Unison: Harmonizing Motion, Speech, and Sound for Human-Centric Audio-Video Generation
Pith reviewed 2026-06-30 23:25 UTC · model grok-4.3
The pith
Unison framework uses semantic-guided audio harmonization and bidirectional cross-modal forcing to align motion, speech, and environmental sound in generated videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
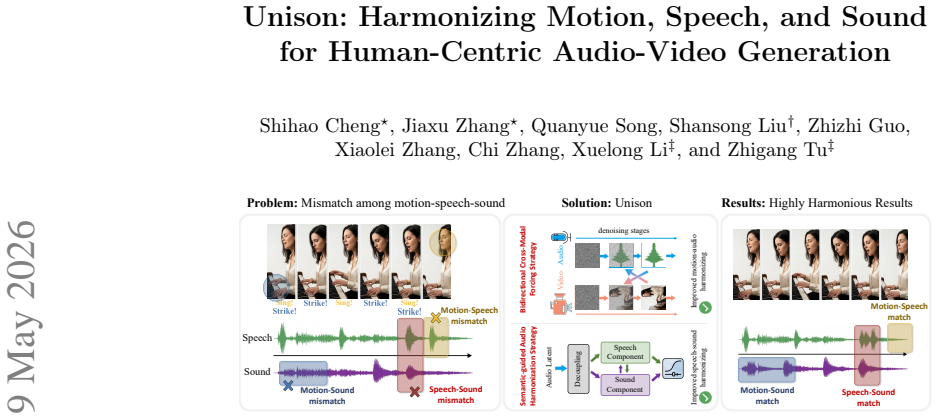
Unison achieves state-of-the-art performance in both audio perceptual quality and cross-modal synchronization by employing a semantic-guided harmonization strategy within the audio stream that decouples the generation of speech and sound-effect components, leveraging bidirectional audio cross-attention and semantic-conditioned gating for semantic-driven adaptive recomposition, and by proposing a bidirectional cross-modal forcing strategy for audio-motion synchronization where the cleaner modality guides the noisier one through decoupled denoising schedules reinforced by a progressive stabilization strategy.
What carries the argument
Semantic-guided harmonization strategy that decouples speech and sound via bidirectional audio cross-attention and semantic-conditioned gating, together with bidirectional cross-modal forcing that uses decoupled denoising schedules to let cleaner modalities guide noisier ones.
If this is right
- Audio perceptual quality improves because speech no longer dominates mixed soundtracks.
- Cross-modal synchronization improves because cleaner signals guide noisier ones during denoising.
- Explicit multimodal harmonization becomes necessary for consistent human-centric video output.
- Decoupled denoising schedules reduce drift between motion and audio tracks.
Where Pith is reading between the lines
- The same decoupling idea could be tested on longer video clips to check whether stabilization holds over time.
- Applying the forcing mechanism to text-conditioned generation might reduce mismatches between captions and visuals.
- The approach leaves open whether similar guidance rules would help in non-human scenes such as nature documentaries.
Load-bearing premise
The semantic-guided harmonization and bidirectional forcing strategies will produce coherent outputs across modalities without introducing new mismatches or requiring dataset-specific tuning beyond what is described.
What would settle it
Side-by-side comparison of Unison-generated videos against baselines on a held-out set, measuring whether lip-speech alignment errors or action-sound timing offsets increase rather than decrease.
