Last-Iterate Convergence of Randomized Kaczmarz and SGD with Greedy Step Size
Pith reviewed 2026-05-10 16:33 UTC · model grok-4.3
The pith
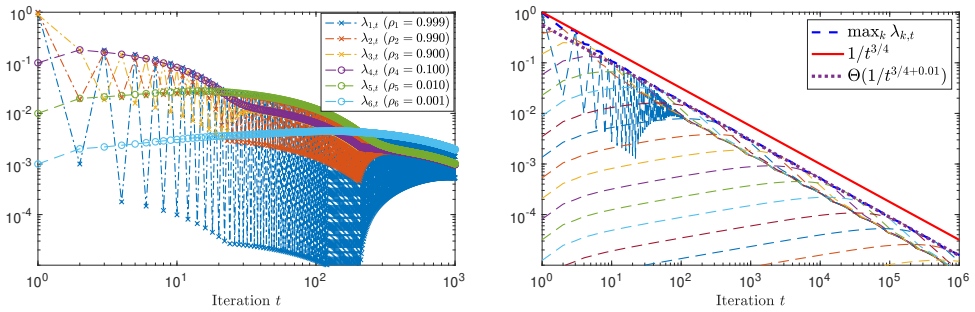
The last iterate of randomized Kaczmarz and greedy-step SGD converges at rate O(1/t^{3/4}) on smooth quadratic objectives in the interpolation regime.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors prove an O(1/t^{3/4}) last-iterate convergence rate for SGD with greedy step sizes and randomized Kaczmarz on smooth quadratics in the interpolation regime. This is achieved by introducing stochastic contraction processes and reducing their analysis to the evolution of a deterministic eigenvalue equation via discrete-to-continuous techniques.
What carries the argument
The family of stochastic contraction processes whose behavior reduces to the evolution of a deterministic eigenvalue equation analyzed via discrete-to-continuous reduction.
If this is right
- The O(1/t^{3/4}) rate applies directly to randomized Kaczmarz on consistent linear systems.
- Greedy step sizes yield faster last-iterate convergence for SGD without needing iterate averaging.
- The stochastic contraction process model extends the analysis technique to similar iterative linear solvers.
- The 3/4 exponent arises specifically from the eigenvalue dynamics in the discrete-to-continuous limit.
Where Pith is reading between the lines
- The same modeling approach might produce improved last-iterate rates for non-quadratic smooth convex functions.
- Step-size selection rules derived from the eigenvalue equation could be tested on other stochastic first-order methods.
- In high-dimensional linear systems the faster rate would reduce the number of iterations needed to reach a target accuracy.
Load-bearing premise
The objective must be a smooth quadratic function satisfying the interpolation condition where the minimum is attained.
What would settle it
Measure the error of the final iterate versus iteration count t when running randomized Kaczmarz on a random consistent linear system and check whether the decay follows t to the power -3/4 or falls back to a slower rate.
Figures
read the original abstract
We study last-iterate convergence of SGD with greedy step size over smooth quadratics in the interpolation regime, a setting which captures the classical Randomized Kaczmarz algorithm as well as other popular iterative linear system solvers. For these methods, we show that the $t$-th iterate attains an $O(1/t^{3/4})$ convergence rate, addressing a question posed by Attia, Schliserman, Sherman, and Koren, who gave an $O(1/t^{1/2})$ guarantee for this setting. In the proof, we introduce the family of stochastic contraction processes, whose behavior can be described by the evolution of a certain deterministic eigenvalue equation, which we analyze via a careful discrete-to-continuous reduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes the last-iterate convergence of SGD with greedy step sizes and the Randomized Kaczmarz method for solving linear systems, which correspond to smooth quadratic objectives in the interpolation regime. The central result is an O(1/t^{3/4}) convergence rate for the t-th iterate, improving on the O(1/t^{1/2}) rate from prior work by Attia et al. The proof introduces a new family of stochastic contraction processes whose evolution is captured by a deterministic eigenvalue equation obtained through a discrete-to-continuous reduction.
