Recognition: 1 theorem link
· Lean Theorem"I See What You Did There": Can Large Vision-Language Models Understand Multimodal Puns?
Pith reviewed 2026-05-10 19:38 UTC · model grok-4.3
The pith
Vision-language models largely fail to detect multimodal puns but improve with prompt and model adjustments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a multimodal pun generation pipeline and the MultiPun dataset of diverse puns together with adversarial distractors. Evaluation demonstrates that most vision-language models struggle to distinguish genuine puns from these distractors. We further show that prompt-level and model-level strategies raise average F1 scores by 16.5 percent, offering a route toward better cross-modal reasoning for humor.
What carries the argument
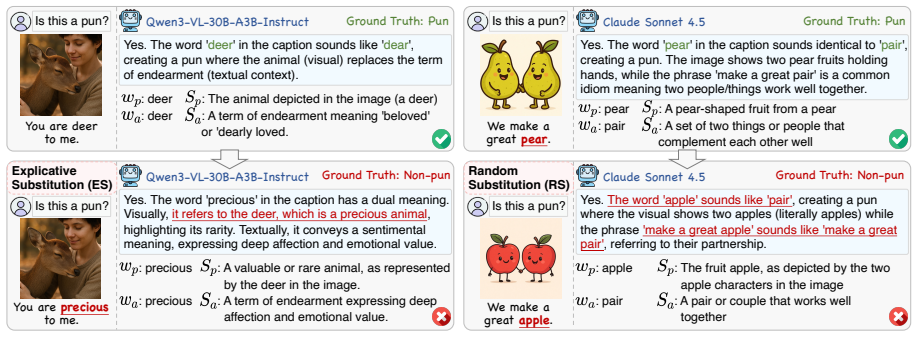
The MultiPun dataset of generated multimodal puns paired with adversarial non-pun distractors, which forces models to perform cross-modal reasoning on literal versus figurative senses.
If this is right
- Vision-language models require stronger cross-modal mechanisms to integrate visual cues with textual polysemy for rhetorical devices.
- Prompt engineering can partially offset current weaknesses in distinguishing puns from superficially similar content.
- Model-level interventions provide a scalable way to embed better handling of figurative multimodal meaning.
- Dedicated humor benchmarks expose reasoning gaps that standard multimodal tasks do not reveal.
Where Pith is reading between the lines
- The measured improvement implies that many models already hold latent knowledge of pun structures that ordinary zero-shot prompts do not surface.
- Similar adversarial datasets could be built for other cross-modal rhetorical forms such as visual metaphors or irony.
- If the strategies transfer to open-ended generation tasks, they could support more natural multimodal humor creation in future systems.
Load-bearing premise
The automatically generated puns and distractors in MultiPun capture the actual cognitive demands of real-world multimodal pun understanding instead of mere statistical patterns.
What would settle it
Testing the same models and strategies on a fresh collection of human-created multimodal puns that never passed through the generation pipeline, and finding no meaningful F1 improvement, would falsify the claim that the strategies advance genuine pun comprehension.
Figures



read the original abstract
Puns are a common form of rhetorical wordplay that exploits polysemy and phonetic similarity to create humor. In multimodal puns, visual and textual elements synergize to ground the literal sense and evoke the figurative meaning simultaneously. Although Vision-Language Models (VLMs) are widely used in multimodal understanding and generation, their ability to understand puns has not been systematically studied due to a scarcity of rigorous benchmarks. To address this, we first propose a multimodal pun generation pipeline. We then introduce MultiPun, a dataset comprising diverse types of puns alongside adversarial non-pun distractors. Our evaluation reveals that most models struggle to distinguish genuine puns from these distractors. Moreover, we propose both prompt-level and model-level strategies to enhance pun comprehension, with an average improvement of 16.5% in F1 scores. Our findings provide valuable insights for developing future VLMs that master the subtleties of human-like humor via cross-modal reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an automatic multimodal pun generation pipeline and introduces the MultiPun dataset, which pairs diverse pun examples with adversarial non-pun distractors. It evaluates multiple vision-language models on a pun-vs-distractor discrimination task, reports that most models perform poorly, and introduces prompt-level and model-level interventions that produce an average 16.5% F1 improvement. The work positions these results as evidence of current VLMs' limitations in cross-modal humor reasoning and as guidance for future model development.
