Neural Router: Semantic Content Matching for Agentic AI
Pith reviewed 2026-06-29 20:21 UTC · model grok-4.3
The pith
Large language models can serve as the semantic-matching engine of a content-based publish/subscribe broker for agentic AI across the edge-cloud computing continuum.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
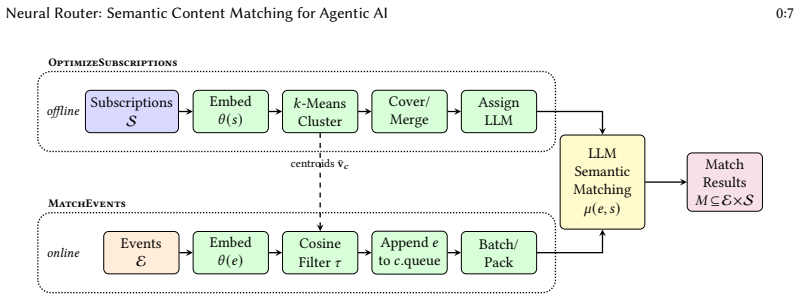
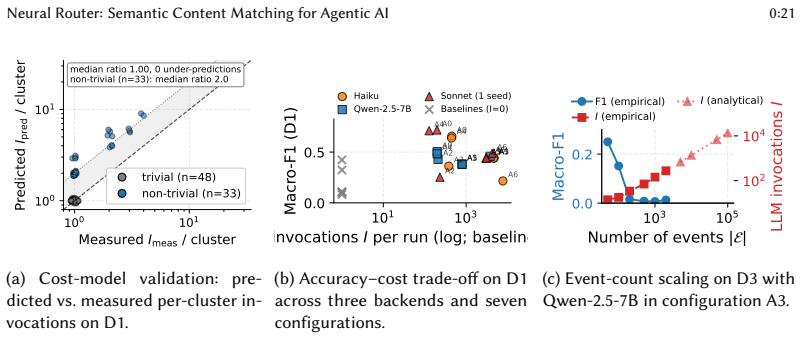
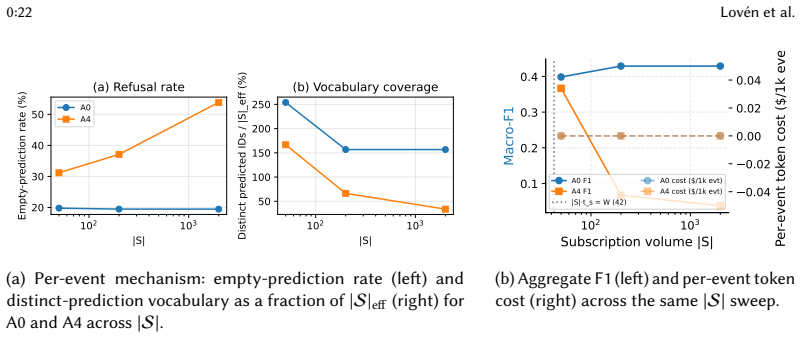
LLMs serve as the semantic-matching engine of a content-based publish/subscribe broker for agentic AI across the edge-cloud computing continuum, bridging the vocabulary and modality gaps that defeat keyword and embedding filters. The work characterises performance via an analytical context-window crossover below which a CoverAndMerge compression pipeline reduces LLM invocations and an empirical discrimination-capacity crossover above which matching accuracy collapses independently of context budget by a model-dependent factor of parameter count and training generation.
What carries the argument
The two-crossover cost-accuracy characterisation, which analytically locates the context window where compression lowers invocations and empirically locates the discrimination capacity limit set by model scale and training generation.
If this is right
- Above the discrimination crossover, compression cannot recover accuracy and only frontier-scale models can clear large subscription sets.
- Backend choice dominates configuration choice, so model selection is the primary operator lever.
- Three composable algorithms and a per-cluster Quality-of-Experience framework support autonomic LLM-tier selection.
