PhotoCraft: Agentic Reasoning with Hierarchical Self-Evolving Memory for Deep Image Search
Pith reviewed 2026-06-28 10:25 UTC · model grok-4.3
The pith
A training-free hierarchical memory system equips MLLM agents with working, episodic, and semantic recall to sustain context across multi-step deep image searches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
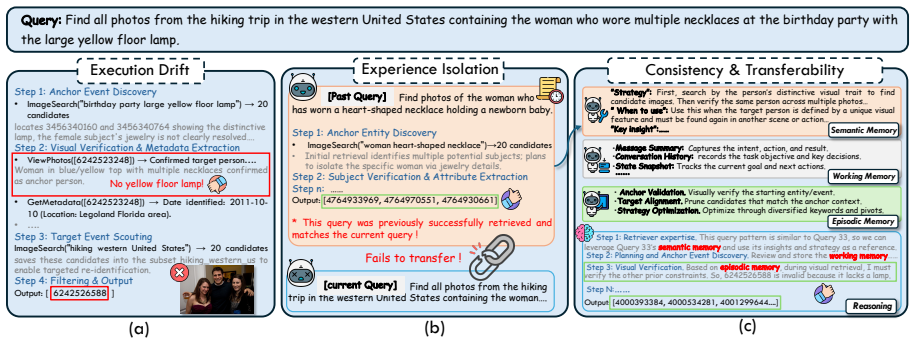
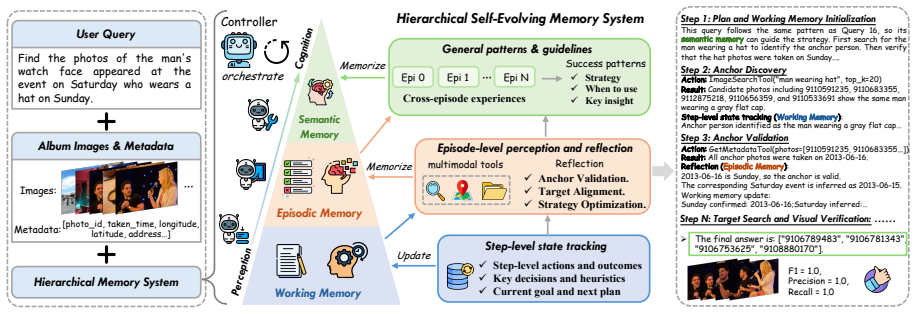
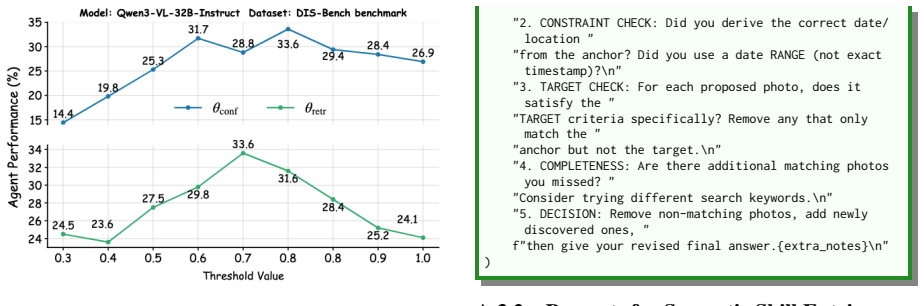
PhotoCraft is a training-free hierarchical memory system for photo-search agents that equips MLLMs with working, episodic, and semantic memory; these components are invoked dynamically during reasoning to preserve logical consistency and enable knowledge transferability, producing consistent gains of up to 18.5 percent in context-aware retrieval on DISBench.
