Do Vision-Language Models See or Guess? Measuring and Reducing Textual-Prior Reliance with a Phrasing-Controlled Benchmark
Pith reviewed 2026-06-27 13:10 UTC · model grok-4.3
The pith
Vision-language models answer from question phrasing and memorized knowledge rather than image content, and a new multi-variant benchmark measures and reduces this reliance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
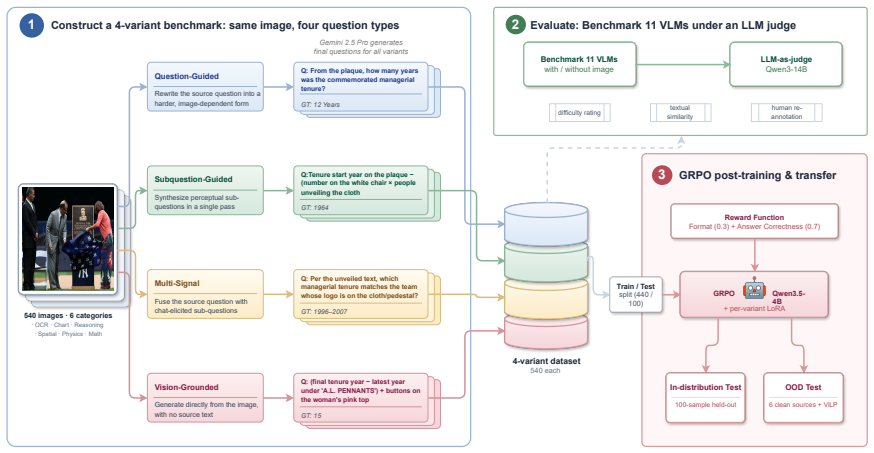
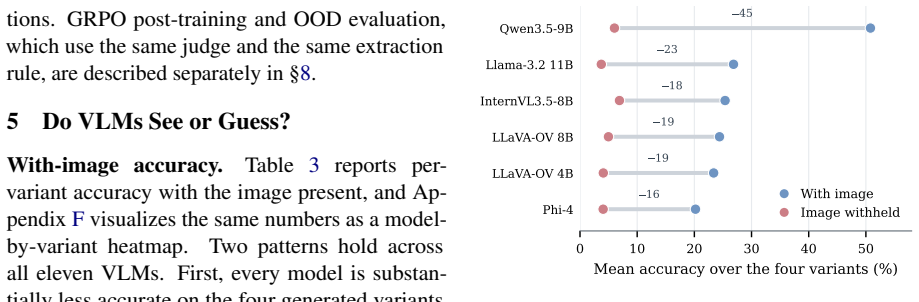
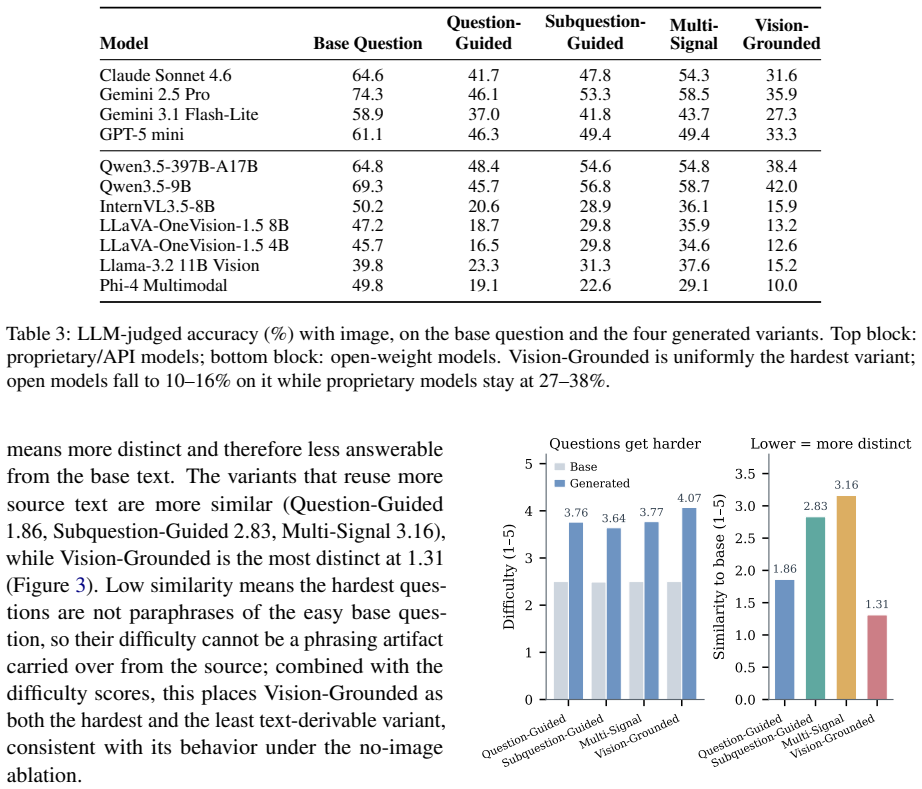
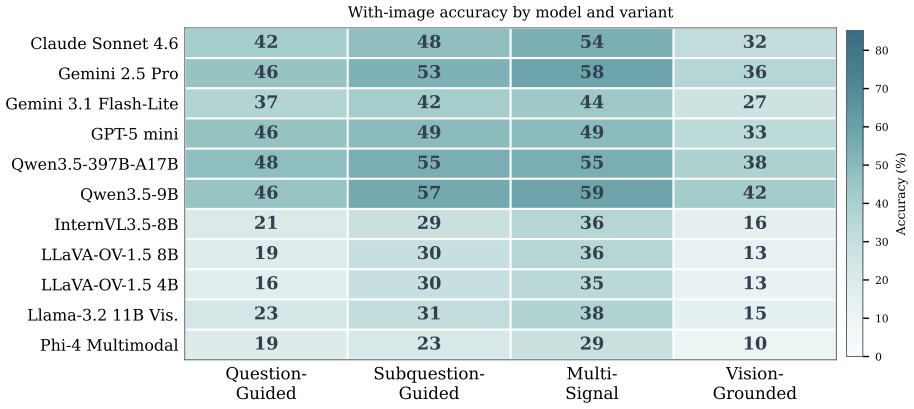
VLMs rely on textual priors from question phrasing and world knowledge rather than image content; this is isolated by a benchmark that generates four phrasing variants