Constructive interpolation and generalization rates for neural ODEs: a control perspective
Pith reviewed 2026-06-28 18:42 UTC · model grok-4.3
The pith
SA-NODEs exactly interpolate admissible datasets and recover histogram generalization rates via simultaneous cell controllability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
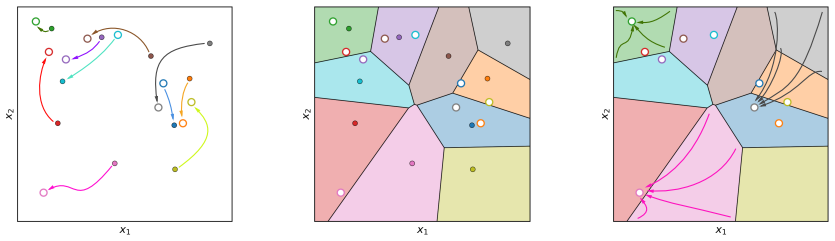
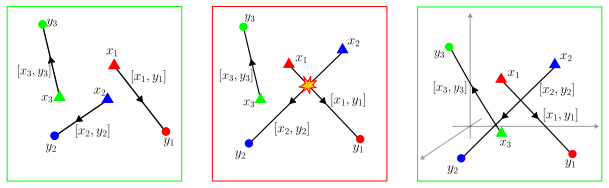
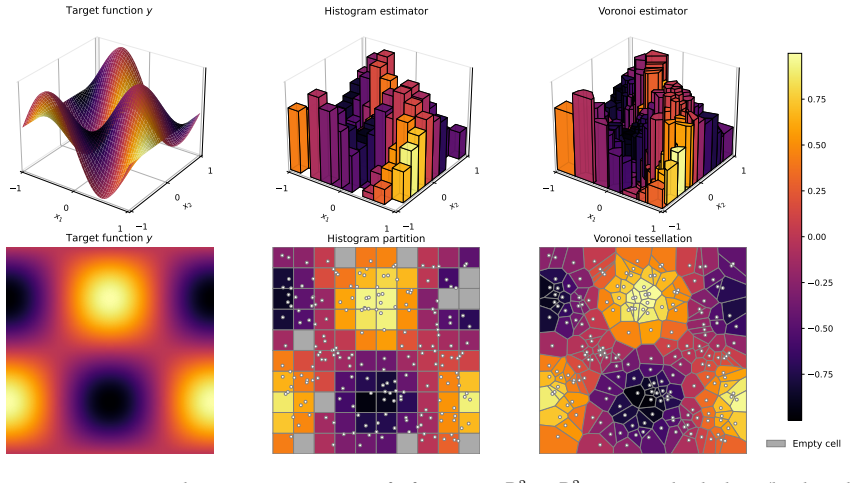
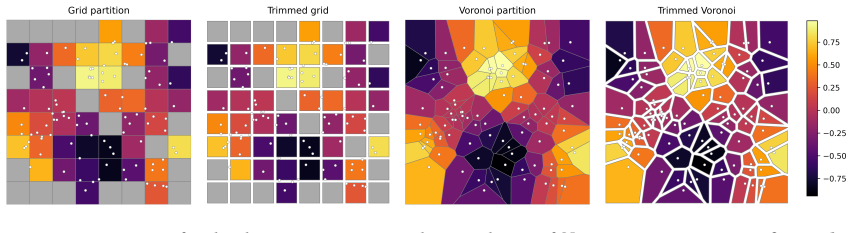
SA-NODEs are capable of exact interpolation of admissible finite datasets and satisfy simultaneous cell controllability (SCC): their flows can map prescribed disjoint cells into arbitrarily small target balls. This property is the mechanism that upgrades interpolation into quantitative generalization by allowing SA-NODEs to emulate piecewise-constant nonparametric estimators and recover their risk bounds provided network width scales conservatively with the sample size. Explicit time dependence is essential; although two-layer autonomous NODEs can interpolate geometrically nondegenerate datasets, structural obstructions prevent them from achieving SCC.
What carries the argument
Simultaneous cell controllability (SCC): the property that the controlled flows map prescribed disjoint cells into arbitrarily small target balls, which directly enables emulation of piecewise-constant estimators.
If this is right
- SA-NODEs recover the generalization rates of histogram and nearest-neighbor estimators.
- Network width must scale conservatively with sample size to attain those rates.
- Trained SA-NODEs achieve competitive or lower test errors than the nonparametric baselines.