What carries the argument
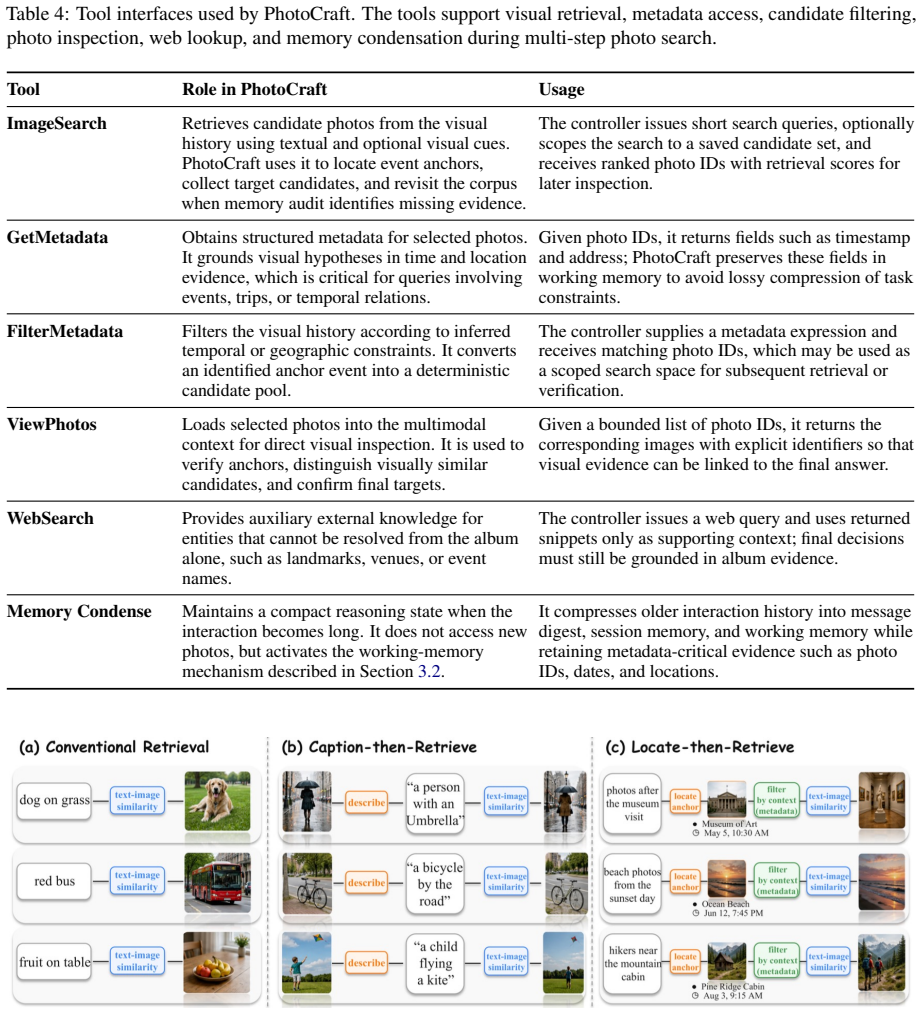
The hierarchical self-evolving memory consisting of working, episodic, and semantic components that are dynamically invoked during agentic reasoning.
If this is right
- Context-aware retrieval performance improves across diverse MLLM backbones.
- Execution drift decreases during long-horizon photo searches.
- Experience transfers more readily from one search task to another.
- Logical consistency is maintained through multi-step answer generation.
Where Pith is reading between the lines
- The same memory structure could be tested on agent tasks that involve sequences of images or video rather than single photos.
- Scalability could be checked by measuring how the dynamic invocation overhead grows with the number of reasoning steps.
- Because the method requires no training, it could be combined with existing MLLM tool-use pipelines with minimal engineering effort.
- The self-evolving property suggests the memory store might accumulate useful patterns across many unrelated user sessions.
Load-bearing premise
A training-free system that dynamically invokes working, episodic, and semantic memory components can preserve logical consistency and transfer knowledge in multi-step MLLM reasoning for image search.
What would settle it
If ablation tests on DISBench show that removing the hierarchical memory components produces retrieval accuracy equal to or higher than the full PhotoCraft system, the claim that the memory hierarchy drives the reported gains would be falsified.
