Multi-Modal Landslide Detection from Sentinel-1 SAR and Sentinel-2 Optical Imagery Using Multi-Encoder Vision Transformers and Ensemble Learning
Pith reviewed 2026-05-10 18:28 UTC · model grok-4.3
The pith
Fusing Sentinel-1 SAR radar data with Sentinel-2 optical imagery through separate vision transformer encoders and an ensemble of neural networks with gradient boosting models produces an F1 score of 0.919 for detecting landslides in image 0
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
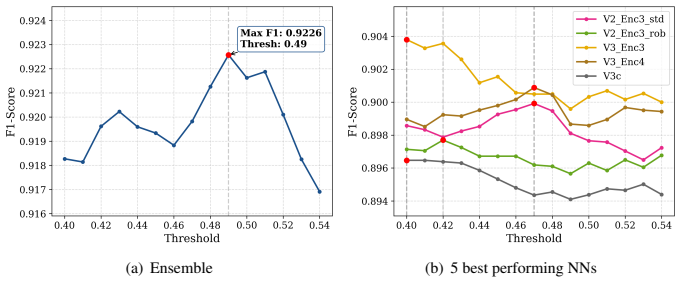
The authors claim that by using dedicated encoders for SAR and optical modalities within a vision transformer setup and then applying ensemble learning, their method can fuse the strengths of both data types to achieve an F1 score of 0.919 in classifying patches as containing landslides or not, all without the need for pre-event optical imagery that is typically used in change detection.
What carries the argument
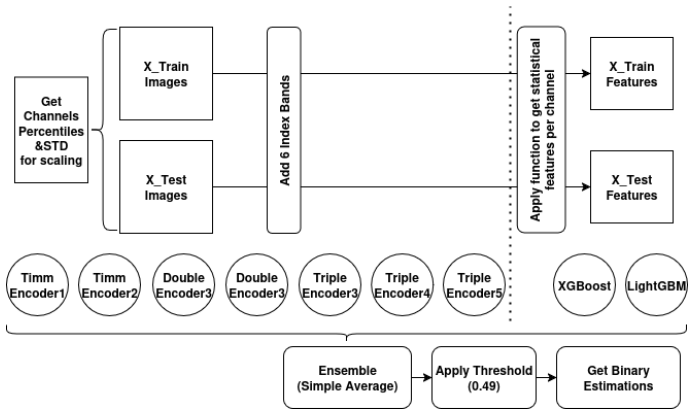
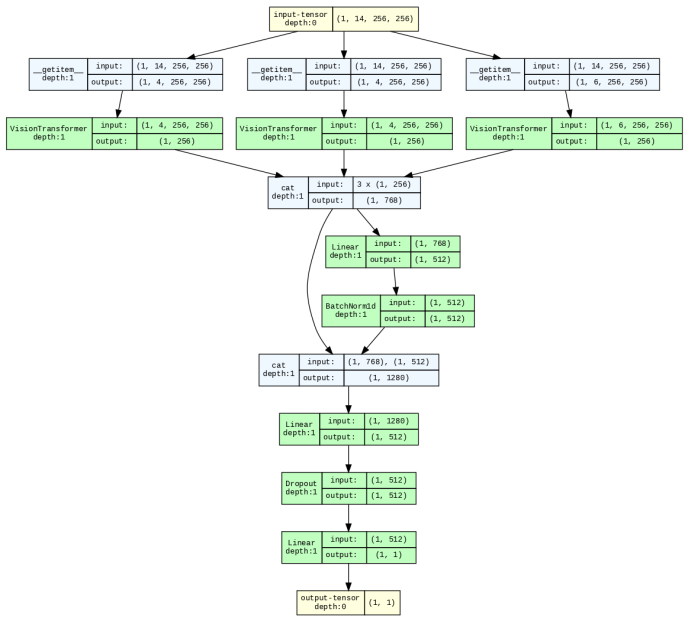
Multi-encoder vision transformers that route each data modality through its own lightweight pretrained encoder, combined with ensemble integration of neural networks and gradient boosting classifiers along with derived spectral indices.
