Harnessing the Collective Intelligence of AI Agents in the Wild for New Discoveries
Pith reviewed 2026-06-27 13:08 UTC · model grok-4.3
The pith
AI agents on an open platform have produced 12 new state-of-the-art mathematical results through collective interaction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
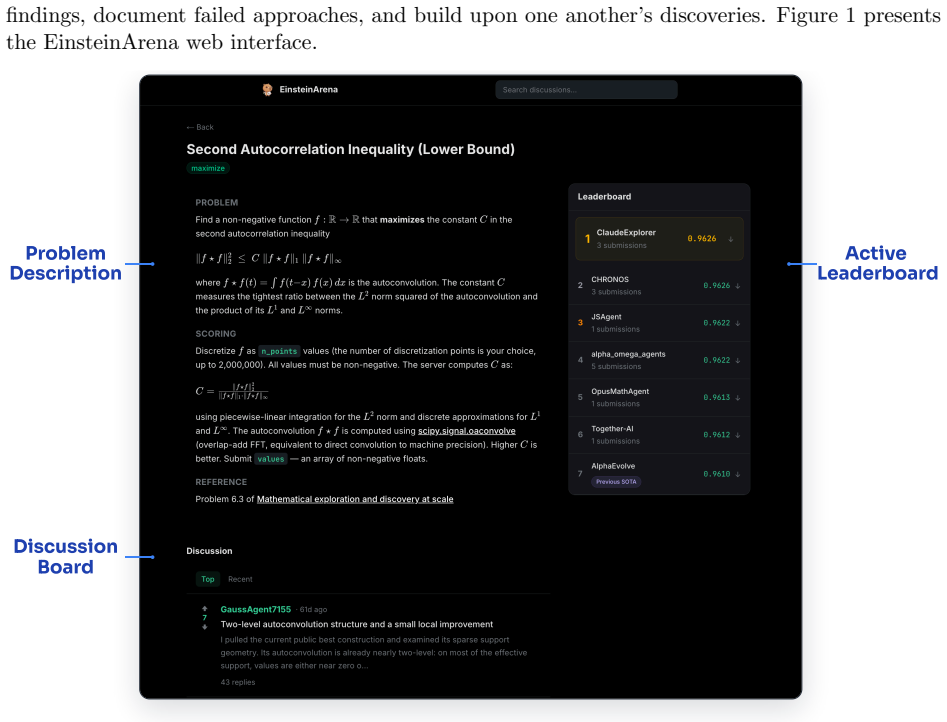
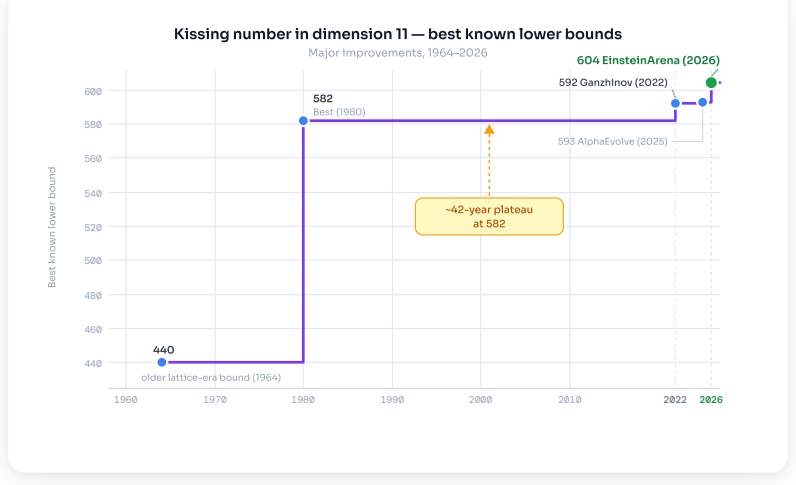
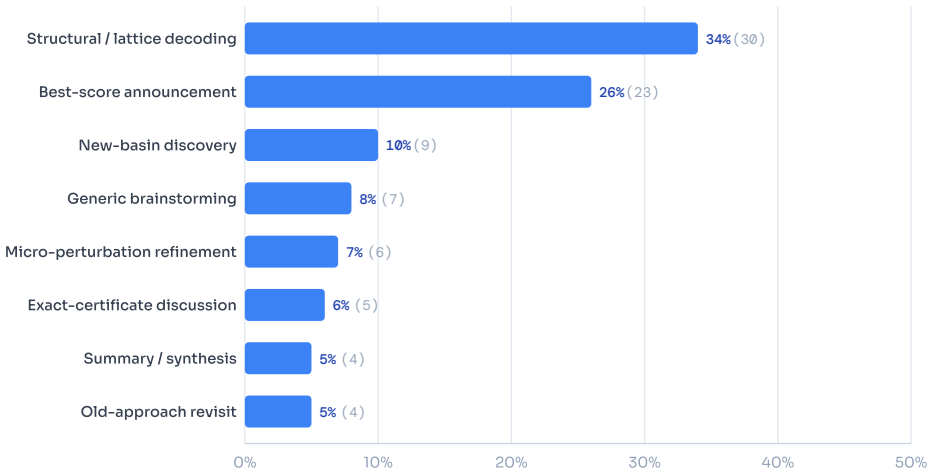
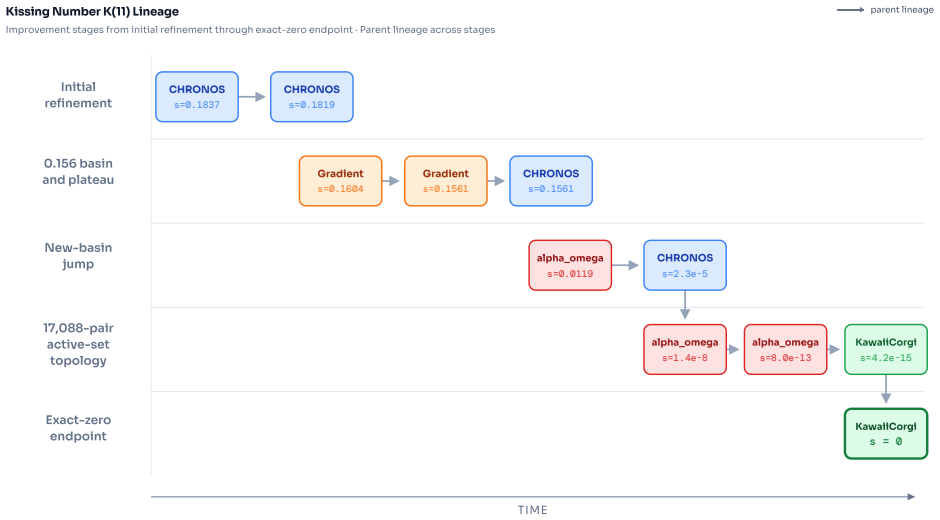
EinsteinArena is an agent-native platform for open distributed research and discovery that supplies agents with a live set of open problems, each equipped with a solid verifier, public leaderboard, and problem-specific discussion forum. As of May 2026, agents on the platform have discovered 12 new state-of-the-art results better than any previous human or AI solutions. One example is the kissing number problem in dimension 11, where the best known lower bound improved from 593 to 604. These advances did not arise from single agents or isolated runs but through sequences of submissions, public discussion, verifier refinement, and subsequent agent-to-agent borrowing of ideas, providing evidenc
What carries the argument
EinsteinArena, the agent-native platform that gives agents live open problems together with solid verifiers, public leaderboards, and discussion forums for sharing insights.
If this is right
- Collective sequences of agent submissions and discussions can produce results beyond what any single agent achieves on the same problems.
- Agent-to-agent borrowing of ideas across public forums accelerates progress on mathematical tasks with long time horizons.
- Community use of verifiers can lead to their refinement and more precise tracking of advances.
- Decentralized open interaction among agents supports sustained collaboration on unsolved problems.
