SpectCount: Spectrotemporal Counting via Synthetic Signals Improves Large Audio Language Models
Pith reviewed 2026-06-27 21:16 UTC · model grok-4.3
The pith
Synthetic signals for spectrotemporal counting fix perceptual weaknesses in large audio language models and raise performance on unseen benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
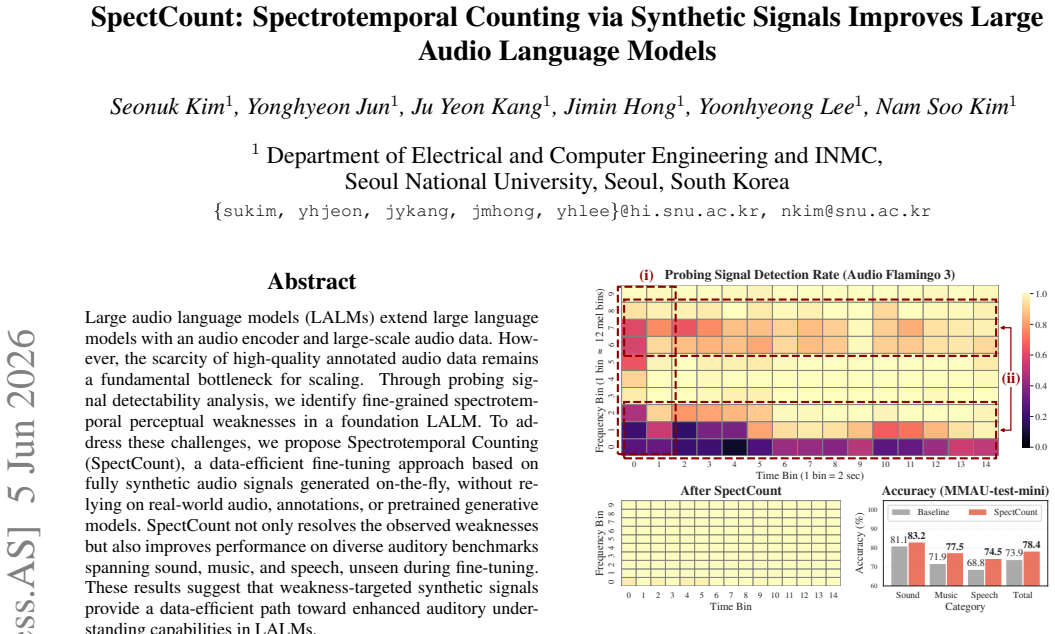
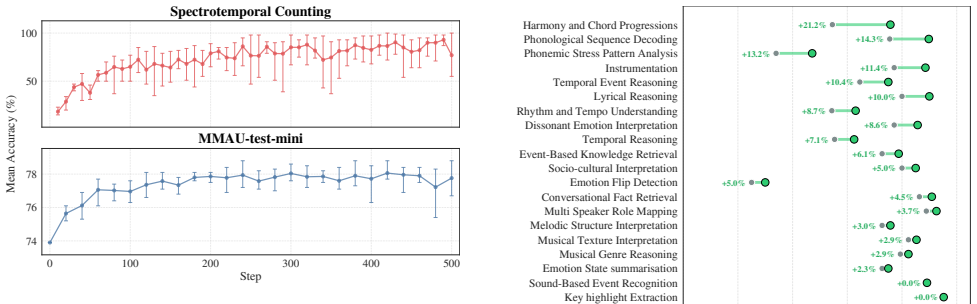
Through probing signal detectability analysis, we identify fine-grained spectrotemporal perceptual weaknesses in a foundation LALM. SpectCount, a data-efficient fine-tuning approach based on fully synthetic audio signals generated on-the-fly for spectrotemporal counting, resolves the observed weaknesses and improves performance on diverse auditory benchmarks spanning sound, music, and speech unseen during fine-tuning.
What carries the argument
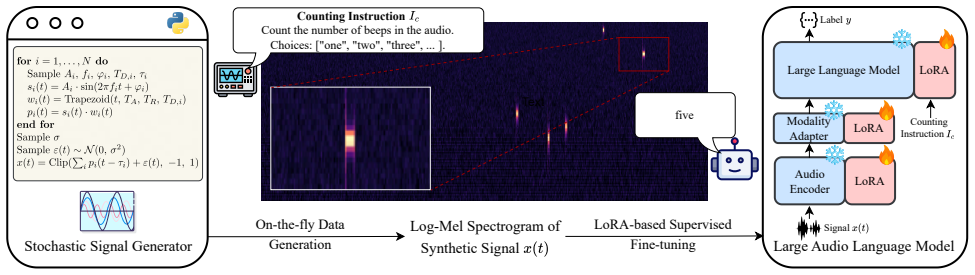
SpectCount, the fine-tuning procedure that trains on synthetic signals for spectrotemporal counting tasks generated without real audio or pretrained models.