- Autonomous NODEs remain limited by structural obstructions to SCC even when they interpolate the data.
Where Pith is reading between the lines
- The SCC mechanism could be checked in other non-autonomous ODE families to identify minimal architectures for interpolation-plus-generalization tasks.
- Tighter width scaling might be possible by refining the cell-mapping construction beyond the conservative bound used here.
- The numerical confirmation that autonomous models fail SCC suggests testing whether added layers or different activations can overcome the obstructions.
Load-bearing premise
The input datasets must be admissible and the models must include explicit time dependence.
What would settle it
A concrete admissible dataset for which no SA-NODE flow achieves exact interpolation, or a numerical example in which an autonomous NODE flow maps disjoint cells to small balls on geometrically nondegenerate data.
Figures
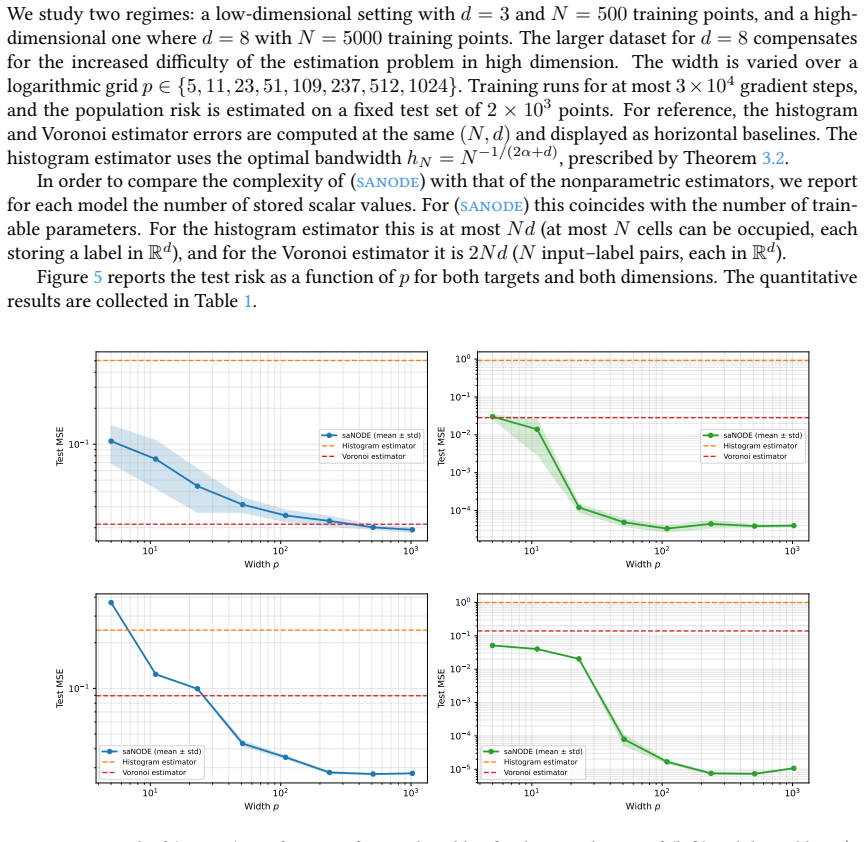

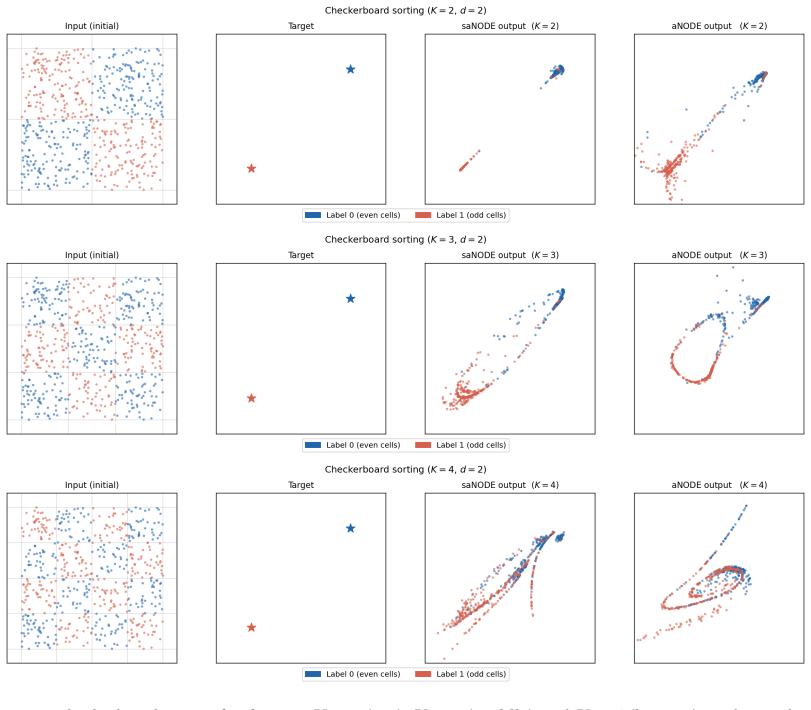
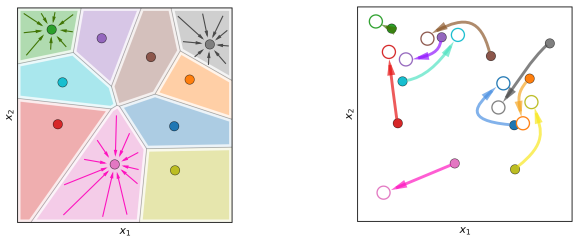
read the original abstract
We study supervised regression with neural ODEs (NODEs) from a control-theoretic perspective to derive explicit population-risk bounds. We focus on a widely used class of non-autonomous models with constant parameters and explicit time dependence, which we call semi-autonomous NODEs (SA-NODEs). We constructively prove that SA-NODEs are capable of \emph{exact} interpolation of admissible finite datasets, and even satisfy a stronger property that we call \emph{simultaneous cell controllability} (SCC): their flows can map prescribed disjoint cells into arbitrarily small target balls. This property is the mechanism that upgrades interpolation into quantitative generalization, by allowing SA-NODEs to emulate piecewise-constant nonparametric estimators. Consequently, our risk bounds recover the rates of histogram and nearest-neighbor estimators, provided the network width satisfies a conservative scaling with the sample size. Numerical experiments show that trained SA-NODEs achieve competitive -- often lower -- test errors than these baselines. Finally, we show that the explicit time dependence is essential. Although two-layer autonomous NODEs can interpolate geometrically nondegenerate datasets, structural obstructions prevent them from achieving SCC. These limitations, further confirmed numerically, support the view that SA-NODEs provide a minimal effective architecture for learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a control-theoretic analysis of semi-autonomous neural ODEs (SA-NODEs) for supervised regression. It provides a constructive proof that SA-NODEs exactly interpolate admissible finite datasets and satisfy simultaneous cell controllability (SCC), enabling emulation of piecewise-constant nonparametric estimators such as histograms and nearest neighbors. This yields population-risk bounds matching those estimators when network width scales conservatively with sample size. The paper further shows that explicit time dependence is essential, as autonomous NODEs, while able to interpolate geometrically nondegenerate data, cannot achieve SCC due to controllability obstructions.
