Recognition: no theorem link
AgentSZZ: Teaching the LLM Agent to Play Detective with Bug-Inducing Commits
Pith reviewed 2026-05-13 20:31 UTC · model grok-4.3
The pith
An LLM agent with task-specific tools and a reasoning loop identifies bug-inducing commits more accurately than prior SZZ methods by succeeding where git blame fails.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AgentSZZ is an agent-based framework that leverages LLM-driven agents to explore repositories and identify bug-inducing commits. It integrates task-specific tools, domain knowledge, and a ReAct-style loop to enable adaptive and causal tracing of bugs, supported by a structured compression module that reduces redundant context while preserving key evidence.
What carries the argument
AgentSZZ, an LLM agent that runs a ReAct-style reasoning loop equipped with repository exploration tools and bug-domain knowledge to perform iterative causal tracing of commit origins.
If this is right
- SZZ-dependent tasks such as defect prediction and vulnerability analysis receive more complete and accurate input data because recall rises sharply on cross-file and ghost commits.
- The compression module cuts token consumption by more than 30 percent with negligible accuracy loss, making repeated agent runs practical on large repositories.
- Ablation results establish that removing either the task-specific tools or the domain knowledge sharply reduces performance, confirming both components are required.
- The ReAct loop replaces fixed pipelines, allowing the agent to adapt its search strategy to the structure of each bug report.
Where Pith is reading between the lines
- The same agent structure could be reused for related software-history tasks such as tracing the introduction of security vulnerabilities or performance regressions.
- Interactive tool-augmented agents may outperform static analysis pipelines in other code-investigation settings that require multi-step causal reasoning.
- The approach suggests a general pattern: supplying LLMs with narrow, high-precision tools plus domain rules can close performance gaps that pure text-based prompting leaves open.
Load-bearing premise
LLM agents supplied with the described tools and domain knowledge can reliably perform adaptive causal tracing of bug origins inside real code repositories, even in cases where line-based git blame cannot succeed.
What would settle it
A direct head-to-head evaluation on a fresh set of developer-annotated bug-inducing commits that contains a high proportion of cross-file and ghost cases; if AgentSZZ shows no substantial F1 improvement over the strongest prior LLM-based SZZ baseline, the central claim is false.
Figures



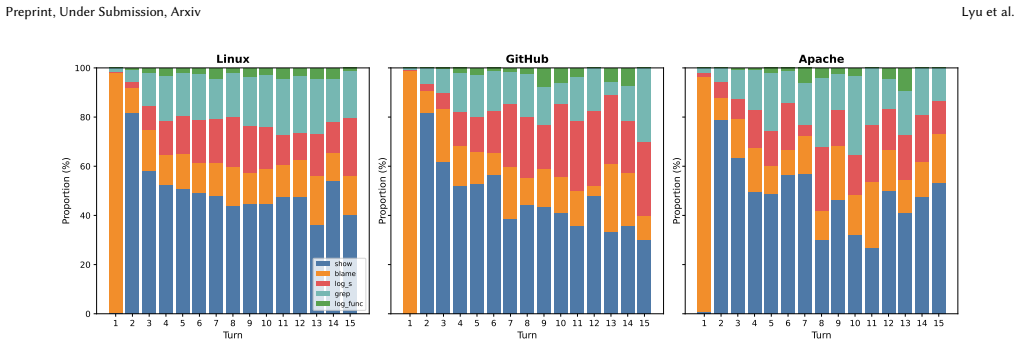
read the original abstract
The SZZ algorithm is the dominant technique for identifying bug-inducing commits and underpins many software engineering tasks, such as defect prediction and vulnerability analysis. Despite numerous variants, including recent LLM-based approaches, performance remains limited on developer-annotated datasets (e.g., recall of 0.552 on the Linux kernel). A key limitation is the reliance on git blame, which traces line-level changes within the same file, failing in common scenarios such as ghost and cross-file cases-making nearly one-quarter of bug-inducing commits inherently untraceable. Moreover, current approaches follow fixed pipelines that restrict iterative reasoning and exploration, unlike developers who investigate bugs through an interactive, multi-tool process. To address these challenges, we propose AgentSZZ, an agent-based framework that leverages LLM-driven agents to explore repositories and identify bug-inducing commits. Unlike prior methods, AgentSZZ integrates task-specific tools, domain knowledge, and a ReAct-style loop to enable adaptive and causal tracing of bugs. A structured compression module further improves efficiency by reducing redundant context while preserving key evidence. Extensive experiments on three widely used datasets show that AgentSZZ consistently outperforms state-of-the-art SZZ algorithms across all settings, achieving F1-score gains of up to 27.2% over prior LLM-based approaches. The improvements are especially pronounced in challenging scenarios such as cross-file and ghost commits, with recall gains of up to 300% and 60%, respectively. Ablation studies show that task-specific tools and domain knowledge are critical, while compression tool outputs reduce token consumption by over 30% with negligible impact. The replication package is available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AgentSZZ, an LLM-driven agent framework that employs a ReAct-style iterative loop, task-specific tools, domain knowledge, and a structured compression module to identify bug-inducing commits. Unlike prior SZZ variants that rely on fixed git-blame pipelines, AgentSZZ performs adaptive causal tracing; experiments on three developer-annotated datasets report consistent F1 gains up to 27.2 % over prior LLM-based SZZ methods, with especially large recall improvements (up to 300 % and 60 %) on cross-file and ghost commits.
