SciVisAgentSkills: Design and Evaluation of Agent Skills for Scientific Data Analysis and Visualization
Pith reviewed 2026-06-28 02:17 UTC · model grok-4.3
The pith
Reusable agent skills encoding SciVis tool patterns raise coding agents' mean task scores on multi-step workflows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
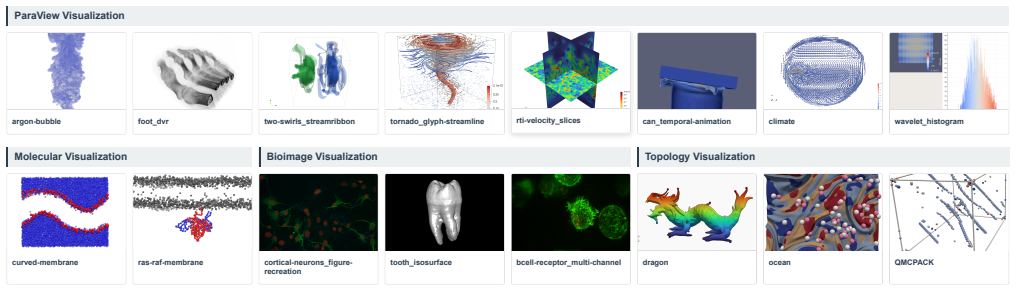
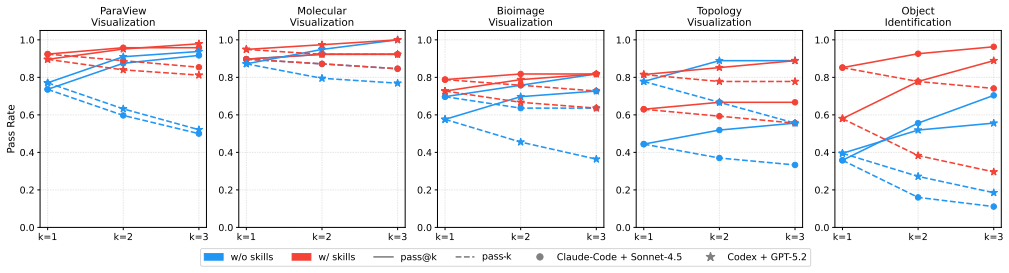
SciVisAgentSkills is a collection of reusable agent skills that augment coding agents for scientific data analysis and visualization by encoding environment assumptions, tool usage patterns, and domain heuristics across scientific tools such as ParaView, napari, VMD, and TTK. Evaluated on Codex and Claude Code using SciVisAgentBench, a benchmark of 108 expert-designed multi-step tasks, the skills improve mean task scores across the evaluated suites, with token-efficiency benefits that depend on the agent harness and tool setting. The findings indicate that structured procedural knowledge supports more reliable long-horizon SciVis workflows and that skills must be examined together with the e
What carries the argument
SciVisAgentSkills, a collection of reusable agent skills that encode environment assumptions, tool usage patterns, and domain heuristics for SciVis tools.
If this is right
- Agent skills improve mean task scores on the 108 SciVis tasks.
- Token-efficiency benefits depend on the specific agent harness and tool setting.
- Structured procedural knowledge supports reliable long-horizon SciVis workflows.
- Skills should be studied together with the execution harness that loads them.
Where Pith is reading between the lines
- The same skill design pattern could be applied to other agent toolkits that control different scientific software stacks.
- Skills tuned for one set of visualization packages may require updates when new versions or entirely new tools appear.
- Integrating the skills into additional agent frameworks beyond the two tested here could reveal further performance differences.
- Real deployment would need mechanisms to keep the encoded heuristics current as the underlying tools evolve.
Load-bearing premise
The 108 expert-designed tasks in SciVisAgentBench represent real-world long-horizon SciVis workflows and the skills will transfer to agents and tools beyond the two tested harnesses.
What would settle it
A follow-up evaluation on a fresh collection of tasks drawn directly from actual user sessions in ParaView or napari that shows no score improvement or worse token use when the skills are applied.