Figures








read the original abstract
Motion, speech, and sound effects are fundamental elements of human-centric videos, yet their heterogeneous temporal characteristics make joint generation highly challenging. Existing audio-video generation models often fail to maintain consistent alignment across these modalities, leading to noticeable mismatches between motion, speech, and environmental sounds. We present Unison, a unified framework that explicitly promotes coherence across the motion, speech, and sound modalities. Within the audio stream, Unison employs a semantic-guided harmonization strategy that decouples the generation of speech and sound-effect components. Leveraging bidirectional audio cross-attention and semantic-conditioned gating for semantic-driven adaptive recomposition, this approach effectively mitigates speech dominance and enhances acoustic clarity. For audio-motion synchronization, we propose a bidirectional cross-modal forcing strategy where the cleaner modality guides the noisier one through decoupled denoising schedules, reinforced by a progressive stabilization strategy. Extensive experiments demonstrate that Unison achieves state-of-the-art performance in both audio perceptual quality and cross-modal synchronization, highlighting the importance of explicit multimodal harmonization in human-centric video generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Unison, a unified framework for human-centric audio-video generation that jointly produces motion, speech, and sound effects. It introduces a semantic-guided harmonization strategy within the audio stream that decouples speech and sound-effect generation via bidirectional audio cross-attention and semantic-conditioned gating, and a bidirectional cross-modal forcing strategy that uses decoupled denoising schedules plus progressive stabilization to align audio with motion. The central claim is that these explicit harmonization mechanisms yield state-of-the-art performance in audio perceptual quality and cross-modal synchronization.
Significance. If the empirical results hold, the explicit decoupling and bidirectional guidance mechanisms address a recognized limitation in existing multimodal generators where heterogeneous temporal characteristics lead to mismatches. The work provides concrete, implementable strategies that could be adopted or extended in subsequent audio-video synthesis research.
minor comments (3)
- Abstract: the claim of 'state-of-the-art performance' would be strengthened by naming the primary quantitative metrics (e.g., FAD, SyncNet score) and the number of baselines compared.
- The manuscript would benefit from a short pseudocode block or diagram illustrating the interaction between the semantic-conditioned gating and the bidirectional cross-attention layers.
- Section 5 (experiments): ensure that all reported numbers include standard deviations across multiple random seeds or runs.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the significance of the explicit decoupling and bidirectional guidance mechanisms, and the recommendation for minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity; empirical framework with independent mechanisms
full rationale
The paper introduces Unison as a unified framework employing semantic-guided harmonization (via bidirectional audio cross-attention and semantic-conditioned gating) and bidirectional cross-modal forcing (with decoupled denoising schedules and progressive stabilization). These are described as explicit strategies to address modality mismatches, with SOTA claims resting on extensive experiments rather than any derivation chain. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes smuggled via prior work appear in the text. The central claims are presented as empirical outcomes of the proposed architecture, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
DART: Difficulty-Adaptive Routing for Zero-Shot Video Temporal Grounding
DART routes zero-shot video temporal grounding queries by difficulty using DPP entropy, achieving up to 3.5 mIoU gains with 7x fewer frames on Charades-STA and ActivityNet Captions.
-
InteractiveAvatar: Real-Time Streaming Video Generation for Consistent and Intent-Aware Avatars
InteractiveAvatar uses autoregressive distillation, Long-Short Visual Memory, and a Reasoning-Reaction Module to enable real-time, consistent, intent-aware avatar video streaming.
-
InteractiveAvatar: Real-Time Streaming Video Generation for Consistent and Intent-Aware Avatars
InteractiveAvatar is a real-time infinite-streaming avatar video generation system using autoregressive distillation, Long-Short Visual Memory for consistency, and a Reasoning-Reaction Module for intent-aware interactions.
