LARA: Latent Action Representation Alignment for Vision-Language-Action Models
Pith reviewed 2026-06-27 22:23 UTC · model grok-4.3
The pith
Jointly aligning representations lets latent action models and vision-language-action models improve each other during training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
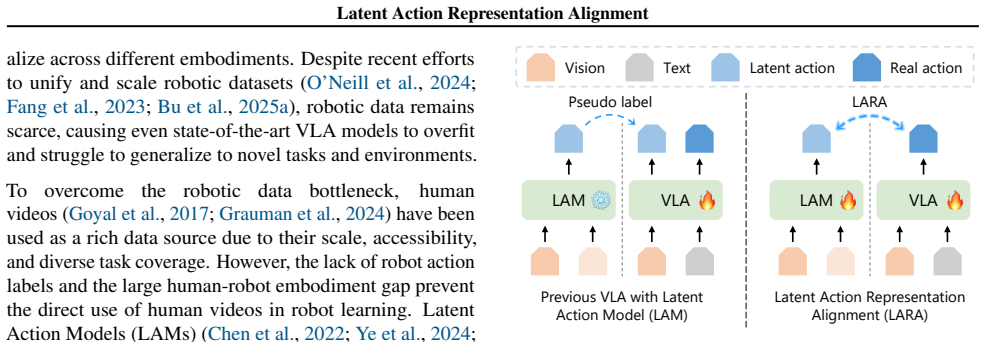
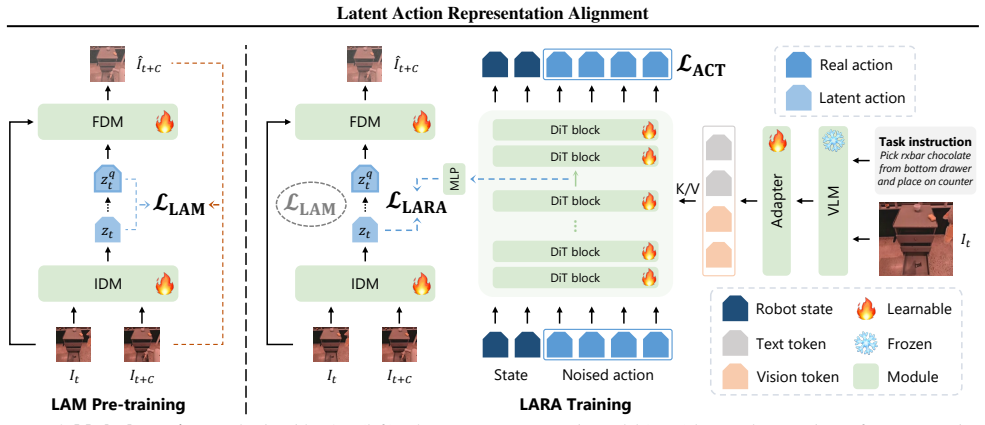
LARA enables reciprocal benefits by jointly optimizing LAM and VLA through representation alignment, allowing LAMs to learn from action trajectories and VLAs to be regularized by learned forward dynamics.
What carries the argument
Latent Action Representation Alignment (LARA), a plug-and-play framework that aligns representations between LAM and VLA models during joint optimization.
If this is right
- LAMs learn to avoid spurious visual changes by incorporating action trajectories during alignment.
- VLAs are regularized by forward dynamics learned inside LAMs, reducing hallucinations of functionally ineffective trajectories.
- The same framework supports pre-training from scratch, post-training enhancement of existing VLA models, and refinement of LAMs.
