What Limits Does Quantization Place on Dense Top-k Retrieval? A Theoretical Study
Pith reviewed 2026-06-27 08:25 UTC · model grok-4.3
The pith
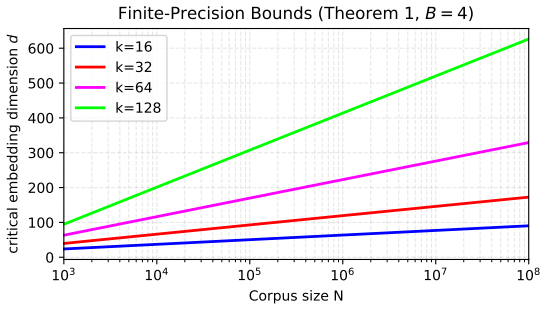
With B bits per coordinate, perfect top-k retrieval requires Bd = Omega(k ln N), so dimension must grow logarithmically with corpus size at fixed precision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
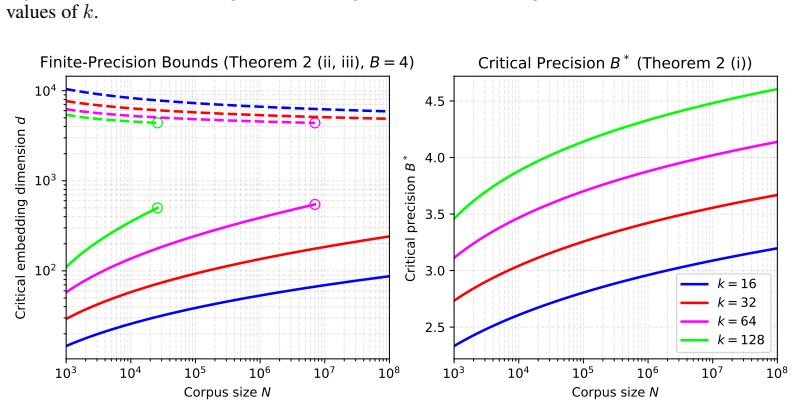
In the l2-normalized B-bit uniform scalar quantization model, the realizability condition that every k-subset is exactly the top-k set for some query vector cannot hold unless Bd = Omega(k ln N). Moreover, when B falls below O(ln ln N), the condition fails for any finite dimension, and two further regimes bound the feasible (B, d) pairs.
What carries the argument
The realizability condition that every k-subset of the corpus must be exactly retrievable as top-k by some query, under the l2-normalized B-bit uniform scalar quantization model.
If this is right
- At any fixed precision B, the embedding dimension d must grow at least logarithmically with N.
- Below precision B* = O(ln ln N), no finite dimension allows perfect top-k retrieval.
- Vector databases and dense retrieval systems using standard quantization will require growing dimension or precision as corpus size increases.
- Two additional regimes exist that further restrict the allowable combinations of B and d.
Where Pith is reading between the lines
- The exact-realizability requirement may be relaxed in approximate retrieval settings, potentially lowering the scaling.
- The bounds suggest information-theoretic limits that could apply to other quantization schemes beyond uniform scalar.
- Practical systems might compensate by increasing both dimension and bits together rather than one alone.
Load-bearing premise
Every k-subset must be exactly realizable as the top-k result for some query rather than only approximately.
What would settle it
Construct a corpus of size N with k fixed, choose B and d such that Bd is o(k ln N), and check whether some k-subset has no query vector whose quantized top-k exactly matches it.
Figures
read the original abstract
We establish conditions for embedding a corpus of $N$ documents as $d$-dimensional vectors such that every $k$-subset $S \subseteq [N]$ is realizable as a result of top-$k$ retrieval by some query vector. Recent work shows that $d = O(k)$ suffices for such embeddings to exist in $\mathbb{R}^d$, independently of $N$. We theoretically prove that this corpus-independent bound is specific to infinite precision. With $B$ bits per coordinate, perfect top-$k$ retrieval requires $Bd = \Omega(k \ln N)$; thus, at any fixed precision, the dimension must grow at least logarithmically with $N$. Specializing to a $\ell_2$-normalized $B$-bit uniform scalar quantization model, we also identify a threshold on the precision $B^{*} = O(\ln \ln N)$ below which no dimension suffices, together with two further regimes that bound the feasible $(B, d)$ pairs. Our result implies that in practical vector databases and dense retrieval systems where quantization is standard, the embedding dimension and possibly the precision must grow with the corpus size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that while d = O(k) suffices for perfect top-k realizability in infinite precision (independent of N), B-bit quantization requires Bd = Ω(k ln N) by a counting argument over the binom(N,k) subsets that must each be exactly realizable by some query. Specializing to the ℓ2-normalized B-bit uniform scalar quantization model on the sphere, it derives a threshold B* = O(ln ln N) below which no finite d works, plus two additional regimes bounding feasible (B,d) pairs.
