Recognition: unknown
RespondeoQA: a Benchmark for Bilingual Latin-English Question Answering
Pith reviewed 2026-05-10 00:58 UTC · model grok-4.3
The pith
The first QA benchmark centered on Latin provides 7800 bilingual question-answer pairs from pedagogical sources to test language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present RespondeoQA as the first QA benchmark centered on Latin, containing approximately 7800 question-answer pairs extracted from pedagogical sources including exams, trivia, and textbooks. After automated extraction, cleaning, and manual review, the dataset includes diverse types such as knowledge-based, multihop reasoning, constrained translation, and mixed language pairs. Evaluation of large language models reveals poorer performance on skill-oriented questions, with some variation by model and question language.
What carries the argument
The RespondeoQA dataset, constructed via automated extraction followed by cleaning and manual review from Latin pedagogical materials, functions as the core mechanism for assessing bilingual QA and translation capabilities.
If this is right
- Models show weaker results on skill-based questions such as scansion and literary-device identification than on straightforward knowledge questions.
- Some models handle questions posed directly in Latin slightly better than English versions, while others vary more by task type.
- Reasoning-focused models provide only limited overall gains despite advantages on specific subtasks.
- The dataset creation process supplies a reusable method for building similar benchmarks for other low-resource or specialized languages.
Where Pith is reading between the lines
- The benchmark could support development of educational tools that assist with Latin reading and analysis in classroom settings.
- It may highlight how training data imbalances affect model handling of historical texts beyond the specific Latin domain.
- Researchers could extend the set by linking pairs to full source texts for deeper context-based evaluation.
- Similar extraction pipelines might apply to other ancient languages with surviving pedagogical materials.
- keywords
Load-bearing premise
The automated extraction followed by cleaning and manual review produces a high-quality, representative collection of Latin pedagogical questions without major selection biases or errors in the final pairs.
What would settle it
A random sample of the pairs showing high rates of factual errors, inaccurate translations, or questions outside typical pedagogical content would demonstrate that the dataset fails to provide a reliable test of model performance on Latin.
Figures




read the original abstract
We introduce a benchmark dataset for question answering and translation in bilingual Latin and English settings, containing about 7,800 question-answer pairs. The questions are drawn from Latin pedagogical sources, including exams, quizbowl-style trivia, and textbooks ranging from the 1800s to the present. After automated extraction, cleaning, and manual review, the dataset covers a diverse range of question types: knowledge- and skill-based, multihop reasoning, constrained translation, and mixed language pairs. To our knowledge, this is the first QA benchmark centered on Latin. As a case study, we evaluate three large language models -- LLaMa 3, Qwen QwQ, and OpenAI's o3-mini -- finding that all perform worse on skill-oriented questions. Although the reasoning models perform better on scansion and literary-device tasks, they offer limited improvement overall. QwQ performs slightly better on questions asked in Latin, but LLaMa3 and o3-mini are more task dependent. This dataset provides a new resource for assessing model capabilities in a specialized linguistic and cultural domain, and the creation process can be easily adapted for other languages. The dataset is available at: https://github.com/slanglab/RespondeoQA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RespondeoQA, a benchmark dataset of approximately 7,800 bilingual Latin-English question-answer pairs sourced from pedagogical materials including exams, quizbowl trivia, and textbooks spanning the 1800s to the present. The construction pipeline consists of automated extraction, cleaning, and manual review to produce pairs covering knowledge-based, skill-based, multihop reasoning, constrained translation, and mixed-language questions. As a case study, three LLMs (LLaMa 3, Qwen QwQ, and OpenAI o3-mini) are evaluated, with the finding that all models perform worse on skill-oriented questions, reasoning models show limited gains on scansion and literary devices, and performance varies by question language. The dataset is released publicly on GitHub, and the pipeline is presented as adaptable to other languages. The work positions itself as the first Latin-centered QA benchmark.
Significance. If the dataset quality and representativeness hold, this provides a valuable new resource for evaluating LLMs on a classical language with complex morphology and limited digital resources, addressing a clear gap in multilingual QA benchmarks. The open release of the 7,800-pair dataset and the described creation process are explicit strengths that support reproducibility and extension to other low-resource languages. The case study offers initial insights into model limitations on skill-based Latin tasks, though its evidentiary weight depends on the completeness of the reported metrics.
major comments (2)
- [Dataset Construction] Dataset Construction section: The description of automated extraction followed by manual review does not report quantitative details such as the total number of candidate pairs initially extracted, the fraction discarded or edited during review, or any measure of inter-annotator agreement; without these, the claim that the final collection is high-quality and free of major selection biases cannot be fully assessed.
