From Observation to Intervention: A Causal Audit of Expert Importance in Mixture-of-Experts Models
Pith reviewed 2026-06-27 14:16 UTC · model grok-4.3
The pith
Observational routing metrics do not predict causal expert importance in Mixture-of-Experts models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
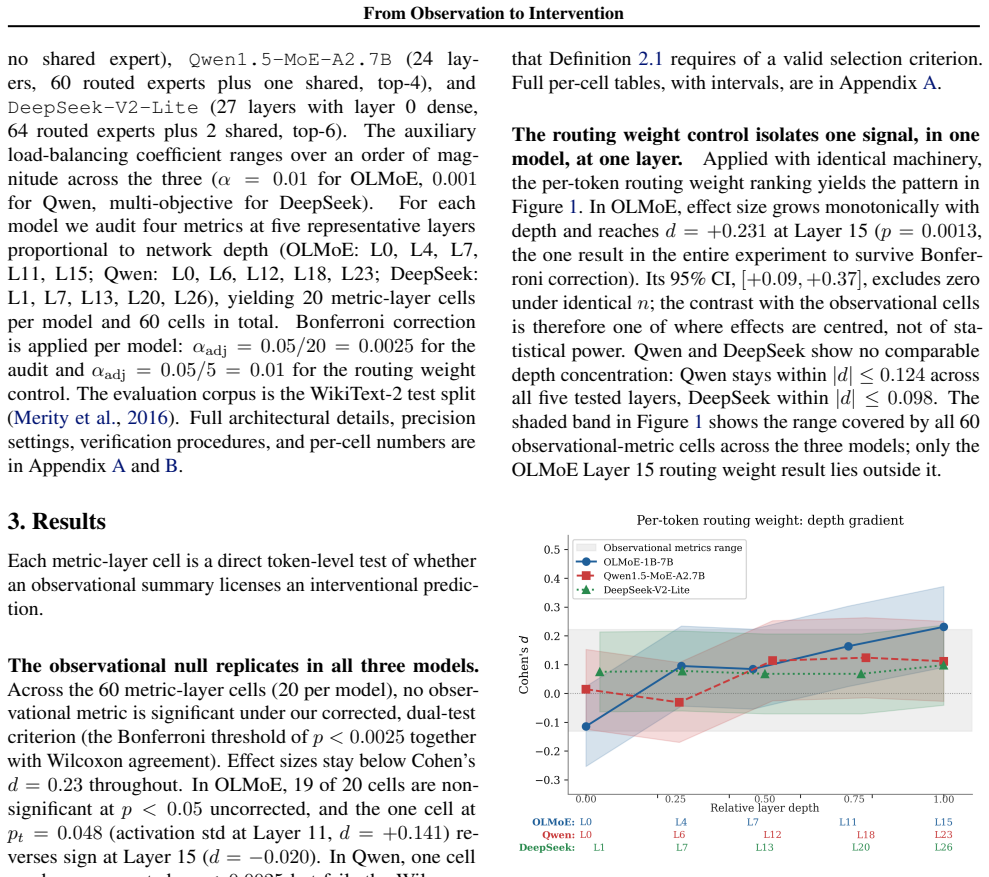
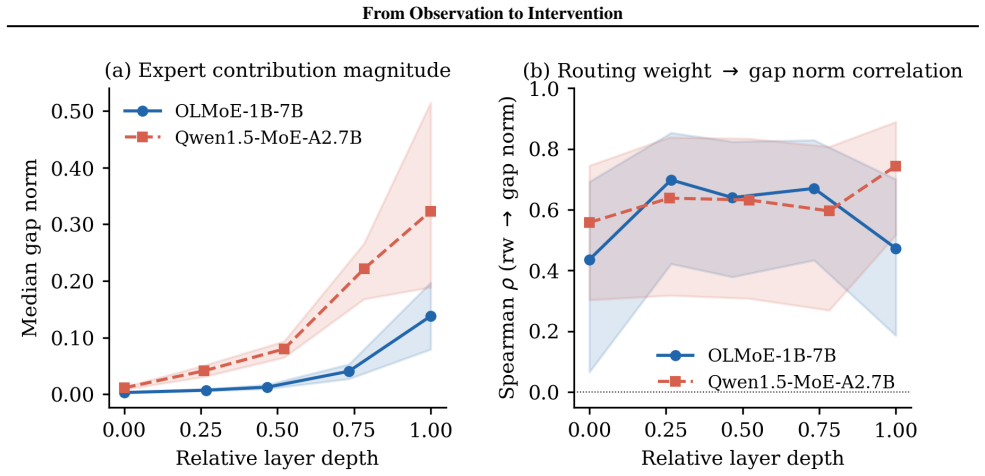
A token-level interventional audit across three high-redundancy MoE architectures finds no observational metric predicts causal expert importance in any model: across all 60 metric-layer combinations effect sizes stay below Cohen's d = 0.23, and no metric is reliably positive under our corrected, dual-test criterion. A per-token routing weight control, run with identical n, rules out insufficient power, recovering a signal whose CI excludes zero at OLMoE's final MoE layer (d = +0.231, 95% CI [+0.09, +0.37], p = 0.0013). Existing pruning methods succeed in this regime not by identifying dispensable experts but because early-layer redundancy renders most selection criteria interchangeable.
