Timestep-Aware SVDQuant-GPTQ for W4A4 Quantization of Wan2.2-I2V
Pith reviewed 2026-06-29 18:39 UTC · model grok-4.3
The pith
Timestep- and expert-aware calibration enables W4A4 quantization of MoE video DiTs with 59.3 percent memory reduction and under 1 percent quality drop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
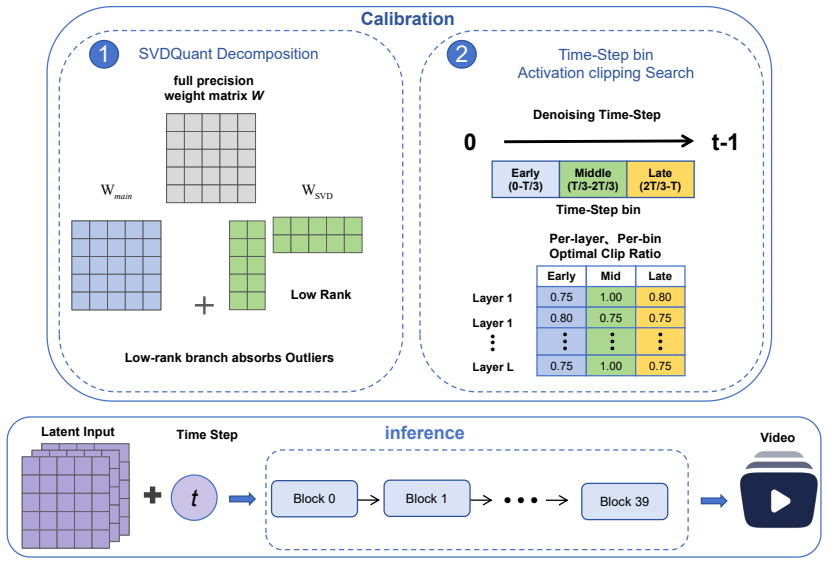
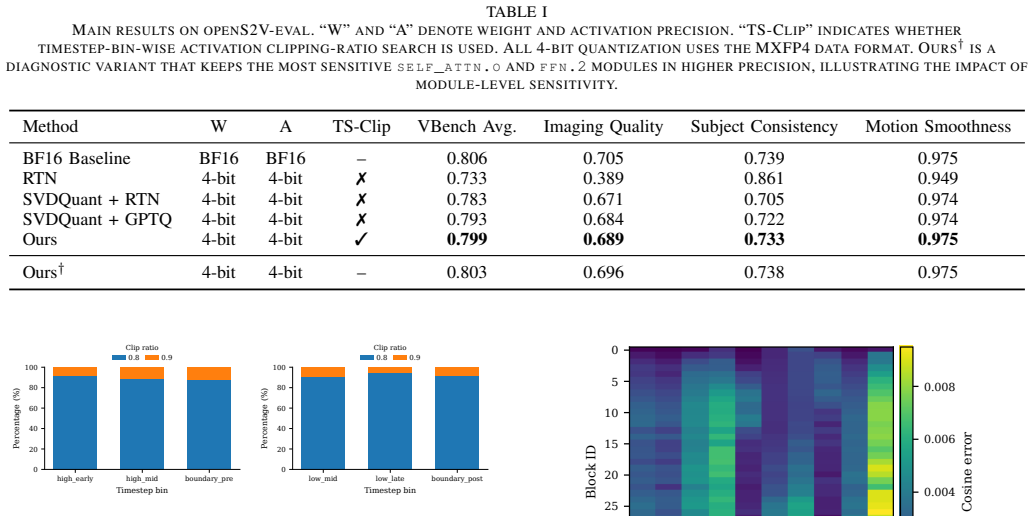
By combining SVDQuant-based low-rank outlier compensation with GPTQ-based residual weight quantization and timestep-bin-wise per-layer activation clipping-ratio search performed separately for the high-noise and low-noise experts, the approach enables W4A4 quantization of Wan2.2-I2V that reduces peak GPU memory by 59.3% relative to BF16 while limiting the drop to 0.9% in VBench average score and 2.3% in Imaging Quality on the OpenS2V-Eval benchmark.