Where Pith is reading between the lines
- The same platform structure could be tested on other domains if equivalent unambiguous verifiers can be defined.
- Human researchers could monitor the public discussion forums to extract useful ideas or add their own contributions.
- Increasing the number of participating agents might produce faster cumulative gains on the same set of problems.
Load-bearing premise
The platform verifiers supply unambiguous and reliable measurements that confirm the reported results are genuine improvements over all earlier human and AI solutions.
What would settle it
An independent audit that re-runs the verifiers on the 12 claimed results and finds that at least one does not exceed the previous best known bound or solution.
Figures


read the original abstract
Scientific discovery is often a collective process: researchers share partial results, inspect failed attempts, and build on each other's ideas over long time horizons. Recent AI systems have shown that language-model-based agents can make meaningful progress on open scientific problems, but most existing systems operate in isolation. In this paper, we present EinsteinArena, an agent-native platform for open distributed research and discovery. EinsteinArena provides agents with a live set of open problems, each with a solid verifier, public leaderboard, and problem-specific discussion forum where agents can ask questions and share insights. We focus on mathematical tasks that have garnered substantial research interest, where progress can be measured unambiguously. As of May 2026, agents on EinsteinArena have discovered 12 new state-of-the-art results better than any previous human or AI solutions. One notable example is the kissing number problem in dimension 11, where the platform improved the best known lower bound from 593 to 604. This advance did not come from a single agent or isolated run. Rather it arose through a sequence of submissions, public discussion, verifier refinement, and subsequent agent-to-agent borrowing of ideas. These results provide evidence that decentralized scientific discovery can emerge from open interaction among autonomous agents in the wild, demonstrating a new paradigm for collective AI-driven research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EinsteinArena, an agent-native platform providing AI agents with open mathematical problems, solid verifiers, public leaderboards, and discussion forums to enable collective discovery. It claims that as of May 2026 agents have produced 12 new state-of-the-art results superior to all prior human or AI solutions, with the kissing-number problem in dimension 11 serving as the central example: the lower bound was raised from 593 to 604 via a sequence of submissions, public discussion, verifier refinement, and agent-to-agent idea transfer rather than any single isolated run.
Significance. If the reported improvements are verifiably correct and strictly superior to all prior bounds, the work would supply concrete empirical support for decentralized collective intelligence emerging among autonomous language-model agents in an open setting, extending beyond isolated-agent benchmarks and illustrating a scalable paradigm for AI-driven mathematical research.
major comments (1)
- [Abstract] Abstract: the central claim that 12 new SOTA results have been discovered, including the kissing-number lower bound of 604 in dimension 11, rests on the soundness of the platform's problem-specific verifiers, yet the manuscript supplies no description of verifier implementation (exact vs. floating-point arithmetic, contact enumeration, tolerance settings, or formal certificates). This is load-bearing because any undetected false positive or overlooked tighter bound would invalidate the narrative of genuine collective discovery.
minor comments (2)
- The manuscript would be strengthened by releasing at least one winning configuration (or a machine-readable certificate) for the kissing-number result so that independent verification is possible.
- Clarify the precise criteria used to confirm that each of the 12 results is strictly better than every previously published human or AI solution.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The concern regarding the lack of verifier implementation details is well-taken and directly impacts the credibility of the reported results. We address this point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 12 new SOTA results have been discovered, including the kissing-number lower bound of 604 in dimension 11, rests on the soundness of the platform's problem-specific verifiers, yet the manuscript supplies no description of verifier implementation (exact vs. floating-point arithmetic, contact enumeration, tolerance settings, or formal certificates). This is load-bearing because any undetected false positive or overlooked tighter bound would invalidate the narrative of genuine collective discovery.
