What carries the argument
A temporal knowledge graph (TKG) that represents commits and their time-ordered relationships, navigated by an LLM agent using dedicated tools for exploration and causal inference.
If this is right
- Context expansion through file-history traversal discovers ancestor commits that standard blame misses.
- The combination of TKG structure and agent navigation produces an exploration-exploitation balance that improves recall without sacrificing precision.
- Stronger open-weight LLMs receive a larger performance lift from the same TKG architecture.
- BIC identification becomes usable as a building block for downstream tasks such as defect prediction and automated program repair.
Where Pith is reading between the lines
- The same TKG-plus-agent pattern could be applied to other software-evolution questions that require ordering and causal reasoning over commit history.
- Integrating additional data sources such as issue trackers or test outcomes into the TKG would likely further enlarge the set of recoverable bug origins.
- If the approach scales, it suggests that graph-based representations of version history may replace or augment blame-centric tooling in many defect-analysis pipelines.
Load-bearing premise
The LLM agent can reliably perform causal analysis over the constructed TKG without introducing incorrect inferences about which commit introduced the bug.
What would settle it
Manual inspection of the 60 additional true-positive bug-inducing commits reported by AgenticSZZ but missed by baselines, to determine whether those commits are in fact the ones that introduced the defects.
Figures




read the original abstract
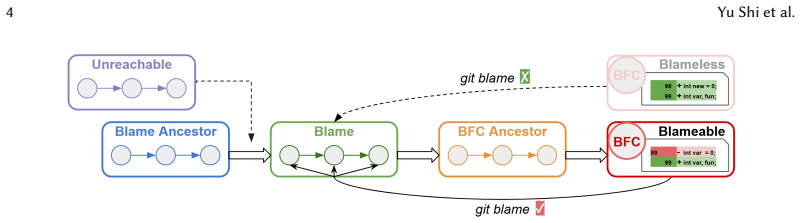
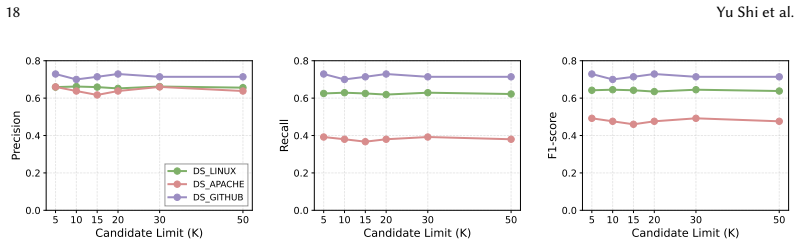
Identifying Bug-Inducing Commits (BICs) is fundamental for understanding software defects and enabling downstream tasks such as defect prediction and automated program repair. Yet existing SZZ-based approaches rely on git blame, restricting the search space to commits that directly modified the fixed lines. Our preliminary study on 2,102 validated bug-fixing commits reveals this limitation is significant: 28% of BICs require traversing commit history beyond blame results and 14% are blameless. We present AgenticSZZ, the first approach to apply Temporal Knowledge Graphs (TKGs) to software evolution analysis. AgenticSZZ reframes BIC identification from ranking blame commits into a graph search problem, where temporal ordering is fundamental to causal reasoning about bug introduction. The approach operates in two phases: (1) constructing a TKG that encodes commits with temporal and structural relationships, expanding the search space by traversing file history backward from blame commits and the bug-fixing commit; and (2) leveraging an LLM agent to navigate the graph using specialized tools for candidate exploration and causal analysis. Evaluation on three datasets shows that AgenticSZZ achieves F1-scores of 0.47 to 0.79, with statistically significant F1 improvements over state-of-the-art by up to 34%. Ablation confirms that both components and context expansion each contribute: the TKG and agent form an exploration-exploitation synergy, while context expansion unlocks ancestor BIC discovery, yielding 60 additional true positives. A sensitivity analysis across five open-weight LLMs reveals that effective TKG navigation requires sufficiently capable models, and that the TKG architecture amplifies stronger LLMs, widening the advantage. By transforming BIC identification into graph search, we open a new direction for temporal and causal reasoning in software evolution analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgenticSZZ, which reframes Bug-Inducing Commit (BIC) identification as a graph search problem by constructing a Temporal Knowledge Graph (TKG) that encodes commits with temporal and structural relationships, expanding the search space beyond git blame via file history traversal. An LLM agent then navigates this TKG using specialized tools for exploration and causal analysis. On three datasets, it reports F1 scores of 0.47–0.79 with up to 34% statistically significant improvement over SOTA SZZ baselines, supported by ablations showing TKG-agent synergy and 60 additional true positives from context expansion, plus sensitivity analysis across LLMs.
