Multi-task LLMs for Bug Classification: Efficient Inference with Auxiliary Decoding Heads
Pith reviewed 2026-06-27 15:44 UTC · model grok-4.3
The pith
A multi-task LLM with auxiliary decoding heads performs line-level bug localization on full files using one generated token.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
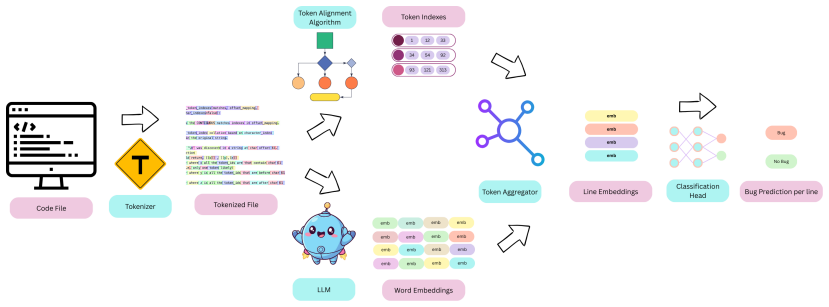
The central claim is that a token alignment algorithm, a multi-task LLM for bug localization (MLC), and an optimized training recipe for multi-line prediction together produce state-of-the-art line-level bug localization performance among comparable setups when given full-file context, while matching the accuracy of agentic methods on Defects4J and PypiBugs yet requiring only a single generated token per file.
What carries the argument
The multi-task LLM for bug localization (MLC) equipped with auxiliary decoding heads, enabled by a token alignment algorithm that maps outputs back to original source lines.
If this is right
- The method reaches state-of-the-art line-level bug localization among setups that use full-file context.
- Performance on Defects4J and PypiBugs becomes comparable to agentic approaches.
- Inference requires only one generated token per file, cutting latency by orders of magnitude.
- The model shows strong generalization when evaluated on a small out-of-domain Python dataset.
Where Pith is reading between the lines
- The same auxiliary-head design could be reused for other token-level code tasks such as vulnerability or smell detection without retraining an entire model.
- Because only one token is produced, the approach could be inserted directly into real-time IDE checkers or CI pipelines where agentic methods are currently too slow.
- If the token alignment step proves robust across tokenizers, the technique may transfer to non-Python languages with minimal additional engineering.
- The efficiency gain opens the possibility of running bug localization at scale over large repositories rather than on isolated files.
Load-bearing premise
The token alignment algorithm can map the model's output tokens back to the correct original source lines without introducing errors that would break line-level accuracy.
What would settle it
A direct test on the Defects4J benchmark in which the single-token predictions, after alignment, fail to identify the known buggy lines at the accuracy level claimed for the method.
Figures

read the original abstract
The rapid adoption of LLM-powered code generation has dramatically accelerated software development, yet effective verification methods remain severely underdeveloped. Existing bug localization techniques are either prohibitively expensive, requiring minutes of agentic reasoning and thousands of generated tokens per file, and/or operate at coarse function-level granularity unsuitable for precise debugging. While works that focus on line-level granularity and are more light-weight are often limited in their performance or context size. We introduce a novel line-level bug localization approach that addresses these limitations through three key contributions: (1) a token alignment algorithm that overcomes fundamental tokenization challenges in previous work, (2) a lightweight multi-task LLM for bug localization (MLC) enabling efficient line-level bug classification, and (3) an optimized training recipe for multi-line prediction. Our method achieves state-of-the-art performance among similar setups on line-level bug localization with full-file context. At the same time we reach comparable performance to agentic approaches on Defects4J and PypiBugs benchmarks while reducing inference latency by orders of magnitudes, requiring only a single generated token per file. We further demonstrate strong generalization by introducing and evaluating on a small out-of-domain evaluation datasets in Python. We will open source our code, models, and datasets upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a multi-task LLM (MLC) with auxiliary decoding heads for line-level bug localization in full-file context. It proposes a token alignment algorithm to map subword tokens back to source lines, a lightweight multi-task architecture for efficient inference, and an optimized training recipe for multi-line bug prediction. The central claims are state-of-the-art performance among similar setups on line-level localization, performance comparable to agentic methods on Defects4J and PypiBugs while requiring only a single generated token per file, and strong generalization on a small out-of-domain Python dataset. The authors commit to open-sourcing code, models, and datasets upon acceptance.
