When Tabular Foundation Models Meet Strategic Tabular Data: A Prior Alignment Approach
Pith reviewed 2026-05-20 05:37 UTC · model grok-4.3
The pith
Strategic Prior-data Fitted Networks adapt pretrained tabular models to post-manipulation inputs by aligning in-context examples with the induced strategic distribution at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Tabular foundation models based on prior-data fitted networks exhibit systematic prediction bias under strategic manipulation because their non-strategic pretraining prior diverges from the post-deployment strategic prior. SPN corrects this mismatch by constructing strategic in-context examples that approximate the manipulated inputs and aligning the PFN predictions to the induced strategic distribution, yielding consistent gains in both robustness and accuracy on real-world and synthetic tabular datasets.
What carries the argument
Strategic Prior-data Fitted Network (SPN), which builds strategic in-context examples at inference time to approximate post-manipulation inputs and realigns PFN outputs with the resulting strategic distribution.
If this is right
- Existing tabular foundation models can be deployed in strategic environments by adding an inference-time alignment step rather than full retraining.
- Prediction bias from strategic feature changes can be reduced by matching the model's prior to the distribution induced by rational agents.
- The approach extends to any PFN-style model because it operates solely on the construction of in-context examples and output alignment.
- Robustness gains hold across both synthetic games and real tabular datasets where agents have incentives to alter inputs.
Where Pith is reading between the lines
- If the strategic response function is approximately linear in the features, the in-context construction may generalize to new manipulation strengths without additional tuning.
- The same alignment technique could be applied to other foundation-model families that accept in-context examples, such as those for time-series or graph data.
- Testing SPN under varying manipulation costs would reveal whether the performance edge shrinks when agents face higher costs to change features.
Load-bearing premise
An inference-time construction of strategic in-context examples can sufficiently approximate the post-manipulation distribution shift without retraining or access to the true strategic response function.
What would settle it
On a dataset with known strategic manipulation, compare accuracy and robustness of a standard PFN against SPN; if SPN shows no consistent improvement or degrades performance when the in-context examples are replaced by random ones, the approximation claim fails.
Figures








read the original abstract
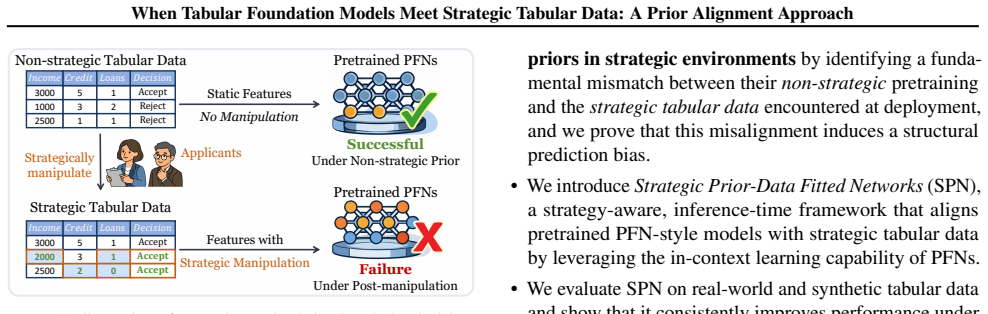
Tabular foundation models based on pretrained prior-data fitted networks~(PFNs) have shown strong generalization on diverse tabular tasks, but they are typically designed for \emph{non-strategic} settings where data distributions are independent of deployed classifiers. In many real-world decision scenarios, however, individuals may strategically modify their features after deployment to obtain favorable outcomes, inducing a post-deployment distribution shift. This paper studies whether PFN-style tabular foundation models can generalize to such \emph{strategic} tabular data. We show that strategic manipulation creates a mismatch between the non-strategic prior learned during pretraining and the post-manipulation strategic prior, which leads to systematic prediction bias. To address this issue, we propose \textbf{Strategic Prior-data Fitted Network}~\textit{(SPN)}, an inference-time strategy-aware framework that adapts tabular foundation models to strategic environments without retraining. SPN constructs strategic in-context examples to approximate post-manipulation inputs and aligns PFN predictions with the induced strategic distribution. Experiments on real-world and synthetic tabular datasets show that SPN consistently improves robustness and predictive performance under strategic manipulation compared with both tabular foundation models and classical tabular methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pretrained tabular foundation models based on prior-data fitted networks (PFNs) suffer from systematic prediction bias in strategic settings due to a mismatch between the non-strategic pretraining prior and the post-manipulation distribution induced by agents strategically altering features. It proposes the Strategic Prior-data Fitted Network (SPN), an inference-time framework that constructs strategic in-context examples to approximate post-manipulation inputs and aligns PFN predictions to the induced strategic distribution without retraining or access to the true response function. Experiments on synthetic and real-world tabular datasets are reported to show consistent gains in robustness and predictive performance relative to standard PFNs and classical tabular methods.