Significance. If the central empirical claims hold after addressing validation gaps, the work would be significant for software engineering by being the first to apply TKGs to software evolution analysis and demonstrating that agentic causal reasoning over expanded temporal graphs can outperform blame-restricted methods. The preliminary finding that 28% of BICs require non-blame traversal, combined with the ablation results, provides concrete evidence for the value of broader search plus structured reasoning, opening a promising direction for temporal/causal techniques in defect prediction and automated repair.
major comments (3)
- [Evaluation] Evaluation section: the manuscript reports statistically significant F1 improvements and 60 additional true positives from context expansion, but provides no details on the exact statistical tests, p-value thresholds, effect sizes, or multiple-comparison corrections applied across the three datasets and five LLMs; this makes it impossible to verify the robustness of the 'up to 34%' claim.
- [Dataset construction] Dataset construction and ground-truth validation: while the preliminary study on 2,102 bug-fixing commits is cited to motivate the 28% non-blame and 14% blameless cases, the paper gives insufficient information on how these commits and their ground-truth BICs were collected, validated, or sampled, raising the risk that selection bias toward blame-failure cases inflates the measured benefit of TKG expansion.
- [Agent causal analysis] Agent causal analysis: no error analysis, human review, or inter-annotator agreement is reported for the LLM agent's specific tool calls and causal inferences on the TKG; without this, the ablation results cannot distinguish whether the F1 gains derive from reliable reasoning or simply from the larger candidate pool produced by file-history traversal.
minor comments (2)
- [Sensitivity analysis] The sensitivity analysis across LLMs is useful but would be strengthened by reporting the exact prompts and tool-calling formats used for each model.
- [Figures] Figure captions and legends for the TKG diagrams should explicitly label temporal edge directions and node attributes to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which has helped us identify areas to strengthen the manuscript. We address each major comment point by point below, outlining specific revisions we will make to improve clarity, transparency, and rigor.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the manuscript reports statistically significant F1 improvements and 60 additional true positives from context expansion, but provides no details on the exact statistical tests, p-value thresholds, effect sizes, or multiple-comparison corrections applied across the three datasets and five LLMs; this makes it impossible to verify the robustness of the 'up to 34%' claim.
Authors: We agree that the statistical methodology requires explicit documentation to allow verification of the reported improvements. In the revised manuscript, we will add a new subsection under Evaluation that specifies: (1) the exact tests employed (paired Wilcoxon signed-rank tests for F1-score comparisons, chosen due to non-normality confirmed via Shapiro-Wilk tests); (2) the significance threshold (p < 0.05); (3) effect sizes (Cohen's d for each pairwise comparison); and (4) multiple-comparison correction (Bonferroni adjustment applied across the three datasets and five LLMs, with adjusted p-values reported). We will also include the raw p-values and confidence intervals for the 'up to 34%' claim to demonstrate robustness. revision: yes
-
Referee: [Dataset construction] Dataset construction and ground-truth validation: while the preliminary study on 2,102 bug-fixing commits is cited to motivate the 28% non-blame and 14% blameless cases, the paper gives insufficient information on how these commits and their ground-truth BICs were collected, validated, or sampled, raising the risk that selection bias toward blame-failure cases inflates the measured benefit of TKG expansion.