Where Pith is reading between the lines
- The routing mechanism could extend semantic matching to live, multi-modal agent interactions that cross edge and cloud boundaries.
- Improvements in smaller models may shift the discrimination crossover and widen the set of usable backends.
- The offline characterisation supplies a baseline for designing online adaptation layers in production agentic systems.
Load-bearing premise
The three public datasets spanning social-media, legal, and smart-home sensor domains sufficiently represent the content-matching workloads that will arise in deployed agentic AI systems across the edge-cloud continuum.
What would settle it
Running the multi-label retrieval evaluations on content drawn from actual deployed agentic AI applications operating across edge and cloud environments to check whether the identified crossovers and model-dependent accuracy patterns persist.
Figures
read the original abstract
Large language models (LLMs) can serve as the semantic-matching engine of a content-based publish/subscribe broker for agentic AI across the edge-cloud computing continuum, bridging the vocabulary and modality gaps that defeat keyword and embedding filters. Framed as offline multi-label retrieval over three public datasets spanning social-media, legal, and smart-home sensor domains (six LLMs, seven baselines), our central contribution is a two-crossover cost-accuracy characterisation: an analytical context-window crossover below which a CoverAndMerge compression pipeline reduces LLM invocations, and an empirical discrimination-capacity crossover above which matching accuracy collapses independently of context budget, by a model-dependent factor of parameter count and training generation. Two findings carry practical weight: above the discrimination crossover, compression cannot recover accuracy and only frontier-scale models clear large subscription sets; and there backend choice dominates configuration choice, so model selection, not pipeline tuning, is the primary operator lever. We accompany this with three composable algorithms and a per-cluster Quality-of-Experience framework for autonomic LLM-tier selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that large language models can function as the semantic-matching component in a content-based publish/subscribe broker tailored for agentic AI systems operating across the edge-cloud computing continuum. Through offline multi-label retrieval experiments on three public datasets (social media, legal, and smart-home sensor domains) involving six LLMs and seven baselines, the authors identify two key crossovers: an analytical context-window crossover enabling a CoverAndMerge compression pipeline to reduce LLM invocations, and an empirical discrimination-capacity crossover beyond which matching accuracy declines independently of context budget, depending on model parameters and training generation. Key practical findings include that above the discrimination crossover, compression fails to restore accuracy and only frontier-scale models can handle large subscription sets, with backend choice outweighing configuration choices; the work also introduces three composable algorithms and a Quality-of-Experience framework for autonomic LLM-tier selection.
Significance. If the empirical crossovers and dominance findings generalize, this work offers valuable guidance for deploying LLM-based semantic matching in distributed agentic AI systems, highlighting the primacy of model selection over pipeline tuning. The provision of composable algorithms and the QoE framework for tier selection adds practical utility. The multi-model, multi-baseline evaluation strengthens the empirical basis.
major comments (2)
- [§4 Evaluation] The central claims regarding the transferability of the context-window and discrimination-capacity crossovers to agentic AI pub/sub workloads rest on the three public datasets. However, these datasets consist of static offline multi-label retrieval tasks and do not capture dynamic subscription sets, evolving agent-specific vocabularies, real-time multi-modal streams, or latency constraints characteristic of the edge-cloud continuum, raising questions about whether the reported findings are artifacts of the chosen corpora.
- [§5 Results] The assertion that 'backend choice dominates configuration choice' and the recommendation for frontier-scale models on large subscription sets are based solely on the performance observed in the social-media, legal, and smart-home domains. The manuscript would benefit from additional analysis or experiments demonstrating robustness to workloads more representative of deployed agentic systems.
minor comments (1)
- [Abstract] The abstract mentions 'six LLMs, seven baselines' but does not name them; including the specific models and baselines would improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the deliberate scope of our offline evaluation while acknowledging its limitations.
read point-by-point responses
-
Referee: [§4 Evaluation] The central claims regarding the transferability of the context-window and discrimination-capacity crossovers to agentic AI pub/sub workloads rest on the three public datasets. However, these datasets consist of static offline multi-label retrieval tasks and do not capture dynamic subscription sets, evolving agent-specific vocabularies, real-time multi-modal streams, or latency constraints characteristic of the edge-cloud continuum, raising questions about whether the reported findings are artifacts of the chosen corpora.
