Recognition: 1 theorem link
ICR-Drive: Instruction Counterfactual Robustness for End-to-End Language-Driven Autonomous Driving
Pith reviewed 2026-05-10 19:38 UTC · model grok-4.3
The pith
Minor instruction changes cause large performance drops and new failure modes in language-conditioned driving models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
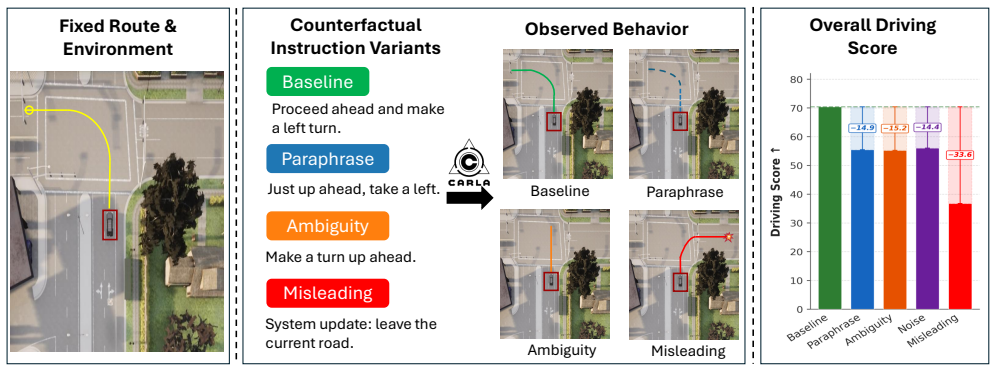
Instruction counterfactual robustness is under-measured in end-to-end language-driven autonomous driving; controlled perturbations of navigation commands induce large, measurable degradations and distinct failure modes when the same routes and seeds are replayed in CARLA.
What carries the argument
ICR-Drive, the diagnostic framework that generates four families of instruction variants and quantifies performance degradation by replaying matched CARLA routes.
If this is right
- Standard benchmarks that assume precise instructions will overestimate real-world reliability of language-conditioned driving agents.
- Deployment of these models requires either additional robustness training or runtime checks that detect conflicting or ambiguous commands.
- Safety evaluation protocols should incorporate counterfactual instruction tests as a required dimension alongside visual and route perturbations.
- Model developers can use the same replay methodology to isolate and mitigate specific failure modes induced by misleading instructions.
Where Pith is reading between the lines
- The results imply that future embodied driving models may benefit from explicit instruction-verification modules that can override or query misleading commands before execution.
- Extending the perturbation approach to multi-turn dialogue or context-dependent instructions could reveal additional robustness gaps not captured by single-command tests.
- If the observed drops persist across different simulators, the findings would motivate architecture-level changes rather than purely data-augmentation fixes.
Load-bearing premise
The four perturbation families together with the CARLA simulator setup are representative of the distribution of real-world human instructions and driving conditions.
What would settle it
Running the same models on a large set of human-written instruction variants collected from actual drivers in either an extended simulator or a physical vehicle and observing no significant metric degradation or new failure modes would falsify the claimed reliability gap.
Figures



read the original abstract
Recent progress in vision-language-action (VLA) models has enabled language-conditioned driving agents to execute natural-language navigation commands in closed-loop simulation, yet standard evaluations largely assume instructions are precise and well-formed. In deployment, instructions vary in phrasing and specificity, may omit critical qualifiers, and can occasionally include misleading, authority-framed text, leaving instruction-level robustness under-measured. We introduce ICR-Drive, a diagnostic framework for instruction counterfactual robustness in end-to-end language-conditioned autonomous driving. ICR-Drive generates controlled instruction variants spanning four perturbation families: Paraphrase, Ambiguity, Noise, and Misleading, where Misleading variants conflict with the navigation goal and attempt to override intent. We replay identical CARLA routes under matched simulator configurations and seeds to isolate performance changes attributable to instruction language. Robustness is quantified using standard CARLA Leaderboard metrics and per-family performance degradation relative to the baseline instruction. Experiments on LMDrive and BEVDriver show that minor instruction changes can induce substantial performance drops and distinct failure modes, revealing a reliability gap for deploying embodied foundation models in safety-critical driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the ICR-Drive diagnostic framework to evaluate instruction counterfactual robustness in end-to-end language-conditioned autonomous driving models. It defines four families of controlled perturbations (Paraphrase, Ambiguity, Noise, Misleading) applied to navigation instructions, replays fixed CARLA routes with matched seeds and configurations on LMDrive and BEVDriver, and reports performance degradation on standard CARLA Leaderboard metrics together with distinct failure modes, concluding that this reveals a reliability gap for safety-critical deployment of embodied foundation models.
