A Comparison of SSL-Based Feature Extractors and Back-End Classifiers for Spoofing Detection: A Multi-Corpus Training and Cross-Linguistic Analysis
Pith reviewed 2026-06-27 17:59 UTC · model grok-4.3
The pith
Naive scaling of training data degrades spoofing detection performance on ASVspoof 5 due to domain bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through multi-corpus training the empirical analysis exposes a domain bias within the ASVspoof 5 dataset, showing that naive data scaling actively degrades performance. The cross-linguistic analysis reveals that fine-tuning with just 8 hours of target-language data enhances detection robustness. Together these findings emphasize the critical need for domain-aware and language-specific adaptation in spoofing detection.
What carries the argument
Pairing of SSL feature extractors (hierarchical local extraction via ResNet) with attention- and graph-based back-end classifiers under multi-corpus training and cross-linguistic fine-tuning.
If this is right
- Domain-aware data selection is required instead of naive scaling for ASVspoof 5.
- Eight hours of target-language data suffices to improve cross-linguistic robustness.
- Hierarchical local feature extraction and global sequence modeling produce different outcomes across back-ends.
- Evaluation must span multiple corpora to reveal hidden dataset biases.
- Language-specific fine-tuning is essential for consistent detection performance.
Where Pith is reading between the lines
- Similar domain biases may exist in other speech datasets and warrant the same multi-corpus checks.
- Voice biometric systems could benefit from adaptive pipelines that detect and correct for language or domain shifts during deployment.
- The eight-hour fine-tuning result suggests minimal-data adaptation strategies may generalize beyond the tested languages.
- Inconsistent benchmarks risk over- or under-estimating real-world spoofing detection reliability.
Load-bearing premise
Observed performance changes stem from domain bias in ASVspoof 5 and language-specific effects rather than uncontrolled differences in model hyperparameters or evaluation protocols.
What would settle it
Re-train the same models on ASVspoof 5 after isolating and removing suspected domain-biased subsets while holding hyperparameters and protocols fixed, then check whether additional data still degrades equal error rate.
Figures

read the original abstract
Voice biometric systems face growing threats from spoofing attacks, yet the evaluation of detection models remains inconsistent across datasets. To investigate these unpredictable fluctuations, we conduct a comprehensive benchmark of four self-supervised learning feature extractors paired with four back-end classifiers. We compare the hierarchical local feature extraction of ResNet with the global sequence and relational modeling of attention and graph-based back-ends. Through multi-corpus training across three scenarios and six evaluation datasets, our empirical analysis yields two critical findings. First, we expose a domain bias within the ASVspoof 5 dataset, showing that naive data scaling actively degrades performance. Second, our cross-linguistic analysis reveals that fine-tuning with just 8 hours of target-language data enhances detection robustness. Together, these findings emphasize the critical need for domain-aware and language-specific adaptation in spoofing detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks four SSL-based feature extractors paired with four back-end classifiers (ResNet, attention, and graph-based) for spoofing detection. It performs multi-corpus training across three scenarios and evaluates on six datasets, reporting two main empirical findings: naive data scaling degrades performance on ASVspoof 5 due to domain bias, and fine-tuning with only 8 hours of target-language data improves cross-linguistic robustness.
Significance. If the central empirical claims hold after verification of experimental controls, the work would usefully demonstrate the sensitivity of spoofing detectors to domain and language mismatch, supporting the need for domain-aware training strategies. The multi-corpus and cross-linguistic design is a positive aspect of the study design.
major comments (2)
- [Abstract / Methods] Abstract and Methods: The claim that 'naive data scaling actively degrades performance' on ASVspoof 5 is attributed to domain bias, yet the text provides no explicit statement that hyperparameters, learning-rate schedules, loss weighting, batch construction, or train/dev/test splits were held fixed across all scaling conditions and corpus combinations. Without this control, the degradation cannot be isolated from changes in training dynamics.
- [Results] Results: The abstract states empirical findings from multi-corpus training but supplies no error bars, statistical significance tests, or detailed exclusion criteria for the reported performance changes. This weakens assessment of whether the observed degradation and 8-hour fine-tuning gains are reliable.
minor comments (1)
- [Abstract] The abstract refers to 'hierarchical local feature extraction of ResNet' versus 'global sequence and relational modeling of attention and graph-based back-ends' without a table or section clearly mapping the four extractors to the four back-ends.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments below regarding the need for explicit experimental controls and statistical reporting. We will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: The claim that 'naive data scaling actively degrades performance' on ASVspoof 5 is attributed to domain bias, yet the text provides no explicit statement that hyperparameters, learning-rate schedules, loss weighting, batch construction, or train/dev/test splits were held fixed across all scaling conditions and corpus combinations. Without this control, the degradation cannot be isolated from changes in training dynamics.