Reference graph
Works this paper leans on
-
[1]
YouTube-8M: A Large-Scale Video Classification Benchmark
Abu-El-Haija, S., Kothari, N., Lee, J., Natsev, A.P., Toderici, G., Varadarajan, B., Vijayanarasimhan, S.: Youtube-8m: A large-scale video classification benchmark. In: arXiv:1609.08675 (2016),https://arxiv.org/pdf/1609.08675v1.pdf
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [2]
- [3]
-
[4]
In: International Conference on Acoustics, Speech, and Signal Processing (ICASSP) (2020)
Chen, H., Xie, W., Vedaldi, A., Zisserman, A.: Vggsound: A large-scale audio-visual dataset. In: International Conference on Acoustics, Speech, and Signal Processing (ICASSP) (2020)
2020
-
[5]
In: CVPR (2025)
Cheng, H.K., Ishii, M., Hayakawa, A., Shibuya, T., Schwing, A., Mitsufuji, Y.: MMAudio: Taming multimodal joint training for high-quality video-to-audio syn- thesis. In: CVPR (2025)
2025
-
[6]
In: ICASSP 2023-2023 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP)
Elizalde, B., Deshmukh, S., Al Ismail, M., Wang, H.: Clap learning audio con- cepts from natural language supervision. In: ICASSP 2023-2023 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2023)
2023
-
[7]
In: Proc
Gemmeke, J.F., Ellis, D.P.W., Freedman, D., Jansen, A., Lawrence, W., Moore, R.C., Plakal, M., Ritter, M.: Audio set: An ontology and human-labeled dataset for audio events. In: Proc. IEEE ICASSP 2017. New Orleans, LA (2017)
2017
-
[8]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Girdhar, R., El-Nouby, A., Liu, Z., Singh, M., Alwala, K.V., Joulin, A., Misra, I.: Imagebind: One embedding space to bind them all. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 15180– 15190 (2023)
2023
-
[9]
Google DeepMind: Veo: A text-to-video generation system (2025),https:// storage.googleapis.com/deepmind-media/veo/Veo-3-Tech-Report.pdf
2025
-
[10]
HaCohen, Y., Brazowski, B., Chiprut, N., Bitterman, Y., Kvochko, A., Berkowitz, A., Shalem, D., Lifschitz, D., Moshe, D., Porat, E., Richardson, E., Shiran, G., Chachy, I., Chetboun, J., Finkelson, M., Kupchick, M., Zabari, N., Guetta, N., Kotler, N., Bibi, O., Gordon, O., Panet, P., Benita, R., Armon, S., Kulikov, V., Inger,Y.,Shiftan,Y.,Melumian,Z.,Farb...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
arXiv preprint arXiv:2511.21579 (2025)
Hu, T., Yu, Z., Zhang, G., Su, Z., Zhou, Z., Zhang, Y., Zhou, Y., Lu, Q., Yi, R.: Harmony: Harmonizing audio and video generation through cross-task synergy. arXiv preprint arXiv:2511.21579 (2025)
-
[12]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Huang, X., Li, Z., He, G., Zhou, M., Shechtman, E.: Self forcing: Bridging the train-test gap in autoregressive video diffusion (2025),https://arxiv.org/abs/ 2506.08009 16 S. Cheng et al
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
In: ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Iashin, V., Xie, W., Rahtu, E., Zisserman, A.: Synchformer: Efficient synchroniza- tion from sparse cues. In: ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 5325–5329. IEEE (2024)
2024
-
[14]
Vicinagearth1(1), 8 (2024)
Jiang, W., Zhang, Y., Zheng, S., Liu, S., Yan, S.: Data augmentation in human- centric vision. Vicinagearth1(1), 8 (2024)
2024
- [15]
-
[16]
Li, X., Wang, S., Zeng, S., et al.: A survey on llm-based multi-agent systems: workflow, infrastructure, and challenges. Vicinagearth1(9) (2024).https://doi. org/10.1007/s44336-024-00009-2
-
[17]
Li, X.: Positive-incentive noise. IEEE Transactions on Neural Networks and Learn- ing Systems35(6), 8708–8714 (2024).https://doi.org/10.1109/TNNLS.2022. 3224577
-
[18]
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling (2023),https://arxiv.org/abs/2210.02747