- [Evaluation Case Study] Evaluation Case Study: The abstract and results state that 'all perform worse on skill-oriented questions' and that reasoning models offer 'limited improvement overall,' yet no table or section provides per-category accuracy scores, error breakdowns, or statistical comparisons across the three models and question types; this omission limits verification of the performance claims that constitute the empirical contribution.
minor comments (3)
- [Abstract] Abstract: The model name 'Qwen QwQ' should be clarified (e.g., exact variant or version) for reproducibility, as it appears inconsistently with standard naming.
- [Introduction] Introduction or Dataset section: Provide at least one concrete example of each major question type (knowledge-based, multihop, constrained translation) to illustrate the diversity claimed.
- [Conclusion] The GitHub link is given, but the manuscript should include a brief description of the repository contents (e.g., file formats, splits) to aid immediate use.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation for minor revision. We address each major comment below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Dataset Construction] Dataset Construction section: The description of automated extraction followed by manual review does not report quantitative details such as the total number of candidate pairs initially extracted, the fraction discarded or edited during review, or any measure of inter-annotator agreement; without these, the claim that the final collection is high-quality and free of major selection biases cannot be fully assessed.
Authors: We agree that additional quantitative details on the construction pipeline would allow readers to better evaluate dataset quality and potential biases. In the revised manuscript, we will expand the Dataset Construction section to report the total number of candidate pairs initially extracted from the pedagogical sources, the numbers and fractions discarded or edited during automated cleaning and manual review, and clarify that the manual review was performed by the authors with consensus resolution on ambiguous items rather than independent annotators, making formal inter-annotator agreement inapplicable. These additions will directly address the concern while preserving the reproducibility of the described process. revision: yes
-
Referee: [Evaluation Case Study] Evaluation Case Study: The abstract and results state that 'all perform worse on skill-oriented questions' and that reasoning models offer 'limited improvement overall,' yet no table or section provides per-category accuracy scores, error breakdowns, or statistical comparisons across the three models and question types; this omission limits verification of the performance claims that constitute the empirical contribution.
Authors: We acknowledge that the current results presentation summarizes key findings without the granular breakdowns needed for full verification. In the revised manuscript, we will add a dedicated table in the Evaluation Case Study section reporting per-category accuracy scores (knowledge-based, skill-based, multihop reasoning, constrained translation, and mixed-language) for LLaMa 3, Qwen QwQ, and OpenAI o3-mini. We will also include representative error examples and basic statistical comparisons to support the claims regarding worse performance on skill-oriented questions and the limited gains from reasoning models. revision: yes
Circularity Check
No significant circularity; empirical dataset curation only
full rationale
The paper introduces a new QA benchmark dataset for Latin-English bilingual settings by describing its collection from pedagogical sources, automated extraction, cleaning, manual review, and subsequent LLM evaluation. No mathematical derivations, fitted parameters, predictions, uniqueness theorems, or self-citations appear as load-bearing elements in the provided abstract or described pipeline. The central claim (first Latin-centered QA benchmark) rests on the empirical construction process itself rather than any reduction to prior inputs or self-referential steps. This is a standard resource-creation paper with no internal circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
RespondeoQA: a Benchmark for Bilingual Latin-English Question Answering
Introduction In recent years, large language models (LLMs) have shown impressive abilities across a wide range of natural language understanding and gen- eration tasks. Yet their performance on many lan- guages,includinghistoricaloneslikeLatin,remains underexplored. Latin occupies a unique position compared to other languages: it is no longer spo- ken, bu...
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[2]
insight into the realtime com- prehension of Latin
Related Work Question answering is a staple of Latin learning, though one which recent research suggests the field can benefit from “insight into the realtime com- prehension of Latin” (Bextermöller, 2018, pg. 298; see also Kuehnast et al., 2024). Outside the class- room, Latin students have long enjoyed question answering of a different kind, that is “qu...
2018
-
[3]
When looking for potential sources of data, we aimed for a diversity of question types, both in terms of format and content
Data Sources We construct our dataset from four sources, includ- ingtwotextbooks,onesetofmultiplechoiceexams, and one set of quizbowl-style trivia questions (Ta- ble 1). When looking for potential sources of data, we aimed for a diversity of question types, both in terms of format and content. Certamen is a quizbowl-style trivia game played competitively ...
2025
-
[4]
put into Latin
Method: Dataset Curation Duringeachstepofourdatacurationpipeline, ifwe used a language model for cleanup or annotation, we performed manual review and intervention of its output. OCRWe obtained PDF scans of textbooks and their answer keys from Google Books, and PDFs of the National Latin Exams (NLE) and keys from the NLE website. For Certamen, we accessed...