Figures
read the original abstract
Recent advances in agentic visualization have enabled the translation of natural language into executable scientific visualization (SciVis) workflows. While general-purpose coding agents show strong capabilities, they often lack the tool-specific expertise required for SciVis tasks. In this work, we present SciVisAgentSkills, a collection of reusable agent skills that augment coding agents for scientific data analysis and visualization by encoding environment assumptions, tool usage patterns, and domain heuristics across scientific tools such as ParaView, napari, VMD, and TTK. We evaluate these skills on Codex and Claude Code using SciVisAgentBench, a benchmark of 108 expert-designed multi-step tasks. Results show that agent skills improve mean task scores across the evaluated suites, with token-efficiency benefits that depend on the agent harness and tool setting. These findings highlight the importance of structured procedural knowledge for enabling reliable, long-horizon SciVis workflows, while also showing that skills should be studied alongside the execution harness that loads and applies them. The skills are available at https://github.com/KuangshiAi/SciVisAgentSkills.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SciVisAgentSkills, a collection of reusable agent skills for coding agents performing scientific data analysis and visualization. The skills encode environment assumptions, tool usage patterns, and domain heuristics for tools such as ParaView, napari, VMD, and TTK. They are evaluated on Codex and Claude Code using SciVisAgentBench, a benchmark of 108 expert-designed multi-step tasks. Results show that the skills improve mean task scores across suites, with token-efficiency benefits that depend on the agent harness and tool setting. The skills are released on GitHub.
Significance. If the empirical results hold with proper controls, this work would demonstrate the value of domain-specific procedural knowledge for reliable long-horizon SciVis agent workflows and the necessity of evaluating skills together with their execution harness. The open release of the skills supports reproducibility and extension by the community.
major comments (1)
- [Evaluation] The abstract asserts performance improvements but supplies no information on baselines, statistical tests, task selection criteria, or error bars, so the data cannot be checked against the claim from the given text. The evaluation section must supply these details to support the central claim that skills improve mean task scores.
Simulated Author's Rebuttal
We thank the referee for the constructive comment and the recommendation of minor revision. We address the evaluation concern below and will update the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation] The abstract asserts performance improvements but supplies no information on baselines, statistical tests, task selection criteria, or error bars, so the data cannot be checked against the claim from the given text. The evaluation section must supply these details to support the central claim that skills improve mean task scores.
Authors: We agree that the abstract and evaluation section require additional detail to make the performance claims verifiable. The revised manuscript will expand the evaluation section to describe the baselines (agents without the skills), the statistical tests applied to the mean task score differences, the expert criteria used to design and select the 108 tasks, and the error bars or variance measures reported for each suite. The abstract will be updated to briefly reference the baseline comparisons and the nature of the reported improvements. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper reports an empirical evaluation of newly designed agent skills on the 108-task SciVisAgentBench benchmark using two agent harnesses. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the provided text or abstract. The central claim (skills improve mean task scores with harness-dependent efficiency effects) is a direct reporting of experimental outcomes on the introduced benchmark and does not reduce to any definitional or fitted equivalence by construction. This is a standard self-contained empirical study with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
HiLSVA: Design and Evaluation of a Human-in-the-Loop Agentic System for Scientific Visualization
HiLSVA introduces a plan-first multi-agent LLM system for scientific visualization that incorporates explicit human oversight, stepwise provenance, and learn-at-test-time adaptation, evaluated via case studies and a 1...