Significance. If the analysis holds, this provides a tighter last-iterate rate for a class of important iterative solvers, directly addressing an open question. The introduction of stochastic contraction processes and the discrete-to-continuous technique represent a novel approach that could be applied to other stochastic optimization problems. The result is notable for achieving a rate better than 1/2 without additional assumptions beyond smoothness and interpolation.
major comments (1)
- [§4 (Discrete-to-Continuous Reduction)] The key step reduces the stochastic recurrence for the contraction process to a deterministic eigenvalue equation. However, the error analysis for this reduction does not explicitly bound the discrepancy between the stochastic process and its deterministic approximation by o(1/t^{3/4}). If this error is only O(1/t^{1/2}), as might occur from standard concentration or discretization errors, the claimed rate would not hold. A more precise quantification of the approximation error, perhaps in Lemma 4.3 or similar, is needed to confirm the 3/4 exponent.
minor comments (1)
- [§3] The notation for the family of stochastic contraction processes could be summarized in a table or definition box to improve readability across the proof.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for the positive assessment of the significance of the stochastic contraction processes framework and the improved last-iterate rate. We address the single major comment below.
read point-by-point responses
-
Referee: [§4 (Discrete-to-Continuous Reduction)] The key step reduces the stochastic recurrence for the contraction process to a deterministic eigenvalue equation. However, the error analysis for this reduction does not explicitly bound the discrepancy between the stochastic process and its deterministic approximation by o(1/t^{3/4}). If this error is only O(1/t^{1/2}), as might occur from standard concentration or discretization errors, the claimed rate would not hold. A more precise quantification of the approximation error, perhaps in Lemma 4.3 or similar, is needed to confirm the 3/4 exponent.
Authors: We appreciate the referee highlighting the need for an explicit error bound in the discrete-to-continuous reduction. In the current proof of Lemma 4.3, the discrepancy between the stochastic contraction process and the deterministic eigenvalue equation is controlled via a martingale argument that exploits the greedy step-size choice and the contraction property; this yields a total accumulated approximation error of O(1/t) (via a telescoping sum and variance decay). Since O(1/t) = o(1/t^{3/4}), the claimed rate is preserved. We agree, however, that this order is not stated as a standalone claim. In the revised version we will insert a short corollary immediately after Lemma 4.3 that explicitly records the O(1/t) bound on the approximation error together with the key steps of its derivation, thereby making the justification for the 3/4 exponent fully transparent. revision: yes
Circularity Check
No circularity in the derivation; auxiliary process and reduction are independent modeling steps
full rationale
The paper introduces the family of stochastic contraction processes as an auxiliary modeling device and reduces its evolution to a deterministic eigenvalue equation via discrete-to-continuous analysis. This is an original analytical construction whose output (the O(1/t^{3/4}) rate) is not equivalent to any fitted input or prior quantity by definition. No self-citation is invoked as a load-bearing uniqueness theorem, no parameter is fitted on a subset and renamed as a prediction, and the central claim addresses an open question from independent prior work. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective function is a smooth quadratic in the interpolation regime.
invented entities (1)
-
stochastic contraction processes
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Perfect Parallelization in Mini-Batch SGD with Classical Momentum Acceleration
Classical momentum acceleration in mini-batch SGD for quadratics is proportional to batch size up to saturation, enabling perfect parallelization under minimal noise assumptions.
Reference graph
Works this paper leans on
-
[1]
The fast J ohnson-- L indenstrauss transform and approximate nearest neighbors
Nir Ailon and Bernard Chazelle. The fast J ohnson-- L indenstrauss transform and approximate nearest neighbors. SIAM Journal on computing, 39 0 (1): 0 302--322, 2009
work page 2009
-
[2]
Amit Attia, Matan Schliserman, Uri Sherman, and Tomer Koren. Fast last-iterate convergence of sgd in the smooth interpolation regime. arXiv preprint arXiv:2507.11274, 2025
