TinyGiantALM: A Compact Audio-Language Model for Intent-Aware Reasoning under Resource Constraints
Pith reviewed 2026-06-27 18:16 UTC · model grok-4.3
The pith
A 1.5B audio-language model outperforms 7B-13B baselines on mixed-modality reasoning via intent-aware filtering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TinyGiantALM is a 1.5B efficiency-oriented audio-language model that uses an Instruction-Aware Feature Refinement framework, built around a Query-guided Projector and Semantic Gating, to filter acoustic signals according to user intent. On the MMAR benchmark the model records 46.4 percent zero-shot accuracy, outperforming 7B-13B baselines and models up to 8 times larger in mixed-modality disentangling, while still trailing 30B+ models on logical narrative tasks and showing trade-offs in overly dense or spatial scenes.
What carries the argument
The Instruction-Aware Feature Refinement framework, which employs a Query-guided Projector and Semantic Gating to filter acoustic signals based on user intent.
If this is right
- Audio reasoning models become deployable in resource-constrained environments without requiring massive parameter counts.
- Architectural precision can allow smaller models to exceed the performance of models several times larger when handling mixed-modality inputs.
- A practical pathway exists toward robust perception capabilities on edge-friendly scales.
- Performance gaps remain in logical narrative reasoning relative to models of 30B parameters and above.
Where Pith is reading between the lines
- The same intent-guided filtering idea could be tested in other multimodal settings such as vision-language models to reduce compute needs.
- Direct measurement of latency and memory use on actual edge devices would be needed to confirm the claimed deployment advantages.
- Dynamic intent changes during a single audio stream might be handled by extending the gating mechanism to update mid-inference.
Load-bearing premise
The Query-guided Projector and Semantic Gating components filter acoustic signals according to user intent in a manner that directly produces the observed accuracy improvements.
What would settle it
An ablation study that removes or disables the Query-guided Projector and Semantic Gating and then re-evaluates zero-shot accuracy on the MMAR benchmark to check whether performance remains unchanged.
Figures

read the original abstract
Current advancements in Audio Reasoning rely on massive Large Audio-Language Models (LALMs), hindering deployment in resource-constrained environments. We introduce TinyGiantALM, a compact 1.5B efficiency-oriented alternative. Instead of brute-force scaling, we propose an Instruction-Aware Feature Refinement framework using a Query-guided Projector and Semantic Gating to filter acoustic signals based on user intent. On the MMAR benchmark, TinyGiantALM achieves 46.4% zero-shot accuracy, significantly outperforming 7B-13B baselines. While a reasoning gap in logical narrative remains versus 30B+ models and certain trade-offs exist in overly dense or spatial scenes, our approach notably surpasses models up to 8x larger in disentangling mixed-modality environments. These findings demonstrate that architectural precision offers a tangible pathway to secure robust perception capabilities on edge-friendly scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TinyGiantALM, a 1.5B-parameter compact audio-language model for resource-constrained settings. It proposes an Instruction-Aware Feature Refinement framework with a Query-guided Projector and Semantic Gating to filter acoustic signals based on user intent. On the MMAR benchmark, it reports 46.4% zero-shot accuracy, outperforming 7B-13B baselines and models up to 8x larger in mixed-modality disentanglement, while noting remaining gaps versus 30B+ models in logical narrative reasoning and trade-offs in dense/spatial scenes.
Significance. If the performance deltas can be rigorously attributed to the proposed modules, the result would demonstrate that targeted architectural precision can yield efficient models competitive with much larger ones in audio reasoning tasks, supporting deployment in edge environments without brute-force scaling.
major comments (2)
- [Abstract / Results] Abstract / Results: The headline claim attributes the 46.4% MMAR accuracy and outperformance of larger models specifically to the Query-guided Projector and Semantic Gating within the Instruction-Aware Feature Refinement framework, yet no ablation studies, removal experiments, or controls are described that hold all other factors (base architecture, training data, projector design) fixed while measuring the modules' isolated contribution.