Reference graph
Works this paper leans on
-
[1]
J. P. Ahrens, B. Geveci, and C. C. Law. ParaView: An end-user tool for large-data visualization. In C. D. Hansen and C. R. Johnson, eds., The Visualization Handbook, chap. 36, pp. 717–731. Academic Press,
-
[2]
doi:10.1016/B978-012387582-2/50038-11, 2
-
[3]
K. Ai, H. Miao, Z. Li, C. Wang, and S. Liu. An evaluation-centric paradigm for scientific visualization agents. InProceedings of IEEE Workshop on GenAI, Agents, and the Future of VIS, 2025. doi:10. 48550/arXiv.2509.151602
arXiv 2025
-
[4]
K. Ai, H. Miao, K. Tang, N. Gorski, J. Sun, G. Liu, H. I. Ing ´olfsson, D. Lenz, H. Guo, H. Yu, et al. SciVisAgentBench: A benchmark for evaluating scientific data analysis and visualization agents.arXiv preprint arXiv:2603.29139, 2026. doi:10.48550/arXiv.2603.291391, 2, 3
-
[5]
K. Ai, K. Tang, and C. Wang. NLI4V olVis: Natural language interac- tion for volume visualization via multi-LLM agents and editable 3D Gaussian splatting.IEEE Transactions on Visualization and Computer Graphics, 32(1):46–56, 2026. doi:10.1109/TVCG.2025.36338881, 2
-
[6]
Announcements: Introducing the model con- text protocol.https://www.anthropic.com/news/ model-context-protocol, 2024
Anthropic. Announcements: Introducing the model con- text protocol.https://www.anthropic.com/news/ model-context-protocol, 2024. 1
2024
-
[7]
Claude Code: An agentic coding tool.https://github
Anthropic. Claude Code: An agentic coding tool.https://github. com/anthropics/claude-code, 2025. 1
2025
-
[8]
Effective harnesses for long-running agents.https://www.anthropic.com/engineering/ effective-harnesses-for-long-running-agents, 2025
Anthropic. Effective harnesses for long-running agents.https://www.anthropic.com/engineering/ effective-harnesses-for-long-running-agents, 2025. 4
2025
-
[9]
Equipping agents for the real world with agent skills.https://claude.com/blog/ equipping-agents-for-the-real-world-with-agent-skills,
Anthropic. Equipping agents for the real world with agent skills.https://claude.com/blog/ equipping-agents-for-the-real-world-with-agent-skills,
-
[10]
Harness design for long-running application de- velopment.https://www.anthropic.com/engineering/ harness-design-long-running-apps, 2026
Anthropic. Harness design for long-running application de- velopment.https://www.anthropic.com/engineering/ harness-design-long-running-apps, 2026. 4
2026
-
[11]
A. Biswas, T. L. Turton, N. R. Ranasinghe, S. Jones, B. Love, W. Jones, A. Hagberg, H.-W. Shen, N. DeBardeleben, and E. Lawrence. VizGenie: Toward self-refining, domain-aware work- flows for next-generation scientific visualization.IEEE Transactions on Visualization and Computer Graphics, 32(1):1021–1031, 2026. doi:10.1109/TVCG.2025.36346551, 2
-
[12]
N. Chen, Y . Zhang, J. Xu, K. Ren, and Y . Yang. VisEval: A bench- mark for data visualization in the era of large language models.IEEE Transactions on Visualization and Computer Graphics, 31(1):1301– 1311, 2025. doi:10.1109/TVCG.2024.34563202
-
[13]
Z. Chen, J. Chen, S. ¨O. Arik, M. Sra, T. Pfister, and J. Yoon. CoDA: Agentic systems for collaborative data visualization.arXiv preprint arXiv:2510.03194, 2025. doi:10.48550/arXiv.2510.031942
-
[14]
V . Dhanoa, A. Wolter, G. M. Le ´on, H.-J. Schulz, and N. Elmqvist. Agentic visualization: Extracting agent-based design patterns from visualization systems.IEEE Computer Graphics and Applications, 45(6):89–90, 2025. doi:10.1109/MCG.2025.36077411, 2
-
[15]
V . Dibia. LIDA: A tool for automatic generation of grammar-agnostic visualizations and infographics using large language models. InPro- ceedings of Annual Meeting of the Association for Computational Lin- guistics: System Demonstrations, pp. 113–126, 2023. doi:10.18653/ v1/2023.acl-demo.112