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [19]
-
[20]
Liu, K., Li, W., Chen, L., Wu, S., Zheng, Y., Ji, J., Zhou, F., Jiang, R., Luo, J., Fei, H., et al.: Javisdit: Joint audio-video diffusion transformer with hierarchical spatio-temporal prior synchronization. arXiv preprint arXiv:2503.23377 (2025)
-
[21]
Liu, K., Hu, W., Xu, J., Shan, Y., Lu, S.: Rolling forcing: Autoregressive long video diffusion in real time (2025),https://arxiv.org/abs/2509.25161
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Ovi: Twin Backbone Cross-Modal Fusion for Audio-Video Generation
Low, C., Wang, W., Katyal, C.: Ovi: Twin backbone cross-modal fusion for audio- video generation. arXiv preprint arXiv:2510.01284 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
IEEE/ACM Transactions on Au- dio, Speech, and Language Processing pp
Mei, X., Meng, C., Liu, H., Kong, Q., Ko, T., Zhao, C., Plumbley, M.D., Zou, Y., Wang, W.: WavCaps: A ChatGPT-assisted weakly-labelled audio captioning dataset for audio-language multimodal research. IEEE/ACM Transactions on Au- dio, Speech, and Language Processing pp. 1–15 (2024)
2024
-
[24]
OpenAI: Sora 2 system card (2025),https://cdn.openai.com/pdf/50d5973c- c4ff-4c2d-986f-c72b5d0ff069/sora_2_system_card.pdf
2025
-
[25]
In: Proceedings of the 28th ACM International Conference on Multimedia
Prajwal, K.R., Mukhopadhyay, R., Namboodiri, V.P., Jawahar, C.: A lip sync expert is all you need for speech to lip generation in the wild. In: Proceedings of the 28th ACM International Conference on Multimedia. p. 484–492. MM ’20, ACM (Oct 2020).https://doi.org/10.1145/3394171.3413532,http://dx.doi.org/ 10.1145/3394171.3413532
-
[26]
In: International conference on machine learning
Radford,A.,Kim,J.W.,Xu,T.,Brockman,G.,McLeavey,C.,Sutskever,I.:Robust speech recognition via large-scale weak supervision. In: International conference on machine learning. pp. 28492–28518. PMLR (2023)
2023
-
[27]
In: CVPR (2023)
Ruan, L., Ma, Y., Yang, H., He, H., Liu, B., Fu, J., Yuan, N.J., Jin, Q., Guo, B.: Mm-diffusion: Learning multi-modal diffusion models for joint audio and video generation. In: CVPR (2023)
2023
-
[28]
Advances in neural information processing systems35, 25278–25294 (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022)
2022
-
[29]
Vicinagearth2(9) (2025).https://doi.org/10.1007/ s44336-025-00018-9 Abbreviated paper title 17
Shen, Y., Zhang, D.: A survey of language-guided video object segmentation: from referring to reasoning. Vicinagearth2(9) (2025).https://doi.org/10.1007/ s44336-025-00018-9 Abbreviated paper title 17
2025
-
[30]
Corresponding authors: Xie Chen and Xipeng Qiu
SII-OpenMOSS Team, Yu, D., Chen, M., Chen, Q., Luo, Q., Wu, Q., Cheng, Q., Li, R., Liang, T., Zhang, W., Tu, W., Peng, X., Gao, Y., Huo, Y., Zhu, Y., Luo, Y., Zhang, Y., Song, Y., Xu, Z., Zhang, Z., Yang, C., Chang, C., Zhou, C., Chen, H., Ma, H., Li, J., Tong, J., Liu, J., Chen, K., Li, S., Wang, S., Jiang, W., Fei, Z., Ning, Z., Li, C., Li, C., He, Z., ...
-
[31]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Song, K., Chen, B., Simchowitz, M., Du, Y., Tedrake, R., Sitzmann, V.: History- guided video diffusion (2025),https://arxiv.org/abs/2502.06764
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Team, O., Yu, D., Chen, M., Chen, Q., Luo, Q., Wu, Q., Cheng, Q., Li, R., Liang, T., Zhang, W., Tu, W., Peng, X., Gao, Y., Huo, Y., Zhu, Y., Luo, Y., Zhang, Y., Song, Y., Xu, Z., Zhang, Z., Yang, C., Chang, C., Zhou, C., Chen, H., Ma, H., Li, J., Tong, J., Liu, J., Chen, K., Li, S., Jiang, S., Wang, S., Jiang, W., Fei, Z., Ning, Z., Li, C., Li, C., He, Z....