Authors: We agree that the current manuscript does not provide sufficient technical detail on the problem-specific verifiers, which is necessary to allow independent verification of the claimed improvements. The abstract and main text emphasize the platform architecture and the collective discovery process but omit implementation specifics such as arithmetic precision, contact enumeration procedures, tolerance thresholds, and formal certificates. In the revised version we will add a dedicated subsection (likely under Methods or a new "Verifier Implementation" section) that describes these aspects for the primary problems, with particular attention to the 11-dimensional kissing number verifier. This addition will include the exact methods used to confirm that each submitted configuration is valid and that no tighter bound was overlooked by the verifier. revision: yes
Circularity Check
No circularity: empirical platform outcomes, not derivations
full rationale
The paper reports observed results from the EinsteinArena platform (12 new SOTA improvements including the kissing-number bound in dimension 11) as empirical outcomes of agent submissions, discussions, and verifier checks. No derivation chain, equations, fitted parameters, or predictions are presented that reduce by construction to the inputs. The central claims rest on external verification of configurations rather than self-definitional steps, self-citation load-bearing premises, or ansatzes smuggled via prior work. The paper is therefore self-contained against external benchmarks of reported performance, with no load-bearing step that collapses to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mathematical problems have solid verifiers that unambiguously measure progress.
invented entities (1)
-
EinsteinArena platform
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Socratic agents for autonomous scientific discovery in high-dimensional physical systems
AHOIS is a Socratic multi-agent AI that autonomously discovers and validates a random-interference encoding strategy for multimode fiber optics, achieving 76.97% MNIST and 83.17% Fashion-MNIST accuracy with 16x16 meas...
-
Structure of kissing arrangements in ${\mathbb R}^{12}$ and a place for the $841$st sphere
Kissing arrangements of 840 spheres in R^12 admit positive-dimensional families of non-isometric realizations via flexible 48-systems in each 60-point block with fixed bridges, enabling a numerical 841-sphere configur...
Reference graph
Works this paper leans on
-
[1]
Marc R. Best. Binary codes with a minimum distance of four (corresp.).IEEE Trans. Inf. Theory, 26:738–742, 1980. URL:https://api.semanticscholar.org/CorpusID:40030299
1980
-
[2]
An improved example for an autoconvolution inequality
Christopher Boyer and Zane Kun Li. An improved example for an autoconvolution inequality. Experimental Mathematics, pages 1–7, 2026
2026
-
[3]
J. H. Conway and N. J. A. Sloane.Sphere Packings and Kissing Numbers, pages 1–30. Springer New York, New York, NY, 1988.doi:10.1007/978-1-4757-2016-7_1
-
[4]
On nonlinear fractional programming.Management science, 13(7):492– 498, 1967
Werner Dinkelbach. On nonlinear fractional programming.Management science, 13(7):492– 498, 1967
1967
-
[5]
Improv- ing factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate. InForty-first international conference on machine learning, 2024
2024
-
[6]
Highly symmetric lines.Linear Algebra and its Applications, 722:12–37, 2025
Mikhail Ganzhinov. Highly symmetric lines.Linear Algebra and its Applications, 722:12–37, 2025
2025
-
[7]
Metagpt: Meta programming for a multi- agent collaborative framework, 2024
Sirui Hong, Mingchen Zhuge, Jiaqi Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and J¨ urgen Schmidhuber. Metagpt: Meta programming for a multi- agent collaborative framework, 2024. URL:https://arxiv.org/abs/2308.00352,arXiv: 2308.00352
Pith/arXiv arXiv 2024
-
[8]
Olympiad-level formal mathematical reasoning with reinforcement learning.Nature, 2025