If this is right
- The identified spectrotemporal weaknesses are resolved by the synthetic counting procedure.
- Performance rises on multiple auditory benchmarks across sound, music, and speech domains.
- The method requires no real-world audio, annotations, or pretrained generative models.
- Weakness-targeted synthetic signals offer a data-efficient path to better auditory understanding in LALMs.
Where Pith is reading between the lines
- If the approach scales, LALMs could be iteratively improved through repeated cycles of synthetic task generation rather than data collection.
- Similar probing and synthetic correction might extend to other perceptual gaps in multimodal models.
- The results imply that targeted synthetic data can substitute for large volumes of real annotated audio in some training regimes.
Load-bearing premise
The assumption that the spectrotemporal weaknesses identified by probing are the main bottleneck limiting LALM performance and that on-the-fly synthetic signals can address them in a generalizable way.
What would settle it
A direct test showing that after SpectCount fine-tuning the model exhibits no gain in accuracy on spectrotemporal signal detection tasks or no improvement on the held-out sound, music, and speech benchmarks.
Figures
read the original abstract
Large audio language models (LALMs) extend large language models with an audio encoder and large-scale audio data. However, the scarcity of high-quality annotated audio data remains a fundamental bottleneck for scaling. Through probing signal detectability analysis, we identify fine-grained spectrotemporal perceptual weaknesses in a foundation LALM. To address these challenges, we propose Spectrotemporal Counting (SpectCount), a data-efficient fine-tuning approach based on fully synthetic audio signals generated on-the-fly, without relying on real-world audio, annotations, or pretrained generative models. SpectCount not only resolves the observed weaknesses but also improves performance on diverse auditory benchmarks spanning sound, music, and speech, unseen during fine-tuning. These results suggest that weakness-targeted synthetic signals provide a data-efficient path toward enhanced auditory understanding capabilities in LALMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies fine-grained spectrotemporal perceptual weaknesses in a foundation large audio language model (LALM) via signal detectability probing. It proposes SpectCount, a data-efficient fine-tuning method that generates fully synthetic audio signals on-the-fly (without real-world audio, annotations, or pretrained generative models) and trains the model on a spectrotemporal counting task. The central claim is that this approach resolves the identified weaknesses and yields performance gains on diverse unseen auditory benchmarks spanning sound, music, and speech.
Significance. If the transfer from synthetic signals to real benchmarks holds and the improvements are not due to generic fine-tuning effects, the result would be significant: it demonstrates a scalable, annotation-free path to mitigate data scarcity in LALMs by targeting specific perceptual bottlenecks with synthetic data. The on-the-fly generation without external models or real audio is a notable strength for reproducibility and efficiency.
major comments (2)
- [Abstract and §4 (Experiments)] The central claim that SpectCount 'resolves the observed weaknesses' and improves performance on unseen benchmarks rests on the untested assumption that the synthetic signal distribution matches the acoustic statistics driving the probed failures. No ablation isolating the counting objective from generic fine-tuning effects is described, nor any analysis showing that the synthetic signals (e.g., tones or noise bursts) reproduce the relevant spectrotemporal statistics of real audio.
- [§3 (Method)] §3 (Method): the claim that synthetic signals are generated 'without relying on real-world audio, annotations, or pretrained generative models' is load-bearing for the data-efficiency argument, but the manuscript provides no verification that the generated signals avoid implicit leakage from any pretrained components used in synthesis.
minor comments (2)
- [§3] Clarify the exact form of the synthetic signals (e.g., pure tones, modulated noise, or more complex constructions) and the precise counting objective in the fine-tuning loss.
- [Introduction] The probing analysis in the introduction would benefit from explicit metrics (e.g., detection thresholds or error rates) to allow readers to assess the severity of the identified weaknesses.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the opportunity to clarify our work. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] The central claim that SpectCount 'resolves the observed weaknesses' and improves performance on unseen benchmarks rests on the untested assumption that the synthetic signal distribution matches the acoustic statistics driving the probed failures. No ablation isolating the counting objective from generic fine-tuning effects is described, nor any analysis showing that the synthetic signals (e.g., tones or noise bursts) reproduce the relevant spectrotemporal statistics of real audio.