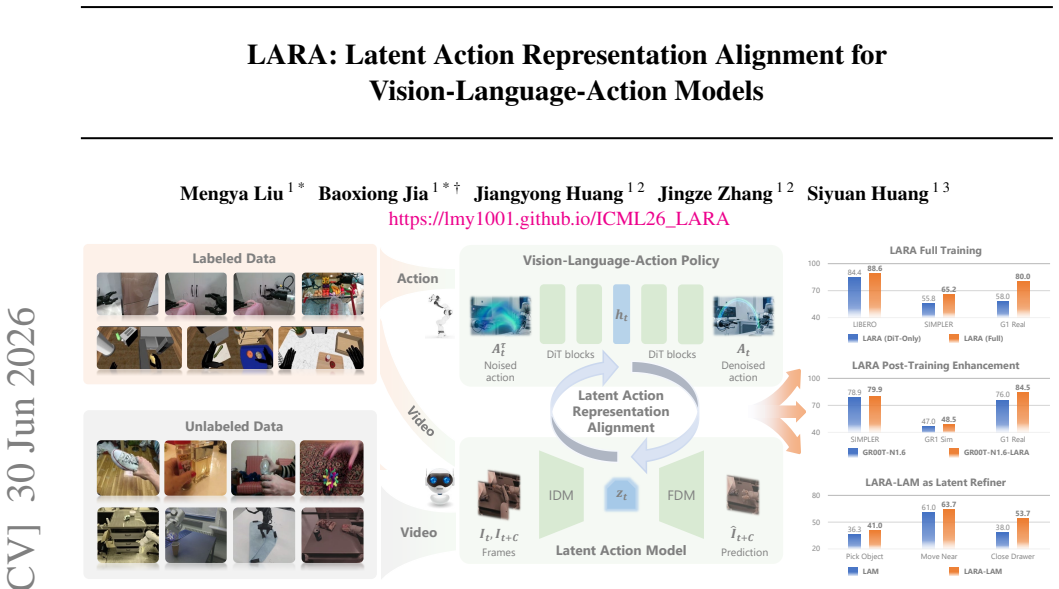
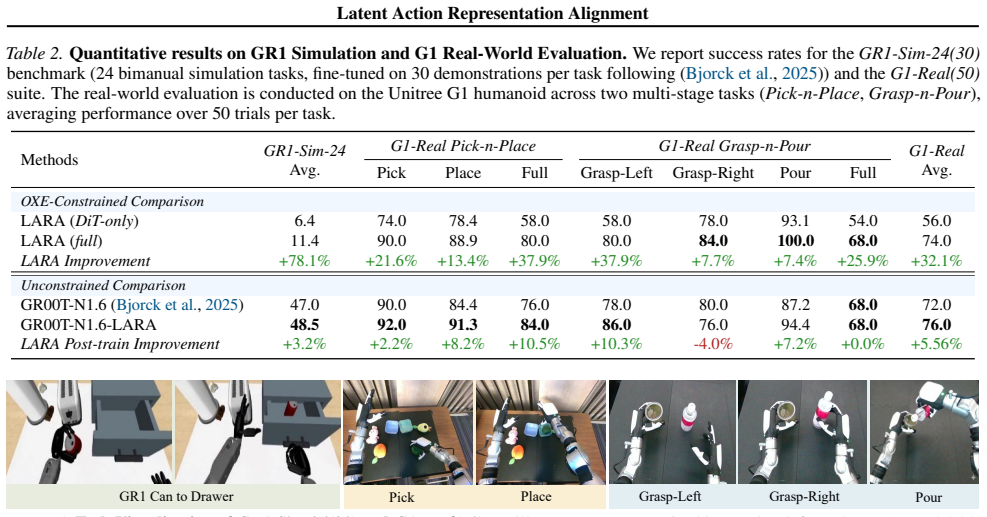
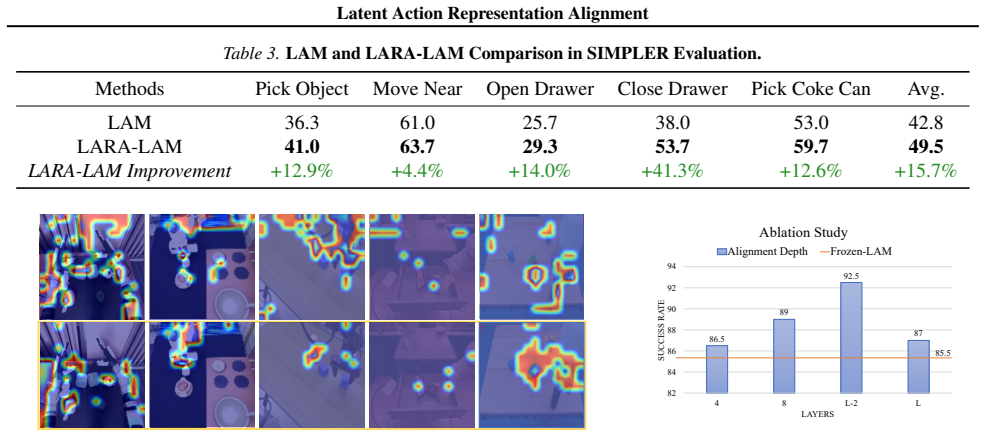
- Average gains of roughly 10 percent, 5 percent, and 15 percent appear across the three simulation and one real-world robotic manipulation benchmarks.