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Con- ference
Tian, Z., Liu, Z., Yuan, R., Pan, J., Liu, Q., Tan, X., Chen, Q., Xue, W., Guo, Y.: Vidmuse: A simple video-to-music generation framework with long-short-term modeling. In: Proceedings of the Computer Vision and Pattern Recognition Con- ference. pp. 18782–18793 (2025)
2025
-
[35]
Audiobox: Unified audio generation with natural language prompts,
Vyas, A., Shi, B., Le, M., Tjandra, A., Wu, Y.C., Guo, B., Zhang, J., Zhang, X., Adkins, R., Ngan, W., et al.: Audiobox: Unified audio generation with natural language prompts. arXiv preprint arXiv:2312.15821 (2023)
-
[36]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Wang, D., Zuo, W., Li, A., Chen, L.H., Liao, X., Zhou, D., Yin, Z., Dai, X., Jiang, D., Yu, G.: Universe-1: Unified audio-video generation via stitching of experts. arXiv preprint arXiv:2509.06155 (2025)
- [38]
-
[39]
Wang, L.X.X., Zhang, H., Dong, C., Shan, Y.: Vfhq: A high-quality dataset and benchmark for video face super-resolution (2022),https://arxiv.org/abs/2205. 03409
2022
-
[40]
Advances in Neural Information Processing Systems37, 65618–65642 (2024)
Wang, W., Yang, Y.: Vidprom: A million-scale real prompt-gallery dataset for text- to-video diffusion models. Advances in Neural Information Processing Systems37, 65618–65642 (2024)
2024
-
[41]
In: CVPR (2023)
Yu, J., Zhu, H., Jiang, L., Loy, C.C., Cai, W., Wu, W.: CelebV-Text: A large-scale facial text-video dataset. In: CVPR (2023)
2023
-
[42]
Cheng et al
Yuan, R., Lin, H., Guo, S., Zhang, G., Pan, J., Zang, Y., Liu, H., Du, X., Du, X., Ye, Z., Zheng, T., Jiang, Z., Ma, Y., Liu, M., Yu, L., Tian, Z., Zhou, Z., Xue, L., Qu, X., Li, Y., Shen, T., Ma, Z., Wu, S., Zhan, J., Wang, C., Wang, Y., Zhou, X., Chi, X., Zhang, X., Yang, Z., Liang, Y., Wang, X., Liu, S., Mei, L., Li, P., Chen, Y., Lin, C., Chen, X., Xi...
2025
-
[43]
Yuan, R., Lin, H., Guo, S., Zhang, G., Pan, J., Zang, Y., Liu, H., Liang, Y., Ma, W., Du, X., Du, X., Ye, Z., Zheng, T., Jiang, Z., Ma, Y., Liu, M., Tian, Z., Zhou, Z., Xue, L., Qu, X., Li, Y., Wu, S., Shen, T., Ma, Z., Zhan, J., Wang, C., Wang, Y., Chi, X., Zhang, X., Yang, Z., Wang, X., Liu, S., Mei, L., Li, P., Wang, J., Yu, J., Pang, G., Li, X., Wang,...
-
[44]
arXiv preprint arXiv:2511.03334 (2025)
Zhang, G., Zhou, Z., Hu, T., Peng, Z., Zhang, Y., Chen, Y., Zhou, Y., Lu, Q., Wang, L.: Uniavgen: Unified audio and video generation with asymmetric cross- modal interactions. arXiv preprint arXiv:2511.03334 (2025)
-
[45]
Zhang, H., Huang, S., Guo, Y., Li, X.: Variational positive-incentive noise: How noise benefits models. IEEE Transactions on Pattern Analysis and Machine Intelli- gence47(9), 8313–8320 (2025).https://doi.org/10.1109/TPAMI.2025.3575295
-
[46]
arXiv preprint arXiv:2412.16563 (2024)
Zhang, X., Li, J., Zhang, J., Dang, Z., Ren, J., Bo, L., Tu, Z.: Semtalk: Holistic co-speech motion generation with frame-level semantic emphasis. arXiv preprint arXiv:2412.16563 (2024)
- [47]
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, Z., Li, L., Ding, Y., Fan, C.: Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3661–3670 (2021)
2021
- [49]
-
[50]
Zhu, H., Kang, W., Yao, Z., Guo, L., Kuang, F., Li, Z., Zhuang, W., Lin, L., Povey, D.: Zipvoice: Fast and high-quality zero-shot text-to-speech with flow matching. arXiv preprint arXiv:2506.13053 (2025)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.