Recognition: no theorem link
ClawGuard: A Runtime Security Framework for Tool-Augmented LLM Agents Against Indirect Prompt Injection
Pith reviewed 2026-05-12 04:12 UTC · model grok-4.3
The pith
ClawGuard enforces user-confirmed task-specific rules at every tool call to block indirect prompt injection in LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
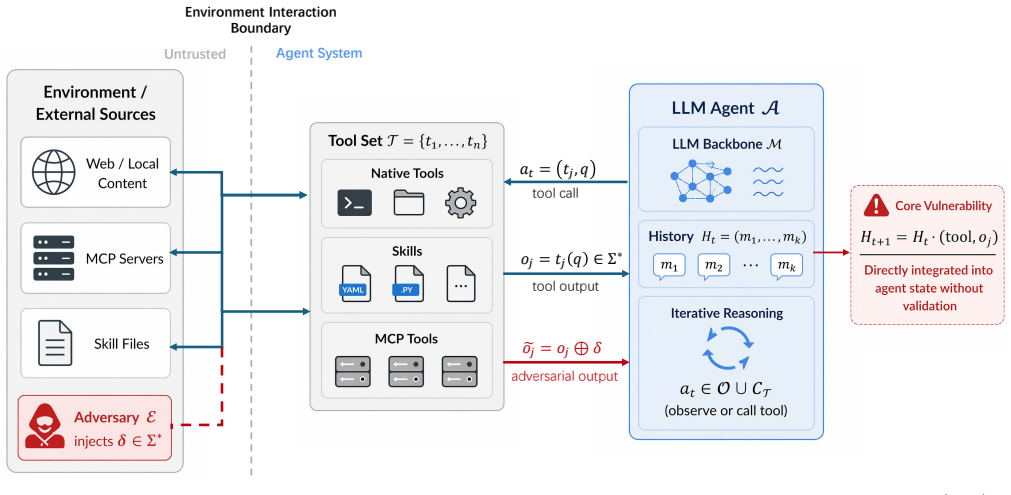
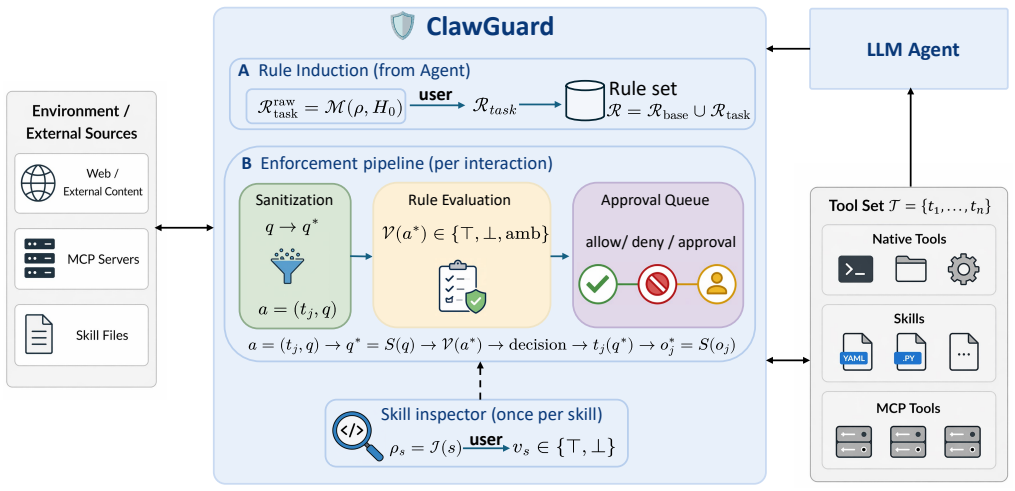
ClawGuard automatically derives task-specific access constraints from the user's stated objective prior to any external tool invocation and enforces a user-confirmed rule set at every tool-call boundary. This transforms defense from unreliable alignment into a deterministic, auditable mechanism that intercepts adversarial tool calls before any real-world effect occurs. The framework blocks all three injection pathways without model modification or infrastructure change.
What carries the argument
User-confirmed, automatically derived task-specific access constraints enforced at tool-call boundaries to create a deterministic checkpoint before execution
If this is right
- Blocks all three injection pathways across web, local, MCP, and skill channels before any tool produces real-world effects
- Preserves agent utility on operating-system, web, and code tasks across five state-of-the-art language models
- Introduces no significant token overhead during normal operation
- Requires no modification to the underlying LLM or agent infrastructure
- Applies uniformly to any tool-augmented agent that exposes tool calls for inspection
Where Pith is reading between the lines
- The same boundary-enforcement pattern could protect other autonomous systems that call external services or APIs beyond LLM agents
- Combining it with existing agent platforms would shift security from purely model-dependent to hybrid rule-based checks
- Refining the automatic derivation step might reduce the frequency of user confirmation needed for routine objectives
Load-bearing premise
Task-specific access constraints derived from the user's objective will be complete enough to block every injection pathway yet loose enough to preserve utility, and users will review and confirm them correctly.