Significance. If the lower-bound derivation and model-specific threshold hold, the result supplies a concrete scaling law for quantized dense retrieval systems: at fixed precision, dimension must grow at least logarithmically with corpus size. The counting argument for the general bound is a clear theoretical strength; the specialization to uniform scalar quantization on the sphere adds practical relevance for vector databases.
major comments (3)
- [§3] §3 (general lower bound): the Ω(k ln N) claim rests on requiring every k-subset to be exactly realizable; the manuscript should explicitly state whether the same counting argument yields a qualitatively different bound under approximate realizability (small rank errors permitted).
- [§4.3] §4.3 (B* threshold): the derivation that B* = O(ln ln N) is the point below which the quantized grid on the sphere cannot separate all k-subsets must be checked for the precise counting of distinguishable half-spaces or Voronoi cells induced by the uniform scalar quantizer; a small-N verification or explicit cardinality calculation would strengthen the claim.
- [§5] §5 (regimes): the two further (B,d) regimes are stated but their proofs appear to reuse the same realizability counting; confirm that they do not inadvertently assume the same grid arrangement already used for the B* threshold.
minor comments (2)
- [Abstract] Abstract: the phrase 'two further regimes' is mentioned but not named; a one-sentence gloss would improve readability.
- [Notation] Notation section: the precise definition of the ℓ2-normalized uniform scalar quantizer (including how ties or boundary points are handled) should appear before the model-specific theorems.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. We address each major comment below. The paper focuses on exact realizability; we will clarify distinctions where needed and add supporting details without altering the core claims.
read point-by-point responses
-
Referee: [§3] §3 (general lower bound): the Ω(k ln N) claim rests on requiring every k-subset to be exactly realizable; the manuscript should explicitly state whether the same counting argument yields a qualitatively different bound under approximate realizability (small rank errors permitted).
Authors: We agree the distinction matters. The Ω(k ln N) bound follows from a pigeonhole argument: there are binom(N,k) subsets but at most 2^{Bd} distinct quantized query vectors, each of which can realize at most one top-k set under exact retrieval. Under approximate realizability (allowing small rank errors), each query could cover multiple subsets, so the same counting argument does not directly yield the same lower bound; a qualitatively weaker or different scaling could hold. We will add an explicit remark in §3 stating that the bound is specific to exact realizability and briefly noting why approximate settings may differ. revision: yes
-
Referee: [§4.3] §4.3 (B* threshold): the derivation that B* = O(ln ln N) is the point below which the quantized grid on the sphere cannot separate all k-subsets must be checked for the precise counting of distinguishable half-spaces or Voronoi cells induced by the uniform scalar quantizer; a small-N verification or explicit cardinality calculation would strengthen the claim.
Authors: The B* = O(ln ln N) threshold is obtained by showing that, for B below this order, the number of distinct Voronoi cells (or distinguishable directions) created by the ℓ2-normalized uniform scalar quantizer on the sphere is o(binom(N,k)), so some k-subsets cannot be isolated. The counting uses the cardinality of the quantization grid rather than a direct half-space enumeration. We will strengthen the section by adding a small-N explicit cardinality calculation (e.g., for N=16,32) that verifies the transition point matches the asymptotic prediction. revision: partial
-
Referee: [§5] §5 (regimes): the two further (B,d) regimes are stated but their proofs appear to reuse the same realizability counting; confirm that they do not inadvertently assume the same grid arrangement already used for the B* threshold.