Significance. If the constructive proofs and SCC property hold, the work supplies a rigorous mechanism linking interpolation to generalization rates in dynamical models, recovering standard nonparametric rates without parameter fitting. The explicit construction via time-dependent controls and the structural obstruction for autonomous models are strengths, as is the internal consistency of the control-theoretic framework with no evident circularity in the bounds.
minor comments (3)
- §3 (definition of admissible datasets): the precise regularity conditions on the data points and cells should be stated explicitly with an example to clarify the scope of the interpolation theorem.
- Numerical experiments section: the reported test errors would benefit from explicit comparison tables against the histogram and NN baselines with the same width scaling, including standard deviations over multiple runs.
- Notation for SCC: the definition in the main text could be cross-referenced more clearly to the controllability rank conditions used later for autonomous NODEs.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the manuscript, the recognition of the constructive proofs and the SCC property, and the recommendation of minor revision. No specific major comments were raised.
Circularity Check
No significant circularity; derivation self-contained via constructive control proof
full rationale
The paper's central claims rest on an explicit constructive proof (via time-dependent controls) that admissible datasets admit exact interpolation and simultaneous cell controllability for SA-NODEs. Generalization bounds then follow by direct emulation of external histogram and nearest-neighbor estimators whose rates are independently known; width scaling is stated explicitly as a conservative requirement. The obstruction for autonomous NODEs is derived from controllability rank conditions internal to the framework. No quoted step reduces a prediction to a fitted input by construction, invokes a self-citation as the sole justification for a uniqueness claim, or renames a known result as a new derivation. All load-bearing steps are therefore independent of the target bounds.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Datasets are admissible finite collections for which exact interpolation is possible
invented entities (1)
-
simultaneous cell controllability (SCC)
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Approximation and Controllability of Nonlinear Control-Affine Systems via Semiautonomous Neural Ordinary Differential Equations
Controlled SA-NODEs uniformly approximate trajectories of nonlinear controlled systems on compact sets and preserve approximate controllability, with error O(P^{-1/2} + Q^{-1/2}) under Sobolev and Barron regularity.