Significance. If the performance claims hold and the token alignment is shown to be reliable, the work would offer a practical advance in software engineering by enabling orders-of-magnitude faster line-level bug localization than agentic approaches. The efficiency gain (single-token inference) combined with full-file context and the open-sourcing pledge could support broader adoption and reproducibility in the field.
major comments (1)
- [§3.2] §3.2: The token alignment algorithm is presented as overcoming fundamental tokenization challenges and is load-bearing for both the line-level F1 scores and the single-generated-token efficiency claim, yet the manuscript reports no ablation studies or independent verification on edge cases such as tokens crossing line boundaries, Unicode characters in identifiers, or bugs spanning non-contiguous lines. Without such validation (e.g., manual audit of alignment accuracy on held-out files), the quantitative claims cannot be fully assessed.
minor comments (1)
- [Abstract] Abstract: The abstract asserts SOTA and comparable performance without supplying any numerical metrics, dataset sizes, or ablation summaries, which reduces immediate readability even though the full paper presumably contains these details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: [§3.2] §3.2: The token alignment algorithm is presented as overcoming fundamental tokenization challenges and is load-bearing for both the line-level F1 scores and the single-generated-token efficiency claim, yet the manuscript reports no ablation studies or independent verification on edge cases such as tokens crossing line boundaries, Unicode characters in identifiers, or bugs spanning non-contiguous lines. Without such validation (e.g., manual audit of alignment accuracy on held-out files), the quantitative claims cannot be fully assessed.
Authors: We agree that the token alignment procedure is central to the reported line-level results and that explicit validation on edge cases would increase confidence in the claims. The current manuscript relies on end-to-end benchmark performance as implicit evidence, but this does not substitute for targeted checks. In the revised version we will add, in §3.2, both an ablation isolating alignment accuracy and a manual audit of alignment correctness on a random sample of held-out files, explicitly covering tokens that cross line boundaries, identifiers containing Unicode, and bugs that span non-contiguous lines. revision: yes
Circularity Check
No circularity: empirical ML contributions with no derivations or self-referential fits
full rationale
The paper introduces three contributions—an empirical token alignment algorithm, a multi-task LLM architecture (MLC), and a training recipe—for line-level bug localization. These are presented as engineering and modeling choices evaluated on benchmarks (Defects4J, PypiBugs, out-of-domain sets). No equations, parameter-fitting steps, or predictions are described that reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems. The performance claims rest on reported experimental metrics rather than any closed derivation chain. The token alignment procedure is a stated algorithmic contribution whose correctness is an empirical assumption, not a mathematical identity derived from the model outputs themselves. This is a standard non-circular empirical paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
The FIL Hypothesis: Inductive Biases Help with Kernel Engineering
The FIL Hypothesis claims that inductive biases outperform purely data-driven methods on GPU programming tasks with non-trivial feedback loops.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[2]
Daniel Han, Michael Han and Unsloth team , title =
-
[3]
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin L...