Figures






read the original abstract
Deep Image Search requires multi-step reasoning over rich contextual cues, such as time, location, and event relations. However, most existing LLM-based agents are stateless and reactive, lacking persistent memory to maintain long-horizon context or transfer experience across tasks, which often leads to execution drift and experience isolation. To address these limitations, we propose PhotoCraft, a training-free, hierarchical memory system for photo-search agents. Inspired by human cognition, PhotoCraft equips MLLMs with working, episodic, and semantic memory, which are dynamically invoked during reasoning to preserve logical consistency and knowledge transferability throughout multi-step reasoning and answer generation. Extensive experiments on DISBench demonstrate that PhotoCraft consistently improves context-aware retrieval across diverse MLLM backbones, achieving gains of up to 18.5\% and effectively mitigating key bottlenecks in memoryless deep image search, offering a practical path toward reliable and generalizable multimodal search agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PhotoCraft, a training-free hierarchical self-evolving memory system for MLLM-based photo search agents. Inspired by human cognition, it incorporates working, episodic, and semantic memory components that are dynamically invoked during multi-step reasoning to maintain logical consistency and enable knowledge transfer across tasks. The central claim is an empirical one: this architecture improves context-aware retrieval on DISBench across diverse MLLM backbones, with gains of up to 18.5% while mitigating bottlenecks in memoryless agents.
Significance. If the reported gains are substantiated by rigorous experiments, the work offers a practical training-free method to address statelessness and execution drift in LLM agents for long-horizon multimodal tasks. This could advance reliable agentic systems in computer vision and multimodal reasoning by providing a cognitively motivated memory hierarchy applicable beyond image search.
major comments (2)
- [Abstract] Abstract: the central claim of up to 18.5% gains on DISBench is presented without any reference to baselines, specific MLLM backbones, evaluation metrics, number of trials, or error analysis, rendering the empirical result unevaluable from the provided text.
- [Method] Method description: the dynamic invocation rules for switching between working, episodic, and semantic memory lack algorithmic specification (e.g., decision criteria, update mechanisms, or pseudocode), which is load-bearing for claims of preserving logical consistency and transferability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and evaluability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of up to 18.5% gains on DISBench is presented without any reference to baselines, specific MLLM backbones, evaluation metrics, number of trials, or error analysis, rendering the empirical result unevaluable from the provided text.
Authors: We agree that the abstract should be more self-contained to allow immediate evaluation of the central empirical claim. The full paper reports results across multiple MLLM backbones (including GPT-4V and LLaVA variants), compares against memoryless baselines and ablations, uses context-aware retrieval accuracy on DISBench, and includes multi-trial statistics with variance. In the revision we will expand the abstract to explicitly reference the key baselines, backbones, metric, trial count, and note the presence of error analysis, while remaining within length limits. revision: yes
-
Referee: [Method] Method description: the dynamic invocation rules for switching between working, episodic, and semantic memory lack algorithmic specification (e.g., decision criteria, update mechanisms, or pseudocode), which is load-bearing for claims of preserving logical consistency and transferability.
Authors: We acknowledge that the current description of the invocation logic is primarily narrative and would benefit from explicit algorithmic detail. The manuscript explains the roles of the three memory types and their dynamic use during reasoning, but does not provide pseudocode or precise decision criteria for switching and updating. We will add a dedicated subsection with pseudocode, decision rules (e.g., context-length thresholds, relevance scoring), and update mechanisms to make the implementation reproducible and to strengthen the claims regarding consistency and transfer. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper advances an empirical architecture (training-free hierarchical memory with working/episodic/semantic components) whose central claim is performance improvement on DISBench (up to 18.5% across MLLM backbones). No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The argument rests on experimental results rather than any reduction of outputs to inputs by construction, making the derivation chain self-contained.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
CoLT: Teaching Multi-Modal Models to Think with Chain of Latent Thoughts
CoLT replaces text-based chain-of-thought in MLLMs with 3-step latent thought chains supervised by a removable external decoder in forward and backward modes, yielding 10.1x faster inference on eight benchmarks.