What would settle it
An experiment in which an indirect prompt injection still triggers an unauthorized tool call after the rules are applied, or a measurable drop in success rate on the OS, web, or code utility benchmarks when the constraints are active.
Figures


read the original abstract
Tool-augmented Large Language Model (LLM) agents have demonstrated impressive capabilities in automating complex, multi-step real-world tasks, yet remain vulnerable to indirect prompt injection. Adversaries exploit this weakness by embedding malicious instructions within tool-returned content, which agents directly incorporate into their conversation history as trusted observations. To address these vulnerabilities, we introduce \textsc{ClawGuard}, a novel runtime security framework that enforces a user-confirmed rule set at every tool-call boundary, transforming unreliable alignment-dependent defense into a deterministic, auditable mechanism that intercepts adversarial tool calls before any real-world effect is produced. By automatically deriving task-specific access constraints from the user's stated objective prior to any external tool invocation, \textsc{ClawGuard} blocks all three injection pathways without model modification or infrastructure change. Experiments across five state-of-the-art language models on six injection benchmarks covering web, local, MCP, and skill channels, as well as three utility benchmarks covering OS, web, and code tasks, demonstrate that \textsc{ClawGuard} achieves robust protection against indirect prompt injection without compromising agent utility or introducing significant token overhead. This work establishes deterministic tool-call boundary enforcement as an effective defense mechanism for secure agentic AI systems. Code is publicly available at github.com/Claw-Guard/ClawGuard/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ClawGuard, a runtime security framework for tool-augmented LLM agents vulnerable to indirect prompt injection. It automatically derives task-specific access constraints from the user's stated objective before any tool use, requires user confirmation of the rule set, and deterministically enforces the constraints at every tool-call boundary to intercept adversarial calls before real-world effects occur. This is positioned as transforming alignment-dependent defenses into an auditable, model-agnostic mechanism that blocks all three injection pathways (web, local, MCP, skill channels) without infrastructure changes. The authors report experiments on five state-of-the-art LLMs across six injection benchmarks and three utility benchmarks (OS, web, code tasks), claiming robust protection with no utility degradation or significant token overhead. Public code is released at github.com/Claw-Guard/ClawGuard/.
Significance. If the empirical claims hold, the work offers a concrete, deployable alternative to purely alignment-based defenses for a timely threat in agentic AI systems. The deterministic boundary-enforcement approach and public code release are clear strengths that support reproducibility and community validation. This could meaningfully influence secure design patterns for tool-using LLM agents by prioritizing runtime auditable controls over model retraining.
major comments (2)
- [§5] §5 (Evaluation): The manuscript asserts that experiments on five models and nine benchmarks demonstrate 'robust protection' and 'no utility loss' but supplies no quantitative metrics, tables, figures, error bars, baseline comparisons, or description of how protection rates, utility preservation, or token overhead were measured; this directly prevents evaluation of the central empirical claim.
- [§3.2] §3.2 (Constraint Derivation): The automatic derivation of task-specific constraints from the user's objective is presented as both complete enough to block all injection pathways and permissive enough to preserve utility, yet no formal completeness argument, coverage analysis, or exhaustive check against the six injection benchmarks is provided; incompleteness here would leave pathways open while over-constraint would invalidate the utility results.
minor comments (1)
- [Abstract] Abstract: The text states 'nine benchmarks' while separately enumerating six injection and three utility benchmarks; a single clarifying sentence would avoid minor confusion.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions that will be incorporated into the next version of the manuscript.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation): The manuscript asserts that experiments on five models and nine benchmarks demonstrate 'robust protection' and 'no utility loss' but supplies no quantitative metrics, tables, figures, error bars, baseline comparisons, or description of how protection rates, utility preservation, or token overhead were measured; this directly prevents evaluation of the central empirical claim.