What carries the argument
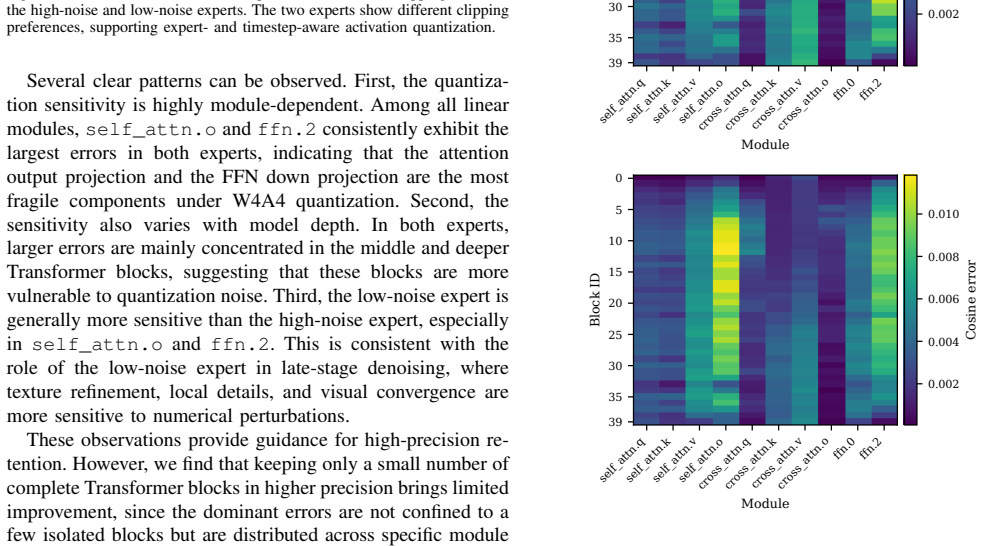
timestep-bin-wise per-expert activation clipping-ratio search within the SVDQuant-GPTQ framework that accounts for distinct sensitivities of high-noise and low-noise experts
If this is right
- Peak GPU memory usage for inference drops by 59.3% compared to the BF16 baseline.
- VBench average score drops by only 0.9% and Imaging Quality by 2.3%.
- Expert- and timestep-aware calibration proves essential for maintaining high fidelity in W4A4 inference on MoE video DiTs.
- Single global calibration policies fail to capture the quantization sensitivities across experts and denoising steps.
Where Pith is reading between the lines
- Similar per-expert timestep-aware strategies could apply to other mixture-of-experts models in generative tasks.
- Dynamic adjustment of clipping ratios during the denoising process might further improve results beyond static post-training calibration.
- Memory reductions of this scale could support higher-resolution or longer-duration video generation on hardware with limited VRAM.
Load-bearing premise
The distinct quantization sensitivities of the high-noise and low-noise experts cannot be adequately captured by any single global calibration policy, making independent per-expert timestep-bin searches both necessary and sufficient.
What would settle it
Demonstrating that a single global calibration policy without timestep or expert separation achieves equivalent or superior VBench and Imaging Quality scores on the same benchmark would falsify the necessity of the aware calibration.
Figures

read the original abstract
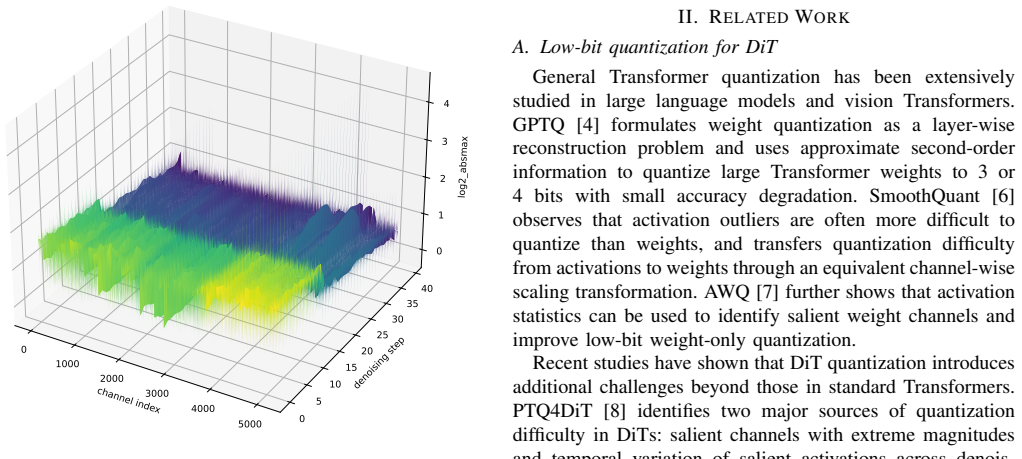
W4A4 quantization of large video diffusion Transformers offers substantial memory savings but is hindered by two main challenges: sparse large-magnitude activation outliers, and strongly timestep-dependent activation distributions across the multi-step denoising trajectory. These difficulties are compounded by Wan2.2-I2V's two-expert Mixture-of-Experts DiT design, whose high-noise and low-noise experts exhibit distinct quantization sensitivities that a single global calibration policy cannot capture. We propose a post-training quantization framework combining SVDQuant-based low-rank outlier compensation, GPTQ-based reconstruction-aware residual weight quantization, and timestep-bin-wise per-layer activation clipping-ratio search conducted independently for each expert. On the OpenS2V-Eval benchmark, our method reduces peak GPU memory by 59.3\% relative to the BF16 baseline while incurring only a 0.9\% drop in VBench average score and a 2.3\% drop in Imaging Quality, demonstrating that expert- and timestep-aware calibration is essential for high-fidelity W4A4 inference on MoE video DiTs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a post-training W4A4 quantization pipeline for the Wan2.2-I2V MoE video DiT that combines SVDQuant low-rank outlier compensation, GPTQ reconstruction-aware weight quantization, and independent timestep-bin-wise per-layer activation clipping-ratio search for each expert. On OpenS2V-Eval it reports a 59.3% reduction in peak GPU memory relative to BF16 with 0.9% and 2.3% drops in VBench average and Imaging Quality, respectively, and concludes that expert- and timestep-aware calibration is essential.
Significance. If the necessity of the expert/timestep-aware component is demonstrated, the work would provide a practical route to memory-efficient inference of large MoE video diffusion models; the empirical memory and quality numbers on an external benchmark are the primary contribution.
major comments (2)