Where Pith is reading between the lines
- If alignment remains stable across larger unlabeled video collections, VLA training could scale with far less robot-specific action data.
- The same alignment idea could be tested on other pairs of dynamics models and policy models in robotics.
- Persistent alignment during continued training might reduce the frequency of out-of-distribution failures in deployed robots.
Load-bearing premise
Forcing representation alignment between separately trained LAM and VLA models will produce reciprocal benefits without destabilizing either model or introducing new failure modes.
What would settle it
A controlled comparison showing that joint training with alignment produces lower success rates or higher rates of ineffective trajectories than separate training on the same benchmarks would falsify the reciprocal-benefit claim.
Figures
read the original abstract
Visual-language action (VLA) models enable robots to predict actions directly from observations and language instructions, but their performance depends on large-scale, high-quality data and is limited by the scarcity of real-world robot action datasets. To facilitate VLA model learning with abundant unlabeled human videos, Latent Action Models (LAM) learn latent action representations from visual dynamics to provide additional supervision for VLA learning. However, LAM and VLA are typically trained separately, leaving LAM ungrounded during VLA training and VLA models constrained by frozen LAM representations. To address these issues, we propose Latent Action Representation Alignment (LARA), a plug-and-play framework that jointly optimizes LAM and VLA via representation alignment. This enables reciprocal benefits where LAMs learn with action trajectories to avoid spurious visual changes, while VLAs are regularized by forward dynamics learned within LAMs to reduce hallucinations of functionally ineffective trajectories. We demonstrate LARA versatility and effectiveness for pre-training, post-training enhancement of pre-trained VLA models, and LAM refinement, achieving an average of ~10%, ~5%, and ~15% improvement over 3 simulation and 1 meticulously designed real-world robotic manipulation benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LARA, a plug-and-play framework that jointly optimizes Latent Action Models (LAMs) and Vision-Language-Action (VLA) models through representation alignment. This is intended to ground LAMs with action trajectories (avoiding spurious visual changes) and regularize VLAs with LAM forward dynamics (reducing ineffective trajectories). The approach is applied to pre-training, post-training enhancement, and LAM refinement, with reported average gains of ~10%, ~5%, and ~15% over three simulation benchmarks and one real-world robotic manipulation benchmark.
Significance. If the gains are robust, reproducible, and causally attributable to the alignment mechanism rather than joint optimization or data effects, the work would meaningfully address data scarcity for VLAs by leveraging unlabeled human videos. The plug-and-play design and multi-stage applicability would be practical strengths for the field.
major comments (2)
- [Experiments / Results] The central empirical claim (average ~10/5/15% gains) rests on the assertion that representation alignment produces specific reciprocal benefits (LAM avoiding spurious changes; VLA avoiding ineffective trajectories). No ablation isolating the alignment loss from other joint-training effects (e.g., extra gradients, data mixing) is described, leaving the mechanism unverified against the skeptic concern.