Authors: We acknowledge that the current description of the preliminary study lacks sufficient methodological detail. The 2,102 commits were randomly sampled from 12 popular open-source Java repositories (e.g., Apache projects) using a stratified approach by project size and bug-fix frequency, with ground-truth BICs established through a multi-stage process: initial identification via SZZ variants followed by manual validation by two experienced developers per commit (with a third resolving disagreements). In the revision, we will add a dedicated subsection detailing the sampling frame, inclusion/exclusion criteria, validation protocol, and inter-rater agreement (Cohen's kappa = 0.82). We will also explicitly discuss potential selection biases and their mitigation, including a sensitivity analysis on a broader random sample. revision: yes
-
Referee: [Agent causal analysis] Agent causal analysis: no error analysis, human review, or inter-annotator agreement is reported for the LLM agent's specific tool calls and causal inferences on the TKG; without this, the ablation results cannot distinguish whether the F1 gains derive from reliable reasoning or simply from the larger candidate pool produced by file-history traversal.
Authors: We agree that the absence of error analysis limits the ability to attribute gains specifically to the agent's reasoning capabilities versus the expanded search space. In the revised version, we will add an 'Error Analysis' subsection that includes: (1) manual review of 150 randomly sampled agent trajectories (tool calls and causal inferences) by two human annotators; (2) reported accuracy rates for tool selection and causal conclusion correctness; (3) common error categories (e.g., temporal misordering); and (4) inter-annotator agreement (Cohen's kappa). This analysis will be cross-referenced with the ablation results to show that the TKG-agent synergy contributes beyond mere candidate expansion, with 60 additional true positives broken down by reasoning quality. revision: yes
Circularity Check
No significant circularity; empirical evaluation stands independently
full rationale
The paper introduces AgenticSZZ as a two-phase empirical method: TKG construction from git history (expanding beyond blame) followed by LLM-agent navigation with specialized tools. Central results are F1 scores (0.47-0.79) and statistical improvements over SZZ baselines on three datasets, plus ablations showing contribution from TKG+agent and context expansion. No equations, fitted parameters, or derivations are presented that reduce to self-inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked; the approach is framed as a new graph-search reframing with independent components. The reader's assessment of score 2.0 aligns with the absence of any reduction to fitted inputs or self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents equipped with graph navigation tools can perform reliable causal reasoning about bug introduction from commit history
invented entities (1)
-
Temporal Knowledge Graph encoding commits with temporal and structural relationships
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
temporal ordering is fundamental to causal reasoning about bug introduction... PRECEDES edges connect each commit to the next one by commit date... enabling chronological reasoning about bug introduction
-
IndisputableMonolith/Foundation/reality_from_one_distinctiontime-as-orbit certificate echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
TKG... encodes commits with temporal and structural relationships
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
AgentSZZ: Teaching the LLM Agent to Play Detective with Bug-Inducing Commits
AgentSZZ is an LLM-agent framework that identifies bug-inducing commits with up to 27.2% higher F1 scores than prior methods by enabling adaptive exploration and causal tracing, especially for cross-file and ghost commits.
Reference graph
Works this paper leans on
- [1]
-
[2]
Muhammad Asaduzzaman, Michael C. Bullock, Chanchal K. Roy, and Kevin A. Schneider. 2012. Bug introducing changes: A case study with Android. In9th IEEE Working Conference of Mining Software Repositories, MSR 2012, June 2-3, 2012, Zurich, Switzerland, Michele Lanza, Massimiliano Di Penta, and Tao Xie (Eds.). IEEE Computer Society, 116–119. doi:10.1109/MSR....