-
Turnpike and Sparse Optimal Control for Semiautonomous Neural ODEs
Proves exponential turnpike and one-sided sparsity for L1-regularized optimal control of SA-NODEs, confirmed numerically on oscillators with 30x parameter reduction.
Reference graph
Works this paper leans on
-
[1]
Agrachev and A
A. Agrachev and A. Sarychev. Control in the spaces of ensembles of points.SIAM Journal on Control and Optimization, 58(3):1579–1596, 2020
2020
-
[2]
Agrachev and A
A. Agrachev and A. Sarychev. Control on the manifolds of mappings with a view to the deep learning. Journal of Dynamical and Control Systems, 28(4):989–1008, 2022
2022
-
[3]
Álvarez-López, B
A. Álvarez-López, B. Geshkovski, and D. Ruiz-Balet. Constructive approximate transport maps with normalizing flows.Applied Mathematics & Optimization, 92(2):33, 2025
2025
-
[4]
Álvarez-López, R
A. Álvarez-López, R. Orive-Illera, and E. Zuazua. Cluster-based classification with neural ODEs via control.Journal of Machine Learning, 4(2):128–156, 2025
2025
-
[5]
Álvarez-López, A
A. Álvarez-López, A. H. Slimane, and E. Zuazua. Interplay between depth and width for interpolation in neural ODEs.Neural Networks, 180:106640, 2024
2024
-
[6]
Aurenhammer
F. Aurenhammer. Voronoi diagrams—a survey of a fundamental geometric data structure.ACM Computing Surveys, 23(3):345–405, 1991
1991
-
[7]
F. Bach. Breaking the curse of dimensionality with convex neural networks.Journal of Machine Learning Research, 18(19):1–53, 2017
2017
-
[8]
A. Barron. Universal approximation bounds for superpositions of a sigmoidal function.IEEE Trans- actions on Information Theory, 39(3):930–945, 1993
1993
-
[9]
P. L. Bartlett, P. M. Long, G. Lugosi, and A. Tsigler. Benign overfitting in linear regression.Proceedings of the National Academy of Sciences, 117(48):30063–30070, 2020
2020
-
[10]
Bauer, L
B. Bauer, L. Devroye, M. Kohler, A. Krzyżak, and H. Walk. Nonparametric estimation of a function from noiseless observations at random points.Journal of Multivariate Analysis, 160:93–104, 2017
2017
-
[11]
Belkin, D
M. Belkin, D. Hsu, S. Ma, and S. Mandal. Reconciling modern machine-learning practice and the classical bias–variance trade-off.Proceedings of the National Academy of Sciences, 116(32):15849– 15854, 2019
2019
-
[12]
Biau and L
G. Biau and L. Devroye.Lectures on the Nearest Neighbor Method. Springer Series in the Data Sciences. Springer, 2015
2015
-
[13]
Bleistein and A
L. Bleistein and A. Guilloux. On the generalization and approximation capacities of neural controlled differential equations. InInternational Conference on Learning Representations, 2024
2024
-
[14]
Celledoni, M
E. Celledoni, M. J. Ehrhardt, C. Etmann, R. I. McLachlan, B. Owren, C.-B. Schönlieb, and F. Sherry. Structure-preserving deep learning.European Journal of Applied Mathematics, 32(5):888–936, 2021
2021
-
[15]
R. T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. K. Duvenaud. Neural ordinary differential equa- tions. InAdvances in Neural Information Processing Systems, volume 31, pages 6572–6583, 2018
2018
-
[16]
Cheng, Q
J. Cheng, Q. Li, T. Lin, and Z. Shen. Interpolation, approximation, and controllability of deep neural networks.SIAM Journal on Control and Optimization, 63(1):625–649, 2025
2025
-
[17]
Cipriani, M
C. Cipriani, M. Fornasier, and A. Scagliotti. From neurodes to autoencodes: A mean-field control framework for width-varying neural networks.European Journal of Applied Mathematics, 2024. 34
2024
-
[18]
Cohen, W
A. Cohen, W. Dahmen, I. Daubechies, and R. DeVore. Tree approximation and optimal encoding. Applied and Computational Harmonic Analysis, 11(2):192–226, 2001