Authors: We agree that the current presentation of results in §5 is insufficient for independent evaluation. In the revised manuscript we will expand the evaluation section to include: (1) tables reporting protection rates (percentage of blocked adversarial tool calls) for each of the five models across the six injection benchmarks, (2) utility metrics (task success rates on the three utility benchmarks with and without ClawGuard), (3) token-overhead measurements with standard deviations, (4) explicit descriptions of how each metric was computed, and (5) baseline comparisons against undefended agents. Error bars and statistical details will be added where multiple runs were performed. These changes will make the empirical claims fully verifiable. revision: yes
-
Referee: [§3.2] §3.2 (Constraint Derivation): The automatic derivation of task-specific constraints from the user's objective is presented as both complete enough to block all injection pathways and permissive enough to preserve utility, yet no formal completeness argument, coverage analysis, or exhaustive check against the six injection benchmarks is provided; incompleteness here would leave pathways open while over-constraint would invalidate the utility results.
Authors: We acknowledge the lack of a formal completeness argument or explicit coverage analysis. While a rigorous formal proof is difficult due to the open-ended semantics of natural-language objectives, we will add a new subsection in §3.2 that provides: (1) the precise derivation procedure with illustrative examples, (2) an exhaustive per-benchmark coverage table mapping each of the six injection scenarios to the constraints that would have been derived and how they block the malicious calls, and (3) discussion of how user confirmation of the rule set mitigates both under- and over-constraint risks. We will also reference the empirical results from the injection benchmarks to demonstrate that the derived constraints were sufficient in practice. These additions will directly address the referee's concern. revision: partial
Circularity Check
No significant circularity; framework description and evaluation are independent
full rationale
The paper presents ClawGuard as a runtime security layer that derives task-specific constraints from the user's objective and enforces them at tool-call boundaries. No equations, fitted parameters, or self-referential derivations appear in the provided text. The central mechanism is described as an independent, deterministic enforcement step rather than a quantity computed from the same data or claims it protects. Empirical results on injection and utility benchmarks are reported separately and do not reduce to the derivation procedure by construction. Self-citation is absent from the load-bearing claims, and the automatic derivation is treated as a practical engineering choice whose completeness is left to experimental validation rather than assumed via prior self-referential results.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Sealing the Audit-Runtime Gap for LLM Skills
SIGIL cryptographically seals the audit-runtime gap for LLM skills via an on-chain registry with four publication types, DAO vetting, and a runtime verification loader that enforces integrity and permissions.
-
From Craft to Kernel: A Governance-First Execution Architecture and Semantic ISA for Agentic Computers
Arbiter-K is a new execution architecture that treats LLMs as probabilistic processors inside a neuro-symbolic kernel with a semantic ISA to enable deterministic security enforcement and unsafe trajectory interdiction...
Reference graph
Works this paper leans on
-
[1]
Claude Code: Agentic coding tool,
Anthropic, “Claude Code: Agentic coding tool,” https://www.anthropic. com/claude-code, 2024
work page 2024
-
[2]
——, “Claude computer use,” https://www.anthropic.com/news/ computer-use, 2024
work page 2024
-
[3]
——, “Model context protocol,” https://modelcontextprotocol.io, 2024
work page 2024
-
[4]
Invoke-deobfuscation: Ast- based and semantics-preserving deobfuscation for powershell scripts,
H. Chai, L. Ying, H. Duan, and D. Zha, “Invoke-deobfuscation: Ast- based and semantics-preserving deobfuscation for powershell scripts,” in2022 52nd Annual IEEE/IFIP International Conference on Depend- able Systems and Networks (DSN). IEEE, 2022, pp. 295–306
work page 2022
- [5]
-
[6]
Evaluating Large Language Models Trained on Code
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
{StruQ}: Defending against prompt injection with structured queries,
S. Chen, J. Piet, C. Sitawarin, and D. Wagner, “{StruQ}: Defending against prompt injection with structured queries,” in34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 2383–2400