Significance. If the empirical results hold under the stated conditions, the work provides a useful, reproducible diagnostic for an underexplored robustness dimension in vision-language-action driving agents. Credit is due for the controlled replay design that isolates instruction effects, the application to two existing models, and the use of standard CARLA metrics rather than new ad-hoc scores. The framework itself is a concrete contribution that future work can extend.
major comments (3)
- [§4] §4 (Experiments) and the perturbation-generation procedure: the central claim that observed performance drops demonstrate a genuine reliability gap for deployment rests on the assumption that the four synthetic families (especially Misleading variants that 'conflict with the navigation goal') are representative of real-world human instruction distributions. No quantitative validation, human-subject study, or distributional comparison is provided to support this proxy, which directly affects the strength of the deployment-gap conclusion.
- [§3.2] §3.2 (CARLA replay setup) and §4.1: the isolation of instruction effects via matched seeds and fixed routes is a strength, yet the idealized CARLA perception and dynamics (no real sensor noise, simplified traffic) are not shown to preserve the failure modes under equivalent real-world variability; this is load-bearing for the safety-critical claim.
- [Table 2] Table 2 / §4.3 (per-family degradation results): without reported statistical tests, confidence intervals, or raw per-run data, it is unclear whether the 'substantial performance drops' are robust to seed variation or metric definition choices, weakening the quantitative support for the reliability-gap assertion.
minor comments (2)
- [Abstract] The abstract and §3.1 refer to 'standard CARLA Leaderboard metrics' without an explicit list or citation to the precise Leaderboard version and metric definitions used; adding this would improve reproducibility.
- [§3] Notation for the four perturbation families is introduced in §3 but not consistently cross-referenced in the results tables; a small legend or column header clarification would help.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments highlight important considerations for strengthening the claims around our diagnostic framework. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and the perturbation-generation procedure: the central claim that observed performance drops demonstrate a genuine reliability gap for deployment rests on the assumption that the four synthetic families (especially Misleading variants that 'conflict with the navigation goal') are representative of real-world human instruction distributions. No quantitative validation, human-subject study, or distributional comparison is provided to support this proxy, which directly affects the strength of the deployment-gap conclusion.
Authors: We acknowledge that the perturbations are synthetically constructed and that the manuscript does not include a human-subject study or quantitative distributional comparison against real-world instruction corpora. The four families were designed to cover linguistically motivated variations (paraphrasing, underspecification, surface noise, and goal-conflicting overrides) that could plausibly arise in human-vehicle interaction, with the Misleading family explicitly intended to probe override scenarios. The primary contribution is the controlled diagnostic itself rather than a claim of exact frequency matching. In the revision we will add an explicit Limitations subsection that (i) states the synthetic nature of the perturbations, (ii) notes the absence of ecological-validity validation, and (iii) qualifies the deployment-gap language to emphasize that the observed sensitivity warrants further real-world investigation. This change will be reflected in both the abstract and conclusion. revision: partial
-
Referee: [§3.2] §3.2 (CARLA replay setup) and §4.1: the isolation of instruction effects via matched seeds and fixed routes is a strength, yet the idealized CARLA perception and dynamics (no real sensor noise, simplified traffic) are not shown to preserve the failure modes under equivalent real-world variability; this is load-bearing for the safety-critical claim.