Load-bearing premise
The complementary strengths of SAR and optical data can be effectively combined through separate encoders and ensembles to detect landslides accurately even without pre-event images for comparison.
What would settle it
Testing the full multi-modal model against single-modality versions on an independent landslide dataset from a new region and finding no meaningful F1 improvement from the fusion would indicate that the claimed benefit of combining the data types does not hold.
Figures

read the original abstract
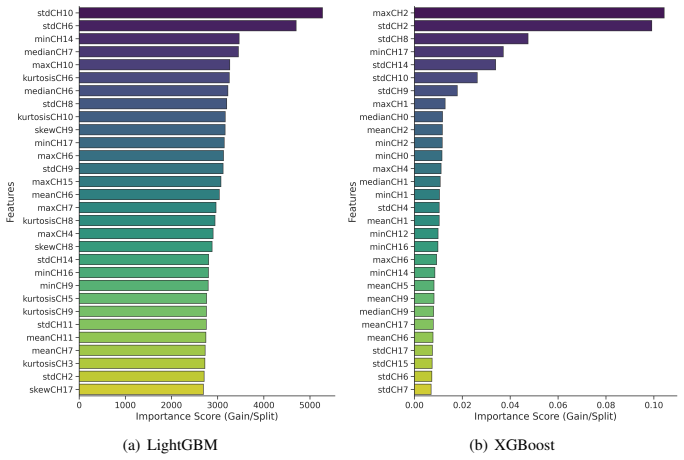
Landslides represent a major geohazard with severe impacts on human life, infrastructure, and ecosystems, underscoring the need for accurate and timely detection approaches to support disaster risk reduction. This study proposes a modular, multi-model framework that fuses Sentinel-2 optical imagery with Sentinel-1 Synthetic Aperture Radar (SAR) data, for robust landslide detection. The methodology leverages multi-encoder vision transformers, where each data modality is processed through separate lightweight pretrained encoders, achieving strong performance in landslide detection. In addition, the integration of multiple models, particularly the combination of neural networks and gradient boosting models (LightGBM and XGBoost), demonstrates the power of ensemble learning to further enhance accuracy and robustness. Derived spectral indices, such as NDVI, are integrated alongside original bands to enhance sensitivity to vegetation and surface changes. The proposed methodology achieves a state-of-the-art F1 score of 0.919 on landslide detection, addressing a patch-based classification task rather than pixel-level segmentation and operating without pre-event Sentinel-2 data, highlighting its effectiveness in a non-classical change detection setting. It also demonstrated top performance in a machine learning competition, achieving a strong balance between precision and recall and highlighting the advantages of explicitly leveraging the complementary strengths of optical and radar data. The conducted experiments and research also emphasize scalability and operational applicability, enabling flexible configurations with optical-only, SAR-only, or combined inputs, and offering a transferable framework for broader natural hazard monitoring and environmental change applications. Full training and inference code can be found in https://github.com/IoannisNasios/sentinel-landslide-cls.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a multi-modal approach for detecting landslides using Sentinel-1 SAR and Sentinel-2 optical imagery. It utilizes separate lightweight pretrained vision transformer encoders for each modality, incorporates spectral indices like NDVI, and employs an ensemble learning strategy combining neural networks with LightGBM and XGBoost. The method achieves an F1 score of 0.919 on a patch-based classification task without pre-event Sentinel-2 data and performed well in a machine learning competition. Public code is provided.
Significance. This work has potential significance in providing a flexible and effective framework for landslide detection that leverages complementary information from SAR and optical sensors without requiring pre-event imagery. The modular design allows for different input configurations, which could be useful for operational disaster response and broader environmental monitoring applications. The public availability of the code supports reproducibility.
major comments (2)
- [Results] Results section: The reported F1 score of 0.919 is presented without accompanying details on the dataset size, validation strategy, or variability across runs, which is necessary to substantiate the state-of-the-art claim and assess generalizability beyond the competition dataset.