- [Abstract / Experiments] The abstract and claim summary supply no baselines, error bars, data-exclusion rules, or statistical tests. Without these, the reported deltas cannot be assessed for significance or compared to prior LAM/VLA joint-training methods.
minor comments (1)
- [Method] Notation for the alignment objective and the separate LAM/VLA losses should be introduced with explicit equations early in the method section to clarify how the joint optimization is formulated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below and commit to revisions that strengthen the empirical support for our claims without overstating current results.
read point-by-point responses
-
Referee: [Experiments / Results] The central empirical claim (average ~10/5/15% gains) rests on the assertion that representation alignment produces specific reciprocal benefits (LAM avoiding spurious changes; VLA avoiding ineffective trajectories). No ablation isolating the alignment loss from other joint-training effects (e.g., extra gradients, data mixing) is described, leaving the mechanism unverified against the skeptic concern.
Authors: We agree that the manuscript does not contain an ablation that isolates the alignment loss from other joint-training effects such as additional gradients or data mixing. Existing experiments compare LARA against separate LAM and VLA training but lack a joint-training control without the alignment objective. We will add this ablation in the revision to directly test whether the reported reciprocal benefits are attributable to representation alignment. revision: yes
-
Referee: [Abstract / Experiments] The abstract and claim summary supply no baselines, error bars, data-exclusion rules, or statistical tests. Without these, the reported deltas cannot be assessed for significance or compared to prior LAM/VLA joint-training methods.
Authors: We acknowledge that the abstract lacks explicit baselines, error bars, and statistical details. We will revise the abstract to reference the main comparison baselines and note that error bars appear in the result tables. Data-exclusion rules and any statistical tests are already described in the experimental setup; we will add a brief pointer in the abstract. Full comparison to prior joint-training methods remains in the body of the paper due to length constraints. revision: partial
Circularity Check
No circularity; empirical performance claims with no derivations or self-referential reductions
full rationale
The paper's central claims consist of an empirical method (LARA) and reported benchmark improvements (~10/5/15%). No equations, derivations, or fitted parameters are presented in the abstract or described structure. The description of reciprocal benefits is a design rationale, not a mathematical reduction to inputs. No self-citation load-bearing steps or ansatz smuggling appear. This is a standard non-circular empirical ML paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Semi-Supervised Vision-Language-Action Model
SemiVLA improves VLA adaptation under 10% labeled trajectories via self-distilled pseudo-actions, reaching 89% success on LIBERO with OpenVLA backbone.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.25616 , year=
Don't Blind Your VLA: Aligning Visual Representations for OOD Generalization , author=. arXiv preprint arXiv:2510.25616 , year=
-
[2]
arXiv preprint arXiv:2504.10483 , year=
Repa-e: Unlocking vae for end-to-end tuning with latent diffusion transformers , author=. arXiv preprint arXiv:2504.10483 , year=
-
[3]
arXiv preprint arXiv:2406.09246 , year=
Openvla: An open-source vision-language-action model , author=. arXiv preprint arXiv:2406.09246 , year=
-
[4]
arXiv preprint arXiv:2212.06817 , year=
Rt-1: Robotics transformer for real-world control at scale , author=. arXiv preprint arXiv:2212.06817 , year=
-
[5]
arXiv preprint arXiv:2503.14734 , year=
Gr00t n1: An open foundation model for generalist humanoid robots , author=. arXiv preprint arXiv:2503.14734 , year=
-
[6]
arXiv preprint arXiv:2410.24164 , year=
_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. arXiv preprint arXiv:2410.24164 , year=
-
[7]
arXiv preprint arXiv:2410.11758 , year=