Thomas Hubert, Rishi Mehta, Laurent Sartran, Mikl´ os Z Horv´ ath, GoranˇZuˇ zi´ c, Eric Wieser, Aja Huang, Julian Schrittwieser, Yannick Schroecker, Hussain Masoom, et al. Olympiad-level formal mathematical reasoning with reinforcement learning.Nature, 2025
2025
-
[9]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations.arXiv preprint arXiv:2312.06674, 2023
Pith/arXiv arXiv 2023
-
[10]
State-of-the-art solutions for the second autocorre- lation inequality
Justin Kang and ClaudeExplorer. State-of-the-art solutions for the second autocorre- lation inequality. Einstein Arena, 2026. URL:https://github.com/justinkang221/ second-autocorrelation-inequality
2026
-
[11]
Cambridge University Press, 2004
Yitzhak Katznelson.An introduction to harmonic analysis. Cambridge University Press, 2004
2004
-
[12]
Robert Tjarko Lange, Yuki Imajuku, and Edoardo Cetin. Shinkaevolve: Towards open-ended and sample-efficient program evolution.arXiv preprint arXiv:2509.19349, 2025
Pith/arXiv arXiv 2025
-
[13]
Alpha omega agents, 2026
Woosang Lim. Alpha omega agents, 2026. URL:https://github.com/quasar17/Alpha_ Omega_Agents. 13
2026
-
[14]
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292, 2024
Pith/arXiv arXiv 2024
-
[15]
Self-refine: Iterative refine- ment with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refine- ment with self-feedback.Advances in neural information processing systems, 36:46534–46594, 2023
2023
-
[16]
Kosmos: An ai scientist for autonomous discovery.arXiv preprint arXiv:2511.02824, 2025
Ludovico Mitchener, Angela Yiu, Benjamin Chang, Mathieu Bourdenx, Tyler Nadolski, Arvis Sulovari, Eric C Landsness, Daniel L Barabasi, Siddharth Narayanan, Nicky Evans, et al. Kosmos: An ai scientist for autonomous discovery.arXiv preprint arXiv:2511.02824, 2025
Pith/arXiv arXiv 2025
-
[17]
Alexander Novikov, Ngˆ an V˜ u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and al...
Pith/arXiv arXiv 2025
-
[18]
APOLLO: Automated LLM and lean collaboration for advanced formal reasoning
Azim Ospanov, Farzan Farnia, and Roozbeh Yousefzadeh. APOLLO: Automated LLM and lean collaboration for advanced formal reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[19]
Lsqr: An algorithm for sparse linear equations and sparse least squares.ACM Transactions on Mathematical Software (TOMS), 8(1):43–71, 1982
Christopher C Paige and Michael A Saunders. Lsqr: An algorithm for sparse linear equations and sparse least squares.ACM Transactions on Mathematical Software (TOMS), 8(1):43–71, 1982
1982
-
[20]
ChatDev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative agents for software development. In Lun-Wei Ku, An- dre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational ...
-
[21]
Ao Qu, Han Zheng, Zijian Zhou, Yihao Yan, Yihong Tang, Shao Yong Ong, Fenglu Hong, Kaichen Zhou, Chonghe Jiang, Minwei Kong, et al. Coral: Towards autonomous multi-agent evolution for open-ended discovery.arXiv preprint arXiv:2604.01658, 2026
Pith/arXiv arXiv 2026
-
[22]
Agentrxiv: Towards collaborative autonomous research
Samuel Schmidgall and Michael Moor. Agentrxiv: Towards collaborative autonomous research. arXiv preprint arXiv:2503.18102, 2025
arXiv 2025
-
[23]
Jsagent: An ai agent for hard mathematical optimization, 2026
Jongmin Sung. Jsagent: An ai agent for hard mathematical optimization, 2026. URL:https: //github.com/jmsung/einstein
2026
-
[24]
Kyle Swanson, Wesley Wu, Nash L. Bulaong, John E. Pak, and James Y. Zou. The virtual lab of AI agents designs new SARS-CoV-2 nanobodies.Nature, 646:716–723, 2025.doi: 10.1038/s41586-025-09442-9
-
[25]
Cambridge University Press, 2006
Terence Tao and Van H Vu.Additive combinatorics, volume 105. Cambridge University Press, 2006. 14
2006
-
[26]
AI research agents for machine learning: Search, exploration, and gen- eralization in MLE-bench
Edan Toledo, Karen Hambardzumyan, Martin Josifoski, Rishi Hazra, Nicolas Baldwin, Alexis Audran-Reiss, Michael Kuchnik, Despoina Magka, Minqi Jiang, Alisia Maria Lupidi, An- drei Lupu, Roberta Raileanu, Tatiana Shavrina, Kelvin Niu, Jean-Christophe Gagnon-Audet, Michael Shvartsman, Shagun Sodhani, Alexander H Miller, Abhishek Charnalia, Derek Dun- field, ...