- [Abstract] Abstract: The comparisons to 7B-13B baselines and 8x-larger models report no error bars, standard deviations, number of runs, or statistical tests, leaving the significance of the accuracy deltas unquantified and the robustness of the central claim difficult to evaluate.
minor comments (1)
- [Abstract] Abstract: The mention of trade-offs in overly dense or spatial scenes is qualitative only; specific metrics or failure-case analysis would clarify the scope of the limitations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below, acknowledging where the current version falls short and committing to targeted revisions.
read point-by-point responses
-
Referee: [Abstract / Results] The headline claim attributes the 46.4% MMAR accuracy and outperformance of larger models specifically to the Query-guided Projector and Semantic Gating within the Instruction-Aware Feature Refinement framework, yet no ablation studies, removal experiments, or controls are described that hold all other factors (base architecture, training data, projector design) fixed while measuring the modules' isolated contribution.
Authors: We agree that the manuscript lacks explicit ablation studies isolating the Query-guided Projector and Semantic Gating. The reported results reflect the full framework, and while comparisons to baselines provide supporting evidence, they do not hold all other variables fixed. In the revised version we will add controlled ablation experiments, including variants with each module removed or disabled, to quantify their isolated contributions. revision: yes
-
Referee: [Abstract] The comparisons to 7B-13B baselines and 8x-larger models report no error bars, standard deviations, number of runs, or statistical tests, leaving the significance of the accuracy deltas unquantified and the robustness of the central claim difficult to evaluate.
Authors: The accuracies are reported from single evaluation runs, following standard zero-shot evaluation practice on MMAR. Multiple independent runs were not conducted owing to computational limits in our resource-constrained setting. We will revise the manuscript to state this explicitly, report any available seed-based variability where feasible, and note the single-run nature as a limitation. revision: partial
Circularity Check
No circularity: empirical performance claims lack any derivation chain or self-referential reduction
full rationale
The provided abstract and description contain no equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations. The central claim is an empirical benchmark result (46.4% on MMAR) attributed to the proposed modules, but this is presented as an architectural choice and measured outcome rather than a mathematical reduction to inputs by construction. Absence of any derivation chain means no opportunity for the enumerated circularity patterns to apply; the result is self-contained as a reported experiment.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction The recentInterspeech 2026 Audio Reasoning Challenge[1] highlighted a pivotal shift in auditory intelligence, where Large Audio-Language Models (LALMs) like Qwen3-Omni achieve remarkable reasoning depth. However, these top-tier systems predominantly rely on massive parameter scaling (>7B–30B) and computationally expensive Reinforcement Learni...
2026
-
[2]
Despite this, audio remains chal- lenging due to high temporal density and overlapping signals
Related Work Deep Reasoning in LALMs.The success of Chain-of-Thought (CoT) [3] has shifted audio research from simple perception toward cognitive reasoning. Despite this, audio remains chal- lenging due to high temporal density and overlapping signals. Current state-of-the-art LALMs, such as SALMONN [4] and Qwen2-Audio [5], rely on massive parameter scali...
-
[3]
TinyGiantALM: A Compact Audio-Language Model for Intent-Aware Reasoning under Resource Constraints
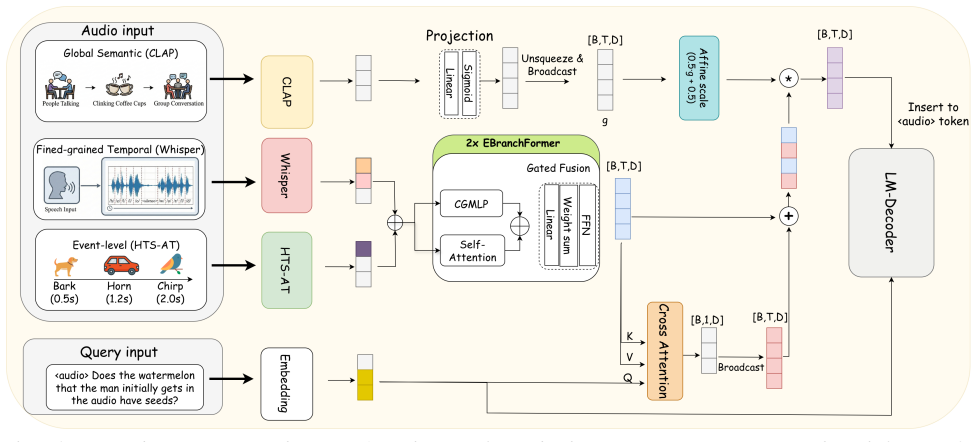
and E-Branchformer [7] have set benchmarks in speech processing by decoupling local-global contexts, their potential as ”reasoning bridges” for LLMs remains largely unexplored. arXiv:2606.08425v2 [cs.SD] 20 Jun 2026 Most existing ALMs utilize simple linear projectors that fail to filter task-relevant information. TinyGiantALM addresses this by repurposing...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Methodology We propose TinyGiantALM, an audio-language model de- signed to bridge the gap between heterogeneous acoustic signals and textual user intent. As illustrated in Figure 2, our frame- work consists of a triple-stream acoustic front-end, a novel Query-guided Projector utilizing E-Branchformer blocks, and a Large Language Model (LLM) backbone. 3.1....
