What if Agents Could Imagine? Reinforcing Open-Vocabulary HOI Comprehension through Generation
Pith reviewed 2026-05-21 13:14 UTC · model grok-4.3
The pith
Enabling agents to generate alternative viewpoints resolves hallucinations and limited perspectives in open-vocabulary human-object interaction understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
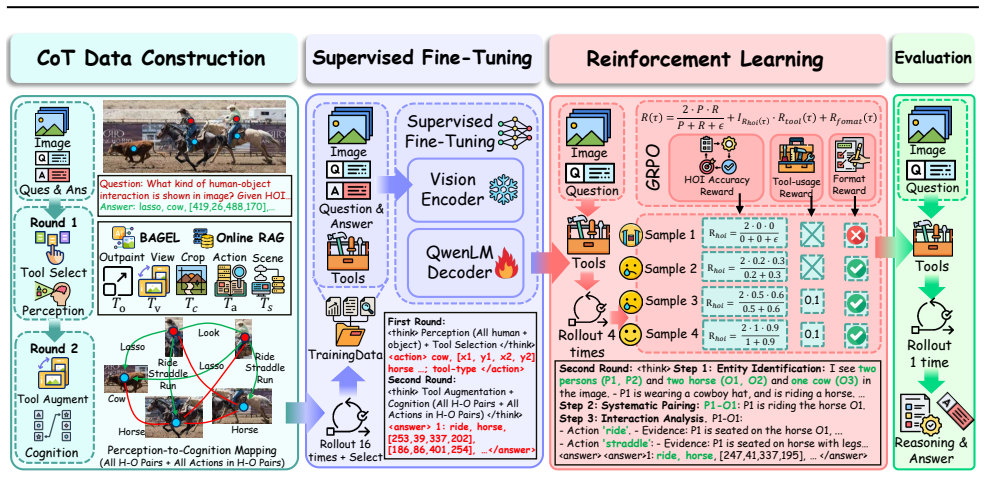
ImagineAgent integrates cognitive mapping, tool-augmented reinforcement learning, and generative world modeling for robust OV-HOI understanding. A new hicodet-6K CoT dataset structures perceived entities into interaction pairs for supervised fine-tuning. A multimodal tool library supplies online retrieval, image cropping, and generative modeling at inference time, while a generative component reconstructs alternative viewpoints to overcome limited image perspectives. A composite reward jointly optimizes prediction accuracy and tool efficiency, delivering state-of-the-art performance on SWIG-HOI and HICO-DET with only 36.7 percent of the training data required by existing methods.
What carries the argument
Generative world modeling that reconstructs alternative viewpoints so the agent can imagine different perspectives and resolve visual-semantic ambiguities in human-object scenes.
Load-bearing premise
The generative model can produce alternative viewpoints that resolve visual-semantic ambiguities and hallucinations without introducing new errors or biases that affect downstream HOI predictions.
What would settle it
An ablation test that disables only the viewpoint-generation step and measures the resulting change in accuracy and hallucination rate on a set of images containing known viewpoint ambiguities.
Figures









read the original abstract
Multimodal Large Language Models have shown promising capabilities in bridging visual and textual reasoning, yet their reasoning capabilities in Open-Vocabulary Human-Object Interaction (OV-HOI) are limited by cross-modal hallucinations and limited viewpoints of images. To address this, we propose ImagineAgent, an agentic framework that integrates cognitive mapping, tool-augmented reinforcement learning (RL), and generative world modeling for robust OV-HOI understanding. Specifically, we first propose an innovative CoT dataset named hicodet-6K for supervised fine-tuning (SFT), which effectively bridges the perception-to-cognition gap by structuring perceived entities into interaction pairs for comprehensive predictions. Subsequently, we develop a multimodal tool library integrating online retrieval, image cropping, and generative modeling, enabling the agent to dynamically augment reasoning with domain-specific tools to resolve visual-semantic ambiguities and hallucinations during inference. Moreover, we incorporate a generative model to reconstruct alternative viewpoints, enabling the agent to 'imagine' under limited viewpoints. Finally, we propose a composite reward mechanism to jointly optimize prediction accuracy and tool efficiency. Evaluations on both SWIG-HOI and HICO-DET datasets demonstrate that our method achieves state-of-the-art performance while requiring merely 36.7% of the training data compared to existing methods, validating our robustness, empirical effectiveness and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ImagineAgent, an agentic framework for open-vocabulary human-object interaction (OV-HOI) comprehension that integrates cognitive mapping, a multimodal tool library (including online retrieval, cropping, and generative modeling), supervised fine-tuning on a new CoT dataset called hicodet-6K, generative reconstruction of alternative viewpoints to address limited image perspectives and hallucinations, and a composite reward mechanism for RL-based optimization of accuracy and tool efficiency. It reports state-of-the-art results on SWIG-HOI and HICO-DET while using only 36.7% of the training data required by prior methods.