Significance. If the empirical claims hold under proper statistical controls, the work would demonstrate that tool-augmented LLM agents can overcome well-known limitations of line-level blame in real repositories, offering a practical advance for downstream tasks such as defect prediction and vulnerability analysis. The availability of a replication package and the ablation results on tools and compression are positive indicators of reproducibility.
major comments (2)
- [Experimental results section] Experimental results section (and associated tables): all headline metrics (F1 = 0.272 gain, recall gains of 300 % / 60 % on cross-file/ghost subsets) are reported as single point estimates with no run-to-run variance, standard deviations, or statistical significance tests against the SOTA baselines. Because the ReAct agent performs stochastic tool use and iterative reasoning, the absence of these controls directly undermines the central claim of “consistent outperformance across all settings.”
- [Experimental results section] Baseline and data-preparation description: the manuscript does not provide sufficient detail on how the prior SZZ and LLM-based baselines were re-implemented, which data splits were used, or whether any post-hoc selection of runs occurred. Without this information it is impossible to verify that the reported deltas are not artifacts of implementation differences or cherry-picking.
minor comments (2)
- [Abstract] The abstract states that experiments were run on “three widely used datasets” but does not name them; adding the dataset names would improve immediate readability.
- [Method section] Notation for the compression module and tool interfaces could be clarified with a small diagram or pseudocode snippet to make the ReAct loop easier to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that will strengthen the empirical claims and reproducibility of the work.
read point-by-point responses
-
Referee: [Experimental results section] Experimental results section (and associated tables): all headline metrics (F1 = 0.272 gain, recall gains of 300 % / 60 % on cross-file/ghost subsets) are reported as single point estimates with no run-to-run variance, standard deviations, or statistical significance tests against the SOTA baselines. Because the ReAct agent performs stochastic tool use and iterative reasoning, the absence of these controls directly undermines the central claim of “consistent outperformance across all settings.”
Authors: We agree that single-point estimates are insufficient given the stochastic nature of the ReAct loop. In the revised manuscript we will rerun all experiments at least five times with different random seeds, report mean F1/recall scores together with standard deviations, and add statistical significance tests (Wilcoxon signed-rank test with Bonferroni correction) against each baseline. Updated tables and a new paragraph in the experimental results section will document these controls. revision: yes
-
Referee: [Experimental results section] Baseline and data-preparation description: the manuscript does not provide sufficient detail on how the prior SZZ and LLM-based baselines were re-implemented, which data splits were used, or whether any post-hoc selection of runs occurred. Without this information it is impossible to verify that the reported deltas are not artifacts of implementation differences or cherry-picking.