-
[5]
Global Branch (MHSA):Captures long-range context via Multi-Head Self-Attention: Zattn = LayerNorm(X+ Dropout(MHSA(X)))(5)
-
[6]
Features are expanded, convolved, and projected back: Xconv = Lin2(σ(DConv17(σ(Lin1(X)))))(6) Zconv = LayerNorm(X+ Dropout(X conv))(7)
Local Branch (Convolution):Captures acoustic tran- sients via 1D depth-wise convolution (k= 17). Features are expanded, convolved, and projected back: Xconv = Lin2(σ(DConv17(σ(Lin1(X)))))(6) Zconv = LayerNorm(X+ Dropout(X conv))(7)
-
[7]
Dynamic Merge:Branch outputs are dynamically fused using weights derived from their concatenated features: [Wattn,W conv] = softmax(Linear([Zattn;Z conv]))(8) Zmerge =W attn ⊙Z attn +W conv ⊙Z conv (9)
-
[8]
Final FFN:The fused representation passes through a Feed-Forward Network (FFN): Henc = LayerNorm(Zmerge + Dropout(FFN(Zmerge))) (10) This hybrid encoding robustly aligns the acoustic scene and temporal events into the LLM space. Stage B: User Intent-Aware Refinement.To align the audio representation with the user’s specific instruction, we derive a global...
-
[9]
Dataset Training Data.We utilize all publicly available subsets of the CoTA dataset [11] hosted on Hugging Face, totaling558,423 instruction-tuning samples
Experiment 4.1. Dataset Training Data.We utilize all publicly available subsets of the CoTA dataset [11] hosted on Hugging Face, totaling558,423 instruction-tuning samples. This collection excludes AudioSet and comprises: (1)Environmental Sounds(AudioCaps [12], Clotho [13]); (2)Speech(MELD [14], CoV oST 2 [15]); and (3)Music(MusicBench [16]). The data fol...
2048
-
[10]
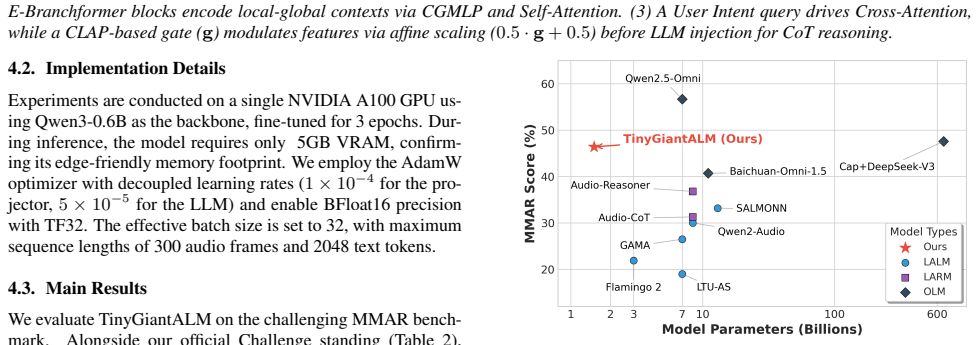
(11B, 40.7%) and approaches the performance of the 671B Caption+DeepSeek-V3 [23] pipeline (47.6%). Specifically in theMix-Music-Speechdomain, TinyGiantALM achieves 58.5%, trailing only the SOTA Qwen2.5-Omni [24], proving that specialized architectural priors can compensate for the lack of massive pre-training scale (see Figure 3). Reasoning Gap vs. Scale....