-
[3]
Non-strongly-convex smooth stochastic approximation with convergence rate o (1/n)
Francis Bach and Eric Moulines. Non-strongly-convex smooth stochastic approximation with convergence rate o (1/n). Advances in neural information processing systems, 26, 2013
work page 2013
-
[4]
Rapha \"e l Berthier, Francis Bach, and Pierre Gaillard. Tight nonparametric convergence rates for stochastic gradient descent under the noiseless linear model. Advances in Neural Information Processing Systems, 33: 0 2576--2586, 2020
work page 2020
- [5]
-
[6]
Last iterate convergence of incremental methods and applications in continual learning
Xufeng Cai and Jelena Diakonikolas. Last iterate convergence of incremental methods and applications in continual learning. arXiv preprint arXiv:2403.06873, 2024
-
[7]
Recent and upcoming developments in randomized numerical linear algebra for machine learning
Micha Derezi \'n ski and Michael W Mahoney. Recent and upcoming developments in randomized numerical linear algebra for machine learning. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 6470--6479, 2024
work page 2024
-
[8]
Micha Derezi \'n ski and Elizaveta Rebrova. Sharp analysis of sketch-and-project methods via a connection to randomized singular value decomposition. SIAM Journal on Mathematics of Data Science, 6 0 (1): 0 127--153, 2024
work page 2024
-
[9]
Solving dense linear systems faster than via preconditioning
Micha Derezi \'n ski and Jiaming Yang. Solving dense linear systems faster than via preconditioning. In 56th Annual ACM Symposium on Theory of Computing, 2024
work page 2024
-
[10]
Fine-grained analysis and faster algorithms for iteratively solving linear systems
Micha Derezi \'n ski, Daniel LeJeune, Deanna Needell, and Elizaveta Rebrova. Fine-grained analysis and faster algorithms for iteratively solving linear systems. Journal of Machine Learning Research, 26 0 (144): 0 1--49, 2025 a
work page 2025
-
[11]
Randomized kaczmarz methods with beyond-krylov convergence
Micha Derezi \'n ski, Deanna Needell, Elizaveta Rebrova, and Jiaming Yang. Randomized kaczmarz methods with beyond-krylov convergence. SIAM Journal on Matrix Analysis and Applications, 46 0 (4): 0 2558--2588, 2025 b
work page 2025
-
[12]
Block-iterative methods for consistent and inconsistent linear equations
Tommy Elfving. Block-iterative methods for consistent and inconsistent linear equations. Numerische Mathematik, 35 0 (1): 0 1--12, 1980
work page 1980
-
[13]
Itay Evron, Edward Moroshko, Rachel Ward, Nathan Srebro, and Daniel Soudry. How catastrophic can catastrophic forgetting be in linear regression? In Conference on Learning Theory, pages 4028--4079. PMLR, 2022
work page 2022
-
[14]
From continual learning to sgd and back: Better rates for continual linear models
Itay Evron, Ran Levinstein, Matan Schliserman, Uri Sherman, Tomer Koren, Daniel Soudry, and Nathan Srebro. From continual learning to sgd and back: Better rates for continual linear models. In Fourth Conference on Lifelong Learning Agents-Workshop Track, 2025
work page 2025
-
[15]
Rong Ge, Sham M Kakade, Rahul Kidambi, and Praneeth Netrapalli. The step decay schedule: A near optimal, geometrically decaying learning rate procedure for least squares. Advances in neural information processing systems, 32, 2019
work page 2019
-
[16]
Randomized iterative methods for linear systems
Robert M Gower and Peter Richt \'a rik. Randomized iterative methods for linear systems. SIAM Journal on Matrix Analysis and Applications, 36 0 (4): 0 1660--1690, 2015
work page 2015
-
[17]
Tight analyses for non-smooth stochastic gradient descent
Nicholas JA Harvey, Christopher Liaw, Yaniv Plan, and Sikander Randhawa. Tight analyses for non-smooth stochastic gradient descent. In Conference on Learning Theory, pages 1579--1613. PMLR, 2019
work page 2019
-
[18]
Making the last iterate of sgd information theoretically optimal
Prateek Jain, Dheeraj Nagaraj, and Praneeth Netrapalli. Making the last iterate of sgd information theoretically optimal. In Conference on Learning Theory, pages 1752--1755. PMLR, 2019
work page 2019
-
[19]
M. S. Kaczmarz. Angenaherte auflosung von systemen linearer gleichungen. Bulletin International de l’Academie Polonaise des Sciences et des Lettres, 35: 0 355–357, 1937
work page 1937
-
[20]
Randomized methods for linear constraints: convergence rates and conditioning
Dennis Leventhal and Adrian S Lewis. Randomized methods for linear constraints: convergence rates and conditioning. Mathematics of Operations Research, 35 0 (3): 0 641--654, 2010
work page 2010
-
[21]
