Recognition: unknown
Growing Pains: Extensible and Efficient LLM Benchmarking Via Fixed Parameter Calibration
Pith reviewed 2026-05-10 16:32 UTC · model grok-4.3
The pith
A fixed set of 100 anchor questions per dataset lets new LLM benchmarks join an existing suite while predicting full performance within 2-3 points and preserving model rankings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
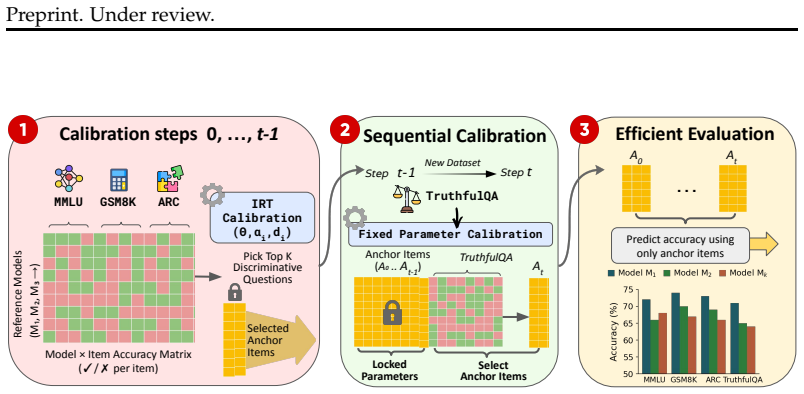
The central claim is that holding previously calibrated item parameters fixed while estimating only the parameters of new items via a shared anchor set allows the multidimensional IRT model to recover full-dataset performance from 100 anchors per dataset, with absolute error of 2-3 percentage points and Spearman rank correlation of at least 0.9, thereby supporting direct score comparison across models evaluated at different times.
What carries the argument
Multidimensional Item Response Theory model that calibrates new item parameters while holding anchor item parameters fixed across evaluation periods.
If this is right
- New datasets can be introduced without requiring every existing model to be re-evaluated on them.
- Scores obtained in different time periods remain directly comparable through the shared anchor scale.
- The marginal cost of adding each new dataset stays constant regardless of how many models have already been tested.
- Model rankings across the entire suite are preserved with high fidelity from the partial anchor evaluations.
Where Pith is reading between the lines
- The same anchor-based linking could be used to retire outdated datasets while still allowing historical model scores to be placed on the updated scale.
- Public benchmark repositories could maintain a single growing evaluation ledger in which any model evaluated at any past or future date receives a comparable score vector.
- The constant-cost property would make it feasible to keep adding specialized or adversarial datasets without the total evaluation budget exploding.
Load-bearing premise
LLM responses to the benchmark items behave according to the assumptions of a multidimensional IRT model so that a fixed set of 100 anchors is enough to recover accurate item parameters and full-dataset predictions.
What would settle it
Applying the same fixed-anchor procedure to a fresh collection of models and datasets and measuring that predicted accuracies deviate by more than 3 percentage points from actual full evaluations or that Spearman rank correlation drops below 0.9.
Figures







read the original abstract
The rapid release of both language models and benchmarks makes it increasingly costly to evaluate every model on every dataset. In practice, models are often evaluated on different samples, making scores difficult to compare across studies. To address this, we propose a framework based on multidimensional Item Response Theory (IRT) that uses anchor items to calibrate new benchmarks to the evaluation suite while holding previously calibrated item parameters fixed. Our approach supports a realistic evaluation setting in which datasets are introduced over time and models are evaluated only on the datasets available at the time of evaluation, while a fixed anchor set for each dataset is used so that results from different evaluation periods can be compared directly. In large-scale experiments on more than $400$ models, our framework predicts full-evaluation performance within 2-3 percentage points using only $100$ anchor questions per dataset, with Spearman $\rho \geq 0.9$ for ranking preservation, showing that it is possible to extend benchmark suites over time while preserving score comparability, at a constant evaluation cost per new dataset. Code available at https://github.com/eliyahabba/growing-pains
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multidimensional IRT framework that uses a fixed set of 100 anchor questions per dataset to calibrate new benchmarks while holding item parameters fixed, enabling prediction of full-evaluation LLM performance and preservation of model rankings as new datasets are added over time. Large-scale experiments on >400 models report that full scores can be predicted within 2-3 percentage points with Spearman ρ ≥ 0.9 for rankings, at constant per-model evaluation cost.