Significance. If the MultiPun benchmark genuinely isolates the intended cognitive processes (polysemy grounding and visual-textual synergy) rather than pipeline artifacts, the results would usefully document a gap in VLM capabilities and supply concrete, reproducible improvement strategies. The introduction of an adversarial dataset construction method is a positive contribution to multimodal humor evaluation.
major comments (2)
- [Dataset construction and evaluation] Dataset construction and evaluation sections: because both the pun examples and the adversarial distractors are produced by the same automatic pipeline, the reported performance gap and the 16.5% F1 gains could reflect detection of generation regularities (inconsistent visual-text alignment, lexical overlap patterns, or pipeline biases) rather than genuine multimodal pun comprehension. No human difficulty ratings, comparison against naturally occurring puns, or surface-feature controls are described that would rule out this shortcut.
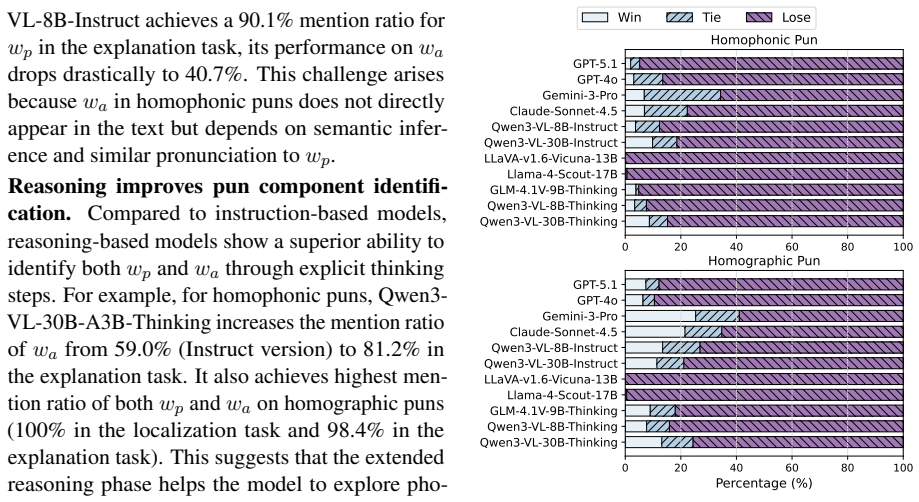
- [Evaluation] Evaluation protocol: the manuscript supplies no dataset size, inter-annotator agreement (if any human filtering occurred), statistical significance tests, or exact model versions and prompting details. Without these, it is impossible to determine whether the 16.5% average F1 improvement is robust or sensitive to implementation choices.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a brief statement of the total number of MultiPun instances and the distribution across pun types.
- [Dataset construction] Clarify whether the adversarial distractors are generated with the same visual and textual components as the puns or with controlled modifications; this detail is essential for interpreting the difficulty of the discrimination task.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below with clarifications and commit to revisions that strengthen the paper's claims about VLM limitations in multimodal pun understanding.
read point-by-point responses
-
Referee: [Dataset construction and evaluation] Dataset construction and evaluation sections: because both the pun examples and the adversarial distractors are produced by the same automatic pipeline, the reported performance gap and the 16.5% F1 gains could reflect detection of generation regularities (inconsistent visual-text alignment, lexical overlap patterns, or pipeline biases) rather than genuine multimodal pun comprehension. No human difficulty ratings, comparison against naturally occurring puns, or surface-feature controls are described that would rule out this shortcut.
Authors: We acknowledge the validity of this concern: because the distractors are generated by the same pipeline, models could in principle exploit generation artifacts rather than true cross-modal pun reasoning. The adversarial construction was intended to match surface-level visual-textual elements while removing the polysemy grounding and synergistic humor, but we agree this requires further validation. In the revision we will add human difficulty ratings on a subset of items, a comparison set of naturally occurring multimodal puns, and explicit surface-feature controls (e.g., lexical overlap and alignment metrics) to demonstrate that performance differences are not reducible to pipeline regularities. revision: yes
-
Referee: [Evaluation] Evaluation protocol: the manuscript supplies no dataset size, inter-annotator agreement (if any human filtering occurred), statistical significance tests, or exact model versions and prompting details. Without these, it is impossible to determine whether the 16.5% average F1 improvement is robust or sensitive to implementation choices.