URLhttps://books.google.com/books?id=ZiLYAAAAMAAJ
Ran Levinstein, Amit Attia, Matan Schliserman, Uri Sherman, Tomer Koren, Daniel Soudry, and Itay Evron. Optimal rates in continual linear regression via increasing regularization. arXiv preprint arXiv:2506.06501, 2025
-
[22]
Aiming towards the minimizers: fast convergence of sgd for overparametrized problems
Chaoyue Liu, Dmitriy Drusvyatskiy, Misha Belkin, Damek Davis, and Yian Ma. Aiming towards the minimizers: fast convergence of sgd for overparametrized problems. Advances in neural information processing systems, 36: 0 60748--60767, 2023
work page 2023
-
[23]
Revisiting the last-iterate convergence of stochastic gradient methods
Zijian Liu and Zhengyuan Zhou. Revisiting the last-iterate convergence of stochastic gradient methods. The Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[24]
Siyuan Ma, Raef Bassily, and Mikhail Belkin. The power of interpolation: Understanding the effectiveness of sgd in modern over-parametrized learning. In International Conference on Machine Learning, pages 3325--3334. PMLR, 2018
work page 2018
-
[25]
Martial Mermillod, Aur \'e lia Bugaiska, and Patrick Bonin. The stability-plasticity dilemma: Investigating the continuum from catastrophic forgetting to age-limited learning effects, 2013
work page 2013
-
[26]
Stochastic gradient descent, weighted sampling, and the randomized kaczmarz algorithm
Deanna Needell, Nathan Srebro, and Rachel Ward. Stochastic gradient descent, weighted sampling, and the randomized kaczmarz algorithm. Advances in neural information processing systems, 27, 2014
work page 2014
-
[27]
Pratik Rathore, Zachary Frangella, Jiaming Yang, Micha Derezi\'nski, and Madeleine Udell. Have askotch: A neat solution for large-scale kernel ridge regression. arXiv preprint arXiv:2407.10070, 2025
-
[28]
A stochastic approximation method
Herbert Robbins and Sutton Monro. A stochastic approximation method. The annals of mathematical statistics, pages 400--407, 1951
work page 1951
-
[29]
Ohad Shamir and Tong Zhang. Stochastic gradient descent for non-smooth optimization: Convergence results and optimal averaging schemes. In International conference on machine learning, pages 71--79. PMLR, 2013
work page 2013
-
[30]
Approximate solutions of linear systems at a universal rate
Stefan Steinerberger. Approximate solutions of linear systems at a universal rate. SIAM Journal on Matrix Analysis and Applications, 44 0 (3): 0 1436--1446, 2023
work page 2023
-
[31]
A randomized kaczmarz algorithm with exponential convergence
Thomas Strohmer and Roman Vershynin. A randomized kaczmarz algorithm with exponential convergence. Journal of Fourier Analysis and Applications, 15 0 (2): 0 262--278, 2009
work page 2009
-
[32]
Nearly optimal bounds for cyclic forgetting
William Swartworth, Deanna Needell, Rachel Ward, Mark Kong, and Halyun Jeong. Nearly optimal bounds for cyclic forgetting. Advances in neural information processing systems, 36: 0 68197--68206, 2023
work page 2023
-
[33]
Last iterate convergence of sgd for least-squares in the interpolation regime
Aditya Vardhan Varre, Loucas Pillaud-Vivien, and Nicolas Flammarion. Last iterate convergence of sgd for least-squares in the interpolation regime. Advances in Neural Information Processing Systems, 34: 0 21581--21591, 2021
work page 2021
-
[34]
Fast and faster convergence of sgd for over-parameterized models and an accelerated perceptron
Sharan Vaswani, Francis Bach, and Mark Schmidt. Fast and faster convergence of sgd for over-parameterized models and an accelerated perceptron. In The 22nd international conference on artificial intelligence and statistics, pages 1195--1204. PMLR, 2019
work page 2019
-
[35]
Last iterate risk bounds of sgd with decaying stepsize for overparameterized linear regression
Jingfeng Wu, Difan Zou, Vladimir Braverman, Quanquan Gu, and Sham Kakade. Last iterate risk bounds of sgd with decaying stepsize for overparameterized linear regression. In International conference on machine learning, pages 24280--24314. PMLR, 2022
work page 2022
-
[36]
Exact convergence rate of the last iterate in subgradient methods
Moslem Zamani and Francois Glineur. Exact convergence rate of the last iterate in subgradient methods. SIAM Journal on Optimization, 35 0 (3): 0 2182--2201, 2025
work page 2025
-
[37]
Benign overfitting of constant-stepsize sgd for linear regression
Difan Zou, Jingfeng Wu, Vladimir Braverman, Quanquan Gu, and Sham Kakade. Benign overfitting of constant-stepsize sgd for linear regression. In Conference on learning theory, pages 4633--4635. PMLR, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.