Authors: We thank the referee for this observation. In the experimental protocol, hyperparameters (including learning rates and schedules), loss weighting, batch construction, and train/dev/test splits were held fixed across all data scaling conditions and corpus combinations to isolate the effect of domain bias. We acknowledge that this was not stated explicitly. We will revise the Methods section to include a dedicated paragraph confirming these controls were maintained throughout the scaling experiments. revision: yes
-
Referee: [Results] Results: The abstract states empirical findings from multi-corpus training but supplies no error bars, statistical significance tests, or detailed exclusion criteria for the reported performance changes. This weakens assessment of whether the observed degradation and 8-hour fine-tuning gains are reliable.
Authors: We agree that error bars, significance testing, and exclusion criteria would strengthen the presentation. Our key configurations were run with multiple random seeds, enabling computation of means and standard deviations. We will update the Results section and figures to report error bars, add statistical significance tests (e.g., paired t-tests) for the degradation and fine-tuning gains, and detail exclusion criteria for datasets and trials in the revised Methods. revision: yes
Circularity Check
Empirical benchmark with no derivation chain or self-referential fitting
full rationale
The paper is a purely empirical study consisting of benchmark comparisons of four SSL feature extractors and four back-end classifiers across multi-corpus training scenarios and six evaluation datasets. No equations, first-principles derivations, or predictive models are presented. All reported findings (domain bias in ASVspoof 5, benefits of 8-hour fine-tuning) are direct experimental outcomes on external public datasets. No parameters are fitted to a subset and then called predictions, no self-citations serve as load-bearing uniqueness theorems, and no ansatzes are smuggled in. The derivation chain is empty by construction; the work contains no mathematical steps that could reduce to their own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
However, advanced spoofing attacks which mimic bona fide users pose serious security risks
Introduction Automatic Speaker Verification (ASV) offers a reliable and con- venient biometric recognition method based on voice charac- teristics. However, advanced spoofing attacks which mimic bona fide users pose serious security risks. To counter these threats, spoofing detection systems, also called countermea- sures (CMs), are increasingly deployed ...
Pith/arXiv arXiv 2026
-
[2]
Models are comprised of two main components: SSL- based feature extractors and back-end classifiers (Figure 1)
SSL-based Spoofing Detection Our approach to spoofing detection leverages the strengths of SSL models to extract robust representations from raw audio data. Models are comprised of two main components: SSL- based feature extractors and back-end classifiers (Figure 1). 2.1. SSL Feature Extractors The model comprises two primary components: a convolutional ...
-
[3]
Datasets and Metrics For training, we use the ASVspoof 5 training set, MLAAD- v3 [16], ASVspoof19 [17], and VCTK [18]
Experimental Setup 3.1. Datasets and Metrics For training, we use the ASVspoof 5 training set, MLAAD- v3 [16], ASVspoof19 [17], and VCTK [18]. To support multi- corpus evaluation, the ASVspoof 5 validation set is replaced Table 2:Performance of back-end classifiers with the XLSR feature extractor in three training cases (best results highlighted in bold, ...
2021
-
[4]
We begin by evaluating four distinct back-ends paired with an XLSR feature extractor (Sec
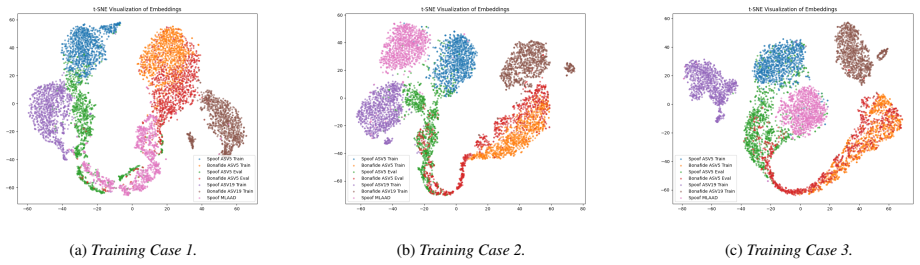
Results and Analysis Our experimental framework systematically benchmarks the combination between various Self-Supervised Learning (SSL) front-ends and back-end classifiers. We begin by evaluating four distinct back-ends paired with an XLSR feature extractor (Sec. 4.1), followed by qualitative results of the learned embed- ding space via visualization (Se...