1996
-
[5]
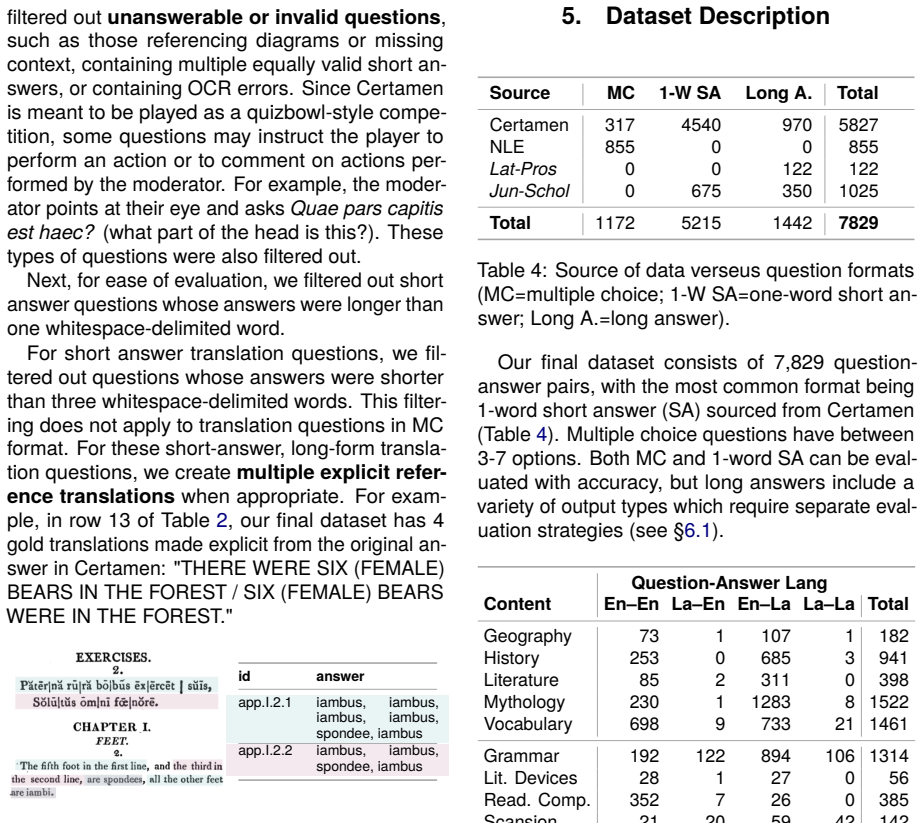
Dataset Description Source MC 1-W SA Long A. Total Certamen 317 4540 970 5827 NLE 855 0 0 855 Lat-Pros 0 0 122 122 Jun-Schol 0 675 350 1025 Total 1172 5215 1442 7829 Table 4: Source of data verseus question formats (MC=multiple choice; 1-W SA=one-word short an- swer; Long A.=long answer). Our final dataset consists of 7,829 question- answer pairs, with th...
-
[6]
feet identifi- cation
Experiments To illustrate the utility of our dataset to benchmark LLMs, we propose with a set of prompts and evalu- ation metrics, applied to three current LLMs. 6.1. Experimental Setup ModelsWe evaluate two open-source LLMs— LLaMa 3.3 (Grattafiori et al., 2024) and Qwen QwQ (Qwen Team et al., 2025; Qwen Team, 2025)— and one commercial model, OpenAI’s o3-...
2024
-
[7]
Considering the added computational cost, it is unnecessary to use reasoning models for most tasks we tested
Discussion and Future Work Reasoning abilities are beneficial for some skill- based tasks (scansion, literary devices) but are un- able to compensate for poorer foundational knowl- edge. Considering the added computational cost, it is unnecessary to use reasoning models for most tasks we tested. We also observed QwQ’s reason- ing ability sometimes prevent...
-
[8]
Ourevaluation of three large language models reveals that even strong general-purpose models struggle with skill- basedandlinguisticallyprecisetasks
Conclusion We present the first benchmark for QA and transla- tion in mixed Latin–English settings, built from over 7000 questions spanning two centuries of peda- gogical materials and capturing a wide spectrum of linguisticandreasoningchallenges. Ourevaluation of three large language models reveals that even strong general-purpose models struggle with sk...
-
[9]
At the time of writing, we do not plan to redis- tribute the portions of our dataset sourced from Certamen
Ethics Our dataset is derived from publicly available mate- rials, but some subsets are copyrighted and have distinct terms of use and access. At the time of writing, we do not plan to redis- tribute the portions of our dataset sourced from Certamen. The Junior Classical League (JCL) has agreed to host the Certamen portion of our dataset on its website al...
-
[10]
However, the performance of the tested models still has room for improvement
Limitations ItispossiblethatourquestionsexistinLLMpretrain- ing data. However, the performance of the tested models still has room for improvement. Even if our data was seen by the models during training, it is also unlikely to have seen answers aligned to the questions. Some combinations of question types, content, and languages are sparsely represented ...