What carries the argument
The token-level interventional audit that forces or blocks routing to specific experts on individual tokens and measures the downstream effect on model output.
If this is right
- Pruning decisions based on utilization rates, activation norms, or routing weights do not target experts whose removal changes model behavior.
- Early-layer redundancy makes most selection criteria interchangeable, so pruning succeeds without identifying truly dispensable experts.
- Population-level observational summaries cannot be treated as evidence for token-level interventional claims about expert importance.
- The same inferential gap from rung-1 associations to rung-2 interventions appears in at least one concrete interpretability practice.
- A direct routing-weight control produces measurable effects, confirming that causal signals are detectable when they exist.
Where Pith is reading between the lines
- The same audit design could be applied to other neural-network components where observational proxies are used to justify edits or pruning.
- High redundancy may be masking the need for more precise expert routing in current MoE training regimes.
- Testing the same metrics in lower-redundancy or differently scaled MoE models would show whether the disconnect is architecture-specific.
- The results supply a concrete template for checking whether other interpretability claims rest on untested moves from observation to intervention.
Load-bearing premise
The chosen token-level routing interventions isolate the causal contribution of individual experts without introducing confounding changes to other model computations or to the router itself.
What would settle it
Observing an observational metric whose effect size exceeds Cohen's d = 0.5 and passes the dual-test criterion when predicting the outcome of expert-removal interventions in any of the three tested models would falsify the central claim.
Figures
read the original abstract
Interpretability methods routinely use population-level summary statistics over observed model behaviour to license claims about the effects of targeted interventions on specific computations; in Pearl's terms, they treat rung-1 associational evidence as if it supported rung-2 interventional conclusions, a move whose validity is rarely tested. We examine one concrete instance: the use of routing statistics in Mixture-of-Experts (MoE) pruning, where utilization rates, activation norms, and routing weight distributions are treated as predictors of which experts can be removed without functional cost. A token-level interventional audit across three high-redundancy MoE architectures (OLMoE-1B-7B-0924, Qwen1.5-MoE-A2.7B, DeepSeek-V2-Lite) finds no observational metric predicts causal expert importance in any model: across all 60 metric-layer combinations effect sizes stay below Cohen's $d = 0.23$, and no metric is reliably positive under our corrected, dual-test criterion. A per-token routing weight control, run with identical $n$, rules out insufficient power, recovering a signal whose CI excludes zero at OLMoE's final MoE layer ($d = +0.231$, 95\% CI $[+0.09, +0.37]$, $p = 0.0013$). Existing pruning methods succeed in this regime not by identifying dispensable experts but because early-layer redundancy renders most selection criteria interchangeable. Our results provide an explicit counterexample to the common inferential step from population-level observational summaries to token-level interventional claims about expert importance, and illustrate how interventional audits can calibrate the evidential standards for interpretability claims.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that common observational metrics (utilization rates, activation norms, routing weight distributions) do not predict the causal importance of experts in Mixture-of-Experts models under token-level routing interventions. An audit across three high-redundancy MoE architectures (OLMoE-1B-7B-0924, Qwen1.5-MoE-A2.7B, DeepSeek-V2-Lite) finds effect sizes below Cohen's d = 0.23 for all 60 metric-layer combinations, with no metric reliably positive under a corrected dual-test criterion. A per-token routing-weight positive control recovers a detectable signal (d = +0.231, 95% CI [+0.09, +0.37], p = 0.0013 at OLMoE's final layer), and the authors conclude that pruning succeeds due to early-layer redundancy rather than precise expert identification.