work page 2025
-
[8]
ClaWHub: Open skill registry for OpenClaw agents,
ClaWHub Community, “ClaWHub: Open skill registry for OpenClaw agents,” https://clawhub.ai, 2026
work page 2026
-
[9]
Defeating Prompt Injections by Design
E. Debenedetti, I. Shumailov, T. Fan, J. Hayes, N. Carlini, D. Fabian, C. Kern, C. Shi, A. Terzis, and F. Tram `er, “Defeating prompt injections by design,”ArXiv, vol. abs/2503.18813, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:277940706
work page internal anchor Pith review arXiv 2025
-
[10]
AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents
E. Debenedetti, J. Zhang, M. Balunovi’c, L. Beurer-Kellner, M. Fischer, and F. Tram `er, “Agentdojo: A dynamic environment to evaluate attacks and defenses for llm agents,”ArXiv, vol. abs/2406.13352,
work page internal anchor Pith review arXiv
-
[11]
Available: https://api.semanticscholar.org/CorpusID: 270619628
[Online]. Available: https://api.semanticscholar.org/CorpusID: 270619628
-
[12]
AutoGPT: An autonomous GPT-4 experiment,
S. Gravitas, “AutoGPT: An autonomous GPT-4 experiment,” https:// github.com/Significant-Gravitas/AutoGPT, 2023
work page 2023
-
[13]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection,” inProceed- ings of the 16th ACM workshop on artificial intelligence and security, 2023, pp. 79–90
work page 2023
-
[14]
Promptlocate: Localizing prompt injection attacks,
Y . Jia, Y . Liu, Z. Shao, J. Jia, and N. Z. Gong, “Promptlocate: Localizing prompt injection attacks,” inIEEE Symposium on Security and Privacy, 2026
work page 2026
-
[15]
Mitre att&ck applications in cybersecurity and the way forward.arXiv preprint arXiv:2502.10825, 2025
Y . Jiang, Q. Meng, F. Shang, N. Oo, L. T. H. Minh, H. W. Lim, and B. Sikdar, “Mitre att&ck applications in cybersecurity and the way forward,”arXiv preprint arXiv:2502.10825, 2025
-
[16]
When ai meets the web: Prompt injection risks in third-party ai chatbot plugins,
Y . Kaya, A. Landerer, S. Pletinckx, M. Zimmermann, C. Kruegel, and G. Vigna, “When ai meets the web: Prompt injection risks in third-party ai chatbot plugins,”arXiv preprint arXiv:2511.05797, 2025
-
[17]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Agentbench: Evaluating LLMs as agents,
X. Liu, H. Yu, H. Zhang, Y . Xu, X. Lei, H. Lai, Y . Gu, H. Ding, K. Men, K. Yang, S. Zhang, X. Deng, A. Zeng, Z. Du, C. Zhang, S. Shen, T. Zhang, Y . Su, H. Sun, M. Huang, Y . Dong, and J. Tang, “Agentbench: Evaluating LLMs as agents,” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/fo...
work page 2024
-
[19]
Prompt Injection attack against LLM-integrated Applications
Y . Liu, G. Deng, Y . Li, K. Wang, Z. Wang, X. Wang, T. Zhang, Y . Liu, H. Wang, Y . Zhenget al., “Prompt injection attack against llm-integrated applications,”arXiv preprint arXiv:2306.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Formalizing and benchmarking prompt injection attacks and defenses,
Y . Liu, Y . Jia, R. Geng, J. Jia, and N. Z. Gong, “Formalizing and benchmarking prompt injection attacks and defenses,” in33rd USENIX Security Symposium (USENIX Security 24), 2024, pp. 1831–1847
work page 2024
-
[21]
Minimax-01: Scaling foundation models with lightning attention.arXiv preprint arXiv:2501.08313, 2025
MiniMax, “Minimax-01: Scaling foundation models with lightning attention,” 2025. [Online]. Available: https://arxiv.org/abs/2501.08313
-
[22]
MITRE ATT&CK tactic TA0006: Credential access,
MITRE Corporation, “MITRE ATT&CK tactic TA0006: Credential access,” https://attack.mitre.org/tactics/TA0006/, 2018, accessed 2024
work page 2018
-
[23]
MITRE ATT&CK technique T1041: Exfiltration over C2 chan- nel,
——, “MITRE ATT&CK technique T1041: Exfiltration over C2 chan- nel,” https://attack.mitre.org/techniques/T1041/, 2018, accessed 2024
work page 2018
-
[24]
Kimi K2.5: Visual Agentic Intelligence
Moonshot AI, “Kimi k2.5: Visual agentic intelligence,” 2026. [Online]. Available: https://arxiv.org/abs/2602.02276
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
WebGPT: Browser-assisted question-answering with human feedback
R. Nakano, J. Hilton, S. Balaji, J. Wu, L. Ouyang, C. Kim, C. Hesse, S. Jain, V . Kosaraju, W. Saunderset al., “Webgpt: Browser- assisted question-answering with human feedback,”arXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
OpenClaw: An open agent framework,
OpenClaw Team, “OpenClaw: An open agent framework,” https:// openclaw.ai, 2025
work page 2025
-
[27]
Command-line obfuscation de- tection using small language models,
V . Outrata, M. A. Polak, and M. Kopp, “Command-line obfuscation de- tection using small language models,”arXiv preprint arXiv:2408.02637, 2024
-
[28]
Training language models to follow instructions with human feedback