Significance. If the central claims hold under realistic introduction conditions, the work provides a concrete, extensible method for maintaining comparable LLM benchmark scores without repeated full evaluations, directly addressing the practical problem of benchmark proliferation. The scale of the reported experiments (>400 models) and public code release are notable strengths that support reproducibility and empirical grounding.
major comments (1)
- The large-scale experiments fit IRT parameters using the full set of >400 models, but the framework targets the realistic regime in which a new dataset is introduced with only a small number of early models available for anchor-based calibration. No results are shown for item-parameter estimation or downstream prediction accuracy when the response matrix is small (e.g., 5–20 models), leaving the 2–3 pp accuracy and ρ ≥ 0.9 guarantees untested in the low-data regime that is load-bearing for the extensibility claim.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which correctly identifies a gap between our large-scale experimental setup and the low-data regime most relevant to the framework's extensibility claims. We address this point directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The large-scale experiments fit IRT parameters using the full set of >400 models, but the framework targets the realistic regime in which a new dataset is introduced with only a small number of early models available for anchor-based calibration. No results are shown for item-parameter estimation or downstream prediction accuracy when the response matrix is small (e.g., 5–20 models), leaving the 2–3 pp accuracy and ρ ≥ 0.9 guarantees untested in the low-data regime that is load-bearing for the extensibility claim.
Authors: We agree that this is a substantive limitation of the current experiments. While fitting on the full >400-model response matrix demonstrates the upper-bound performance of the fixed-parameter approach, it does not test the realistic case in which a new dataset's 100 anchor items must be calibrated using only the small number of early models that have been evaluated on it. In the revised manuscript we will add a new set of experiments that simulate the low-data regime: for each dataset we will randomly subsample the response matrix to 5, 10, 15, and 20 models to re-estimate the anchor item parameters (keeping the multidimensional IRT structure and all other hyperparameters fixed), then use the resulting fixed parameters to predict full-dataset scores and rankings for the remaining held-out models. We will report mean absolute prediction error and Spearman ρ under these conditions, together with a discussion of the minimum number of models needed for stable calibration. This will either substantiate the reported accuracy guarantees in the target regime or qualify them appropriately. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents a multidimensional IRT calibration framework for extending benchmarks via fixed anchor items and validates its performance empirically by comparing anchor-based predictions to full-dataset evaluations across >400 models, achieving the reported 2-3 pp accuracy and Spearman ρ ≥ 0.9. No load-bearing steps reduce by construction to inputs: the IRT fitting and prediction use standard parameter estimation on response matrices, with held-out validation providing external grounding rather than tautological equivalence. No self-citations, ansatzes, or renamings of known results are invoked as the central justification, and the method remains self-contained against the experimental benchmarks without definitional loops or fitted inputs relabeled as independent predictions.
Axiom & Free-Parameter Ledger
free parameters (2)
- IRT item parameters (difficulty, discrimination)
- Model ability parameters
axioms (2)
- domain assumption LLM responses to benchmark questions conform to the assumptions of multidimensional Item Response Theory
- domain assumption Anchor items are representative and sufficient to calibrate new dataset items without bias
Forward citations
Cited by 1 Pith paper
-
Beyond Fixed Benchmarks and Worst-Case Attacks: Dynamic Boundary Evaluation for Language Models
Dynamic Boundary Evaluation adaptively identifies each LLM's performance boundary on a shared difficulty scale using a calibrated item bank and a search algorithm.
Reference graph
Works this paper leans on
-
[1]
URL https://arxiv.org/abs/2306.10062. Cl´ementine Fourrier, Nathan Habib, Alina Lozovskaya, Konrad Szafer, and Thomas Wolf. Open llm leaderboard v2. https://huggingface.co/spaces/open-llm-leaderboard/ open llm leaderboard,
-
[2]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7,
2021
-
[3]
A rosetta stone for ai benchmarks, 2025
URLhttps://arxiv.org/abs/2512.00193. Valentin Hofmann, David Heineman, Ian Magnusson, Kyle Lo, Jesse Dodge, Maarten Sap, Pang Wei Koh, Chun Wang, Hannaneh Hajishirzi, and Noah A. Smith. Fluid language model benchmarking,
-
[4]
arXiv preprint arXiv:2509.11106 , year=
URLhttps://arxiv.org/abs/2509.11106. David Ili´c and Gilles E. Gignac. Evidence of interrelated cognitive-like capabilities in large language models: Indications of artificial general intelligence or achievement?Intelligence, 106:101858, September
-
[5]
doi: 10.1016/j.intell.2024.101858
ISSN 0160-2896. doi: 10.1016/j.intell.2024.101858. URL http://dx.doi.org/10.1016/j.intell.2024.101858. Douwe Kiela, Max Bartolo, Yixin Nie, Divyansh Kaushik, Atticus Geiger, Zhengxuan Wu, Bertie Vidgen, Grusha Prasad, Amanpreet Singh, Pratik Ringshia, Zhiyi Ma, Tristan Thrush, Sebastian Riedel, Zeerak Waseem, Pontus Stenetorp, Robin Jia, Mohit Bansal, Chr...