-
[3]
Gabriele Bavota, Bernardino De Carluccio, Andrea De Lucia, Massimiliano Di Penta, Rocco Oliveto, and Orazio Strollo
-
[4]
When Does a Refactoring Induce Bugs? An Empirical Study. In12th IEEE International Working Conference on Source Code Analysis and Manipulation, SCAM 2012, Riva del Garda, Italy, September 23-24, 2012. IEEE Computer Society, 104–113. doi:10.1109/SCAM.2012.20
-
[5]
Xiao Chen, Hengcheng Zhu, Jialun Cao, Ming Wen, and Shing-Chi Cheung. 2025. SemBIC: Semantic-Aware Identifica- tion of Bug-Inducing Commits.Proc. ACM Softw. Eng.2, FSE (2025), 1363–1385. doi:10.1145/3715781
-
[6]
Zimin Chen, Yue Pan, Siyu Lu, Jiayi Xu, Claire Le Goues, Martin Monperrus, and He Ye. 2025. Prometheus: Unified Knowledge Graphs for Issue Resolution in Multilingual Codebases.CoRRabs/2507.19942 (2025). arXiv:2507.19942 doi:10.48550/ARXIV.2507.19942
-
[7]
2013.Statistical Power Analysis for the Behavioral Sciences
Jacob Cohen. 2013.Statistical Power Analysis for the Behavioral Sciences. Routledge
work page 2013
-
[8]
Daniel Alencar da Costa, Shane McIntosh, Weiyi Shang, Uirá Kulesza, Roberta Coelho, and Ahmed E. Hassan. 2017. A Framework for Evaluating the Results of the SZZ Approach for Identifying Bug-Introducing Changes.IEEE Trans. Software Eng.43, 7 (2017), 641–657. doi:10.1109/TSE.2016.2616306
-
[9]
Steven Davies, Marc Roper, and Murray Wood. 2014. Comparing text-based and dependence-based approaches for determining the origins of bugs.J. Softw. Evol. Process.26, 1 (2014), 107–139. doi:10.1002/SMR.1619
-
[10]
DeepSeek-AI. 2025. DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models.CoRRabs/2512.02556 (2025). arXiv:2512.02556 doi:10.48550/ARXIV.2512.02556
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.02556 2025
-
[11]
Xueying Du, Yiling Lou, Mingwei Liu, Xin Peng, and Tianyong Yang. 2023. KG4CraSolver: Recommending Crash Solutions via Knowledge Graph. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/FSE 2023, San Francisco, CA, USA, December 3-9, 2023, Satish Chandra, Kelly Blinc...
-
[12]
Yuanrui Fan, Xin Xia, Daniel Alencar da Costa, David Lo, Ahmed E. Hassan, and Shanping Li. 2021. The Impact of Mislabeled Changes by SZZ on Just-in-Time Defect Prediction.IEEE Trans. Software Eng.47, 8 (2021), 1559–1586. doi:10.1109/TSE.2019.2929761
-
[13]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. In Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020 (Findings of ACL, Vol. EMNLP 2020), Trev...
-
[14]
Afshin Mansouri, and Yuanyuan Zhang
Mark Harman, S. Afshin Mansouri, and Yuanyuan Zhang. 2012. Search-based software engineering: Trends, techniques and applications.ACM Comput. Surv.45, 1 (2012), 11:1–11:61. doi:10.1145/2379776.2379787
-
[15]
Hassan, Hao Li, Dayi Lin, Bram Adams, Tse-Hsun Chen, Yutaro Kashiwa, and Dong Qiu
Ahmed E. Hassan, Hao Li, Dayi Lin, Bram Adams, Tse-Hsun Chen, Yutaro Kashiwa, and Dong Qiu. 2025. Agentic Software Engineering: Foundational Pillars and a Research Roadmap.CoRRabs/2509.06216 (2025). arXiv:2509.06216 doi:10.48550/ARXIV.2509.06216
-
[16]
Hideaki Hata, Osamu Mizuno, and Tohru Kikuno. 2012. Bug prediction based on fine-grained module histories. In34th International Conference on Software Engineering, ICSE 2012, June 2-9, 2012, Zurich, Switzerland, Martin Glinz, Gail C. Murphy, and Mauro Pezzè (Eds.). IEEE Computer Society, 200–210. doi:10.1109/ICSE.2012.6227193 , Vol. 1, No. 1, Article . Pu...