2001
-
[19]
Cuchiero, M
C. Cuchiero, M. Larsson, and J. Teichmann. Deep neural networks, generic universal interpolation, and controlled ODEs.SIAM J. Math. Data Sci., 2(3):901–919, 2020
2020
-
[20]
J. Q. Davis, K. Choromanski, J. Varley, H. Lee, J.-J. Slotine, V. Likhosterov, A. Weller, A. Makadia, and V. Sindhwani. Time dependence in non-autonomous neural odes, 2020. ICLR 2020 Workshop DeepDiffEq
2020
-
[21]
R. A. DeVore. Nonlinear approximation.Acta Numerica, 7:51–150, 1998
1998
-
[22]
Dupont, A
E. Dupont, A. Doucet, and Y. W. Teh. Augmented neural ODEs. InAdvances in Neural Information Processing Systems, pages 3140–3150, 2019
2019
-
[23]
Durrett.Probability
R. Durrett.Probability. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, 5 edition, 2019
2019
-
[24]
W. E. A proposal on machine learning via dynamical systems.Communications in Mathematics and Statistics, 5(1):1–11, 2017
2017
-
[25]
W. E, J. Han, and Q. Li. A mean-field optimal control formulation of deep learning.Research in the Mathematical Sciences, 6(1):10, 2018
2018
-
[26]
Elamvazhuthi, B
K. Elamvazhuthi, B. Gharesifard, A. L. Bertozzi, and S. Osher. Neural ode control for trajectory approximation of continuity equation.IEEE Control Systems Letters, 6:3152–3157, 2022
2022
-
[27]
Esteve, B
C. Esteve, B. Geshkovski, D. Pighin, and E. Zuazua. Large-time asymptotics in deep learning, 2020
2020
-
[28]
Geshkovski and D
B. Geshkovski and D. Ruiz-Balet. Constructive conditional normalizing flows, 2026
2026
-
[29]
Grathwohl, R
W. Grathwohl, R. T. Q. Chen, J. Bettencourt, I. Sutskever, and D. Duvenaud. FFJORD: Free-form con- tinuous dynamics for scalable reversible generative models. InInternational Conference on Learning Representations, 2019
2019
-
[30]
Györfi, M
L. Györfi, M. Kohler, A. Krzyżak, and H. Walk.A Distribution-Free Theory of Nonparametric Regres- sion. Springer Series in Statistics. Springer, 2002
2002
-
[31]
Haber and L
E. Haber and L. Ruthotto. Stable architectures for deep neural networks.Inverse Problems, 34(1):014004, 2018
2018
-
[32]
J. Jia, Z. Yang, M. Wang, K. Guo, J. Yang, X. Yu, and L. Guo. Feedback favors the generalization of Neural ODEs. InInternational Conference on Learning Representations, 2025
2025
-
[33]
Kidger, J
P. Kidger, J. Morrill, J. Foster, and T. Lyons. Neural controlled differential equations for irregular time series. InAdvances in Neural Information Processing Systems, volume 33, pages 6696–6707, 2020
2020
-
[34]
Klusowski and A
J. Klusowski and A. Barron. Approximation by combinations of relu and squared relu ridge functions with l1 and l0 controls.IEEE Transactions on Information Theory, 64(12):7649–7656, 2018
2018
-
[35]
LeCun, Y
Y. LeCun, Y. Bengio, and G. Hinton. Deep learning.Nature, 521:436–44, 2015
2015
-
[36]
Q. Li, L. Chen, C. Tai, and W. E. Maximum principle based algorithms for deep learning.Journal of Machine Learning Research, 18(165):1–29, 2018
2018
-
[37]
Q. Li, T. Lin, and Z. Shen. Deep learning via dynamical systems: An approximation perspective. Journal of the European Mathematical Society, 25(5):1671–1709, 2022
2022
-
[38]
Q. Li, T. Lin, and Z. Shen. Deep neural network approximation of invariant functions through dy- namical systems.Journal of Machine Learning Research, 25(278):1–57, 2024
2024
-
[39]
Z. Li, K. Liu, L. Liverani, and E. Zuazua. Universal approximation of dynamical systems by semiau- tonomous neural odes and applications.SIAM Journal on Numerical Analysis, 64:193–223, 2026. 35
2026
-
[40]
Y. Lu, A. Zhong, Q. Li, and B. Dong. Beyond finite layer neural networks: Bridging deep architec- tures and numerical differential equations. InProceedings of the International Conference on Machine Learning, ICML’18, pages 3282–3291, 2018