Significance. If the interventional results hold, the work supplies a concrete counterexample to the routine use of rung-1 observational summaries to support rung-2 interventional claims in interpretability. The explicit reporting of effect sizes, confidence intervals, p-values, and a positive control that rules out insufficient power are strengths that make the negative finding falsifiable and reproducible. This calibrates evidential standards for MoE pruning methods and suggests that apparent success of observational pruning criteria stems from interchangeability under redundancy rather than accurate causal identification.
minor comments (3)
- [Methods] The Methods section should include a table or supplementary figure summarizing effect sizes, CIs, and test outcomes for all 60 metric-layer combinations to allow direct inspection of the uniformity claim.
- [Methods] The exact definition and implementation of the 'corrected, dual-test criterion' is referenced in the abstract but would benefit from an explicit algorithmic description or pseudocode in the main text for reproducibility.
- [Experimental Setup] The manuscript would be strengthened by reporting the precise number of tokens and layers analyzed per model, as well as any preprocessing steps for the token-level interventions.
Simulated Author's Rebuttal
We thank the referee for the supportive review, accurate summary of our findings, and recommendation for minor revision. The report correctly identifies the core contribution as a falsifiable counterexample to rung-1 to rung-2 inference in MoE interpretability, along with the value of the positive control and explicit effect-size reporting.
Circularity Check
No circularity in empirical interventional audit
full rationale
The paper derives its central claim from direct token-level routing interventions on three MoE models, followed by computation of Cohen's d effect sizes and dual-test statistical criteria on the resulting output changes. These steps are experimental measurements of causal effects, not self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations. The per-token routing-weight positive control is an independent verification of statistical power using the same n, and no equations or prior-author citations are invoked to force the null result. The audit is self-contained against external benchmarks via the reported interventions and CIs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token-level routing interventions can be performed in a manner that isolates the causal effect of a single expert.
Forward citations
Cited by 1 Pith paper
-
How Modular Is a Frontier Mixture-of-Experts? A Pre-registered Causal Test in Which Apparent Expert Modularity Mostly Dissolves
Pre-registered ablation tests on Command A+ reveal that only one of six expert families (Arabic) shows clean selective modularity; all others fail selectivity or are measurement-dependent.
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
MoE-Pruner: Pruning Mixture-of-Experts Large Language Model using the Hints from Its Router , author=. 2024 , eprint=
2024
-
[2]
2019 , eprint=
Attention is not Explanation , author=. 2019 , eprint=
2019
-
[3]
2020 , eprint=
Sanity Checks for Saliency Maps , author=. 2020 , eprint=
2020
-
[4]
2026 , eprint=
Causality is Key for Interpretability Claims to Generalise , author=. 2026 , eprint=
2026
-
[5]
2022 , eprint=
Task-Specific Expert Pruning for Sparse Mixture-of-Experts , author=. 2022 , eprint=
2022
-
[6]
2024 , eprint=
SEER-MoE: Sparse Expert Efficiency through Regularization for Mixture-of-Experts , author=. 2024 , eprint=
2024
-
[7]
2025 , eprint=
Finding Fantastic Experts in MoEs: A Unified Study for Expert Dropping Strategies and Observations , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
OLMoE: Open Mixture-of-Experts Language Models , author=. 2025 , eprint=
2025
-
[9]
2024 , eprint=
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model , author=. 2024 , eprint=
2024
-
[10]
2016 , eprint=
Pointer Sentinel Mixture Models , author=. 2016 , eprint=
2016
-
[11]
Probabilistic and causal inference: the works of Judea Pearl , pages=
On Pearl's hierarchy and the foundations of causal inference , author=. Probabilistic and causal inference: the works of Judea Pearl , pages=. 2022 , publisher=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.