Reference graph
Works this paper leans on
-
[1]
Zouying Cao, Jiaji Deng, Li Yu, Weikang Zhou, Zhaoyang Liu, Bolin Ding, and Hai Zhao
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631. Zouying Cao, Jiaji Deng, Li Yu, Weikang Zhou, Zhaoyang Liu, Bolin Ding, and Hai Zhao. 2025. Re- member me, refine me: A dynamic procedural mem- ory framework for experience-driven agent evolution. arXiv preprint arXiv:2512.10696. Zhangtao Cheng, Yuhao Ma, Jian Lang, Kunpeng Zhang, Ting Zhong, Yong...
Pith/arXiv arXiv 2025
-
[2]
A survey on composed image retrieval.ACM Transactions on Multimedia Computing, Communi- cations and Applications, 21(7):1–27. Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, and 1 others. 2025. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multi- modal reasoning with scalable reinfo...
Pith/arXiv arXiv 2025
-
[3]
A survey on llm-based multi-agent sys- tems: workflow, infrastructure, and challenges.Vici- nagearth, 1(1):9. You Li, Fan Ma, and Yi Yang. 2025. Imagine and seek: Improving composed image retrieval with an imag- ined proxy. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 3984–3993. Tsung-Yi Lin, Michael Maire, ...
arXiv 2025
-
[4]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan
Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079. Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan
-
[5]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning repres...
arXiv 2022
-
[6]
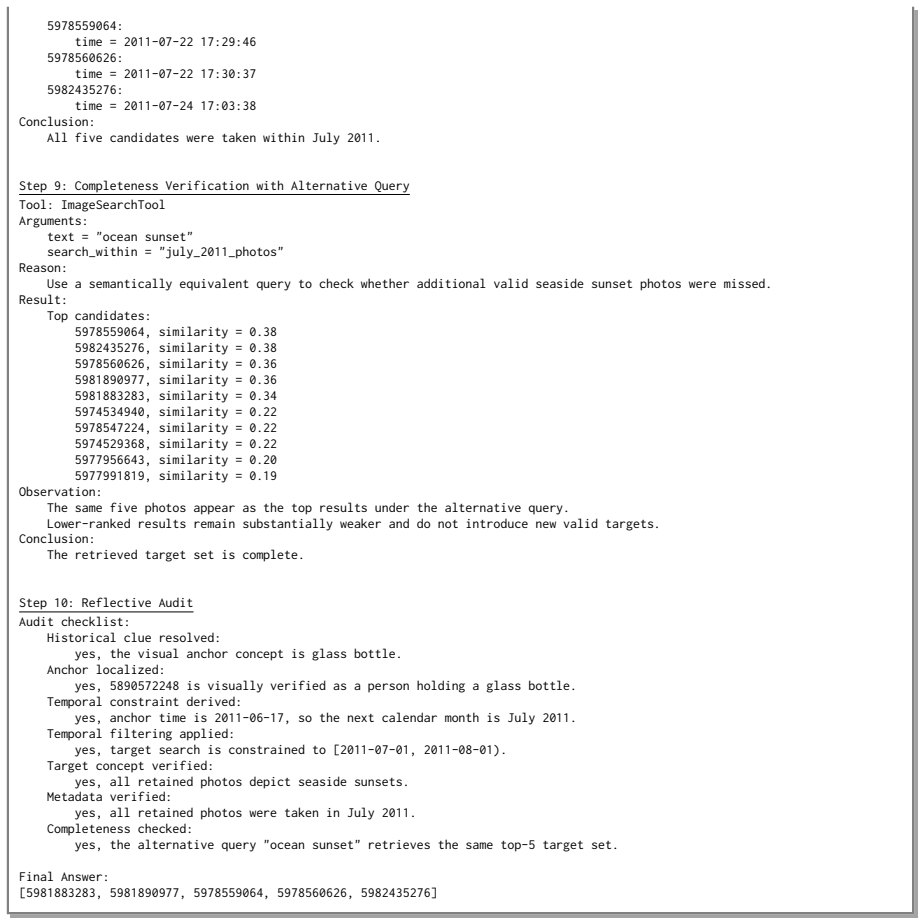
[REFLECTION: Reasoning Chain Audit]\n
as the multimodal encoder. We evaluate two encoder scales, 2B and 8B parameters, to examine how retrieval quality affects overall agent perfor- mance. Hyperparameters.Consistent with ImageSeeker’s setting (Deng et al., 2026), we set the maximum number of interaction turns to 30 and require the agent to return an answer once this budget is ex- hausted. Con...