-
[17]
Aidan Hogan, Eva Blomqvist, Michael Cochez, Claudia d’Amato, Gerard De Melo, Claudio Gutierrez, Sabrina Kirrane, José Emilio Labra Gayo, Roberto Navigli, Sebastian Neumaier, et al. 2021. Knowledge graphs.ACM Computing Surveys (Csur)54, 4 (2021), 1–37
work page 2021
-
[18]
Hassan, Audris Mockus, Anand Sinha, and Naoyasu Ubayashi
Yasutaka Kamei, Emad Shihab, Bram Adams, Ahmed E. Hassan, Audris Mockus, Anand Sinha, and Naoyasu Ubayashi
-
[19]
Software Eng.39, 6 (2013), 757–773
A Large-Scale Empirical Study of Just-in-Time Quality Assurance.IEEE Trans. Software Eng.39, 6 (2013), 757–773. doi:10.1109/TSE.2012.70
-
[20]
Sunghun Kim and E. James Whitehead Jr. 2006. How long did it take to fix bugs?. InProceedings of the 2006 International Workshop on Mining Software Repositories, MSR 2006, Shanghai, China, May 22-23, 2006, Stephan Diehl, Harald C. Gall, and Ahmed E. Hassan (Eds.). ACM, 173–174. doi:10.1145/1137983.1138027
-
[21]
Sunghun Kim, Thomas Zimmermann, Kai Pan, and E. James Whitehead Jr. 2006. Automatic Identification of Bug- Introducing Changes. In21st IEEE/ACM International Conference on Automated Software Engineering (ASE 2006), 18-22 September 2006, Tokyo, Japan. IEEE Computer Society, 81–90. doi:10.1109/ASE.2006.23
-
[22]
Hao Li, Haoxiang Zhang, and Ahmed E. Hassan. 2025. The Rise of AI Teammates in Software Engineering (SE) 3.0: How Autonomous Coding Agents Are Reshaping Software Engineering.CoRRabs/2507.15003 (2025). arXiv:2507.15003 doi:10.48550/ARXIV.2507.15003
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.15003 2025
-
[23]
Yue Li, Bohan Liu, Ting Zhang, Zhiqi Wang, David Lo, Lanxin Yang, Jun Lyu, and He Zhang. 2025. A Knowledge Enhanced Large Language Model for Bug Localization.Proc. ACM Softw. Eng.2, FSE (2025), 1914–1936. doi:10.1145/ 3729356
work page 2025
-
[24]
Yizhou Liu, Pengfei Gao, Xinchen Wang, Jie Liu, Yexuan Shi, Zhao Zhang, and Chao Peng. 2024. MarsCode Agent: AI-native Automated Bug Fixing.CoRRabs/2409.00899 (2024). arXiv:2409.00899 doi:10.48550/ARXIV.2409.00899
-
[25]
Yunbo Lyu, Hong Jin Kang, Ratnadira Widyasari, Julia Lawall, and David Lo. 2024. Evaluating SZZ Implementations: An Empirical Study on the Linux Kernel.IEEE Trans. Software Eng.50, 9 (2024), 2219–2239. doi:10.1109/TSE.2024.3406718
-
[26]
Edmilson Campos Neto, Daniel Alencar da Costa, and Uirá Kulesza. 2018. The impact of refactoring changes on the SZZ algorithm: An empirical study. In25th International Conference on Software Analysis, Evolution and Reengineering, SANER 2018, Campobasso, Italy, March 20-23, 2018, Rocco Oliveto, Massimiliano Di Penta, and David C. Shepherd (Eds.). IEEE Comp...