-
[11]
This material is based in part upon work supported by National Science Foundation award 1845576 (CAREER)
Acknowledgments We would like to thank the UMass NLP group for their feedback and commentary on this project. This material is based in part upon work supported by National Science Foundation award 1845576 (CAREER). Any opinions, findings and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect ...
-
[12]
Bibliographical References ACL/NJCL. 2024. About Us. National Latin Exam website. Suzanne Adema. 2019. Latin learning and instruc- tion as a research field.Journal of Latin Linguis- tics, 18(1-2):35–59. Mikel Artetxe, Sebastian Ruder, and Dani Yo- gatama.2020.Onthecross-lingualtransferability of monolingual representations. InProceedings of the 58th Annua...
-
[13]
InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9540–9561, Abu Dhabi, United Arab Emirates
DEMETR: Diagnosing evaluation met- rics for translation. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9540–9561, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics. Milena Kuehnast, Konstantin Schulz, and Anke Lüdeling. 2024. Development of basic reading skills in Latin.Cogent educ...
2022
-
[14]
Common Corpus: The Largest Collection of Ethical Data for LLM Pre-Training
Common Corpus: The Largest Col- lection of Ethical Data for LLM Pre-Training. ArXiv:2506.01732 [cs]. Jürgen Leonhardt. 2013.Latin: Story of a World Language. Harvard University Press. Patrick Lewis, Barlas Oguz, Ruty Rinott, Sebastian Riedel, and Holger Schwenk. 2020. MLQA: Eval- uating cross-lingual extractive question answer- ing. InProceedings of the 5...
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[15]
InProceedings of LT4HALA 2020 - 1st Workshop on Language Technologies for Historical and Ancient Lan- guages, pages 94–99, Marseille, France
Latin-Spanish neural machine translation: from the Bible to saint augustine. InProceedings of LT4HALA 2020 - 1st Workshop on Language Technologies for Historical and Ancient Lan- guages, pages 94–99, Marseille, France. Euro- pean Language Resources Association (ELRA). Vaibhav Mavi, Anubhav Jangra, and Adam Jatowt
2020
-
[16]
Multi-hop question answering.Found. Trends Inf. Retr., 17(5):457–586. Assel Mukanova, Alibek Barlybayev, Aizhan Nazy- rova, Lyazzat Kussepova, Bakhyt Matkarimov, and Gulnazym Abdikalyk. 2024. Development of a Geographical Question- Answering System in theKazakhLanguage.IEEEAccess,12:105460– 105469. OpenAI. 2023. GPT-4 Technical Report. ArXiv:2303.08774 [c...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
InProceedingsofthe61stAnnual MeetingoftheAssociationforComputationalLin- guistics (Volume 1: Long Papers), pages 15181– 15199, Toronto, Canada
Exploring large language models for clas- sicalphilology. InProceedingsofthe61stAnnual MeetingoftheAssociationforComputationalLin- guistics (Volume 1: Long Papers), pages 15181– 15199, Toronto, Canada. Association for Com- putational Linguistics. Pedro Rodriguez, Shi Feng, Mohit Iyyer, He He, and Jordan Boyd-Graber. 2021. Quizbowl: The case for incrementa...
2021
-
[18]
Thea Sommerschield, Yannis Assael, John Pavlopoulos, Vanessa Stefanak, Andrew Senior, Chris Dyer, John Bodel, Jonathan Prag, Ion An- droutsopoulos, and Nando de Freitas
Universitätsverlag Kiel, Kiel. Thea Sommerschield, Yannis Assael, John Pavlopoulos, Vanessa Stefanak, Andrew Senior, Chris Dyer, John Bodel, Jonathan Prag, Ion An- droutsopoulos, and Nando de Freitas. 2023. Ma- chineLearningforAncientLanguages: ASurvey. Computational Linguistics, pages 1–45. Yixuan Tang, Hwee Tou Ng, and Anthony Tung
2023
-
[19]
Association for Com- putational Linguistics
Do multi-hop question answering sys- tems know how to answer the single-hop sub- questions? InProceedings of the 16th Confer- ence of the European Chapter of the Associa- tion for Computational Linguistics: Main Volume, pages 3244–3249, Online. Association for Com- putational Linguistics. Klaudia Thellmann, Bernhard Stadler, Michael Fromm, Jasper Schulze ...
2024
-
[20]
InProceedings of the Third Workshop on Language Technologies for His- torical and Ancient Languages (LT4HALA) @ LREC-COLING-2024, pages 122–128, Torino, Italia
LLM-based machine translation and sum- marization for Latin. InProceedings of the Third Workshop on Language Technologies for His- torical and Ancient Languages (LT4HALA) @ LREC-COLING-2024, pages 122–128, Torino, Italia. ELRA and ICCL. Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziy...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.