- [Methods] Methods section: While the use of multi-encoder ViTs is described, there is insufficient information on the exact fusion mechanism between the SAR and optical feature representations prior to the ensemble step, which is central to demonstrating the benefit of multi-modal integration.
minor comments (3)
- [Abstract] The abstract mentions 'lightweight pretrained encoders' but does not specify which ViT variants or pretraining datasets are used; this should be clarified in the methods.
- No discussion of potential limitations, such as sensitivity to SAR speckle noise or optical cloud cover, is included.
- [Introduction] The competition name or reference should be included for better context on the performance.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. We have addressed the two major comments point by point below and will incorporate the requested clarifications and details into the revised manuscript.
read point-by-point responses
-
Referee: [Results] Results section: The reported F1 score of 0.919 is presented without accompanying details on the dataset size, validation strategy, or variability across runs, which is necessary to substantiate the state-of-the-art claim and assess generalizability beyond the competition dataset.
Authors: We agree that additional details would strengthen the results section and help substantiate the performance claims. The current manuscript references the competition dataset and the patch-based task but does not provide explicit statistics. In the revision we will add the total number of patches, class distribution, and the precise train/validation/test split ratios. We will also describe the validation strategy (hold-out from the competition data) and include performance variability by reporting mean F1 and standard deviation across multiple independent runs with different random seeds. These additions will appear in a new or expanded paragraph in the results section. revision: yes
-
Referee: [Methods] Methods section: While the use of multi-encoder ViTs is described, there is insufficient information on the exact fusion mechanism between the SAR and optical feature representations prior to the ensemble step, which is central to demonstrating the benefit of multi-modal integration.
Authors: We acknowledge that the fusion step between the modality-specific encoders could be described more explicitly. The manuscript outlines separate lightweight ViT encoders for SAR and optical inputs, but the precise manner in which their feature representations are combined before being passed to the ensemble (NN, LightGBM, XGBoost) is not detailed enough. In the revised methods section we will specify the fusion operation (including feature dimensions, concatenation or projection steps), how the fused representation is prepared for each ensemble member, and any ablation or analysis that isolates the contribution of the multi-modal fusion. A clarifying diagram or pseudocode will be added if space permits. revision: yes
Circularity Check
No significant circularity; purely empirical performance claim
full rationale
The paper presents a modular multi-encoder ViT + ensemble (LightGBM/XGBoost) pipeline for patch-based landslide classification on Sentinel-1/2 data, reporting an F1 of 0.919 on a competition dataset without pre-event imagery. All load-bearing steps are standard supervised training and fusion of modalities; no equations, uniqueness theorems, or predictions reduce by construction to fitted inputs or self-citations. Public code is supplied, making the result externally verifiable on the given split. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
multi-encoder vision transformers... ensemble of neural networks and gradient boosting models (LightGBM and XGBoost)... F1 score of 0.919 on landslide detection, addressing a patch-based classification task
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Derived spectral indices, such as NDVI... statistical descriptors... 126 features per patch
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Clay-CNN Hybrids: Leveraging Geospatial Foundation Models as Auxiliary Context for Landslide Detection
Hybrid U-Net augmented with Clay GFM context via two-stage LoRA reaches 64.5% test F1 on Landslide4Sense, beating both standalone Clay (55.2%) and plain U-Net (59.9%).
Reference graph
Works this paper leans on
-
[1]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A lightweight dual-stream attention network for real-time landslide monitor- ing in multi-modal remote sensing imagery. Remote Sensing Applications: Society and Environment , 101732. Di Martire, D., Tessitore, S., Brancato, D., Ciminelli, M.G., Costabile, S., Costantini, M., Graziano, G.V ., Minati, F., Ramondini, M., Calcaterra, D., 2016. Landslide detec...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Wightman, Pytorch image models, https://github.com/rwightman/pytorch-image-models, 2019
An integrated approach of machine learning and remote sensing for evaluating landslide hazards and risk hotspots, nw himalaya. Remote Sensing Applications: Society and Environment 33, 101140. Tu, Z., Talebi, H., Zhang, H., Yang, F., Milanfar, P., Bovik, A., Li, Y ., 2022. Maxvit: Multi-axis vision transformer, in: European conference on computer vi- sion,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.