Authors: We agree that an explicit ablation isolating the counting objective and a direct comparison of spectrotemporal statistics would strengthen the evidence for the transfer mechanism. The reported gains on diverse unseen benchmarks provide indirect support, but to address this directly we will add both an ablation (SpectCount vs. generic fine-tuning on identical synthetic signals) and a feature analysis (e.g., modulation spectra) in the revised §4. revision: yes
-
Referee: [§3 (Method)] the claim that synthetic signals are generated 'without relying on real-world audio, annotations, or pretrained generative models' is load-bearing for the data-efficiency argument, but the manuscript provides no verification that the generated signals avoid implicit leakage from any pretrained components used in synthesis.
Authors: The generation procedure uses only elementary mathematical operations (sine synthesis, band-limited noise, amplitude/frequency modulation) implemented via standard numerical routines with no machine-learning models or external pretrained components at any stage. We will revise §3 to include explicit pseudocode and a statement confirming the absence of any pretrained elements, thereby documenting the lack of leakage. revision: yes
Circularity Check
No circularity: empirical probing and synthetic fine-tuning rest on external benchmarks
full rationale
The paper presents an empirical pipeline—signal detectability probing to identify weaknesses, followed by on-the-fly synthetic signal generation for fine-tuning—without equations, parameter fitting, or derivations. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core claim. Performance gains are reported on held-out real-world benchmarks (sound, music, speech) that serve as independent external validation rather than being defined by or fitted to the synthetic procedure itself. The approach is therefore self-contained against external benchmarks and exhibits none of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SpectCount: Spectrotemporal Counting via Synthetic Signals Improves Large Audio Language Models
Introduction Recent advances in large language models (LLMs) have en- abled multimodal perception, extending their capabilities be- yond text to audio, visual, and other modalities [1, 2]. In the auditory domain, large spoken language models (LSLMs) inte- grate speech encoders with LLM backbones to support speech- centric tasks [3, 4, 5, 6, 7], and large ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
SpectCount SpectCount synthesizes training dataD={(x j(t), yj)}M j=1, generated on-the-fly, where the model learns to count pulses representing fine-grained acoustic events scattered across the time–frequency space, requiring detailed spectrotemporal de- tection and aggregation abilities. Each signalx j(t)consists of Nsuperposed pulses (N∼ U {1, N max}), ...
-
[3]
Implementation details We applied SpectCount to Audio Flamingo 3 [9] and Qwen2- Audio-Instruct [10] using the configuration in Table 2
Experiments 3.1. Implementation details We applied SpectCount to Audio Flamingo 3 [9] and Qwen2- Audio-Instruct [10] using the configuration in Table 2. LoRA (r= 8,α= 16, dropout0.05) was applied to all linear lay- ers. Training was conducted on three NVIDIA RTX 4090 GPUs with a batch size of 8, using AdamW at a constant learning rate of2×10 −4. Training ...
-
[4]
We identify fine-grained spectrotemporal perceptual weaknesses in a foun- dation LALM through probing analysis, and design a counting task to address these weaknesses
Conclusion In this paper, we propose SpectCount, a data-efficient fine- tuning method that enhances auditory perception and under- standing of LALMs using fully synthetic signals. We identify fine-grained spectrotemporal perceptual weaknesses in a foun- dation LALM through probing analysis, and design a counting task to address these weaknesses. Experimen...