2018
-
[41]
P. Marion. Generalization Bounds for Neural Ordinary Differential Equations and Deep Residual Networks. InAdvances in Neural Information Processing Systems, volume 36, pages 48918–48938, 2023
2023
-
[42]
Marzouk, Z
Y. Marzouk, Z. Ren, S. Wang, and J. Zech. Distribution learning via neural differential equations: A nonparametric statistical perspective.Journal of Machine Learning Research, 25(232):1–61, 2024
2024
-
[43]
Massaroli, M
S. Massaroli, M. Poli, J. Park, A. Yamashita, and H. Asama. Dissecting neural ODEs. InAdvances in Neural Information Processing Systems, volume 33, pages 3952–3963, 2020
2020
-
[44]
E. A. Nadaraya. On estimating regression.Theory of Probability and its Applications, 9(1):141–142, 1964
1964
-
[45]
Pinkus.n-Widths in Approximation Theory, volume 7 ofErgebnisse der Mathematik und ihrer Grenzgebiete (3)
A. Pinkus.n-Widths in Approximation Theory, volume 7 ofErgebnisse der Mathematik und ihrer Grenzgebiete (3). Springer, Berlin, Heidelberg, 1985
1985
-
[46]
Reznikov and E
A. Reznikov and E. B. Saff. The covering radius of randomly distributed points on a manifold.Inter- national Mathematics Research Notices, 2016(19):6065–6094, 2016
2016
-
[47]
Rubanova, R
Y. Rubanova, R. T. Q. Chen, and D. K. Duvenaud. Latent ordinary differential equations for irregularly-sampled time series. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[48]
Ruiz-Balet, E
D. Ruiz-Balet, E. Affili, and E. Zuazua. Interpolation and approximation via momentum ResNets and neural ODEs.Systems & Control Letters, 162:105182, 2022
2022
-
[49]
Ruiz-Balet and E
D. Ruiz-Balet and E. Zuazua. Neural ODE Control for Classification, Approximation, and Transport. SIAM Review, 65(3):735–773, 2023
2023
-
[50]
Ruiz-Balet and E
D. Ruiz-Balet and E. Zuazua. Control of neural transport for normalising flows.Journal de Mathé- matiques Pures et Appliquées, 181:58–90, 2024
2024
-
[51]
Scagliotti
A. Scagliotti. Deep learning approximation of diffeomorphisms via linear-control systems.Mathe- matical Control and Related Fields, 13(3):1226–1257, 2023
2023
-
[52]
Scagliotti
A. Scagliotti. Minimax problems for ensembles of control-affine systems.SIAM Journal on Control and Optimization, 63(1):502–523, 2025
2025
-
[53]
Sontag and H
E. Sontag and H. Sussmann. Complete controllability of continuous-time recurrent neural networks. Systems & Control Letters, 30(4):177–183, 1997
1997
-
[54]
C. J. Stone. Optimal global rates of convergence for nonparametric regression.The annals of statistics, pages 1040–1053, 1982
1982
-
[55]
Tabuada and B
P. Tabuada and B. Gharesifard. Universal approximation power of deep residual neural networks through the lens of control.IEEE Transactions on Automatic Control, 68(5):2715–2728, 2023
2023
-
[56]
A. B. Tsybakov.Introduction to Nonparametric Estimation. Springer Publishing Company, Incorpo- rated, 1st edition, 2008
2008
-
[57]
V. N. Vapnik.Statistical Learning Theory. Wiley, New York, 1998
1998
-
[58]
Verma and M
M. Verma and M. Kumar. Analysis of generalization capacities of Neural Ordinary Differential Equa- tions.Transactions on Machine Learning Research, 2025
2025
-
[59]
G. S. Watson. Smooth regression analysis.Sankhy ¯a: The Indian Journal of Statistics, Series A, 26(4):359–372, 1964
1964
-
[60]
Zhang, S
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals. Understanding deep learning (still) requires rethinking generalization.Communications of the ACM, 64(3):107–115, 2021. 36
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.