Significance. If the empirical claims hold after proper validation, the work could advance OV-HOI understanding by showing how generative 'imagination' of viewpoints combined with tool-augmented RL can mitigate cross-modal hallucinations and data inefficiency in multimodal LLMs. The introduction of hicodet-6K and the composite reward design represent concrete contributions to bridging perception-to-cognition gaps in this domain.
major comments (2)
- [Evaluation / Experiments] The central SOTA claim with 36.7% training data (abstract and evaluation sections) rests on the generative model producing alternative viewpoints that resolve visual-semantic ambiguities without harming downstream HOI predictions. However, no consistency checks, label preservation metrics, or ablations are reported comparing original and generated views on labeled HOI pairs from SWIG-HOI or HICO-DET; if generated images introduce hallucinated object placements or viewpoint artifacts, the reported gains could be evaluation artifacts rather than true robustness.
- [Framework / Method] The multimodal tool library and composite reward (described in the framework section) are presented as jointly optimizing prediction accuracy and tool efficiency, but the manuscript provides no ablation isolating the contribution of the generative viewpoint synthesis versus the other tools (retrieval, cropping) or versus the hicodet-6K SFT alone; this makes it difficult to attribute the data reduction specifically to the 'imagine' component.
minor comments (2)
- [Introduction] The abstract and introduction use 'hicodet-6K' without clarifying its relation to the original HICO-DET (e.g., size, annotation process, or overlap); a brief table or paragraph would improve clarity.
- [Method] Notation for the composite reward function and tool-augmented RL loop is introduced but not formalized with equations; adding a short algorithmic pseudocode box would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the empirical support for our claims without overstating the current results.
read point-by-point responses
-
Referee: [Evaluation / Experiments] The central SOTA claim with 36.7% training data (abstract and evaluation sections) rests on the generative model producing alternative viewpoints that resolve visual-semantic ambiguities without harming downstream HOI predictions. However, no consistency checks, label preservation metrics, or ablations are reported comparing original and generated views on labeled HOI pairs from SWIG-HOI or HICO-DET; if generated images introduce hallucinated object placements or viewpoint artifacts, the reported gains could be evaluation artifacts rather than true robustness.
Authors: We agree that direct validation of the generated viewpoints is necessary to rule out evaluation artifacts and to confirm that label integrity is preserved. Although the end-to-end performance gains and data efficiency in our experiments are consistent with the value of viewpoint imagination, the manuscript does not currently report consistency checks or label-preservation metrics on the generated images. In the revised manuscript we will add an ablation that measures HOI prediction agreement and label preservation between original and generated views on a representative subset of labeled pairs drawn from both SWIG-HOI and HICO-DET, together with qualitative inspection for hallucinated placements or viewpoint artifacts. revision: yes
-
Referee: [Framework / Method] The multimodal tool library and composite reward (described in the framework section) are presented as jointly optimizing prediction accuracy and tool efficiency, but the manuscript provides no ablation isolating the contribution of the generative viewpoint synthesis versus the other tools (retrieval, cropping) or versus the hicodet-6K SFT alone; this makes it difficult to attribute the data reduction specifically to the 'imagine' component.