-
[6]
Dynabench: Rethinking benchmarking in NLP
Asso- ciation for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.324. URL https://aclanthology.org/2021.naacl-main.324. 10 Preprint. Under review. Seock-Ho Kim and Allan S. Cohen. A comparison of linking and concurrent calibration under item response theory.Applied Psychological Measurement, 22:131 – 143,
-
[7]
metabench– a sparse benchmark of reasoning and knowledge in large language models
URL https://arxiv.org/abs/2407.12844. Michael J. Kolen and Robert L. Brennan. Test equating, scaling, and linking: Methods and practices
-
[8]
URLhttps://api.semanticscholar.org/CorpusID:119066024. John P . Lalor, Hao Wu, and Hong Yu. Building an evaluation scale using item re- sponse theory. In Jian Su, Kevin Duh, and Xavier Carreras (eds.),Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp. 648– 657li2026adaptivetestingllmevaluation, Austin, Texas,
2016
-
[9]
Association for Compu- tational Linguistics. doi: 10.18653/v1/D16-1062. URL https://aclanthology.org/ D16-1062. Peiyu Li, Xiuxiu Tang, Si Chen, Ying Cheng, Ronald A. Metoyer, Ting Hua, and Nitesh V . Chawla. Adaptive testing for llm evaluation: A psychometric alternative to static bench- marks.ArXiv preprint, abs/2511.04689,
-
[10]
URLhttps://arxiv.org/abs/2511.04689. Frederic M. Lord and Marilyn S. Wingersky. Comparison of irt true-score and equipercentile observed-score ”equatings”.Applied Psychological Measurement, 8:453 – 461,
-
[11]
Sasha Luccioni, Yacine Jernite, and Emma Strubell
URL https://api.semanticscholar.org/CorpusID:121685628. Sasha Luccioni, Yacine Jernite, and Emma Strubell. Power hungry processing: Watts driving the cost of ai deployment? InThe 2024 ACM Conference on Fairness Accountability and Transparency, FAccT ’24. ACM,
2024
-
[12]
doi: 10.1145/3630106.3658542. URL http: //dx.doi.org/10.1145/3630106.3658542. Aviya Maimon, Amir DN Cohen, Gal Vishne, Shauli Ravfogel, and Reut Tsarfaty. Iq test for llms: An evaluation framework for uncovering core skills in llms,
-
[13]
URL https://arxiv.org/abs/2507.20208. Yotam Perlitz, Elron Bandel, Ariel Gera, Ofir Arviv, Liat Ein-Dor, Eyal Shnarch, Noam Slonim, Michal Shmueli-Scheuer, and Leshem Choshen. Efficient benchmarking (of language models). In Kevin Duh, Helena Gomez, and Steven Bethard (eds.),Pro- ceedings of the 2024 Conference of the North American Chapter of the Associat...
-
[14]
URLhttps://openreview.net/forum?id=qAml3FpfhG
OpenReview.net, 2024b. URLhttps://openreview.net/forum?id=qAml3FpfhG. Felipe Maia Polo, Ronald Xu, Lucas Weber, M ´ırian Silva, Onkar Bhardwaj, Leshem Choshen, Allysson Flavio Melo de Oliveira, Yuekai Sun, and Mikhail Yurochkin. Effi- cient multi-prompt evaluation of llms. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Ja...
2024
-
[15]
and Jia, Robin and Boyd-Graber, Jordan
Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.346. URLhttps://aclanthology.org/2021.acl-long.346. Martha L. Stocking and Frederic M. Lord. Developing a common metric in item response theory.ETS Research Report Series, 1982(1):i–29,
-
[16]
doi: https://doi.org/10.1002/j. 2333-8504.1982.tb01311.x. URL https://onlinelibrary.wiley.com/doi/abs/10.1002/j. 2333-8504.1982.tb01311.x. Sang Truong, Yuheng Tu, Percy Liang, Bo Li, and Sanmi Koyejo. Reliable and efficient amortized model-based evaluation,
work page doi:10.1002/j 1982
-
[17]
URLhttps://arxiv.org/abs/2503.13335. Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Benjamin Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Sreemanti Dey, Shubh-Agrawal, Sandeep Singh Sandha, Siddartha Venkat Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, and Micah Goldblum. Livebench: A challenging, co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.