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. E. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. J. Lowe, “Training language models to follow instructions with human feedback,”ArXiv, vol. abs/2203.02155,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Available: https://api.semanticscholar.org/CorpusID: 246426909
[Online]. Available: https://api.semanticscholar.org/CorpusID: 246426909
-
[30]
Ignore Previous Prompt: Attack Techniques For Language Models
F. Perez and I. Ribeiro, “Ignore previous prompt: Attack techniques for language models,”arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Mcp safety audit: Llms with the model context protocol allow major security exploits
B. Radosevich and J. Halloran, “Mcp safety audit: Llms with the model context protocol allow major security exploits,”ArXiv, vol. abs/2504.03767, 2025. [Online]. Available: https://api.semanticscholar. org/CorpusID:277621603
-
[32]
Identifying the risks of lm agents with an lm-emulated sandbox,
Y . Ruan, H. Dong, A. Wang, S. Pitis, Y . Zhou, J. Ba, Y . Dubois, C. J. Maddison, and T. Hashimoto, “Identifying the risks of lm agents with an lm-emulated sandbox,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[33]
Great, now write an article about that: The crescendo{Multi-Turn}{LLM}jailbreak attack,
M. Russinovich, A. Salem, and R. Eldan, “Great, now write an article about that: The crescendo{Multi-Turn}{LLM}jailbreak attack,” in 34th USENIX Security Symposium (USENIX Security 25), 2025, pp. 2421–2440
work page 2025
-
[34]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in neural infor- mation processing systems, vol. 36, pp. 68 539–68 551, 2023
work page 2023
-
[35]
D. Schmotz, L. Beurer-Kellner, S. Abdelnabi, and M. Andriushchenko, “Skill-inject: Measuring agent vulnerability to skill file attacks,” ArXiv, vol. abs/2602.20156, 2026. [Online]. Available: https://api. semanticscholar.org/CorpusID:285972708
-
[36]
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, “” do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 1671–1685
work page 2024
-
[37]
Q. team, “Qwen3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
E. Wallace, K. Xiao, R. Leike, L. Weng, J. Heidecke, and A. Beu- tel, “The instruction hierarchy: Training llms to prioritize privileged instructions,”arXiv preprint arXiv:2404.13208, 2024
work page internal anchor Pith review arXiv 2024
-
[39]
Agentspec: Customizable runtime enforcement for safe and reliable llm agents
H. Wang, C. M. Poskitt, and J. Sun, “Agentspec: Customizable runtime enforcement for safe and reliable llm agents.” inProceedings of the IEEE/ACM International Conference on Software Engineering, ICSE, 2026, pp. 12–18
work page 2026
-
[40]
MCPTox: A Benchmark for Tool Poisoning Attack on Real-World MCP Servers,
Z. Wang, Y . Gao, Y . Wang, S. Liu, H. Sun, H. Cheng, G. Shi, H. Du, and X. Li, “Mcptox: A benchmark for tool poisoning attack on real-world mcp servers,”arXiv preprint arXiv:2508.14925, 2025
-
[41]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” inThe eleventh international conference on learning representations, 2022
work page 2022
-
[42]
Benchmarking and defending against indirect prompt injection attacks on large language models,
J. Yi, Y . Xie, B. Zhu, K. Hines, E. Kiciman, G. Sun, X. Xie, and F. Wu, “Benchmarking and defending against indirect prompt injection attacks on large language models,”Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .1,
-
[43]
Available: https://api.semanticscholar.org/CorpusID: 266521508
[Online]. Available: https://api.semanticscholar.org/CorpusID: 266521508
-
[44]
GLM-5: from Vibe Coding to Agentic Engineering
A. Zeng, X. Lv, Z. Hou, Z. Du, Q. Zheng, B. Chen, D. Yin, C. Ge, C. Huang, C. Xieet al., “Glm-5: from vibe coding to agentic engineer- ing,”arXiv preprint arXiv:2602.15763, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents,
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 10 471–10 506
work page 2024
-
[46]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Z. Zhang, S. Cui, Y . Lu, J. Zhou, J. Yang, H. Wang, and M. Huang, “Agent-safetybench: Evaluating the safety of llm agents,”arXiv preprint arXiv:2412.14470, 2024
work page internal anchor Pith review arXiv 2024
-
[47]
X. Zong, Z. Shen, L. Wang, Y . Lan, and C. Yang, “Mcp-safetybench: A benchmark for safety evaluation of large language models with real-world mcp servers,”ArXiv, vol. abs/2512.15163, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:283920063
-
[48]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023. 11 APPENDIX Table IV lists the default pattern libraryPused by the Content Sanitizer. Each entry specifies the secret category, its coverage, and the redaction token subst...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.