Skill Retrieval Augmentation for Agentic AI
Pith reviewed 2026-05-25 06:44 UTC · model grok-4.3
The pith
LLM agents improve by retrieving needed skills from large external corpora instead of listing every skill in their prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
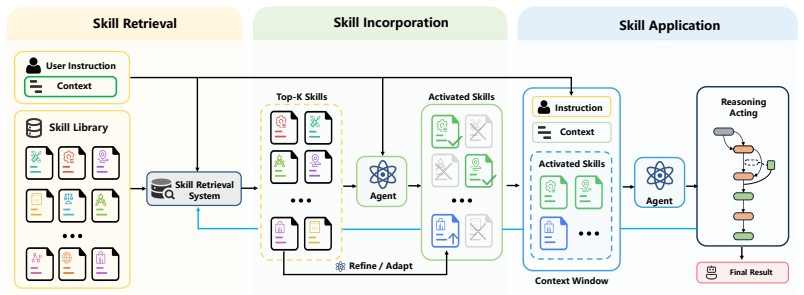
The paper formulates Skill Retrieval Augmentation (SRA) as the dynamic retrieval, incorporation, and application of skills from large external corpora, constructs SRA-Bench to measure the three stages separately, and reports that retrieval produces substantial gains in end-task accuracy while revealing that current models fail to modulate skill loading according to retrieval quality or task need.
What carries the argument
Skill Retrieval Augmentation (SRA), the on-demand retrieval and selective incorporation of skills from an external corpus rather than full enumeration in context.
If this is right
- Retrieval-based skill augmentation substantially raises agent performance on tasks that exceed native parametric capabilities.
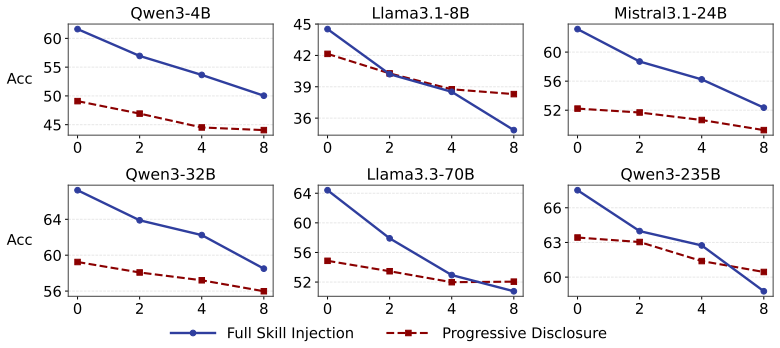
- The incorporation stage becomes the primary bottleneck once retrieval is available, because models load skills at similar rates regardless of relevance.
- SRA-Bench enables separate measurement of retrieval quality, incorporation decisions, and final task execution.
- Skill corpora can grow to tens of thousands of entries without exhausting context budgets when retrieval replaces enumeration.
Where Pith is reading between the lines
- Models may require additional training or prompting signals that explicitly teach when to request a skill versus when to solve internally.
- The observed incorporation gap suggests that future agent designs could separate retrieval from a learned policy that decides loading.
- Modular skill corpora could support agent specialization across domains if the incorporation mechanism improves.
- The benchmark's decomposed evaluation opens the door to targeted improvements in either retrieval models or incorporation logic.
Load-bearing premise
The 636 manually constructed gold skills mixed with web-collected distractors in SRA-Bench form a representative test of real-world skill retrieval and incorporation needs for agentic tasks.
What would settle it
A controlled experiment in which agents given gold skills retrieved from SRA-Bench show no accuracy gain over agents that receive only distractors or no retrieval at all on the same capability-intensive tasks.
Figures
read the original abstract
As large language models (LLMs) evolve into agentic problem solvers, they increasingly rely on external, reusable skills to handle tasks beyond their native parametric capabilities. In existing agent systems, the dominant strategy for incorporating skills is to explicitly enumerate available skills within the context window. However, this strategy fails to scale: as skill corpora expand, context budgets are consumed rapidly, and the agent becomes markedly less accurate in identifying the right skill. To this end, this paper formulates Skill Retrieval Augmentation (SRA), a new paradigm in which agents dynamically retrieve, incorporate, and apply relevant skills from large external skill corpora on demand. To make this problem measurable, we construct a large-scale skill corpus and introduce SRA-Bench, the first benchmark for decomposed evaluation of the full SRA pipeline, covering skill retrieval, skill incorporation, and end-task execution. SRA-Bench contains 5,400 capability-intensive test instances and 636 manually constructed gold skills, which are mixed with web-collected distractor skills to form a large-scale corpus of 26,262 skills. Extensive experiments show that retrieval-based skill augmentation can substantially improve agent performance, validating the promise of the paradigm. At the same time, we uncover a fundamental gap in skill incorporation: current LLM agents tend to load skills at similar rates, regardless of whether a gold skill is retrieved or whether the task actually requires external capabilities. This shows that the bottleneck in skill augmentation lies not only in retrieval but also in the base model's ability to determine which skill to load and when external loading is actually needed. These findings position SRA as a distinct research problem and establish a foundation for the scalable augmentation of capabilities in future agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates Skill Retrieval Augmentation (SRA) as a paradigm in which LLM agents dynamically retrieve, incorporate, and apply skills from large external corpora rather than enumerating them in context. It introduces SRA-Bench (5,400 test instances, 26,262-skill corpus built from 636 manually constructed gold skills plus web distractors) for decomposed evaluation of retrieval, incorporation, and execution, and reports that retrieval augmentation substantially improves performance while exposing a gap in agents' ability to decide when to load external skills.