- [11]
-
[12]
Perception 31.54 39.6044.3043.62 +12.08Speaker Analysis 39.58 41.67 41.6745.83 +6.25
Perception Layer TasksAnomaly Detection 41.1823.5341.18 41.18 0.00Counting 29.29 26.2640.4036.36 +7.07Env. Perception 31.54 39.6044.3043.62 +12.08Speaker Analysis 39.58 41.67 41.6745.83 +6.25
-
[13]
Semantic Layer TasksContent Analysis 45.07 45.39 49.3451.97 +6.90Correlation Analysis 52.0030.00 38.00 50.00 -2.00Emotion & Intention 40.00 46.67 38.3351.67 +11.67Professional Knowledge33.80 38.03 42.2546.48 +12.68
-
[14]
This suggests IQ primes the attention layers, enabling CLAP’s semantic an- chor for precise deduction
Cultural Layer TasksAesthetic Evaluation 37.50 50.00 50.0062.50 +25.00Culture of Speaker 42.31 32.69 44.2357.69 +15.38Imagination 30.00 30.00 30.00 30.00 0.00Music Theory 22.22 15.87 22.2231.75 +9.53 Average Accuracy 38.00 39.70 42.70 46.40 +8.40 adding IQ or the CLAP gate individually yields moderate gains over the Vanilla baseline (38.00%), but their co...
-
[15]
Conclusion In this work, we presented TinyGiantALM, a 1.5B model ex- ploring the trade-offs between efficiency and reasoning depth. While our architecture achieves a competitive 46.40% zero- shot MMAR accuracy, outperforming significantly larger base- lines, we acknowledge a persistent reasoning gap reflected in our 23.77% Rubric score compared to 30B+ fo...
-
[16]
All scientific content, experi- mental design, and results were produced by the author
Use of Generative AI Disclosure Generative AI tools were used for linguistic polishing and preparing illustrative elements. All scientific content, experi- mental design, and results were produced by the author
-
[17]
Z. Ma, R. Xu, Y . Ma, C.-H. H. Yang, B. Li, J. Kim, J. Xu, J. Li, C. Busso, K. Yu, E. S. Chng, and X. Chen, “The interspeech 2026 audio reasoning challenge: Evaluating reasoning process quality for audio reasoning models and agents,” 2026. [Online]. Available: https://arxiv.org/abs/2602.14224
-
[18]
Z. Ma, Y . Ma, Y . Zhuet al., “Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix,” 2025. [Online]. Available: https://arxiv.org/abs/2505.13032
-
[19]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, b. ichter, F. Xia, E. Chi, Q. V . Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” inAdvances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 24 824–24 837. [Onlin...
2022
-
[20]
SALMONN: Towards Generic Hearing Abilities for Large Language Models
C. Tang, W. Yu, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “Salmonn: Towards generic hearing abilities for large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2310.13289
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin, C. Zhou, and J. Zhou, “Qwen2-audio technical report,” 2024. [Online]. Available: https://arxiv.org/abs/2407.10759
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Conformer: Convolution-augmented transformer for speech recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y . Wu, and R. Pang, “Conformer: Convolution-augmented transformer for speech recognition,”
-
[23]
Conformer: Convolution-augmented transformer for speech recognition,
[Online]. Available: https://arxiv.org/abs/2005.08100
-
[24]
E-branchformer: Branchformer with enhanced merging for speech recognition,
K. Kim, F. Wu, Y . Peng, J. Pan, P. Sridhar, K. J. Han, and S. Watanabe, “E-branchformer: Branchformer with enhanced merging for speech recognition,” in2022 IEEE Spoken Language Technology Workshop (SLT), Jan 2023, pp. 84–91
2023
-
[25]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. Mcleavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inProceedings of the 40th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, and J. Scarlett, Eds., vol. 202. PMLR, 23– ...
2023
-
[26]
Hts-at: A hierarchical token-semantic audio transformer for sound classification and detection,
K. Chen, X. Du, B. Zhu, Z. Ma, T. Berg-Kirkpatrick, and S. Dub- nov, “Hts-at: A hierarchical token-semantic audio transformer for sound classification and detection,” inICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), 2022, pp. 646–650
2022
-
[27]
Clap learning audio concepts from natural language supervision,
B. Elizalde, S. Deshmukh, M. A. Ismail, and H. Wang, “Clap learning audio concepts from natural language supervision,” in ICASSP 2023 - 2023 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[28]
Audio- reasoner: Improving reasoning capability in large audio language models,
Z. Xie, M. Lin, Z. Liu, P. Wu, S. Yan, and C. Miao, “Audio- reasoner: Improving reasoning capability in large audio language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, Eds. Suzhou, China: Association for Computational Linguistics, Nov. 202...