2023
-
[16]
P. P. Do, K. Tang, K. Ai, and C. Wang. SVLAT: Scientific visualiza- tion literacy assessment test.arXiv preprint arXiv:2603.19000, 2026. doi:10.48550/arXiv.2603.190002
-
[17]
GMX-VMD-MCP: MCP service for GROMACS and VMD molecular dynamics simulations and visualization.https:// github.com/egtai/gmx-vmd-mcp, 2025
EgT. GMX-VMD-MCP: MCP service for GROMACS and VMD molecular dynamics simulations and visualization.https:// github.com/egtai/gmx-vmd-mcp, 2025. 1, 2
2025
-
[18]
T. Galimzyanov, S. Titov, Y . Golubev, and E. Bogomolov. Drawing Pandas: A benchmark for LLMs in generating plotting code. InPro- ceedings of IEEE/ACM International Conference on Mining Software Repositories, pp. 503–507, 2025. doi:10.48550/arXiv.2412.027642
-
[19]
Gemini CLI: An open-source ai agent that brings the power of gemini directly into your terminal.https://github.com/ google-gemini/gemini-cli, 2025
Google. Gemini CLI: An open-source ai agent that brings the power of gemini directly into your terminal.https://github.com/ google-gemini/gemini-cli, 2025. 1
2025
-
[20]
N. Gorski, S. Liu, and B. Wang. TopoPilot: Reliable conversational workflow automation for topological data analysis and visualization. arXiv preprint arXiv:2603.25063, 2026. doi:10.48550/arXiv.2603.25063 1, 2
-
[21]
Humphrey, A
W. Humphrey, A. Dalke, and K. Schulten. VMD: Visual molecular dynamics.Journal of Molecular Graphics, 14:33–38, 1996. doi:10. 1016/0263-7855(96)00018-51, 2
1996
-
[22]
D. Jia, A. Irger, L. Besanc ¸on, O. Strnad, D. Luo, J. Bj ¨orklund, A. Kouyoumdjian, A. Ynnerman, and I. Viola. VOICE: Visual ora- cle for interaction, conversation, and explanation.IEEE Transactions on Visualization and Computer Graphics, 31(10):8828–8845, 2025. doi:10.1109/TVCG.2025.35799562
-
[23]
SoK: Agentic Skills -- Beyond Tool Use in LLM Agents
Y . Jiang, D. Li, H. Deng, B. Ma, X. Wang, Q. Wang, and G. Yu. SoK: Agentic skills–beyond tool use in LLM agents.arXiv preprint arXiv:2602.20867, 2026. doi:10.48550/arXiv.2602.208672
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.208672 2026
-
[24]
X. Li, W. Chen, Y . Liu, S. Zheng, X. Chen, Y . He, Y . Li, B. You, H. Shen, J. Sun, et al. SkillsBench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670,
-
[25]
doi:10.48550/arXiv.2602.126702
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.126702
-
[26]
G. Ling, S. Zhong, and R. Huang. Agent skills: A data-driven anal- ysis of claude skills for extending large language model functionality. arXiv preprint arXiv:2602.08004, 2026. doi:10.48550/arXiv.2602.08004 2
-
[27]
S. Liu, H. Miao, and P.-T. Bremer. ParaView-MCP: An autonomous visualization agent with direct tool use. InProceedings of IEEE VIS Conference (Short Papers), pp. 61–65, 2025. doi:10.48550/arXiv.2505. 070641, 2
-
[28]
S. Liu, H. Miao, Z. Li, M. Olson, V . Pascucci, and P.-T. Bremer. A V A: Towards autonomous visualization agents through visual perception- driven decision-making.Computer Graphics F orum, 43(3):e15093,
-
[29]
doi:10.1111/cgf.150931, 2
-
[30]
X. Liu, H. Yu, H. Zhang, Y . Xu, X. Lei, H. Lai, Y . Gu, H. Ding, K. Men, K. Yang, et al. AgentBench: Evaluating LLMs as agents. InProceedings of International Conference on Learning Representa- tions, 2023. doi:10.48550/arXiv.2308.036881
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.036881 2023
-
[31]
M. Mathai, M. Han, J. Knowles, V . A. Mateevitsi, S. Rizzi, and H. Childs. NL2SciVis: A benchmark for natural language to scientific visualization. InProceedings of Eurographics Conference on Visual- ization (Short Papers), 2026. doi:10.2312/evs.202610172