-
[5]
They were not used for any core ideas or significant content
Generative AI Use Disclosure Generative AI tools were used solely for editing and polishing the English writing of this manuscript. They were not used for any core ideas or significant content
-
[6]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inProc. NeurIPS, 2017, pp. 5998–6008
2017
-
[7]
NExT-GPT: Any-to- any multimodal LLM,
S. Wu, H. Fei, L. Qu, W. Ji, and T.-S. Chua, “NExT-GPT: Any-to- any multimodal LLM,” inProc. ICML, 2024, pp. 53 366–53 397
2024
-
[8]
Recent advances in speech language models: A survey,
W. Cui, D. Yu, X. Jiao, Z. Meng, G. Zhang, Q. Wang, Y . Guo, and I. King, “Recent advances in speech language models: A survey,” inProc. ACL, 2025, pp. 13 943–13 970
2025
-
[9]
A survey on speech large language models for understanding,
J. Peng, Y . Wang, B. Li, Y . Guo, H. Wang, Y . Fang, Y . Xi, H. Li, X. Li, K. Zhang, S. Wang, and K. Yu, “A survey on speech large language models for understanding,”IEEE Journal of Selected Topics in Signal Processing, vol. 20, no. 1, pp. 2–31, 2026
2026
-
[10]
DiscreteSLU: A large language model with self- supervised discrete speech units for spoken language understand- ing,
S. Shon, K. Kim, Y .-T. Hsu, P. Sridhar, S. Watanabe, and K. Livescu, “DiscreteSLU: A large language model with self- supervised discrete speech units for spoken language understand- ing,” inProc. Interspeech, 2024, pp. 4154–4158
2024
-
[11]
Investigating the rea- soning abilities of large language models for understanding spo- ken language in interpersonal interactions,
P. Aggarwal, G. Mahajani, P. K. Malasani, V . Jamadagni, C. J. Wendt, E. H. Nirjhar, and T. Chaspari, “Investigating the rea- soning abilities of large language models for understanding spo- ken language in interpersonal interactions,” inProc. Interspeech, 2025, pp. 4518–4522
2025
-
[12]
Frozen large lan- guage models can perceive paralinguistic aspects of speech,
W. Kang, J. Jia, C. Wu, W. Zhou, E. Lakomkin, Y . Gaur, L. Sari, S. Kim, K. Li, J. Mahadeokar, and O. Kalinli, “Frozen large lan- guage models can perceive paralinguistic aspects of speech,” in Proc. Interspeech, 2025, pp. 4323–4327
2025
-
[13]
Towards holistic evalua- tion of large audio-language models: A comprehensive survey,
C.-K. Yang, N. S. Ho, and H.-y. Lee, “Towards holistic evalua- tion of large audio-language models: A comprehensive survey,” inProc. EMNLP, 2025, pp. 10 144–10 170
2025
-
[14]
Audio Flamingo 3: Advancing audio intelligence with fully open large audio language models,
S. Ghosh, A. Goel, J. Kim, S. Kumar, Z. Kong, S. gil Lee, C.-H. H. Yang, R. Duraiswami, D. Manocha, R. Valle, and B. Catanzaro, “Audio Flamingo 3: Advancing audio intelligence with fully open large audio language models,” inProc. NeurIPS, 2025
2025
-
[15]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin, C. Zhou, and J. Zhou, “Qwen2-Audio technical re- port,”arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
MMAU: A mas- sive multi-task audio understanding and reasoning benchmark,
S. Sakshi, U. Tyagi, S. Kumar, A. Seth, R. Selvakumar, O. Nieto, R. Duraiswami, S. Ghosh, and D. Manocha, “MMAU: A mas- sive multi-task audio understanding and reasoning benchmark,” inProc. ICLR, 2025
2025
-
[17]
MMSU: A massive multi-task spoken language under- standing and reasoning benchmark,
D. Wang, J. Wu, J. Li, D. Yang, X. Chen, T. Zhang, and H. M. Meng, “MMSU: A massive multi-task spoken language under- standing and reasoning benchmark,” inProc. ICLR, 2026
2026
-
[18]
SAKURA: On the multi-hop reasoning of large audio-language models based on speech and audio information,
C.-K. Yang, N. Ho, Y .-T. Piao, and H.-y. Lee, “SAKURA: On the multi-hop reasoning of large audio-language models based on speech and audio information,” inProc. Interspeech, 2025, pp. 1788–1792
2025
-
[19]
SoundMind: RL-incentivized logic rea- soning for audio-language models,
X. Diao, C. Zhang, K. Kong, W. Wu, C. Ma, Z. Ouyang, P. Qing, S. V osoughi, and J. Gui, “SoundMind: RL-incentivized logic rea- soning for audio-language models,” inProc. EMNLP, 2025, pp. 528–540
2025
-
[20]
Audio- Reasoner: Improving reasoning capability in large audio language models,
X. Zhifei, M. Lin, Z. Liu, P. Wu, S. Yan, and C. Miao, “Audio- Reasoner: Improving reasoning capability in large audio language models,” inProc. EMNLP, 2025, pp. 23 829–23 851
2025
-
[21]
Echo: Towards advanced audio comprehension via audio-interleaved reasoning,
D. Wu, X. Zhang, D. Yang, J. Yao, L. Chen, Q. Liu, S. Zhao, C. Ma, Y . Kang, and Y . Zhou, “Echo: Towards advanced audio comprehension via audio-interleaved reasoning,” inProc. ICLR, 2026
2026
-
[22]
Teaching audio-aware large language models what does not hear: Mitigating hallucinations through synthesized negative samples,
C.-Y . Kuan and H.-y. Lee, “Teaching audio-aware large language models what does not hear: Mitigating hallucinations through synthesized negative samples,” inProc. Interspeech, 2025, pp. 2073–2077
2025
-
[23]
Listening between the frames: Bridging temporal gaps in large audio-language mod- els,
H. Wang, Y . Li, S. Ma, H. Liu, and X. Wang, “Listening between the frames: Bridging temporal gaps in large audio-language mod- els,” inProc. AAAI, 2026
2026
-
[24]
AudioGenie-Reasoner: A training-free multi-agent framework for coarse-to-fine audio deep reasoning,
Y . Rong, C. Li, D. Yu, and L. Liu, “AudioGenie-Reasoner: A training-free multi-agent framework for coarse-to-fine audio deep reasoning,” inProc. ICASSP, 2026
2026
-
[25]
Audio-Maestro: Enhanc- ing large audio-language models with tool-augmented reasoning,
K.-Y . Lee, T.-E. Lin, and H.-y. Lee, “Audio-Maestro: Enhanc- ing large audio-language models with tool-augmented reasoning,” arXiv preprint arXiv:2510.11454, 2025
-
[26]
Sar-lm: Symbolic au- dio reasoning with large language models,
T. Taheri, Y . Ma, and E. Benetos, “SAR-LM: Symbolic au- dio reasoning with large language models,”arXiv preprint arXiv:2511.06483, 2025
-
[27]
Is syn- thetic data truly effective for training speech language models?