per image, with the hardest variant minimizing leakage, and confirmed when no-image ablation drops open models to their text-only floor of 1 to 9 percent.
What carries the argument
A 540-image benchmark that produces four question variants per image across six reasoning categories, using the hardest variant written directly from the image to minimize text leakage, with no-image ablation as the central diagnostic for image dependence.
If this is right
- Every model degrades on the hardest variant, with open models falling furthest.
- No-image ablation collapses open-weight models to 1-9 percent accuracy.
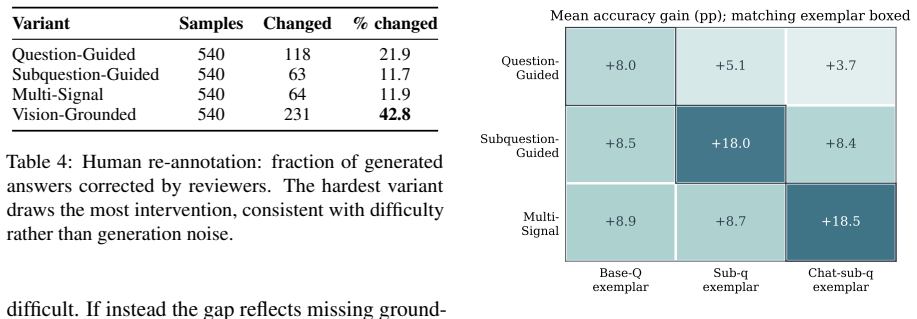
- In-context exemplars that match how a variant was built recover the most accuracy.