2025
-
[29]
AudioCaps: Generating captions for audios in the wild,
C. D. Kim, B. Kim, H. Lee, and G. Kim, “AudioCaps: Generating captions for audios in the wild,” inProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), J. Burstein, C. Doran, and T. Solorio, Eds. Minneapolis, Minnesota: Association f...
2019
-
[30]
Clotho: an audio cap- tioning dataset,
K. Drossos, S. Lipping, and T. Virtanen, “Clotho: an audio cap- tioning dataset,” inICASSP 2020 - 2020 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 736–740
2020
-
[31]
MELD: A multimodal multi-party dataset for emotion recognition in conversations,
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, and R. Mihalcea, “MELD: A multimodal multi-party dataset for emotion recognition in conversations,” inProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, A. Korhonen, D. Traum, and L. M `arquez, Eds. Florence, Italy: Association for Computational Linguistics, Jul...
2019
-
[32]
Covost 2 and massively mul- tilingual speech-to-text translation,
C. Wang, A. Wu, and J. Pino, “Covost 2 and massively mul- tilingual speech-to-text translation,” 2020. [Online]. Available: https://arxiv.org/abs/2007.10310
-
[33]
Mustango: Toward controllable text-to-music generation,
J. Melechovsky, Z. Guo, D. Ghosal, N. Majumder, D. Herremans, and S. Poria, “Mustango: Toward controllable text-to-music generation,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), K. Duh, H. Gomez, and S. Bethard, Eds. Mexico City, M...
2024
-
[34]
S. Ghosh, Z. Kong, S. Kumar, S. Sakshi, J. Kim, W. Ping, R. Valle, D. Manocha, and B. Catanzaro, “Audio flamingo 2: An audio-language model with long-audio understanding and expert reasoning abilities,” 2025. [Online]. Available: https://arxiv.org/abs/2503.03983
-
[35]
Joint audio and speech understanding,
Y . Gong, A. H. Liu, H. Luo, L. Karlinsky, and J. Glass, “Joint audio and speech understanding,” in2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2023, pp. 1– 8
2023
-
[36]
S. Ghosh, S. Kumar, A. Seth, C. K. R. Evuru, U. Tyagi, S. Sakshi, O. Nieto, R. Duraiswami, and D. Manocha, “Gama: A large audio-language model with advanced audio understanding and complex reasoning abilities,” 2024. [Online]. Available: https://arxiv.org/abs/2406.11768
-
[37]
Gpt-4o: The cutting-edge advance- ment in multimodal llm,
R. Islam and O. M. Moushi, “Gpt-4o: The cutting-edge advance- ment in multimodal llm,” inIntelligent Computing, K. Arai, Ed. Cham: Springer Nature Switzerland, 2025, pp. 47–60
2025
-
[38]
Audio- CoT: Exploring chain-of-thought reasoning in large audio lan- guage model,
Z. Ma, Z. Chen, Y . Wanget al., “Audio-cot: Exploring chain-of-thought reasoning in large audio language model,” 2025. [Online]. Available: https://arxiv.org/abs/2501.07246
-
[39]
Baichuan-omni-1.5 technical report,
Y . Li, J. Liu, T. Zhanget al., “Baichuan-omni-1.5 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2501. 15368
2025
-
[40]
DeepSeek-AI, A. Liu, B. Feng, B. Xueet al., “Deepseek-v3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/ 2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Dang, B. Zhang, X. Wang, Y . Chu, and J. Lin, “Qwen2.5-omni technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Gemini: A Family of Highly Capable Multimodal Models
G. Team, R. Anil, S. Borgeaud, J.-B. Alayracet al., “Gemini: A family of highly capable multimodal models,” 2025. [Online]. Available: https://arxiv.org/abs/2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhu, Y . Lv, Y . Wang, D. Guo, H. Wang, L. Ma, P. Zhang, X. Zhang, H. Hao, Z. Guo, B. Yang, B. Zhang, Z. Ma, X. Wei, S. Bai, K. Chen, X. Liu, P. Wang, M. Yang, D. Liu, X. Ren, B. Zheng, R. Men, F. Zhou, B. Yu, J. Yang, L. Yu, J. Zhou, and J. Lin, “Qwen3-omni technical report,” 2025...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.