Authors: We acknowledge that the current experimental design does not isolate the generative viewpoint synthesis from the remaining tools or from the hicodet-6K supervised fine-tuning stage. While the composite reward and full tool library are shown to work together, the manuscript lacks the finer-grained ablations needed to attribute the observed data reduction specifically to the imagination mechanism. We will therefore add controlled ablations in the revised experiments section that evaluate performance when the generative viewpoint tool is removed while keeping the other tools and the SFT stage fixed, thereby clarifying the marginal contribution of the 'imagine' component. revision: yes
Circularity Check
No circularity in empirical agentic framework
full rationale
The paper describes an empirical agentic system (ImagineAgent) built from SFT on a custom CoT dataset (hicodet-6K), a multimodal tool library, generative viewpoint reconstruction, and a composite reward for RL optimization, followed by direct evaluation on SWIG-HOI and HICO-DET. No equations, fitted parameters renamed as predictions, or self-citation chains are shown that would make any reported performance metric equivalent to its inputs by construction. The SOTA claim with reduced training data rests on external benchmark results rather than internal definitional loops.
Axiom & Free-Parameter Ledger
invented entities (1)
-
ImagineAgent
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
composite reward ... Rhoi = 2·P·R/(P+R+ϵ) ... tool-usage reward ... GRPO
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
generative world modeling ... BAGEL ... viewpoint transform / outpaint
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
ConeSep: Cone-based Robust Noise-Unlearning Compositional Network for Composed Image Retrieval
ConeSep tackles noisy triplet correspondences in composed image retrieval by introducing geometric fidelity quantization to locate noise, negative boundary learning for semantic opposites, and targeted unlearning via ...
-
Air-Know: Arbiter-Calibrated Knowledge-Internalizing Robust Network for Composed Image Retrieval
Air-Know decouples MLLM-based external arbitration from proxy learning via knowledge internalization and dual-stream training to overcome noisy triplet correspondence in composed image retrieval.
-
HiSem: Hierarchical Semantic Disentangling for Remote Sensing Image Change Captioning
HiSem adds bidirectional differential attention and a two-level hierarchical routing module with MoE to handle semantic granularity differences in remote sensing change captioning, reporting +7.52% BLEU-4 on WHU-CDC.
Reference graph
Works this paper leans on
-
[1]
introduces hierarchical sampling with difficulty-aware budget reallocation for self-taught reasoners. However, existing methods struggle with long-sequence hallucination (Chen et al., 2025b) and limited cross-modal interaction. To address this, we propose multimodal CoT reasoning via tool-augmented RL to explicitly reduce cross-modal hallucination. Tool-A...
work page 2025
-
[2]
Detect ALL objects from the PREDEFINED OBJECTS that are present
-
[3]
PREDEFINED OBJECTS: {OBJECTS_INFO} Available tools:
Decide whether it is necessary to call any external tools to improve the final HOI predictions. PREDEFINED OBJECTS: {OBJECTS_INFO} Available tools:
-
[4]
"image_description" - If the image is unclear, blurry, or has complex lighting conditions, request detailed image analysis to better understand the scene
-
[5]
"action_description" - Get detailed definitions of action categories to distinguish similar actions (e.g., "hold" vs "carry", "cut" vs "cut_with")
- [6]
-
[7]
"viewpoint_transform" - Select this if the person is occluded or indistinct from the current angle
-
[8]
“image_crop“ – Select this if specific regions of interest need closer examination to detect fine-grained interactions. {OBJECT_DESCRIPTIONS} Instructions: - For object detection: Detect ALL objects from the PREDEFINED LIST that are VISIBLE in the image, regardless of whether they are involved in interactions - IMPORTANT: Only detect "person" as an OBJECT...
-
[9]
Do not miss any potential interaction pair
Be Comprehensive (For Recall): You must systematically check every person against every object from the `DETECTED OBJECTS` list. Do not miss any potential interaction pair
-
[10]
- You MUST ONLY use actions from the `VALID ACTIONS` list for the corresponding object
Strictly Adhere to Lists (For Precision): - You MUST ONLY use objects from the `DETECTED OBJECTS` list. - You MUST ONLY use actions from the `VALID ACTIONS` list for the corresponding object
-
[11]
Ground in Visual Evidence (For Precision): Every reported interaction must be directly supported by clear visual cues in the image (e.g., hand contact, body posture, gaze direction, spatial proximity)
-
[12]
Precise Formatting: - Use precise pixel coordinates for all bounding boxes. - Format each finding as: `number: action, object, [person_x1,person_y1,person_x2,person_y2], [object_x1,object_y1,object_x2,object_y2]` - Do not add any extra text or explanations outside the designated tags. # 3. YOUR THOUGHT PROCESS (Mandatory) You must follow this structured r...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.