Latent action pretraining from videos , author=. arXiv preprint arXiv:2410.11758 , year=
-
[8]
Moto: Latent motion token as the bridging language for robot manipulation , author=
-
[9]
arXiv preprint arXiv:2502.00379 , year=
Latent action learning requires supervision in the presence of distractors , author=. arXiv preprint arXiv:2502.00379 , year=
-
[10]
Lapo: Latent-variable advantage-weighted policy optimization for offline reinforcement learning , author=
-
[11]
arXiv preprint arXiv:2507.23682 , year=
Villa-x: enhancing latent action modeling in vision-language-action models , author=. arXiv preprint arXiv:2507.23682 , year=
-
[12]
Univla: Learning to act anywhere with task-centric latent actions , author=
-
[13]
arXiv preprint arXiv:2410.06940 , year=
Representation alignment for generation: Training diffusion transformers is easier than you think , author=. arXiv preprint arXiv:2410.06940 , year=
-
[14]
arXiv preprint arXiv:2304.07193 , year=
Dinov2: Learning robust visual features without supervision , author=. arXiv preprint arXiv:2304.07193 , year=
-
[15]
arXiv preprint arXiv:2405.12213 , year=
Octo: An open-source generalist robot policy , author=. arXiv preprint arXiv:2405.12213 , year=
-
[16]
arXiv preprint arXiv:2501.15830 , year=
Spatialvla: Exploring spatial representations for visual-language-action model , author=. arXiv preprint arXiv:2501.15830 , year=
-
[17]
arXiv preprint arXiv:2501.14818 , year=
Eagle 2: Building post-training data strategies from scratch for frontier vision-language models , author=. arXiv preprint arXiv:2501.14818 , year=
-
[18]
arXiv preprint arXiv:2505.11917 , year=
OneTwoVLA: A Unified Vision-Language-Action Model with Adaptive Reasoning , author=. arXiv preprint arXiv:2505.11917 , year=
-
[19]
arXiv preprint arXiv:2512.01715 , year=
DiG-Flow: Discrepancy-Guided Flow Matching for Robust VLA Models , author=. arXiv preprint arXiv:2512.01715 , year=
-
[20]
arXiv preprint arXiv:2507.15597 , year=
Being-h0: vision-language-action pretraining from large-scale human videos , author=. arXiv preprint arXiv:2507.15597 , year=
-
[21]
arXiv preprint arXiv:2502.19417 , year=
Hi robot: Open-ended instruction following with hierarchical vision-language-action models , author=. arXiv preprint arXiv:2502.19417 , year=
-
[22]
arXiv preprint arXiv:2312.10812 , year=
Learning to act without actions , author=. arXiv preprint arXiv:2312.10812 , year=
-
[23]
Genie: Generative interactive environments , author=
-
[24]
Dynamo: In-domain dynamics pretraining for visuo-motor control , author=
-
[25]
arXiv preprint arXiv:2411.00785 , year=
Igor: Image-goal representations are the atomic control units for foundation models in embodied ai , author=. arXiv preprint arXiv:2411.00785 , year=
-
[26]
2025 , publisher=
Diffusion policy: Visuomotor policy learning via action diffusion , author=. 2025 , publisher=
2025
-
[27]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models , author=
-
[28]
arXiv preprint arXiv:2501.09747 , year=
Fast: Efficient action tokenization for vision-language-action models , author=. arXiv preprint arXiv:2501.09747 , year=
-
[29]
arXiv preprint arXiv:2507.04447 , year=
Dreamvla: a vision-language-action model dreamed with comprehensive world knowledge , author=. arXiv preprint arXiv:2507.04447 , year=
-
[30]
arXiv preprint arXiv:2502.19645 , year=
Fine-tuning vision-language-action models: Optimizing speed and success , author=. arXiv preprint arXiv:2502.19645 , year=
-
[31]
arXiv preprint arXiv:2412.14058 , year=
Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models , author=. arXiv preprint arXiv:2412.14058 , year=
-
[32]
arXiv preprint arXiv:2412.10345 , year=
Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies , author=. arXiv preprint arXiv:2412.10345 , year=
-
[33]
Magma: A foundation model for multimodal ai agents , author=
-
[34]
arXiv preprint arXiv:2210.02747 , year=
Flow matching for generative modeling , author=. arXiv preprint arXiv:2210.02747 , year=
-
[35]
Neural discrete representation learning , author=
-
[36]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0 , author=
-
[37]
Libero: Benchmarking knowledge transfer for lifelong robot learning , author=
-