2026
-
[7]
the concert identified by the blue logo
QUERY ANALYSIS -- decompose the query BEFORE calling any tool A. ANCHOR: Identify the reference event, entity, or photo mentioned in the query (e.g., "the concert identified by the blue logo", "the day when you saw the nude statue"). This is what you search for FIRST to derive constraints. B. CONSTRAINT: What fact will the anchor give you? (a specific dat...
-
[8]
- After finding the anchor, I must extract its date/location IMMEDIATELY and use it to constrain the next search
EXECUTE WITH STEP REFLECTION -- after EACH tool result, assess before your next action: - What did I just learn? Does it confirm or change my plan? - Am I still pursuing the right subgoal, or have I drifted? - If results are poor, I should try DIFFERENT keywords or a different approach -- NOT repeat the same failing strategy. - After finding the anchor, I...
-
[9]
on the day we
VERIFY BEFORE ANSWERING - For each candidate photo, confirm it satisfies the TARGET criteria (visual content + metadata constraints). - Anchor constraints define the event/context; do NOT require anchor visuals in target photos unless the query explicitly says so. - When a query uses temporal phrases ("on the day we...", "during the trip to..."), treat th...
-
[10]
leopard print parade
SEARCH PRECISION Use SHORT keywords (2-5 words) for ImageSearchTool, NOT the full query sentence. Good: "leopard print parade", "dinosaur skeleton museum" Bad: "Find photos from the Royal Regiment of Scotland band parade that include leopard print clothing" For complex queries, run MULTIPLE searches with DIFFERENT short keywords
-
[11]
on the day when
ANCHOR FIRST For queries referencing other events ("on the day when...", "the person who...", "after visiting..."): - Find the ANCHOR event/photo first. - VISUALLY VERIFY the anchor with ViewPhotosTool (do not assume based on search score alone). - If uncertain, check MULTIPLE anchor candidates before committing. - Extract the date/location from anchor me...
-
[12]
DATE FILTERING When filtering by date, ALWAYS use a date RANGE or prefix match: Correct: time >= ’2013-06-09’ and time < ’2013-06-10’ WRONG: time == ’2013-06-09 20:36:00’ (matches only ONE SECOND!)
2013
-
[13]
Sydney Harbour Bridge night
MULTI-ATTEMPT SEARCH If your first search returns few or no plausible matches, try AT LEAST 2 DIFFERENT keyword variants. Example: "Sydney Harbour Bridge night" -> also try "bridge night cityscape" -> also try "harbour bridge evening"
-
[14]
Do NOT search the entire album for targets that should be within a specific event
SCOPE CONTROL After deriving a date/location from the anchor, constrain your target search to that scope. Do NOT search the entire album for targets that should be within a specific event. Use FilterMetadataTool or search_within to narrow the scope
-
[15]
The final answer is: [
NEVER-EMPTY RULE You MUST NOT return an empty list []. If no perfect matches exist, return the closest candidates. ANSWER FORMAT In your final response, output exactly: "The final answer is: ["9876543210", "1234567890", ...]." Always use ACTUAL photo IDs from your search results. NEVER use placeholder names like "photo_id1". """ coherent evidence chain th...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.