Authors: Our experiments are explicitly designed as controlled offline multi-label retrieval to isolate the analytical context-window crossover (derived from token budgets and independent of workload dynamics) and the empirical discrimination-capacity crossover (a model-intrinsic property of parameter count and training generation). The manuscript frames the contribution as a characterization of the semantic-matching engine rather than a full end-to-end dynamic pub/sub simulation; the three domains were chosen to span representative content types. We agree that dynamic subscription evolution, multi-modal streams, and latency are not modeled and that online validation would strengthen transferability claims, but these lie outside the current scope. No revision is required as the offline framing is stated throughout. revision: no
-
Referee: [§5 Results] The assertion that 'backend choice dominates configuration choice' and the recommendation for frontier-scale models on large subscription sets are based solely on the performance observed in the social-media, legal, and smart-home domains. The manuscript would benefit from additional analysis or experiments demonstrating robustness to workloads more representative of deployed agentic systems.
Authors: The dominance finding holds consistently across the three domains, which differ in vocabulary density, subscription cardinality, and content formality. This cross-domain consistency supports the conclusion that model selection is the primary lever. While we recognize that additional workloads (e.g., conversational or multi-modal agent traces) could test broader robustness, the present evidence across diverse static corpora is sufficient to ground the practical recommendation. We do not intend to add new experiments. revision: no
Circularity Check
No circularity; experimental results on public datasets
full rationale
The paper's central claims rest on offline multi-label retrieval experiments across three public datasets using six LLMs and seven baselines. The two crossovers are presented as one analytical (context-window) and one empirical (discrimination-capacity), derived from standard retrieval metrics and model comparisons rather than any self-defined parameters, fitted inputs renamed as predictions, or load-bearing self-citations. No equations or steps reduce the findings to inputs by construction; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Autonomic Federated-Market Orchestration for the Edge-Cloud Continuum
Neural Pub/Sub uses a MAPE-K loop with Walrasian price signals on service DAGs to achieve autonomic federated orchestration that matches centralized welfare under gross-substitutes assumptions and outperforms baseline...
Reference graph
Works this paper leans on
-
[1]
Ilias Chalkidis, Manos Fergadiotis, and Ion Androutsopoulos
Karlsruhe, Germany, 163–174. Ilias Chalkidis, Manos Fergadiotis, and Ion Androutsopoulos. 2021. MultiEURLEX – A multi-lingual and multi-label legal document classification dataset for zero-shot cross-lingual transfer. InProc. Conference on Empirical Methods in Natural Language Processing (EMNLP). 6974–6996. Diane J. Cook, Aaron S. Crandall, Brian L. Thoma...
-
[2]
doi:10.1007/11587552_13 Mingdong Li, Qifeng Luo, Lu Wang, Ruisheng Shi, and Jinqiao Shi
Springer, 249–269. doi:10.1007/11587552_13 Mingdong Li, Qifeng Luo, Lu Wang, Ruisheng Shi, and Jinqiao Shi. 2020. Privacy-preserving content-based publish/subscribe service based on order preserving encryption. InInternet of Vehicles. Technologies and Services Toward Smart Cities: 6th International Conference, IOV 2019, Kaohsiung, Taiwan, November 18–21, ...
-
[3]
Real-Time AI Service Economy: A Framework for Agentic Computing Across the Continuum.arXiv preprint arXiv:2603.05614(2026). Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I. Jordan, and Ion Stoica. 2018. Ray: A Distributed Framework for Emerging AI Applications...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.