[38]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Elevating Visual Perception in Multimodal LLMs with Visual Embedding Distillation , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[39]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
3drs: Mllms need 3d-aware representation supervision for scene understanding , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[40]
arXiv preprint arXiv:2512.01809 , year=
Much Ado About Noising: Dispelling the Myths of Generative Robotic Control , author=. arXiv preprint arXiv:2512.01809 , year=
-
[41]
arXiv preprint arXiv:2410.07864 , year=
Rdt-1b: a diffusion foundation model for bimanual manipulation , author=. arXiv preprint arXiv:2410.07864 , year=
-
[42]
Scalable diffusion models with transformers , author=
-
[43]
arXiv preprint arXiv:2505.15659 , year=
FLARE: Robot learning with implicit world modeling , author=. arXiv preprint arXiv:2505.15659 , year=
-
[44]
Bootstrap your own latent-a new approach to self-supervised learning , author=
-
[45]
arXiv preprint arXiv:2405.05941 , year=
Evaluating real-world robot manipulation policies in simulation , author=. arXiv preprint arXiv:2405.05941 , year=
-
[46]
arXiv preprint arXiv:2503.06669 , year=
Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems , author=. arXiv preprint arXiv:2503.06669 , year=
-
[47]
something something
The" something something" video database for learning and evaluating visual common sense , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[48]
arXiv preprint arXiv:2506.15691 , year=
What Do Latent Action Models Actually Learn? , author=. arXiv preprint arXiv:2506.15691 , year=
-
[49]
arXiv preprint arXiv:2307.00595 , year=
Rh20t: A comprehensive robotic dataset for learning diverse skills in one-shot , author=. arXiv preprint arXiv:2307.00595 , year=
-
[50]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives , author=
-
[51]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Masked autoencoders are scalable vision learners , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[52]
Rt-2: Vision-language-action models transfer web knowledge to robotic control, 2023 , author=. URL https://arxiv. org/abs/2307.15818 , year=
Pith/arXiv arXiv 2023
-
[53]
arXiv preprint arXiv:2403.09631 , year=
3d-vla: A 3d vision-language-action generative world model , author=. arXiv preprint arXiv:2403.09631 , year=
-
[54]
IEEE Robotics and Automation Letters , volume=
Pointvla: Injecting the 3d world into vision-language-action models , author=. IEEE Robotics and Automation Letters , volume=. 2026 , publisher=
2026
-
[55]
arXiv preprint arXiv:2508.07917 , year=
Molmoact: Action reasoning models that can reason in space , author=. arXiv preprint arXiv:2508.07917 , year=
-
[56]
arXiv preprint arXiv:2507.16815 , year=
Thinkact: Vision-language-action reasoning via reinforced visual latent planning , author=. arXiv preprint arXiv:2507.16815 , year=
-
[57]
arXiv preprint arXiv:2508.21046 , year=
Cogvla: Cognition-aligned vision-language-action model via instruction-driven routing & sparsification , author=. arXiv preprint arXiv:2508.21046 , year=
-
[58]
arXiv preprint arXiv:2505.04999 , year=
Clam: Continuous latent action models for robot learning from unlabeled demonstrations , author=. arXiv preprint arXiv:2505.04999 , year=
-
[59]
arXiv preprint arXiv:2502.20321 , year=
Unitok: A unified tokenizer for visual generation and understanding , author=. arXiv preprint arXiv:2502.20321 , year=
-
[60]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Denoising token prediction in masked autoregressive models , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[61]
Forty-first International Conference on Machine Learning , year=
Prismatic vlms: Investigating the design space of visually-conditioned language models , author=. Forty-first International Conference on Machine Learning , year=
-
[62]
Black, Kevin and Brown, Noah and Darpinian, James and Dhabalia, Karan and Driess, Danny and Esmail, Adnan and Equi, Michael Robert and Finn, Chelsea and Fusai, Niccolo and Galliker, Manuel Y and others , booktitle=. _
-
[63]
Arnold: A benchmark for language-grounded task learning with continuous states in realistic 3d scenes , author=
-
[64]
An embodied generalist agent in 3d world , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.