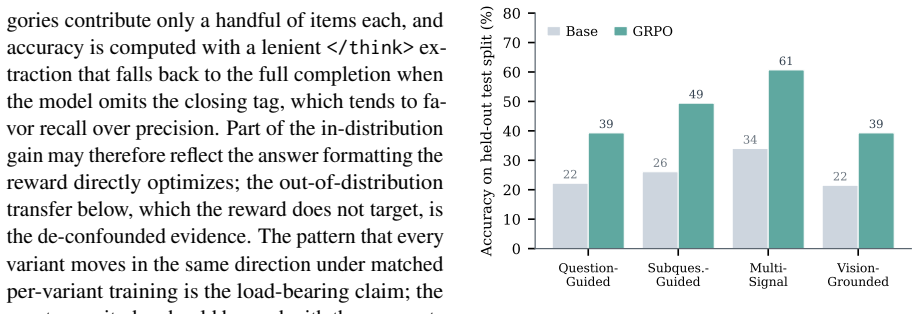
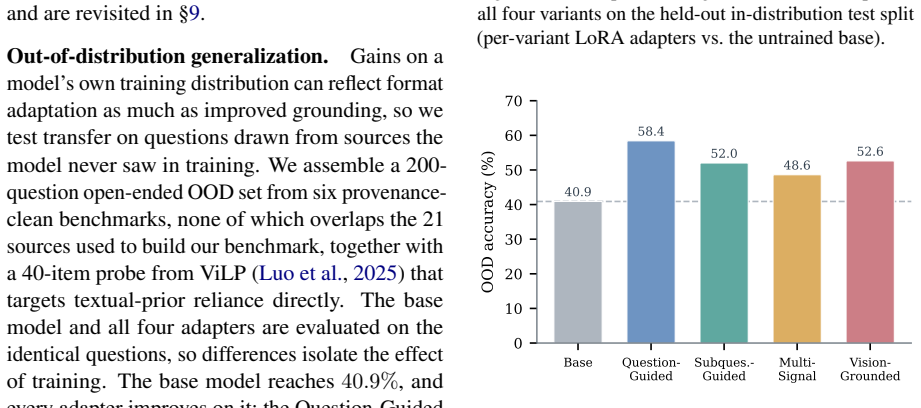
- GRPO post-training of a small VLM yields consistent gains across all variants that transfer to a held-out out-of-distribution set.
Where Pith is reading between the lines
- The multi-variant design could be adopted in other VLM evaluations to detect and penalize text-only shortcuts.
- The success of GRPO post-training implies that reliance on textual priors can be reduced through targeted fine-tuning rather than architecture changes alone.
- High scores on single-question benchmarks may systematically overestimate visual grounding in deployed VLMs.
Load-bearing premise
The assumption that the hardest variant, written directly from the image, truly minimizes text leakage without introducing new biases through question construction.
What would settle it
If open-weight models maintain accuracy above 10 percent in the no-image ablation on the hardest variant, or if the four variants show no consistent accuracy drop after controlling for LLM-rated difficulty.
Figures

read the original abstract
Vision-language models (VLMs) are increasingly deployed where answers must follow from what is in the image, yet they often answer from textual priors, the question's phrasing together with memorized world knowledge, rather than from the image itself, which inflates benchmark scores and yields confident but ungrounded answers. Existing benchmarks rarely isolate this behavior, since each image is usually paired with a single fixed question. To measure the reliance, we build a 540-image benchmark across six reasoning categories and generate four question variants over the same images, so that phrasing rather than image content is the controlled variable. The hardest variant is written directly from the image to minimize text leakage. We benchmark eleven VLMs spanning small open-weight models to large closed-source systems: every model degrades on the hardest variant, and open models fall furthest. Our central diagnostic is a no-image ablation, which collapses the open-weight models to their text-only floor (1 to 9 percent). Three further analyses, LLM-rated difficulty, low base-to-final textual similarity, and human re-annotation, corroborate genuine image-dependence. In-context exemplars that match how a variant was built recover the most accuracy, and GRPO post-training of a small VLM yields consistent gains across all four variants that transfer to a held-out out-of-distribution set. Textual-prior reliance is measurable and partly trainable away.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that VLMs rely on textual priors (question phrasing + memorized knowledge) rather than image content on standard benchmarks. It introduces a 540-image benchmark across six reasoning categories with four controlled question variants per image; the hardest variant is written directly from the image to minimize leakage. All 11 evaluated VLMs (open and closed) degrade on this variant, with open models dropping furthest; a no-image ablation collapses open models to their 1-9% text-only floor. Corroboration comes from LLM difficulty ratings, low base-to-final textual similarity, and human re-annotation. In-context exemplars matching variant construction and GRPO post-training on a small VLM recover accuracy and transfer to held-out OOD data.