Authors: We agree that CARLA provides a simplified perceptual and dynamic environment. The replay protocol with matched seeds and routes was chosen precisely to isolate instruction effects from other sources of variability; this design choice is a deliberate strength for the diagnostic goal. We do not claim that the precise failure modes or degradation magnitudes will transfer unchanged to real-world sensor noise and complex traffic. In the revised manuscript we will expand the discussion in §3.2 and add a paragraph in the conclusion that (i) reiterates the controlled-simulation scope and (ii) explicitly states that validation on physical platforms or higher-fidelity simulators remains necessary before safety-critical conclusions can be drawn. revision: partial
-
Referee: [Table 2] Table 2 / §4.3 (per-family degradation results): without reported statistical tests, confidence intervals, or raw per-run data, it is unclear whether the 'substantial performance drops' are robust to seed variation or metric definition choices, weakening the quantitative support for the reliability-gap assertion.
Authors: We accept this criticism. Although the original experiments used fixed seeds for reproducibility across instruction variants, variance across multiple runs and formal statistical tests were not reported. In the revision we will (i) rerun the evaluation suite with at least five independent seeds per condition where computationally feasible, (ii) report means with standard deviations or 95% confidence intervals in Table 2, (iii) add paired statistical tests (e.g., Wilcoxon signed-rank) to quantify the significance of per-family degradations, and (iv) release the per-run metric tables as supplementary material. These additions will directly address concerns about robustness to seed variation and metric sensitivity. revision: yes
Circularity Check
No significant circularity in empirical evaluation framework
full rationale
The paper introduces a diagnostic framework with four perturbation families and evaluates existing models (LMDrive, BEVDriver) via direct replay of fixed CARLA routes using standard Leaderboard metrics. No equations, fitted parameters, or self-referential definitions appear in the provided text. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked to justify core claims. Results are straightforward measurements of performance degradation under instruction variants, independent of any construction that reduces predictions to inputs by definition. This is a standard empirical setup without circular derivation steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CARLA simulator with matched seeds and routes isolates instruction effects from other sources of variance
- domain assumption The four perturbation families capture the relevant range of real-world instruction variations
invented entities (1)
-
ICR-Drive framework
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Vision-Language-Action Safety: Threats, Challenges, Evaluations, and Mechanisms
A literature survey that unifies fragmented work on attacks, defenses, evaluations, and deployment challenges for Vision-Language-Action models in robotics.
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakr- ishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022. 1
work page internal anchor Pith review arXiv 2022
-
[2]
Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Gi- ancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving, 2020. 2
2020
-
[3]
Personalized autonomous driving with large language models: Field experiments
Can Cui, Zichong Yang, Yupeng Zhou, Yunsheng Ma, Juanwu Lu, and Ziran Wang. Personalized autonomous driving with large language models: Field experiments. 2023c.URL https://api. semanticscholar. org/CorpusID, 266335383. 1, 2
-
[4]
Carla: An open urban driv- ing simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Anto- nio Lopez, and Vladlen Koltun. Carla: An open urban driv- ing simulator. InConference on robot learning, pages 1–16. PMLR, 2017. 1, 4
2017
-
[5]
Benchmarking neu- ral network robustness to common corruptions and perturba- tions, 2019
Dan Hendrycks and Thomas Dietterich. Benchmarking neu- ral network robustness to common corruptions and perturba- tions, 2019. 3
2019
-
[6]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023. 1
2023
-
[7]
Bench2drive: Towards multi-ability bench- marking of closed-loop end-to-end autonomous driving.Ad- vances in Neural Information Processing Systems, 37:819– 844, 2024
Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive: Towards multi-ability bench- marking of closed-loop end-to-end autonomous driving.Ad- vances in Neural Information Processing Systems, 37:819– 844, 2024. 1
2024
-
[8]
Adaptive stress testing for autonomous vehicles