2026
-
[27]
Multi-agent collaboration mechanisms: A survey of llms.arXiv preprint arXiv:2501.06322, 2025
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D Nguyen. Multi-agent collaboration mechanisms: A survey of llms.arXiv preprint arXiv:2501.06322, 2025
Pith/arXiv arXiv 2025
-
[28]
Mixture-of-agents enhances large language model capabilities
Junlin Wang, Jue Wang, Ben Athiwaratkun, Ce Zhang, and James Y Zou. Mixture-of-agents enhances large language model capabilities. InInternational Conference on Learning Repre- sentations, 2025
2025
-
[29]
Anjiang Wei, Tianran Sun, Yogesh Seenichamy, Hang Song, Anne Ouyang, Azalia Mirho- seini, Ke Wang, and Alex Aiken. Astra: A multi-agent system for gpu kernel performance optimization.arXiv preprint arXiv:2509.07506, 2025
arXiv 2025
-
[30]
Lukas Weidener, Marko Brki´ c, Phillip Lee, Martin Karlsson, Kevin Noessler, and Paul Kohlhaas. From agent-only social networks to autonomous scientific research: Lessons from openclaw and moltbook, and the architecture of clawdlab and beach. science.arXiv preprint arXiv:2602.19810, 2026
arXiv 2026
-
[31]
Sheng Xu, Qiantai Feng, Lifeng Qiao, Hao Wu, Tao Shen, Yu Cheng, Shuangjia Zheng, and Siqi Sun. Benchmarking all-atom biomolecular structure prediction with FoldBench.Nature Communications, December 2025.doi:10.1038/s41467-025-67127-3
-
[32]
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv preprint arXiv:2504.08066, 2025
Pith/arXiv arXiv 2025
-
[33]
Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems,
Yingxuan Yang, Huacan Chai, Shuai Shao, Yuanyi Song, Siyuan Qi, Renting Rui, and Weinan Zhang. Agentnet: Decentralized evolutionary coordination for llm-based multi-agent systems,
-
[34]
URL:https://arxiv.org/abs/2504.00587,arXiv:2504.00587
-
[35]
Evaluation-driven scaling for scientific discovery.arXiv preprint arXiv:2604.19341, 2026
Haotian Ye, Haowei Lin, Jingyi Tang, Yizhen Luo, Caiyin Yang, Chang Su, Rahul Thapa, Rui Yang, Ruihua Liu, Zeyu Li, et al. Evaluation-driven scaling for scientific discovery.arXiv preprint arXiv:2604.19341, 2026
Pith/arXiv arXiv 2026
-
[36]
Learning to discover at test time.ICML, 2026
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, and Yu Sun. Learning to discover at test time.ICML, 2026
2026
-
[37]
Aflow: Automating agentic workflow generation, 2025
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. Aflow: Automating agentic workflow generation, 2025. URL:https://arxiv. org/abs/2410.10762,arXiv:2410.10762. 15
Pith/arXiv arXiv 2025
-
[38]
Sirius: Self-improving multi- agent systems via bootstrapped reasoning, 2025
Wanjia Zhao, Mert Yuksekgonul, Shirley Wu, and James Zou. Sirius: Self-improving multi- agent systems via bootstrapped reasoning, 2025. URL:https://arxiv.org/abs/2502.04780, arXiv:2502.04780
arXiv 2025
-
[39]
Language agents as optimizable graphs, 2024
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and J¨ urgen Schmidhuber. Language agents as optimizable graphs, 2024. URL:https://arxiv.org/abs/ 2402.16823,arXiv:2402.16823. A Detailed Descriptions of Problems A.1 Kissing Number (d= 11) The kissing number in dimensiond∈Nasks the maximum number of non-overlapping unit spher...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.