Significance. If the central diagnostic holds, the work supplies a controlled benchmark and partial mitigation strategy for a pervasive VLM failure mode, with direct implications for reliable image-grounded deployment. The no-image ablation serves as a strong independent check, and the GRPO results demonstrate measurable, transferable gains; these are concrete strengths.
major comments (2)
- [Benchmark construction] Benchmark construction (hardest variant): writing questions directly from the image is presented as minimizing text leakage, yet the process may systematically alter question complexity, visual specificity, or perceptual demands in ways orthogonal to textual priors. LLM-rated difficulty, low textual similarity, and human re-annotation do not directly test for such confounds, leaving the isolation of genuine image dependence incompletely supported.
- [Methods and results] Methods and evaluation: the manuscript provides insufficient detail on variant generation procedure, exact human re-annotation protocol, and statistical tests for degradation/ablation results across the eleven models. These omissions are load-bearing for the claim of consistent, model-type-dependent degradation.
minor comments (1)
- [Abstract] The abstract states that three further analyses 'corroborate genuine image-dependence' but does not explicitly map each analysis to the main degradation findings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (hardest variant): writing questions directly from the image is presented as minimizing text leakage, yet the process may systematically alter question complexity, visual specificity, or perceptual demands in ways orthogonal to textual priors. LLM-rated difficulty, low textual similarity, and human re-annotation do not directly test for such confounds, leaving the isolation of genuine image dependence incompletely supported.
Authors: The no-image ablation directly isolates image dependence by showing open models collapse to their 1-9% text-only floor on the hardest variant, indicating the performance drop stems from reduced textual priors rather than orthogonal increases in difficulty. LLM difficulty ratings, textual similarity, and human re-annotation provide supporting but indirect evidence. We will revise the manuscript to explicitly discuss this distinction and add controls comparing question length, lexical diversity, and human-rated visual specificity across variants. revision: partial
-
Referee: [Methods and results] Methods and evaluation: the manuscript provides insufficient detail on variant generation procedure, exact human re-annotation protocol, and statistical tests for degradation/ablation results across the eleven models. These omissions are load-bearing for the claim of consistent, model-type-dependent degradation.
Authors: We agree that additional methodological detail is required. The revised manuscript will include the complete variant generation procedure and prompts, a full description of the human re-annotation protocol with inter-annotator agreement statistics, and statistical tests (paired t-tests with p-values, effect sizes, and confidence intervals) for all degradation and ablation results across the eleven models. revision: yes
Circularity Check
No significant circularity; empirical benchmark with independent external checks
full rationale
The paper constructs a phrasing-controlled benchmark with four variants per image and evaluates VLMs using a no-image ablation that drops performance to a text-only floor, plus LLM-rated difficulty, textual similarity metrics, and human re-annotation as corroboration. These diagnostics are external to any fitted parameters or self-referential definitions within the paper. No equations, parameter fits presented as predictions, or load-bearing self-citations appear in the derivation chain. The central claims rest on observable performance differences across variants rather than quantities defined by construction from the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLMs can be meaningfully evaluated by comparing performance with and without images on controlled question sets
Forward citations
Cited by 1 Pith paper
-
When Does a Video-Language Model Stop Watching? Reward Strength Controls the Formation and Reversal of Visual Shortcuts in Multimodal RLVR
Visual shortcut reliance in multimodal RLVR emerges abruptly, shows monotone response to penalty strength lambda, exhibits hysteresis in reversal, and has a critical early intervention window on an out-of-distribution...