T. Mizumoto, A. Kojima, Y . Fujita, L. Liu, and Y . Sudo, “Is syn- thetic data truly effective for training speech language models?” inInterspeech, 2025, pp. 1808–1812
2025
-
[28]
Synthio: Augmenting small-scale audio classifi- cation datasets with synthetic data,
S. Ghosh, S. Kumar, Z. Kong, R. Valle, B. Catanzaro, and D. Manocha, “Synthio: Augmenting small-scale audio classifi- cation datasets with synthetic data,” inProc. ICLR, 2026
2026
-
[29]
Synthetic train- ing set generation using text-to-audio models for environmental sound classification,
F. Ronchini, L. Comanducci, and F. Antonacci, “Synthetic train- ing set generation using text-to-audio models for environmental sound classification,” inProc. DCASE Workshop, 2024, pp. 126– 130
2024
-
[30]
Can synthetic audio from generative foundation models assist audio recognition and speech modeling?
T. Feng, D. Dimitriadis, and S. Narayanan, “Can synthetic audio from generative foundation models assist audio recognition and speech modeling?” inProc. Interspeech, 2024, pp. 542–546
2024
-
[31]
Scaling laws for synthetic speech for model training,
C. Minixhofer, O. Klejch, and P. Bell, “Scaling laws for synthetic speech for model training,” inProc. Interspeech, 2025, pp. 3189– 3193
2025
-
[32]
From alignment to advancement: Bootstrapping audio-language alignment with synthetic data,
C.-Y . Kuan and H.-y. Lee, “From alignment to advancement: Bootstrapping audio-language alignment with synthetic data,” IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 4604–4619, Jan. 2025
2025
-
[33]
Pre-training with syn- thetic patterns for audio,
Y . Ishikawa, T. Komatsu, and Y . Aoki, “Pre-training with syn- thetic patterns for audio,” inProc. ICASSP, 2025, pp. 1–5
2025
-
[34]
MMAR: A chal- lenging benchmark for deep reasoning in speech, audio, music, and their mix,
Z. Ma, Y . Ma, Y . Zhu, C. Yang, Y .-W. Chao, R. Xu, W. Chen, Y . Chen, Z. Chen, J. Cong, K. Li, K. Li, S. Li, X. Li, X. Li, Z. Lian, Y . Liang, M. Liu, Z. Niu, T. Wang, Y . Wang, Y . Wang, Y . Wu, G. Yang, J. Yu, R. Yuan, Z. Zheng, Z. Zhou, H. Zhu, W. Xue, E. Benetos, K. Yu, E.-S. Chng, and X. Chen, “MMAR: A chal- lenging benchmark for deep reasoning in ...
2025
-
[35]
AIR-Bench: Benchmarking large audio-language models via generative comprehension,
Q. Yang, J. Xu, W. Liu, Y . Chu, Z. Jiang, X. Zhou, Y . Leng, Y . Lv, Z. Zhao, C. Zhou, and J. Zhou, “AIR-Bench: Benchmarking large audio-language models via generative comprehension,” inProc. ACL, 2024, pp. 1979–1998
2024
-
[36]
LoRA: Low-rank adaptation of large lan- guage models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-rank adaptation of large lan- guage models,” inProc. ICLR, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.