Authors: The two additional regimes in §5 are proved via the general counting argument of §3, which applies to any B-bit quantization scheme and counts only the total number of distinct representable vectors (2^{Bd}). They do not rely on the geometry or cell arrangement of the uniform scalar quantizer used to derive the B* threshold in §4.3. We will add a sentence in §5 explicitly stating that these regimes are quantization-model-independent and rest solely on the §3 counting argument. revision: yes
Circularity Check
No circularity: lower bounds derived from independent counting arguments on realizable subsets
full rationale
The paper establishes Bd = Ω(k ln N) and the B* = O(ln ln N) threshold via counting arguments over the number of k-subsets and the discrete grid induced by ℓ2-normalized B-bit uniform scalar quantization. These are first-principles information-theoretic lower bounds on the number of distinguishable top-k sets under the stated model; they do not reduce to fitted parameters, self-definitions, or self-citation chains. The realizability condition is an explicit modeling assumption, not smuggled in via prior work by the same authors. No load-bearing self-citations or ansatzes are indicated in the abstract or description. The derivation is self-contained against external combinatorial benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Embeddings are ℓ2-normalized before B-bit uniform scalar quantization.
- domain assumption Every k-subset must be exactly realizable as top-k for some query vector.
Forward citations
Cited by 1 Pith paper
-
Non-negative Elastic Net Decoding for Information Retrieval
NNN decoding selects documents via non-negative elastic net reconstruction of the query embedding, with a theorem showing it strictly dominates dense retrieval on correlated corpora and experiments showing gains over ...
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations (ICLR) , year =
Orion Weller and Michael Boratko and Iftekhar Naim and Jinhyuk Lee , title =. International Conference on Learning Representations (ICLR) , year =
-
[2]
arXiv preprint arXiv:2601.20844 , year =
Zihao Wang and Hang Yin and Lihui Liu and Hanghang Tong and Yangqiu Song and Ginny Wong and Simon See , title =. arXiv preprint arXiv:2601.20844 , year =
-
[3]
Geometrical realization of set systems and probabilistic communication complexity , booktitle =
Noga Alon and Peter Frankl and Vojt. Geometrical realization of set systems and probabilistic communication complexity , booktitle =. 1985 , publisher =
1985
-
[4]
Lectures on Polytopes , series =
G. Lectures on Polytopes , series =. 1995 , note =
1995
-
[5]
Lectures on Discrete Geometry , series =
Ji. Lectures on Discrete Geometry , series =
-
[6]
Mehryar Mohri and Afshin Rostamizadeh and Ameet Talwalkar , title =
-
[7]
Johnson and Joram Lindenstrauss , title =
William B. Johnson and Joram Lindenstrauss , title =. Contemporary Mathematics , volume =
-
[8]
Roman Vershynin , title =
-
[9]
Nils Reimers and Iryna Gurevych , title =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers) , pages =. 2021 , publisher =
2021
-
[10]
Advances in Neural Information Processing Systems (NeurIPS) , publisher =
Zi Yin and Yuanyuan Shen , title =. Advances in Neural Information Processing Systems (NeurIPS) , publisher =
-
[11]
Advances in Neural Information Processing Systems (NeurIPS) , publisher =
Aditya Kusupati and Gantavya Bhatt and Aniket Rege and Matthew Wallingford and Aditya Sinha and Vivek Ramanujan and William Howard-Snyder and Kaifeng Chen and Sham Kakade and Prateek Jain and Ali Farhadi , title =. Advances in Neural Information Processing Systems (NeurIPS) , publisher =
-
[12]
Robertson and Steve Walker and Susan Jones and Micheline Hancock-Beaulieu and Mike Gatford , title =
Stephen E. Robertson and Steve Walker and Susan Jones and Micheline Hancock-Beaulieu and Mike Gatford , title =. Overview of the Third Text REtrieval Conference (TREC-3) , editor =
-
[13]
Journal of Inequalities in Pure and Applied Mathematics (JIPAM) , volume =
Abdolhossein Hoorfar and Mehdi Hassani , title =. Journal of Inequalities in Pure and Applied Mathematics (JIPAM) , volume =
-
[14]
Product Quantization for Nearest Neighbor Search , journal =
Herv. Product Quantization for Nearest Neighbor Search , journal =
-
[15]
Communications of the ACM , volume =
Alexandr Andoni and Piotr Indyk , title =. Communications of the ACM , volume =
-
[16]