-
[32]
GAIA: a benchmark for General AI Assistants
G. Mialon, C. Fourrier, T. Wolf, Y . LeCun, and T. Scialom. GAIA: A benchmark for general AI assistants. InProceedings of International Conference on Learning Representations, 2023. doi:10.48550/arXiv. 2311.129831
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2023
-
[33]
H. Miao, Z. Li, K. Ai, K. Tang, C. Wang, P.-T. Bremer, and S. Liu. Toward AI VIS co-scientists: A general and end-to-end agent har- ness for solving complex data visualization tasks.arXiv preprint arXiv:2605.21825, 2026. doi:10.48550/arXiv.2605.218252, 4
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.218252 2026
-
[34]
Miao and S
H. Miao and S. Liu. BioImage-Agent.https://github.com/LLNL/ bioimage-agent, 2025. 1, 2
2025
-
[35]
OpenAI Codex: Lightweight coding agent that runs in your terminal.https://github.com/openai/codex, 2025
OpenAI. OpenAI Codex: Lightweight coding agent that runs in your terminal.https://github.com/openai/codex, 2025. 1
2025
-
[36]
T. Peterka, T. Mallick, O. Yildiz, D. Lenz, C. Quammen, and B. Geveci. ChatVis: Large language model agent for generating scien- tific visualizations. InProceedings of IEEE Workshop on Large Data Analysis and Visualization, pp. 22–32, 2025. doi:10.1109/LDAV68558. 2025.000071, 2
-
[37]
Sofroniew, T
N. Sofroniew, T. Lambert, G. Bokota, J. Nunez-Iglesias, P. Sobolewski, A. Sweet, L. Gaifas, K. Evans, A. Burt, D. Don- cila Pop, et al. napari: A multi-dimensional image viewer for Python,
-
[38]
doi:10.5281/zenodo.35556201, 2
-
[39]
J. Sun, D. Lenz, T. Peterka, and H. Yu. SASA V: Self-directed agent for scientific analysis and visualization.arXiv preprint arXiv:2604.03406, 2026. doi:10.48550/arXiv.2604.034061, 2
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.034061 2026
-
[40]
J. Z. Tam, P. Grosset, D. Banesh, N. Ramachandra, T. L. Turton, and J. P. Ahrens. InferA: A smart assistant for cosmological ensemble data. InProceedings of ACM/IEEE SC Workshops, pp. 20–28, 2025. doi:10.1145/3731599.37673421, 2
-
[41]
K. Tang, K. Ai, J. Han, and C. Wang. TexGS-V olVis: Expressive scene editing for volume visualization via textured Gaussian splat- ting.IEEE Transactions on Visualization and Computer Graphics, 32(1):933–943, 2026. doi:10.1109/TVCG.2025.36346432
-
[42]
J. Tierny, G. Favelier, J. A. Levine, C. Gueunet, and M. Michaux. The topology toolkit.IEEE Transactions on Visualization and Computer Graphics, 24(1):832–842, 2018. doi:10.1109/TVCG.2017.27439381, 2
-
[43]
Exploring Interaction Paradigms for LLM Agents in Scientific Visualization
J. V onderhorst, K. Ai, H. Miao, S. Liu, and C. Wang. Exploring in- teraction paradigms for LLM agents in scientific visualization.arXiv preprint arXiv:2604.27996, 2026. doi:10.48550/arXiv.2604.279961, 2, 4
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.279961 2026
-
[44]
Y . Wang, B. Pan, K. Wang, H. Liu, J. Mao, Y . Liu, M. Zhu, B. Zhang, W. Chen, X. Huang, et al. IntuiTF: MLLM-guided trans- fer function optimization for direct volume rendering.arXiv preprint arXiv:2506.18407, 2025. doi:10.48550/arXiv.2506.184072
-
[45]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
R. Xu and Y . Yan. Agent skills for large language models: Archi- tecture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430, 2026. doi:10.48550/arXiv.2602.124302
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.124302 2026
-
[46]
S. Yao, N. Shinn, P. Razavi, and K. Narasimhan.τ-bench: A bench- mark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024. doi:10.48550/arXiv.2406.120451
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.120451 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.