Untrained CNNs Match Backpropagation at V1: A Systematic RSA Comparison of Four Learning Rules Against Human fMRI
Pith reviewed 2026-05-10 06:35 UTC · model grok-4.3
The pith
Untrained CNNs align better with human V1 than backpropagation-trained models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
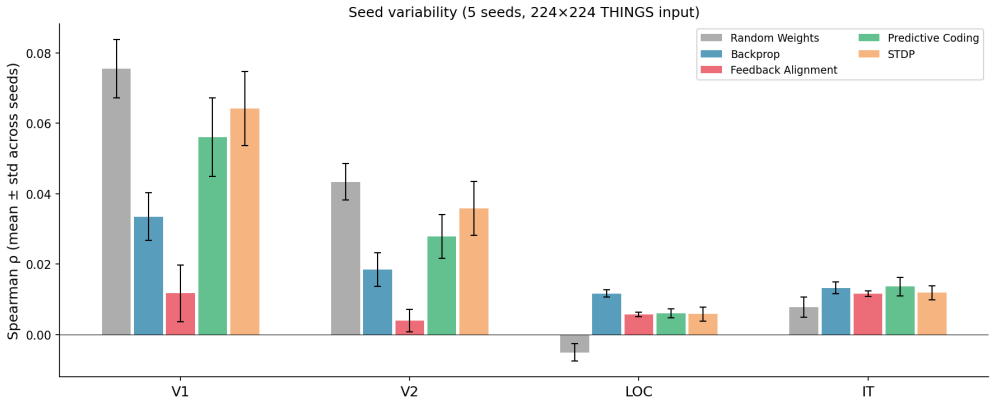
At V1/V2 the untrained random-weights baseline exceeds backpropagation in RSA correlation with human fMRI (rho = 0.076 vs. rho = 0.034), STDP reaches the highest alignment among trained rules, only backpropagation reliably exceeds baseline at LOC, and all five conditions (including untrained) show statistically indistinguishable alignment at IT.
What carries the argument
Representational Similarity Analysis (RSA) applied to identical CNN architectures under four learning rules plus an untrained baseline, measured against fMRI responses in V1, V2, LOC, and IT.
Load-bearing premise
Representational similarity analysis on the THINGS-fMRI dataset with 720 stimuli provides a reliable and unbiased measure of alignment between model representations and human visual cortex activity.
What would settle it
Retraining the same architectures on a different or larger image set and obtaining significantly higher RSA correlations for backpropagation than for the untrained baseline at V1 would falsify the architecture-driven claim.
Figures








read the original abstract
A central question in computational neuroscience is whether the learning rule used to train a neural network determines how well its internal representations align with those of the human visual cortex. We present a systematic comparison of four learning rules (backpropagation (BP), feedback alignment (FA), predictive coding (PC), and spike-timing-dependent plasticity (STDP)) applied to identical convolutional architectures and evaluated against human fMRI data from the THINGS-fMRI dataset (720 stimuli, 3 subjects) using Representational Similarity Analysis (RSA). All models process stimuli at 224 x 224 resolution; results are averaged across 5 random seeds. Crucially, we include an untrained random-weights baseline that reveals the dominant role of architecture. At V1/V2, the untrained baseline exceeds backpropagation (rho = 0.076 vs. rho = 0.034; Delta-rho = +0.044, p < 0.001), and STDP achieves the highest V1 alignment among trained rules (rho = 0.064). At LOC, only BP reliably exceeds the random baseline (rho = 0.012 vs. -0.005, p < 0.001). At IT, all five conditions converge (rho = 0.008-0.014) with no significant pairwise differences among trained rules (p > 0.05, FDR-corrected). FA consistently produces the lowest alignment at V1, V2, and LOC (rho = 0.012 at V1, below all other conditions). Partial RSA confirms all effects survive pixel-similarity control. Seed variability is small relative to between-rule differences at V1/V2. These results demonstrate that early visual alignment is architecture-driven, learning rules differentiate only at intermediate areas, and all rules converge at the highest levels of the hierarchy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a systematic RSA comparison of four learning rules (BP, FA, PC, STDP) plus an untrained random-weights baseline on identical CNNs against THINGS-fMRI data (720 stimuli, 3 subjects) shows architecture dominates early visual alignment: at V1/V2 the untrained baseline exceeds BP (rho=0.076 vs 0.034, p<0.001), STDP is strongest among trained rules, only BP exceeds random at LOC, and all conditions converge at IT with no significant differences among trained rules.
Significance. If the results hold, the work is significant because it provides a controlled empirical demonstration that architectural inductive biases, rather than the choice of learning rule, primarily determine alignment with human V1/V2 representations. The inclusion of an untrained baseline, multiple alternative rules, seed averaging, and a partial RSA pixel-similarity control strengthens the design and yields a clear hierarchical pattern (differentiation at intermediate areas, convergence at IT) that can guide future modeling.
major comments (1)
- Results (V1/V2 comparison and Abstract): The central claim that untrained exceeds BP at V1/V2 (rho = 0.076 vs. rho = 0.034; Delta-rho = +0.044, p < 0.001) to conclude architecture-driven alignment rests on group-level brain RDMs from only 3 subjects. No noise-ceiling, split-half reliability, or inter-subject consistency metrics for the V1/V2 RDMs are reported, leaving open the possibility that the difference and its p-value reflect sampling variability or low SNR rather than a robust effect.
minor comments (2)
- Abstract: The statement that 'partial RSA confirms all effects survive pixel-similarity control' is underspecified; the exact control variable, how partial correlations are computed, and which effects survive should be stated more precisely.