-
[27]
Edmilson Campos Neto, Daniel Alencar da Costa, and Uirá Kulesza. 2019. Revisiting and Improving SZZ Implementa- tions. In2019 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement, ESEM 2019, Porto de Galinhas, Recife, Brazil, September 19-20, 2019. IEEE, 1–12. doi:10.1109/ESEM.2019.8870178
-
[28]
Namyong Park, Fuchen Liu, Purvanshi Mehta, Dana Cristofor, Christos Faloutsos, and Yuxiao Dong. 2022. EvoKG: Jointly Modeling Event Time and Network Structure for Reasoning over Temporal Knowledge Graphs. InWSDM ’22: The Fifteenth ACM International Conference on Web Search and Data Mining, Virtual Event / Tempe, AZ, USA, February 21 - 25, 2022, K. Selcuk ...
-
[29]
Luca Pascarella, Fabio Palomba, and Alberto Bacchelli. 2019. Fine-grained just-in-time defect prediction.J. Syst. Softw. 150 (2019), 22–36. doi:10.1016/J.JSS.2018.12.001
-
[30]
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. 2025. Zep: A Temporal Knowledge Graph Architecture for Agent Memory.CoRRabs/2501.13956 (2025). arXiv:2501.13956 doi:10.48550/ARXIV.2501.13956
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.13956 2025
-
[31]
Giovanni Rosa, Luca Pascarella, Simone Scalabrino, Rosalia Tufano, Gabriele Bavota, Michele Lanza, and Rocco Oliveto. 2021. Evaluating SZZ Implementations Through a Developer-informed Oracle. In43rd IEEE/ACM International Conference on Software Engineering, ICSE 2021, Madrid, Spain, 22-30 May 2021. IEEE, 436–447. doi:10.1109/ICSE43902. 2021.00049
-
[32]
Yu Shi, Hao Li, Bram Adams, and Ahmed E. Hassan. 2025. HAFixAgent: History-Aware Automated Program Repair Agent.CoRRabs/2511.01047 (2025). arXiv:2511.01047 doi:10.48550/ARXIV.2511.01047
-
[33]
Danilo Silva and Marco Túlio Valente. 2017. RefDiff: detecting refactorings in version histories. InProceedings of the 14th International Conference on Mining Software Repositories, MSR 2017, Buenos Aires, Argentina, May 20-28, 2017, Jesús M. González-Barahona, Abram Hindle, and Lin Tan (Eds.). IEEE Computer Society, 269–279. doi:10.1109/MSR.2017.14
-
[34]
Jacek Sliwerski, Thomas Zimmermann, and Andreas Zeller. 2005. When do changes induce fixes?. InProceedings of the 2005 International Workshop on Mining Software Repositories, MSR 2005, Saint Louis, Missouri, USA, May 17, 2005. ACM. doi:10.1145/1083142.1083147
-
[35]
Richard S Sutton and Andrew G Barto. 2018. Reinforcement learning: An introduction second edition.Adaptive computation and machine learning: The MIT Press, Cambridge, MA and London(2018)
work page 2018
-
[36]
Ming Tan, Lin Tan, Sashank Dara, and Caleb Mayeux. 2015. Online Defect Prediction for Imbalanced Data. In37th IEEE/ACM International Conference on Software Engineering, ICSE 2015, Florence, Italy, May 16-24, 2015, Volume 2, Antonia Bertolino, Gerardo Canfora, and Sebastian G. Elbaum (Eds.). IEEE Computer Society, 99–108. doi:10.1109/ICSE.2015.139
-
[37]
Lingxiao Tang, Lingfeng Bao, Xin Xia, and Zhongdong Huang. 2023. Neural SZZ Algorithm. In38th IEEE/ACM International Conference on Automated Software Engineering, ASE 2023, Luxembourg, September 11-15, 2023. IEEE, , Vol. 1, No. 1, Article . Publication date: February 2026. Beyond Blame: Rethinking SZZ with Knowledge Graph Search 21 1024–1035. doi:10.1109/...