-
[5]
Our findings show the ResNet classifier to be the most effective
Conclusions In this study, we conduct a comprehensive evaluation of spoof- ing detection models, focusing on the integration of SSL-based feature extractors and back-end classifiers across various train- ing and evaluation scenarios. Our findings show the ResNet classifier to be the most effective. It achieves consistently the lowest average EER. Our anal...
-
[6]
This work was financially supported by ANR BRUEL (ANR-22-CE39-0009)
Acknowledgements This work was performed using HPC resources from GENCI- IDRIS. This work was financially supported by ANR BRUEL (ANR-22-CE39-0009)
-
[7]
ASVspoof 5: crowd- sourced speech data, deepfakes, and adversarial attacks at scale,
X. Wang, H. Delgado, H. Tak, J. weon Jung, H. jin Shim, M. Todisco, I. Kukanov, X. Liu, M. Sahidullah, T. H. Kinnunen, N. Evans, K. A. Lee, and J. Yamagishi, “ASVspoof 5: crowd- sourced speech data, deepfakes, and adversarial attacks at scale,” inASVspoof, 2024
2024
-
[8]
AASIST: audio anti-spoofing using integrated spectro- temporal graph attention networks,
J. Jung, H. Heo, H. Tak, H. Shim, J. S. Chung, B. Lee, H. Yu, and N. Evans, “AASIST: audio anti-spoofing using integrated spectro- temporal graph attention networks,” inICASSP, 2022
2022
-
[9]
A conformer-based classifier for variable-length utterance process- ing in anti-spoofing,
E. Rosello, A. G. Alan ´ıs, A. M. Gomez, and A. M. Peinado, “A conformer-based classifier for variable-length utterance process- ing in anti-spoofing,” inInterspeech, 2023
2023
-
[10]
Exploring WavLM back-ends for speech spoofing and deepfake detection,
T. Stourbe, V . Miara, T. Lepage, and R. Dehak, “Exploring WavLM back-ends for speech spoofing and deepfake detection,” inASVspoof 2024, 2024
2024
-
[11]
Audio deepfake detection with self- supervised xls-r and sls classifier
Q. Zhang, S. Wen, and T. Hu, “Audio deepfake detection with self- supervised xls-r and sls classifier.” Association for Computing Machinery, 2024
2024
-
[12]
Xlsr-mamba: A dual-column bidirec- tional state space model for spoofing attack detection,
Y . Xiao and R. K. Das, “Xlsr-mamba: A dual-column bidirec- tional state space model for spoofing attack detection,”IEEE Sig- nal Processing Letters, 2025
2025
-
[13]
Aasist: Audio anti-spoofing using in- tegrated spectro-temporal graph attention networks,
J.-w. Jung, H.-S. Heo, H. Tak, H.-j. Shim, J. S. Chung, B.-J. Lee, H.-J. Yu, and N. Evans, “Aasist: Audio anti-spoofing using in- tegrated spectro-temporal graph attention networks,” inICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022
2022
-
[14]
End-to-end anti-spoofing with rawnet2,
H. Tak, J. Patino, M. Todisco, A. Nautsch, N. Evans, and A. Larcher, “End-to-end anti-spoofing with rawnet2,” inIEEE In- ternational Conference on Acoustics, Speech and Signal Process- ing, ICASSP 2021, Toronto, ON, Canada, June 6-11. IEEE, 2021, pp. 6369–6373
2021
-
[15]
ASVspoof 5 challenge: advanced resnet architectures for robust voice spoofing detection,
A.-T. Dao, M. Rouvier, and D. Matrouf, “ASVspoof 5 challenge: advanced resnet architectures for robust voice spoofing detection,” inASVspoof, 2024
2024
-
[16]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[17]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y . Y . Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” inCVPR, 2021
2021
-
[18]
WavLM: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wu, Z. Yang, T. Yao, Y . Zhang, S. Liu, J. Li, M. Zhou, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, 2022
2022
-
[19]
XLS-R: self-supervised cross-lingual speech representation learning at scale,