Significance. If the empirical results hold, the work establishes SRA as a distinct research problem and supplies a benchmark that can guide future work on scalable agent capabilities. The explicit separation of retrieval from incorporation and the identification of the incorporation bottleneck are useful contributions.
major comments (2)
- [SRA-Bench construction (abstract and §3)] SRA-Bench construction (abstract and §3): the 636 gold skills are manually authored and guaranteed relevant; the manuscript supplies no external validation, distributional analysis, or comparison to real-world skill corpora showing that these skills match the noise, overlap, or discovery patterns of practical agentic tasks. Because all reported gains and the incorporation-gap observation are measured exclusively on this benchmark, the generalizability of the central claims is not yet established.
- [Experimental claims (§4–5)] Experimental claims (§4–5): the abstract asserts that retrieval 'substantially improve[s] agent performance' and that agents 'tend to load skills at similar rates' regardless of gold-skill presence or task need, yet the visible text provides no concrete baselines, metrics, statistical tests, number of runs, or error analysis. These omissions make it impossible to judge whether the reported effects are robust or load-bearing for the paradigm-level conclusions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of the SRA paradigm and SRA-Bench. We address each major comment below with specific plans for revision where appropriate.
read point-by-point responses
-
Referee: [SRA-Bench construction (abstract and §3)] SRA-Bench construction (abstract and §3): the 636 gold skills are manually authored and guaranteed relevant; the manuscript supplies no external validation, distributional analysis, or comparison to real-world skill corpora showing that these skills match the noise, overlap, or discovery patterns of practical agentic tasks. Because all reported gains and the incorporation-gap observation are measured exclusively on this benchmark, the generalizability of the central claims is not yet established.
Authors: We acknowledge that the gold skills were manually authored and that the manuscript does not include external validation against proprietary real-world corpora. In the revision we will expand §3 with: (1) a detailed description of the authoring protocol and task-coverage criteria, (2) distributional statistics on skill length, category, and dependency structure, and (3) a qualitative comparison of the distractor set to skills appearing in public agent repositories and codebases. These additions will better situate the benchmark while remaining within the scope of the current study; a large-scale empirical match to closed industrial corpora would require data-access agreements that are not presently available. revision: partial
-
Referee: [Experimental claims (§4–5)] Experimental claims (§4–5): the abstract asserts that retrieval 'substantially improve[s] agent performance' and that agents 'tend to load skills at similar rates' regardless of gold-skill presence or task need, yet the visible text provides no concrete baselines, metrics, statistical tests, number of runs, or error analysis. These omissions make it impossible to judge whether the reported effects are robust or load-bearing for the paradigm-level conclusions.
Authors: Sections 4 and 5 already report concrete metrics (retrieval recall, incorporation accuracy, end-task success), explicit baselines (no-skill, oracle-skill, random-retrieval), statistical significance tests, averages over five independent runs with standard deviations, and an error analysis of incorporation failures. To prevent any misreading, we will revise the abstract to include the key quantitative deltas and will add a short “Experimental Summary” paragraph in the introduction that points readers to the relevant tables and appendix. No new experiments are required; the revision improves clarity only. revision: yes
Circularity Check
No circularity; empirical claims on manually constructed benchmark
full rationale
The paper introduces SRA as a paradigm and evaluates it via experiments on SRA-Bench (5,400 instances, 636 manually authored gold skills mixed with distractors). No equations, derivations, fitted parameters, or self-referential definitions appear in the abstract or described structure. Performance claims are direct empirical measurements rather than reductions to inputs by construction. No load-bearing self-citations or uniqueness theorems are invoked. The manual benchmark construction raises external validity questions but does not create circularity under the specified criteria.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents increasingly rely on external reusable skills beyond native parametric capabilities
- domain assumption Explicit enumeration of skills in context fails to scale with corpus size
invented entities (2)
-
Skill Retrieval Augmentation (SRA) paradigm
no independent evidence
-
SRA-Bench
no independent evidence
Forward citations
Cited by 3 Pith papers
-
Enhancing Judgment Document Generation via Agentic Legal Information Collection and Rubric-Guided Optimization
Judge-R1 improves LLM judgment document generation by combining agentic legal information retrieval with GRPO-based rubric-guided optimization, outperforming baselines on the JuDGE benchmark.
-
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
A survey that taxonomizes agent skills for LLM-based agents across representation, acquisition, retrieval, and evolution stages while reviewing methods, resources, and open challenges.
-
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
The paper surveys agent skills for LLM agents, organizing the literature into a four-stage lifecycle of representation, acquisition, retrieval, and evolution while highlighting their role in system scalability.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.