-
[38]
Lingxiao Tang, Jiakun Liu, Zhongxin Liu, Xiaohu Yang, and Lingfeng Bao. 2025. LLM4SZZ: Enhancing SZZ Algorithm with Context-Enhanced Assessment on Large Language Models.Proc. ACM Softw. Eng.2, ISSTA (2025), 343–365. doi:10.1145/3728885
-
[39]
Lingxiao Tang, Chao Ni, Qiao Huang, and Lingfeng Bao. 2024. Enhancing Bug-Inducing Commit Identification: A Fine- Grained Semantic Analysis Approach.IEEE Trans. Software Eng.50, 11 (2024), 3037–3052. doi:10.1109/TSE.2024.3468296
-
[40]
Rakshit Trivedi, Hanjun Dai, Yichen Wang, and Le Song. 2017. Know-Evolve: Deep Temporal Reasoning for Dynamic Knowledge Graphs. InProceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017 (Proceedings of Machine Learning Research, Vol. 70), Doina Precup and Yee Whye Teh (Eds.). PMLR, 3462–347...
work page 2017
-
[41]
Nikolaos Tsantalis, Matin Mansouri, Laleh Mousavi Eshkevari, Davood Mazinanian, and Danny Dig. 2018. Accurate and efficient refactoring detection in commit history. InProceedings of the 40th International Conference on Software Engineering, ICSE 2018, Gothenburg, Sweden, May 27 - June 03, 2018, Michel Chaudron, Ivica Crnkovic, Marsha Chechik, and Mark Har...
-
[42]
Guoqing Wang, Zeyu Sun, Yizhou Chen, Yifan Zhao, Haiyang Shen, Qingyuan Liang, and Dan Hao. 2025. Beyond the Sum of Parts: Leveraging Entanglement for Bug Inducing Commit Localization.IEEE Transactions on Software Engineering(2025), 1–19. doi:10.1109/TSE.2025.3628362
-
[43]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, and et al. 2025. OpenHands: An Open Platform for AI Software Developers as Generalist Agents....
work page 2025
-
[44]
Ming Wen, Rongxin Wu, Yepang Liu, Yongqiang Tian, Xuan Xie, Shing-Chi Cheung, and Zhendong Su. 2019. Exploring and exploiting the correlations between bug-inducing and bug-fixing commits. InProceedings of the ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/SIGSOFT FSE 2019, Talli...
-
[45]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2024. Agentless: Demystifying LLM-based Software Engineering Agents.CoRRabs/2407.01489 (2024). arXiv:2407.01489 doi:10.48550/ARXIV.2407.01489
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.01489 2024
-
[46]
Meng Yan, Xin Xia, Yuanrui Fan, Ahmed E. Hassan, David Lo, and Shanping Li. 2022. Just-In-Time Defect Identification and Localization: A Two-Phase Framework.IEEE Trans. Software Eng.48, 2 (2022), 82–101. doi:10.1109/TSE.2020.2978819
-
[47]
Boyang Yang, Haoye Tian, Jiadong Ren, Shunfu Jin, Yang Liu, Feng Liu, and Bach Le. 2025. Enhancing Repository- Level Software Repair via Repository-Aware Knowledge Graphs.CoRRabs/2503.21710 (2025). arXiv:2503.21710 doi:10.48550/ARXIV.2503.21710
-
[48]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
-
[49]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and...
work page 2024
-
[50]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. AutoCodeRover: Autonomous Program Improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, Vienna, Austria, September 16-20, 2024, Maria Christakis and Michael Pradel (Eds.). ACM, 1592–1604. doi:10.1145/3650212.3680384 , Vo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.