- [Abstract] Abstract: the central claim that 'expert- and timestep-aware calibration is essential' is unsupported because the manuscript reports performance only versus the BF16 baseline and supplies no quantitative comparison against an otherwise identical SVDQuant+GPTQ pipeline that uses a single global calibration policy across experts and timestep bins. Without this ablation the contribution of the awareness mechanism cannot be isolated from the low-rank compensation and weight quantization.
- [Abstract] Abstract: no error bars, ablation studies, or verification that the per-expert clipping-ratio search avoids overfitting to OpenS2V-Eval are provided, so the reported 0.9%/2.3% metric drops cannot be assessed for statistical reliability or generalization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger evidence isolating the contribution of expert- and timestep-aware calibration. We address each major comment below and commit to revisions that will strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'expert- and timestep-aware calibration is essential' is unsupported because the manuscript reports performance only versus the BF16 baseline and supplies no quantitative comparison against an otherwise identical SVDQuant+GPTQ pipeline that uses a single global calibration policy across experts and timestep bins. Without this ablation the contribution of the awareness mechanism cannot be isolated from the low-rank compensation and weight quantization.
Authors: We agree that a direct ablation against an otherwise identical SVDQuant+GPTQ pipeline with a single global calibration policy is required to isolate the contribution of the expert- and timestep-aware components. The manuscript motivates the need via observed differences in activation distributions between the high-noise and low-noise experts (Section 3.2), but does not provide the requested quantitative comparison. We will add this ablation study, reporting VBench and Imaging Quality for the global-policy baseline versus our per-expert/timestep-bin policy, in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: no error bars, ablation studies, or verification that the per-expert clipping-ratio search avoids overfitting to OpenS2V-Eval are provided, so the reported 0.9%/2.3% metric drops cannot be assessed for statistical reliability or generalization.
Authors: We acknowledge the absence of error bars and explicit verification against overfitting in the current version. The clipping-ratio search is performed on a held-out calibration subset distinct from OpenS2V-Eval, but we agree this should be stated explicitly with supporting ablations. In revision we will report results over multiple random seeds with error bars, include additional ablation studies on the calibration procedure, and verify generalization on a second benchmark to address statistical reliability and overfitting concerns. revision: yes
Circularity Check
No circularity; empirical results on external benchmark with no self-referential derivations
full rationale
The paper describes an empirical post-training quantization pipeline (SVDQuant + GPTQ + per-expert timestep-bin calibration) and reports measured memory reduction and quality drops versus a BF16 baseline on OpenS2V-Eval. No equations, fitted-parameter predictions, or self-citation chains are present that reduce the claimed outcome to its inputs by construction. The assertion that expert/timestep awareness is 'essential' is an interpretive claim resting on the single baseline comparison, not on any internal definitional loop or imported uniqueness theorem.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Holding the FP8 Quality Ceiling at 8-Bit Weights and Activations: INT8 and GGUF Post-Training Quantization of Ideogram 4.0 for Consumer GPUs
INT8 W8A8 post-training quantization of Ideogram 4.0 preserves FP8 quality on a 200-prompt benchmark while outperforming NF4 on CLIP score and offering a favorable quality-memory trade-off via GGUF Q4_K.