Matthijs Douze and Alexandr Guzhva and Chengqi Deng and Jeff Johnson and Gergely Szilvasy and Pierre-Emmanuel Mazar. The. arXiv preprint arXiv:2401.08281 , year =
-
[17]
Billion-Scale Similarity Search with
Jeff Johnson and Matthijs Douze and Herv. Billion-Scale Similarity Search with. IEEE Transactions on Big Data , volume =
-
[18]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Benoit Jacob and Skirmantas Kligys and Bo Chen and Menglong Zhu and Matthew Tang and Andrew Howard and Hartwig Adam and Dmitry Kalenichenko , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[19]
Advances in Neural Information Processing Systems (NeurIPS) , publisher =
Tim Dettmers and Mike Lewis and Younes Belkada and Luke Zettlemoyer , title =. Advances in Neural Information Processing Systems (NeurIPS) , publisher =
-
[20]
Information, Physics, and Computation , series =
Marc M. Information, Physics, and Computation , series =
-
[21]
Spencer , title =
Noga Alon and Joel H. Spencer , title =
-
[22]
Some remarks on the theory of graphs , journal =
Paul Erd. Some remarks on the theory of graphs , journal =
-
[23]
Journal of the American Mathematical Society , volume =
Dimitris Achlioptas and Yuval Peres , title =. Journal of the American Mathematical Society , volume =
-
[24]
Annals of Mathematics , volume =
Dimitris Achlioptas and Assaf Naor , title =. Annals of Mathematics , volume =
-
[25]
On the evolution of random graphs , journal =
Paul Erd. On the evolution of random graphs , journal =
-
[26]
Journal of the American Mathematical Society , volume =
Ehud Friedgut , title =. Journal of the American Mathematical Society , volume =
-
[27]
Annals of Mathematics , volume =
Jian Ding and Allan Sly and Nike Sun , title =. Annals of Mathematics , volume =
-
[28]
David Forney , title =
Alexander Barg and G. David Forney , title =. IEEE Transactions on Information Theory , volume =
-
[29]
arXiv preprint arXiv:2209.05433 , year =
Paulius Micikevicius and Dusan Stosic and Neil Burgess and Marius Cornea and Pradeep Dubey and Richard Grisenthwaite and Sangwon Ha and Alexander Heinecke and Patrick Judd and John Kamalu and Naveen Mellempudi and Stuart Oberman and Mohammad Shoeybi and Michael Siu and Hao Wu , title =. arXiv preprint arXiv:2209.05433 , year =
-
[30]
Efficient Passage Retrieval with Hashing for Open-domain Question Answering
Yamada, Ikuya and Asai, Akari and Hajishirzi, Hannaneh. Efficient Passage Retrieval with Hashing for Open-domain Question Answering. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). 2021
2021
-
[31]
and Zettlemoyer, Luke and Yu, Tao
Su, Hongjin and Shi, Weijia and Kasai, Jungo and Wang, Yizhong and Hu, Yushi and Ostendorf, Mari and Yih, Wen-tau and Smith, Noah A. and Zettlemoyer, Luke and Yu, Tao. One Embedder, Any Task: Instruction-Finetuned Text Embeddings. Findings of the Association for Computational Linguistics: ACL 2023. 2023
2023
-
[32]
Conference on Language Modeling (COLM) , year =
ReasonIR: Training Retrievers for Reasoning Tasks , author =. Conference on Language Modeling (COLM) , year =
-
[33]
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers , volume =
Wang, Wenhui and Wei, Furu and Dong, Li and Bao, Hangbo and Yang, Nan and Zhou, Ming , booktitle =. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers , volume =
-
[34]
Improving Text Embeddings with Large Language Models
Wang, Liang and Yang, Nan and Huang, Xiaolong and Yang, Linjun and Majumder, Rangan and Wei, Furu. Improving Text Embeddings with Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
2024
-
[35]
and Yashunin, D
Malkov, Yu A. and Yashunin, D. A. , journal=. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs , year=
-
[36]
Semantic hashing , journal =
Ruslan Salakhutdinov and Geoffrey Hinton , keywords =. Semantic hashing , journal =. 2009 , note =
2009
-
[37]
A linear lower bound on the unbounded error probabilistic communication complexity , journal =
Jürgen Forster , keywords =. A linear lower bound on the unbounded error probabilistic communication complexity , journal =. 2002 , note =
2002
-
[38]
International Conference on Learning Representations (ICLR) , year =
Elias Frantar and Saleh Ashkboos and Torsten Hoefler and Dan Alistarh , title =. International Conference on Learning Representations (ICLR) , year =
-
[39]
LLM - FP 4: 4-Bit Floating-Point Quantized Transformers
Liu, Shih-yang and Liu, Zechun and Huang, Xijie and Dong, Pingcheng and Cheng, Kwang-Ting. LLM - FP 4: 4-Bit Floating-Point Quantized Transformers. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.