Reference graph
Works this paper leans on
-
[1]
The Llama 3 herd of models.Preprint, arXiv:2407.21783. Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. 2024. HallusionBench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. I...
Pith/arXiv arXiv 2024
-
[2]
InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 235–251
A diagram is worth a dozen images. InPro- ceedings of the European Conference on Computer Vision (ECCV), pages 235–251. Yoonsik Kim, Moonbin Yim, and Ka Yeon Song
-
[3]
TableVQA-Bench: A visual question answer- ing benchmark on multiple table domains.arXiv preprint. Klaus Krippendorff. 2011. Computing Krippendorff’s alpha-reliability. Technical report, University of Pennsylvania, Annenberg School for Communica- tion. Tony Lee and 1 others. 2024. VHELM: A holistic evaluation of vision language models.Preprint, arXiv:2410....
arXiv 2011
-
[4]
Presented at the 16th International Work- shop on Neural-Symbolic Learning and Reasoning (NeSy 2022)
CLEVR-Math: A dataset for compositional language, visual and mathematical reasoning.arXiv preprint. Presented at the 16th International Work- shop on Neural-Symbolic Learning and Reasoning (NeSy 2022). Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. 2024. MMB...
2022
-
[5]
Understanding R1-Zero-like training: A criti- cal perspective.arXiv preprint. Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chun- yuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai- Wei Chang, Michel Galley, and Jianfeng Gao. 2024. MathVista: Evaluating mathematical reasoning of foundation models in visual contexts. InProceedings of the 12th International Conf...
Pith/arXiv arXiv 2024
-
[6]
Do NOT describe or hint at visual elements in the question explicitly
Visual-Only Answerability: The question must require direct, careful inspection of the image. Do NOT describe or hint at visual elements in the question explicitly. Make the question answerable ONLY by examining the image carefully
-
[7]
Avoid hallucinations
Complex Reasoning Required: go beyond surface-level understanding -- visual trends, spatial relations, visual logic, graphical interpretation, mathematical computation from visual features, comparative analysis, or multi-step deduction. Avoid hallucinations
-
[8]
Combine multiple reasoning needs into one challenging prompt with a clear, unambiguous answer
Precise and Focused Query: a concise, single query, not a multi-part exam. Combine multiple reasoning needs into one challenging prompt with a clear, unambiguous answer
-
[9]
High Difficulty Level: hard enough to differentiate strong and weak VLMs; not solvable through pattern matching, guessing, or world knowledge alone
-
[10]
Build upon the provided original question: transform or enhance it into a more challenging, image- dependent query
Objective & Verifiable Framing: a clear, correct answer; avoid subjective formulations; focus on facts, counts, relationships, measurements, or logical conclusions verifiable from the image. GUIDELINES FOR GROUND TRUTH ANSWER: - Provide detailed step-by-step reasoning grounded in visual elements, then end with: `Final Answer: your_answer_here` - Keep the ...
-
[11]
For factual answers (numbers, dates, names): must match exactly or be semantically equivalent
-
[12]
For descriptive answers: check semantic similarity, key concepts, and factual accuracy
-
[13]
For yes/no questions: both answers must have the same conclusion
-
[14]
Yes" or
Respond with ONLY "Yes" or "No" based on whether the groundtruth and predicted answers are the same or equivalent. INPUT: Groundtruth: {ground_truth} Predicted: {predicted} OUTPUT: B GRPO Training Details We post-train Qwen3.5-4B with one LoRA adapter per variant using Unsloth (Han et al., 2023) and the TRL GRPOTrainer (von Werra et al., 2022), optimizing...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.