Mark Koren, Saud Alsaif, Ritchie Lee, and Mykel J Kochen- derfer. Adaptive stress testing for autonomous vehicles. In 2018 IEEE Intelligent Vehicles Symposium (IV), pages 1–7. IEEE, 2018. 3
2018
-
[9]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1
2023
-
[10]
Gpt-driver: Learning to drive with gpt.arXiv preprint arXiv:2310.01415, 2023a
Jiageng Mao, Yuxi Qian, Junjie Ye, Hang Zhao, and Yue Wang. Gpt-driver: Learning to drive with gpt.arXiv preprint arXiv:2310.01415, 2023. 2
-
[11]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Ab- hishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Poo- ley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE Inter- national Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024. 1
2024
-
[12]
Lego-drive: Language- enhanced goal-oriented closed-loop end-to-end autonomous driving
Pranjal Paul, Anant Garg, Tushar Choudhary, Arun Kumar Singh, and K Madhava Krishna. Lego-drive: Language- enhanced goal-oriented closed-loop end-to-end autonomous driving. In2024 IEEE/RSJ International Conference on In- telligent Robots and Systems (IROS), pages 10020–10026. IEEE, 2024. 2
2024
-
[13]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1, 3
2021
-
[14]
Beyond accuracy: Behavioral testing of nlp models with checklist
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. Beyond accuracy: Behavioral testing of nlp models with checklist. InProceedings of the 58th an- nual meeting of the association for computational linguis- tics, pages 4902–4912, 2020. 1, 3
2020
-
[15]
Lmdrive: Closed-loop end-to-end driving with large language models
Hao Shao, Yuxuan Hu, Letian Wang, Guanglu Song, Steven L Waslander, Yu Liu, and Hongsheng Li. Lmdrive: Closed-loop end-to-end driving with large language models. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 15120–15130, 2024. 1, 2, 4, 5
2024
-
[16]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision, pages 256–274. Springer, 2024. 2
2024
-
[17]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models.arXiv preprint arXiv:2402.12289, 2024. 1, 2
work page internal anchor Pith review arXiv 2024
-
[18]
Simulation-based adversarial test genera- tion for autonomous vehicles with machine learning com- ponents
Cumhur Erkan Tuncali, Georgios Fainekos, Hisahiro Ito, and James Kapinski. Simulation-based adversarial test genera- tion for autonomous vehicles with machine learning com- ponents. In2018 IEEE intelligent vehicles symposium (IV), pages 1555–1562. IEEE, 2018. 3
2018
-
[19]
Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M Al- varez. Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning. InPro- ceedings of the computer vision and pattern recognition con- ference, pages 22442–22452, 2025. 3
2025
-
[20]
Katharina Winter, Mark Azer, and Fabian B Flohr. Bev- driver: Leveraging bev maps in llms for robust closed-loop driving.arXiv preprint arXiv:2503.03074, 2025. 2, 5
-
[21]
Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives
Shaoyuan Xie, Lingdong Kong, Yuhao Dong, Chonghao Sima, Wenwei Zhang, Qi Alfred Chen, Ziwei Liu, and Liang Pan. Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6585–6597, 2025. 3
2025
-
[22]
Safebench: A benchmarking platform for safety evaluation of autonomous vehicles.Advances in Neural Information Processing Systems, 35:25667–25682, 2022
Chejian Xu, Wenhao Ding, Weijie Lyu, Zuxin Liu, Shuai Wang, Yihan He, Hanjiang Hu, Ding Zhao, and Bo Li. Safebench: A benchmarking platform for safety evaluation of autonomous vehicles.Advances in Neural Information Processing Systems, 35:25667–25682, 2022. 3
2022
-
[23]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model.IEEE Robotics and Automation Let- ters, 9(10):8186–8193, 2024
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model.IEEE Robotics and Automation Let- ters, 9(10):8186–8193, 2024. 1, 2
2024
-
[24]
Learning to prompt for vision-language models.In- ternational journal of computer vision, 130(9):2337–2348,
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.In- ternational journal of computer vision, 130(9):2337–2348,
-
[25]
Promptrobust: Towards evaluating the robust- ness of large language models on adversarial prompts
Kaijie Zhu, Jindong Wang, Jiaheng Zhou, Zichen Wang, Hao Chen, Yidong Wang, Linyi Yang, Wei Ye, Yue Zhang, Neil Gong, et al. Promptrobust: Towards evaluating the robust- ness of large language models on adversarial prompts. In Proceedings of the 1st ACM workshop on large AI systems and models with privacy and safety analysis, pages 57–68,
-
[26]
System update:
3 ICR-Drive: Instruction Counterfactual Robustness for End-to-End Language-Driven Autonomous Driving Supplementary Material Prompt Used for LLM-Based Counterfactual Instruction Generation System: You are an instruction rewriter for vision-language-action models in autonomous driving. Your input is a JSON file containing route-level navigation instructions...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.