Authors: We acknowledge the gap in methodological transparency. The replication package already contains the exact baseline re-implementation scripts and dataset files. In the revised version we will expand the Experimental Setup subsection with: (1) a step-by-step description of how each baseline (including the prior LLM-based SZZ methods) was re-implemented, (2) explicit confirmation that the three developer-annotated datasets were used in their entirety with no custom train/test splits, and (3) a statement that no post-hoc run selection occurred. We will also add a direct pointer to the replication package in the main text. revision: yes
Circularity Check
No significant circularity; empirical evaluation is self-contained
full rationale
The paper presents an empirical framework (AgentSZZ) evaluated on three public datasets against prior SZZ baselines. Performance metrics (F1, recall) are computed directly from agent outputs on held-out bug-inducing commits; no equations, fitted parameters, or derivations reduce the reported gains to inputs defined by the same data. Ablation results and tool descriptions are likewise measured outcomes rather than self-referential. Self-citations to prior SZZ work are external benchmarks, not load-bearing justifications for the central claim. The evaluation chain is therefore independent of the reported results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can effectively use provided tools and domain knowledge to explore repositories and perform causal tracing of bugs
Reference graph
Works this paper leans on
-
[1]
ACM SIGSOFT Impact Paper Award
2026. ACM SIGSOFT Impact Paper Award. https://www2.sigsoft.org/awards/ impactpaper/
work page 2026
-
[2]
Anthropic. 2026. Claude Opus 4.6 System Card. https://www.anthropic.com/ system-cards
work page 2026
- [3]
-
[4]
Lingfeng Bao, Xin Xia, Ahmed E. Hassan, and Xiaohu Yang. 2022. V-SZZ: au- tomatic identification of version ranges affected by CVE vulnerabilities. InPro- ceedings of the 44th International Conference on Software Engineering(Pittsburgh, Pennsylvania)(ICSE ’22). Association for Computing Machinery, New York, NY, USA, 2352–2364. doi:10.1145/3510003.3510113
-
[5]
Gabriele Bavota and Barbara Russo. 2015. Four eyes are better than two: On the impact of code reviews on software quality. In2015 IEEE International Conference on Software Maintenance and Evolution (ICSME). 81–90. doi:10.1109/ICSM.2015. 7332454
-
[6]
Boyuan Chen and Zhen Ming Jiang. 2019. Extracting and studying the Logging- Code-Issue-Introducing changes in Java-based large-scale open source software systems.Empirical Software Engineering24, 4 (2019), 2285–2322
work page 2019
-
[7]
Junkai Chen, Huihui Huang, Yunbo Lyu, Junwen An, Jieke Shi, Chengran Yang, Ting Zhang, Haoye Tian, Yikun Li, Zhenhao Li, et al. 2025. SecureAgentBench: Benchmarking Secure Code Generation under Realistic Vulnerability Scenarios. arXiv preprint arXiv:2509.22097(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [8]
-
[9]
Cognition AI. 2024. Devin, AI software engineer. https://www.cognition.ai/ introducing-devin
work page 2024
-
[10]
Daniel Alencar da Costa, Shane McIntosh, Weiyi Shang, Uirá Kulesza, Roberta Coelho, and Ahmed E. Hassan. 2017. A Framework for Evaluating the Results of the SZZ Approach for Identifying Bug-Introducing Changes.IEEE Transactions on Software Engineering43, 7 (2017), 641–657. doi:10.1109/TSE.2016.2616306
-
[11]
Daniel Alencar da Costa, Shane McIntosh, Weiyi Shang, Uirá Kulesza, Roberta Coelho, and Ahmed E. Hassan. 2017. A Framework for Evaluating the Results of the SZZ Approach for Identifying Bug-Introducing Changes.IEEE Transactions on Software Engineering43, 7 (2017), 641–657. doi:10.6084/m9.figshare.31869097
-
[12]
Steven Davies, Marc Roper, and Murray Wood. 2014. Comparing text-based and dependence-based approaches for determining the origins of bugs.Journal of Software: Evolution and Process26, 1 (2014), 107–139
work page 2014
-
[13]
Yuanrui Fan, Xin Xia, Daniel Alencar Da Costa, David Lo, Ahmed E Hassan, and Shanping Li. 2019. The impact of mislabeled changes by szz on just-in-time defect prediction.IEEE transactions on software engineering47, 8 (2019), 1559–1586