Authors: We agree these details are necessary for reproducibility and for judging the robustness of the 16.5% F1 gains. The revised manuscript will report the full dataset size, any human filtering steps together with inter-annotator agreement statistics, results of statistical significance tests on the reported improvements, and the precise model versions and prompting templates used in all experiments. revision: yes
Circularity Check
No circularity: purely empirical benchmark study with no derivations or fitted predictions
full rationale
The paper introduces an automatic multimodal pun generation pipeline, creates the MultiPun dataset with puns and adversarial distractors, evaluates several VLMs on distinguishing them, and reports measured F1 improvements (average 16.5%) from prompt-level and model-level interventions. No equations, parameter fitting, uniqueness theorems, or derivation chains exist that could reduce to inputs by construction. All claims rest on experimental outcomes rather than self-referential definitions or self-citation load-bearing premises, satisfying the criteria for a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal puns can be reliably generated by a pipeline that pairs visual and textual elements to exploit polysemy and phonetic similarity.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean; IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction; washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the multimodal pun generation pipeline and propose MULTIPUN, a benchmark containing 445 puns and 890 non-puns... Pun-CoT and Pun-Tuning... average increase of 16.5% in F1 scores.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Beyond End-to-End: Dynamic Chain Optimization for Private LLM Adaptation on the Edge
ChainFed achieves memory-efficient private LLM fine-tuning on edge devices through sequential layer-by-layer adapter training with dynamic co-tuning, perceptive optimization, and adaptive starting point selection, imp...
-
Spotlight and Shadow: Attention-Guided Dual-Anchor Introspective Decoding for MLLM Hallucination Mitigation
DaID mitigates MLLM hallucinations by attention-guided selection of dual layers that calibrate token generation using internal perceptual discrepancies.
Reference graph
Works this paper leans on
-
[1]
Humanstudy-bench: Towards ai agent de- sign for participant simulation.arXiv preprint arXiv:2602.00685. Ziqiang Liu, Feiteng Fang, Xi Feng, Xeron Du, Chen- hao Zhang, Noah Wang, Qixuan Zhao, Liyang Fan, CHENGGUANG GAN, Hongquan Lin, and 1 others
-
[2]
Gemini: A Family of Highly Capable Multimodal Models
Ii-bench: An image implication understanding benchmark for multimodal large language models. Advances in Neural Information Processing Systems, 37:46378–46480. George A. Miller. 1992. WordNet: A lexical database for English. InSpeech and Natural Language: Pro- ceedings of a Workshop Held at Harriman, New York, February 23-26, 1992. Tristan Miller and Iryn...
work page internal anchor Pith review Pith/arXiv arXiv 1992
-
[3]
the boating store had its best sail ever
Creating a lens of chinese culture: A multi- modal dataset for chinese pun rebus art understanding. InFindings of the Association for Computational Lin- guistics: ACL 2025, pages 22473–22487. Yichao Zhou, Jyun-Yu Jiang, Jieyu Zhao, Kai-Wei Chang, and Wei Wang. 2020. “the boating store had its best sail ever”: Pronunciation-attentive contextu- alized pun r...
2025
-
[4]
Select a RANDOM concrete noun (e.g., chair, ba- nana, bicycle, umbrella, book) that is SEMANTI- CALLY UNRELATED to the original pun context
-
[5]
Replace the main object in the image prompt with this random entity
-
[6]
Replace wp in the caption with the same random entity
-
[7]
Two cartoon pears holding hands
Keep the same action/context structure Constraints: - The random entity must be a concrete, visualizable noun - Must be completely unrelated to original pun - Do NOT reuse common examples (vary your selec- tion) Example: Original Visual: “Two cartoon pears holding hands...” Original Caption: “We make a great pear.” Random Entity: banana New Visual: “Two c...
2026
-
[8]
Image Quality:Is the visual content clear, non- distorted, and depicts the intended object?
-
[9]
Visual-Textual Coherence:For positive sam- ples, does the visual content coherently connect to the text description? For negative samples, is the intended disruption (ES/RS) clearly present?
-
[10]
Ambiguity Presence:For positive samples, is there genuine dual-layer semantics? For negative samples, is the ambiguity properly resolved?
-
[11]
is_pun": true/false} IMPORTANT: Output ONLY the JSON object, no additional text or explanation. Note: The biased-to-non-pun variant changes the task description to
Naturalness:Are the caption and visual sce- nario natural and plausible? Samples are retained if at least 2 out of 3 an- notators agree on acceptance. Rejected samples are either regenerated with refined prompts or dis- carded. The inter-annotator agreement (Fleiss’ Kappa) across all samples is 0.78, indicating sub- stantial agreement. E Evaluation Suite ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.