- Methods: The correspondence between model layers and cortical areas (V1/V2, LOC, IT), the precise RSA implementation (distance metric, RDM construction from fMRI and activations), and stimulus preprocessing details for the 224x224 inputs are not fully elaborated, limiting reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for emphasizing the need to demonstrate robustness of the V1/V2 results given the limited number of subjects. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Results (V1/V2 comparison and Abstract): The central claim that untrained exceeds BP at V1/V2 (rho = 0.076 vs. rho = 0.034; Delta-rho = +0.044, p < 0.001) to conclude architecture-driven alignment rests on group-level brain RDMs from only 3 subjects. No noise-ceiling, split-half reliability, or inter-subject consistency metrics for the V1/V2 RDMs are reported, leaving open the possibility that the difference and its p-value reflect sampling variability or low SNR rather than a robust effect.
Authors: We agree that reliability metrics are important to report when using group-level RDMs from a small number of subjects (here, the three subjects available in THINGS-fMRI). In the revised manuscript we will add split-half reliability (Spearman-Brown corrected correlation between RDMs computed on odd/even stimulus splits), noise-ceiling estimates (average correlation of each subject's RDM with the group RDM), and inter-subject consistency (average pairwise correlation between individual subject RDMs) for V1/V2 and the other ROIs. These will be presented in the Results section alongside the existing RSA values. We will also clarify that the reported p-values were obtained via stimulus-label permutation tests (10,000 permutations) and will include supplementary subject-level RSA analyses to show that the pattern of untrained > BP at V1/V2 holds in individual subjects where detectable. While the small sample size remains a limitation of the dataset, these additions will allow readers to evaluate whether the observed differences exceed what would be expected from sampling variability or low SNR. We do not expect the central conclusions to change. revision: yes
Circularity Check
No circularity: purely empirical RSA comparisons on external fMRI benchmark
full rationale
The paper reports direct empirical measurements of Spearman rho between model RDMs (from CNNs trained with BP, FA, PC, STDP or left untrained) and human brain RDMs from the THINGS-fMRI dataset. No equations, derivations, fitted parameters, or predictions are defined; the reported values (e.g., rho = 0.076 untrained vs. 0.034 BP at V1/V2) are computed outputs of standard RSA on fixed architectures and independent neural data. No self-citations, uniqueness theorems, or ansatzes are invoked to support the central claims. The analysis is self-contained against the external benchmark, with seed averaging and pixel-similarity controls providing independent checks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Representational similarity analysis provides a valid proxy for comparing model and brain representations
Forward citations
Cited by 1 Pith paper
-
Cross-Species RSA Reveals Conserved Early Visual Alignment but Divergent Higher-Area Rankings Across Human fMRI and Macaque Electrophysiology
Cross-species RSA finds conserved early visual cortex alignment across learning rules but divergent IT rankings, with model capacity and training data limiting higher-area matches more than the specific rule.
Reference graph
Works this paper leans on
-
[1]
Bi, G.-q. and Poo, M.-m. (1998). Synaptic modifications inculturedhippocampalneurons: dependenceonspike timing, synaptic strength, and postsynaptic cell type. Journal of Neuroscience, 18:10464–10472
work page 1998
-
[2]
Crick, F.(1989).Therecentexcitementaboutneuralnet- works.Nature, 337:129–132
work page 1989
-
[3]
Gifford, A. T. and Cichy, R. M. (2022). THINGS-fMRI: A large-scale dataset of fMRI brain responses to 22,248 images from the THINGS object concept database. NeuroImage, 264:119628
work page 2022
-
[4]
Corriveau, A., Van Wicklin, C., and Baker, C. I. 9 (2019). THINGS: A database of 1,854 object con- cepts and more than 26,000 naturalistic object images. PLOS ONE, 14:e0223792
work page 2019
-
[5]
Kriegeskorte, N., Mur, M., and Bandettini, P. (2008). Representational similarity analysis – connecting the branches of systems neuroscience.Frontiers in Systems Neuroscience, 2:4
work page 2008
-
[6]
Lillicrap, T. P., Cownden, D., Tweed, D. B., and Aker- man, C. J. (2016). Random synaptic feedback weights support error backpropagation for deep learning.Na- ture Communications, 7:13276
work page 2016
-
[7]
P., Santoro, A., Marris, L., Akerman, C
Lillicrap, T. P., Santoro, A., Marris, L., Akerman, C. J., andHinton, G.(2020).Backpropagationandthebrain. Nature Reviews Neuroscience, 21:335–346
work page 2020
-
[8]
Olshausen, B. A. and Field, D. J. (1996). Emergence of simple-cell receptive field properties by learning a sparse code for natural images.Nature, 381:607–609
work page 1996
-
[9]
Rao, R. P. N. and Ballard, D. H. (1999). Predictive cod- ing in the visual cortex: a functional interpretation of some extra-classical receptive-field effects.Nature Neuroscience, 2:79–87
work page 1999
-
[10]
Saxe, A. M., Koh, P. W., Chen, Z., Bhand, M., Suresh, B., and Ng, A. Y. (2011). On random weights and unsupervised feature learning. InProceedings of the 28th International Conference on Machine Learning
work page 2011
-
[11]
DiCarlo, J. J. (2020). Brain-Score: Which artificial neural network for object recognition is most brain- like?bioRxiv
work page 2020
-
[12]
Truzzi, A. and Cusack, R. (2025). Neural responses in early visual cortex are well predicted by random- weight CNNs.bioRxiv
work page 2025
-
[13]
Whittington, J. C. R. and Bogacz, R. (2017). An approx- imation of the error backpropagation algorithm in a predictive coding network with local Hebbian synap- tic plasticity.Neural Computation, 29:1229–1262
work page 2017
-
[14]
Yamins, D. L. K. and DiCarlo, J. J. (2016). Using goal- drivendeeplearningmodelstounderstandsensorycor- tex.Nature Neuroscience, 19:356–365. 10
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.