work page 2019
-
[14]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, et al. 2020. Codebert: A pre-trained model for programming and natural languages.arXiv preprint arXiv:2002.08155 (2020)
work page internal anchor Pith review arXiv 2020
-
[15]
Hideaki Hata, Osamu Mizuno, and Tohru Kikuno. 2012. Bug prediction based on fine-grained module histories. In2012 34th International Conference on Software Engineering (ICSE). 200–210. doi:10.1109/ICSE.2012.6227193
-
[16]
Junda He, Christoph Treude, and David Lo. 2025. LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision and the Road Ahead.ACM Transactions on Software Engineering and Methodology(2025)
work page 2025
-
[17]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2023. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Sunghun Kim, Thomas Zimmermann, Kai Pan, and E. James Jr. Whitehead. 2006. Automatic Identification of Bug-Introducing Changes . InProceedings. 21st IEEE International Conference on Automated Software Engineering. IEEE Computer Society, Los Alamitos, CA, USA, 81–90. doi:10.1109/ASE.2006.23
-
[19]
LaToza, Gina Venolia, and Robert DeLine
Thomas D. LaToza, Gina Venolia, and Robert DeLine. 2006. Maintaining mental models: a study of developer work habits. InProceedings of the 28th International Conference on Software Engineering(Shanghai, China)(ICSE ’06). Association for Computing Machinery, New York, NY, USA, 492–501. doi:10.1145/1134285. 1134355
-
[20]
Joseph Lawrance, Christopher Bogart, Margaret Burnett, Rachel Bellamy, Kyle Rector, and Scott D. Fleming. 2013. How Programmers Debug, Revisited: An Infor- mation Foraging Theory Perspective.IEEE Transactions on Software Engineering 39, 2 (2013), 197–215. doi:10.1109/TSE.2010.111
-
[21]
Junwei Liu, Kaixin Wang, Yixuan Chen, Xin Peng, Zhenpeng Chen, Lingming Zhang, and Yiling Lou. 2026. Large Language Model-Based Agents for Software Engineering: A Survey.ACM Trans. Softw. Eng. Methodol.(March 2026). doi:10. 1145/3796507 Just Accepted
work page 2026
-
[22]
Shuyang Liu, Yang Chen, Rahul Krishna, Saurabh Sinha, Jatin Ganhotra, and Reyhan Jabbarvand. 2025. Process-Centric Analysis of Agentic Software Systems. arXiv preprint arXiv:2512.02393(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Yunbo Lyu, Hong Jin Kang, Ratnadira Widyasari, Julia Lawall, and David Lo. 2024. Evaluating SZZ Implementations: An Empirical Study on the Linux Kernel.IEEE Trans. Softw. Eng.50, 9 (Sept. 2024), 2219–2239. doi:10.1109/TSE.2024.3406718
-
[24]
Edmilson Campos Neto, Daniel Alencar da Costa, and Uirá Kulesza. 2018. The impact of refactoring changes on the SZZ algorithm: An empirical study. In2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengi- neering (SANER). 380–390. doi:10.1109/SANER.2018.8330225
-
[25]
OpenAI. 2024. GPT-4o-mini. https://platform.openai.com/docs/models#gpt-4o- mini
work page 2024
-
[26]
OpenAI. 2025. GPT-5 mini. https://developers.openai.com/api/docs/models/gpt- 5-mini
work page 2025
-
[27]
Chris Parnin and Alessandro Orso. 2011. Are automated debugging tech- niques actually helping programmers?. InProceedings of the 2011 International Symposium on Software Testing and Analysis(Toronto, Ontario, Canada)(IS- STA ’11). Association for Computing Machinery, New York, NY, USA, 199–209. doi:10.1145/2001420.2001445
-
[28]
Luca Pascarella, Fabio Palomba, and Alberto Bacchelli. 2019. Fine-grained just- in-time defect prediction.Journal of Systems and Software150 (2019), 22–36. doi:10.1016/j.jss.2018.12.001
-
[29]
Christophe Rezk, Yasutaka Kamei, and Shane McIntosh. 2022. The Ghost Commit Problem When Identifying Fix-Inducing Changes: An Empirical Study of Apache Projects.IEEE Transactions on Software Engineering48, 9 (2022), 3297–3309. doi:10.1109/TSE.2021.3087419
-
[30]
Giovanni Rosa, Luca Pascarella, Simone Scalabrino, Rosalia Tufano, Gabriele Bavota, Michele Lanza, and Rocco Oliveto. 2021. Evaluating SZZ Implementations Through a Developer-Informed Oracle. In2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE). 436–447. doi:10.1109/ICSE43902.2021. 00049
-
[31]