2020
-
[4]
, booktitle=
Abreu, Rui and Zoeteweij, Peter and Van Gemund, Arjan J.c. , booktitle=. An Evaluation of Similarity Coefficients for Software Fault Localization , year=
-
[5]
ArXiv , year=
Large Language Models in Fault Localisation , author=. ArXiv , year=
-
[6]
ICLR , year=
CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis , author=. ICLR , year=
-
[7]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[9]
2021 , eprint=
Self-Supervised Bug Detection and Repair , author=. 2021 , eprint=
2021
-
[10]
Defects4J: A database of existing faults to enable controlled testing studies for Java programs,
Just, Ren\'. Defects4J: a database of existing faults to enable controlled testing studies for Java programs , year =. Proceedings of the 2014 International Symposium on Software Testing and Analysis , pages =. doi:10.1145/2610384.2628055 , abstract =
-
[11]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[12]
2024 , eprint=
Generating Code World Models with Large Language Models Guided by Monte Carlo Tree Search , author=. 2024 , eprint=
2024
-
[13]
ArXiv , year=
MarsCode Agent: AI-native Automated Bug Fixing , author=. ArXiv , year=
-
[14]
ArXiv , year=
OrcaLoca: An LLM Agent Framework for Software Issue Localization , author=. ArXiv , year=
-
[15]
ArXiv , year=
SweRank: Software Issue Localization with Code Ranking , author=. ArXiv , year=
-
[16]
ArXiv , year=
AgentFL: Scaling LLM-based Fault Localization to Project-Level Context , author=. ArXiv , year=
-
[17]
2025 , eprint=
Fault Localization via Fine-tuning Large Language Models with Mutation Generated Stack Traces , author=. 2025 , eprint=
2025
-
[18]
2024 , eprint=
Impact of Large Language Models of Code on Fault Localization , author=. 2024 , eprint=
2024
-
[19]
2025 IEEE/ACM 33rd International Conference on Program Comprehension (ICPC) , year=
LLM-BL: Large Language Models are Zero-Shot Rankers for Bug Localization , author=. 2025 IEEE/ACM 33rd International Conference on Program Comprehension (ICPC) , year=
2025
-
[20]
2025 25th International Conference on Software Quality, Reliability, and Security Companion (QRS-C) , year=
Empirical Evaluation of LLMs for Automated Program Fault Localisation , author=. 2025 25th International Conference on Software Quality, Reliability, and Security Companion (QRS-C) , year=
2025
-
[21]
2023 , eprint=
Large Language Models for Test-Free Fault Localization , author=. 2023 , eprint=
2023
-
[22]
ArXiv , year=
Improving LLM-Based Fault Localization with External Memory and Project Context , author=. ArXiv , year=
-
[23]
2025 , eprint=
Leveraging Large Language Model for Information Retrieval-based Bug Localization , author=. 2025 , eprint=
2025
-
[24]
2026 , eprint=
Towards Explorative IRBL: Combining Semantic Retrieval with LLM-driven Iterative Code Exploration , author=. 2026 , eprint=
2026
-
[25]
2025 , eprint=
LocAgent: Graph-Guided LLM Agents for Code Localization , author=. 2025 , eprint=
2025
-
[26]
2025 , eprint=
FlexFL: Flexible and Effective Fault Localization with Open-Source Large Language Models , author=. 2025 , eprint=
2025
-
[27]
Mehrpour, Sahar and LaToza, Thomas D. , title=. Empirical Software Engineering , year=. doi:10.1007/s10664-022-10232-4 , url=
-
[28]
Eric and Gao, Ruizhi and Li, Yihao and Abreu, Rui and Wotawa, Franz , journal=
Wong, W. Eric and Gao, Ruizhi and Li, Yihao and Abreu, Rui and Wotawa, Franz , journal=. A Survey on Software Fault Localization , year=
-
[29]
2024 , eprint=
An Empirical Study of Static Analysis Tools for Secure Code Review , author=. 2024 , eprint=
2024
-
[30]
2025 , eprint=
KernelBench: Can LLMs Write Efficient GPU Kernels? , author=. 2025 , eprint=
2025
-
[31]
2025 , eprint=
Security and Quality in LLM-Generated Code: A Multi-Language, Multi-Model Analysis , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[33]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[34]
2025 , eprint=
Gemini: A Family of Highly Capable Multimodal Models , author=. 2025 , eprint=
2025
-
[35]
2025 , eprint=
OpenHands: An Open Platform for AI Software Developers as Generalist Agents , author=. 2025 , eprint=
2025
-
[36]
2024 , eprint=
Agentless: Demystifying LLM-based Software Engineering Agents , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.