Reference graph
Works this paper leans on
-
[1]
Scalable diffusion models with transformers,
William Peebles and Saining Xie, “Scalable diffusion models with transformers,” inProc. of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 4195–4205
2023
-
[2]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, et al., “Wan: Open and advanced large-scale video generative models,”arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
SVDQuant: Absorbing outliers by low-rank components for 4-bit diffusion models,
Muyang Li, Yujun Lin, Zhekai Zhang, Tianle Cai, Xiuyu Li, Junx- ian Guo, Enze Xie, Chenlin Meng, Jun-Yan Zhu, and Song Han, “SVDQuant: Absorbing outliers by low-rank components for 4-bit diffusion models,” inProc. of the 13th ICLR, 2025
2025
-
[4]
GPTQ: Accurate post-training quantization for generative pre-trained transformers,
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh, “GPTQ: Accurate post-training quantization for generative pre-trained transformers,” inProc. of the 11th ICLR, 2023
2023
-
[5]
Vbench: Comprehensive benchmark suite for video generative models,
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al., “Vbench: Comprehensive benchmark suite for video generative models,” inProc. of CVPR, 2024, pp. 21807–21818
2024
-
[6]
SmoothQuant: Accurate and efficient post-training quantization for large language models,
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han, “SmoothQuant: Accurate and efficient post-training quantization for large language models,” inProc. of the 11th ICLR, 2023
2023
-
[7]
AWQ: Activation-aware weight quantization for LLM compression and acceleration,
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han, “AWQ: Activation-aware weight quantization for LLM compression and acceleration,” inProc. of the 7th MLSys, 2024
2024
-
[8]
PTQ4DiT: Post-training quantization for diffusion transformers,
Junyi Wu, Haoxuan Wang, Yuzhang Shang, Mubarak Shah, and Yan Yan, “PTQ4DiT: Post-training quantization for diffusion transformers,” inAdvances in Neural Information Processing Systems, 2024
2024
-
[9]
Q-DiT: Accurate post-training quantization for diffusion transformers,
Lei Chen et al., “Q-DiT: Accurate post-training quantization for diffusion transformers,” inProc. of the IEEE/CVF (CVPR), 2025, pp. 28306–28315
2025
-
[10]
Tcaq-dm: timestep-channel adaptive quantization for diffusion models,
Haocheng Huang, Jiaxin Chen, Jinyang Guo, Ruiyi Zhan, and Yunhong Wang, “Tcaq-dm: timestep-channel adaptive quantization for diffusion models,” inProceedings of the 39th AAAI Conference on Artificial Intelligence, 2025, vol. 39, pp. 17404–17412
2025
-
[11]
ViDiT-Q: Efficient and accurate quantization of diffusion transformers for image and video generation,
Tianchen Zhao, Tongcheng Fang, Haofeng Huang, Rui Wan, Widyadewi Soedarmadji, Enshu Liu, Shiyao Li, Zinan Lin, Guohao Dai, Shengen Yan, Huazhong Yang, Xuefei Ning, and Yu Wang, “ViDiT-Q: Efficient and accurate quantization of diffusion transformers for image and video generation,” inProc. of the 13th ICLR, 2025
2025
-
[12]
Bridging the gap between promise and performance for microscaling fp4 quantization,
Vage Egiazarian, Roberto L Castro, Denis Kuznedelev, Andrei Panferov, Eldar Kurtic, Shubhra Pandit, Alexandre Marques, Mark Kurtz, Saleh Ashkboos, Torsten Hoefler, et al., “Bridging the gap between promise and performance for microscaling fp4 quantization,”arXiv preprint arXiv:2509.23202, 2025
-
[13]
Opens2v-nexus: A detailed benchmark and million-scale dataset for subject-to-video generation,
Shenghai Yuan, Xianyi He, Yufan Deng, Yang Ye, Jinfa Huang, Chongyang Ma, Jiebo Luo, Li Yuan, et al., “Opens2v-nexus: A detailed benchmark and million-scale dataset for subject-to-video generation,” Advances in Neural Information Processing Systems, vol. 38, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.