Yu Shi, Hao Li, Bram Adams, and Ahmed E Hassan. 2026. Beyond Blame: Re- thinking SZZ with Knowledge Graph Search.arXiv preprint arXiv:2602.02934 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Danilo Silva and Marco Tulio Valente. 2017. RefDiff: Detecting Refactorings in Version Histories. In2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR). 269–279. doi:10.1109/MSR.2017.14
- [33]
-
[34]
Ming Tan, Lin Tan, Sashank Dara, and Caleb Mayeux. 2015. Online Defect Predic- tion for Imbalanced Data. In2015 IEEE/ACM 37th IEEE International Conference on Software Engineering, Vol. 2. 99–108. doi:10.1109/ICSE.2015.139
-
[35]
Lingxiao Tang, Lingfeng Bao, Xin Xia, and Zhongdong Huang. 2023. Neural SZZ Algorithm. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). 1024–1035. doi:10.1109/ASE56229.2023.00037
-
[36]
Lingxiao Tang, Jiakun Liu, Zhongxin Liu, Xiaohu Yang, and Lingfeng Bao. 2025. LLM4SZZ: Enhancing SZZ Algorithm with Context-Enhanced Assessment on Large Language Models.Proc. ACM Softw. Eng.2, ISSTA, Article ISSTA016 (June 2025), 23 pages. doi:10.1145/3728885
-
[37]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al . 2026. Kimi K2. 5: Visual Agentic Intelligence.arXiv preprint arXiv:2602.02276(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Eshkevari, Davood Mazinanian, and Danny Dig
Nikolaos Tsantalis, Matin Mansouri, Laleh M. Eshkevari, Davood Mazinanian, and Danny Dig. 2018. Accurate and efficient refactoring detection in commit history. InProceedings of the 40th International Conference on Software Engineering (Gothenburg, Sweden)(ICSE ’18). Association for Computing Machinery, New York, NY, USA, 483–494. doi:10.1145/3180155.3180206
-
[39]
Michele Tufano, Gabriele Bavota, Denys Poshyvanyk, Massimiliano Di Penta, Rocco Oliveto, and Andrea De Lucia. 2017. An empirical study on developer- related factors characterizing fix-inducing commits.Journal of Software: Evolution and Process29, 1 (2017), e1797
work page 2017
-
[40]
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. 2024. Executable code actions elicit better llm agents. InForty-first International Conference on Machine Learning
work page 2024
-
[41]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2024. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Ming Wen, Rongxin Wu, Yepang Liu, Yongqiang Tian, Xuan Xie, Shing-Chi Cheung, and Zhendong Su. 2019. Exploring and exploiting the correlations between bug-inducing and bug-fixing commits. InProceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium Preprint, Under Submission, Arxiv Lyu et al. on the Foundation...
-
[43]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. 2025. The rise and potential of large language model based agents: A survey.Science China Information Sciences 68, 2 (2025), 121101
work page 2025
-
[44]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025. De- mystifying LLM-Based Software Engineering Agents.Proc. ACM Softw. Eng.2, FSE, Article FSE037 (June 2025), 24 pages. doi:10.1145/3715754
-
[45]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al . 2024. Os- world: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems37 (2024), 52040–52094
work page 2024
-
[46]
Hassan, David Lo, and Shanping Li
Meng Yan, Xin Xia, Yuanrui Fan, Ahmed E. Hassan, David Lo, and Shanping Li. 2022. Just-In-Time Defect Identification and Localization: A Two-Phase Framework.IEEE Transactions on Software Engineering48, 1 (2022), 82–101. doi:10.1109/TSE.2020.2978819
-
[47]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer In- terfaces Enable Automated Software Engineering. InAdvances in Neural In- formation Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. 37. Curran A...
work page 2024
-
[48]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
work page 2022
-
[49]
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. 2023. RepoCoder: Repository-Level Code Completion Through Iterative Retrieval and Generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association...
-
[50]
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. 2024. Au- toCodeRover: Autonomous Program Improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis(Vienna, Austria)(ISSTA 2024). Association for Computing Machinery, New York, NY, USA, 1592–1604. doi:10.1145/3650212.3680384
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.