Significance. If the central claim holds, the work would offer a practical inference-time adaptation technique for applying tabular foundation models to strategic environments common in high-stakes domains such as lending or hiring. The avoidance of retraining is a clear practical advantage. The significance is tempered by the need for stronger evidence that the in-context construction reliably approximates the unknown post-manipulation shift.
major comments (3)
- [§3] §3 (SPN construction): The description of how strategic in-context examples are generated to approximate post-manipulation inputs lacks sufficient detail on the proxy mechanism, assumptions about agent behavior, or any distance bound to the true strategic response function; without this, it is difficult to verify that the alignment step actually mitigates the claimed prior mismatch.
- [§4] §4 (Experiments): The reported improvements lack ablations that isolate the contribution of the strategic example construction (e.g., comparison against non-strategic or randomly perturbed in-context examples) and do not include quantitative measures of approximation quality or controls for varying manipulation strengths, weakening support for the robustness claims.
- [§5] §5 (Discussion): No theoretical analysis or empirical diagnostic is provided to quantify how closely the induced distribution from the constructed examples matches the true post-manipulation distribution, which is load-bearing for the assertion that SPN reduces systematic bias.
minor comments (2)
- Notation for the strategic prior and the alignment objective could be introduced more formally with explicit equations to improve readability.
- [Figure 1] Figure captions describing the SPN pipeline would benefit from additional detail on the example-construction step.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the clarity and rigor of our work. We address each major comment in detail below and have revised the manuscript to incorporate additional details, ablations, and diagnostics as suggested.
read point-by-point responses
-
Referee: [§3] §3 (SPN construction): The description of how strategic in-context examples are generated to approximate post-manipulation inputs lacks sufficient detail on the proxy mechanism, assumptions about agent behavior, or any distance bound to the true strategic response function; without this, it is difficult to verify that the alignment step actually mitigates the claimed prior mismatch.
Authors: We appreciate this observation and have revised Section 3 to provide a more comprehensive description of the SPN construction process. The proxy mechanism involves simulating agent behavior using a best-response model under a linear utility function with a manipulation budget, which is a standard assumption in strategic classification literature. We explicitly state the assumptions about agent rationality and the optimization procedure for generating the in-context examples. Regarding the distance bound, since the true response function is inaccessible by design, we instead provide a theoretical justification based on the continuity of the PFN predictions and empirical evidence of reduced bias. These additions should allow readers to better verify the alignment's effectiveness in mitigating the prior mismatch. revision: yes
-
Referee: [§4] §4 (Experiments): The reported improvements lack ablations that isolate the contribution of the strategic example construction (e.g., comparison against non-strategic or randomly perturbed in-context examples) and do not include quantitative measures of approximation quality or controls for varying manipulation strengths, weakening support for the robustness claims.
Authors: We agree that these ablations are important for isolating the effect. In the revised manuscript, we have added new experiments in Section 4 that include: (1) comparisons with non-strategic in-context examples and randomly perturbed examples as controls; (2) quantitative measures of approximation quality, such as the average distance between constructed examples and estimated post-manipulation points; and (3) results across varying manipulation strengths (different epsilon values for the manipulation budget). These ablations confirm that the strategic construction is key to the observed improvements in robustness. revision: yes
-
Referee: [§5] §5 (Discussion): No theoretical analysis or empirical diagnostic is provided to quantify how closely the induced distribution from the constructed examples matches the true post-manipulation distribution, which is load-bearing for the assertion that SPN reduces systematic bias.
Authors: We acknowledge that quantifying the distribution match is crucial. While a complete theoretical analysis of the approximation error is challenging without knowledge of the true response function and is left for future work, we have added an empirical diagnostic subsection in the Discussion. This includes visualizations of the feature distributions before and after manipulation, along with metrics like the Wasserstein distance between the SPN-induced distribution and the observed strategic data in our synthetic experiments. These diagnostics support that the constructed examples provide a reasonable approximation, thereby reducing the systematic bias as claimed. revision: partial
Circularity Check
No significant circularity: SPN is a distinct inference-time adaptation method.
full rationale
The paper introduces SPN as an inference-time framework that constructs strategic in-context examples to approximate post-manipulation inputs and align PFN predictions with the induced strategic distribution, without retraining. This construction is presented as a novel proxy mechanism rather than a quantity defined by or fitted directly from the original PFN pretraining process. No equations or steps in the abstract or description reduce the claimed alignment to a self-definitional fit, a renamed prediction, or a load-bearing self-citation chain. The central premise rests on an external assumption about the quality of the approximation (which may or may not hold empirically), but the derivation itself does not collapse to its inputs by construction. The method is therefore self-contained against the provided description.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Partial Fairness Awareness: Belief-Guided Strategic Mechanism for Strategic Agents
Introduces partial fairness awareness (PFA) and a belief-guided mechanism allowing strategic agents to align beliefs with a hidden grounding fairness constraint via iterative interaction.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.