A. Babu, C. Wang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P. von Platen, Y . Saraf, J. Pino, A. Baevski, A. Con- neau, and M. Auli, “XLS-R: self-supervised cross-lingual speech representation learning at scale,” inInterspeech, 2022
2022
-
[20]
Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data augmentation,
T. Hemlata, T. Massimiliano, W. Xin, J. Jee-weon, Y . Junichi, and N. Evans, “Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data augmentation,” inOdyssey, 2022
2022
-
[21]
ASVspoof 2021: Towards spoofed and deepfake speech de- tection in the wild,
X. Liu, X. Wang, M. Sahidullah, J. Patino, H. Delgado, T. Kin- nunen, M. Todisco, J. Yamagishi, N. Evans, A. Nautsch, and K. A. Lee, “ASVspoof 2021: Towards spoofed and deepfake speech de- tection in the wild,”IEEE ACM Trans. Audio Speech Lang. Pro- cess., 2023
2021
-
[22]
Mlaad: The multi- language audio anti-spoofing dataset,
N. M. M ¨uller, P. Kawa, W. H. Choong, E. Casanova, E. G ¨olge, T. M¨uller, P. Syga, P. Sperl, and K. B¨ottinger, “Mlaad: The multi- language audio anti-spoofing dataset,” in2024 International Joint Conference on Neural Networks (IJCNN), 2024
2024
-
[23]
ASVspoof 2019: Future horizons in spoofed and fake audio detection,
M. Todisco, X. Wang, V . Vestman, M. Sahidullah, H. Delgado, A. Nautsch, J. Yamagishi, N. Evans, T. H. Kinnunen, and K. A. Lee, “ASVspoof 2019: Future horizons in spoofed and fake audio detection,” inInterspeech, 2019
2019
-
[24]
Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (ver- sion 0.92),
J. Yamagishi, C. Veaux, and K. MacDonald, “Cstr vctk corpus: English multi-speaker corpus for cstr voice cloning toolkit (ver- sion 0.92),”University of Edinburgh. The Centre for Speech Tech- nology Research (CSTR), 2019
2019
-
[25]
ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection,
J. Yamagishi, X. Wang, M. Todisco, M. Sahidullah, J. Patino, A. Nautsch, X. Liu, K. A. Lee, T. Kinnunen, N. Evans, and H. Delgado, “ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection,” inASVspoof 2021, 2021
2021
-
[26]
For: A dataset for synthetic speech detection,
R. Reimao and V . Tzerpos, “For: A dataset for synthetic speech detection,” in2019 International Conference on Speech Technol- ogy and Human-Computer Dialogue, SpeD 2019, Timisoara, Ro- mania, October 10-12, C. Burileanu and H. Teodorescu, Eds., 2019
2019
-
[27]
HABLA: A dataset of latin american spanish accents for voice anti-spoofing,
P. A. T. Fl´orez, R. Manrique, and B. P. Nunes, “HABLA: A dataset of latin american spanish accents for voice anti-spoofing,” inIn- terspeech. ISCA, 2023, pp. 1963–1967
2023
-
[28]
CFAD: A chinese dataset for fake audio detection,
H. Ma, J. Yi, C. Wang, X. Yan, J. Tao, T. Wang, S. Wang, and R. Fu, “CFAD: A chinese dataset for fake audio detection,”Speech Commun., vol. 164, p. 103122, 2024
2024
-
[29]
Exploring Self-supervised Embeddings and Syn- thetic Data Augmentation for Robust Audio Deepfake Detection,
J. M. Mart ´ın-Do˜nas, A. ´Alvarez, E. Rosello, A. M. Gomez, and A. M. Peinado, “Exploring Self-supervised Embeddings and Syn- thetic Data Augmentation for Robust Audio Deepfake Detection,” inInterspeech, 2024
2024
-
[30]
MUSAN: A music, speech, and noise corpus,
D. Snyder, G. Chen, and D. Povey, “MUSAN: A music, speech, and noise corpus,”ArXiv, 2015
2015
-
[31]
A study on data augmentation of reverberant speech for robust speech recognition,
T. Ko, V . Peddinti, D. Povey, M. L. Seltzer, and S. Khudanpur, “A study on data augmentation of reverberant speech for robust speech recognition,” inICASSP, 2017
2017
-
[32]
Adam: A method for stochastic opti- mization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic opti- mization,” inICLR, Y . Bengio and Y . LeCun, Eds., 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.