L-Proto: Language-Aware Episodic Prototypical Training for Multilingual Speaker Verification
Pith reviewed 2026-07-02 22:29 UTC · model grok-4.3
The pith
Sampling speakers from one language per episode reduces language entanglement in multilingual speaker embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
L-Proto constructs language-consistent episodes by sampling speakers from a single language per episode. This training strategy reduces language-driven variation and encourages the model to learn embeddings focused on speaker identity rather than linguistic characteristics.
What carries the argument
Language-consistent episodes that enforce single-language sampling within each training episode of prototypical learning.
Load-bearing premise
Constructing episodes from speakers of only one language per episode is enough to separate speaker identity from language effects without losing important cross-lingual information.
What would settle it
Observing no reduction in language clustering or no performance gain on cross-lingual speaker verification tests when comparing L-Proto to random episodic sampling.
Figures

read the original abstract
Multilingual speaker verification remains challenging because language-dependent acoustic variability causes speaker identity to become entangled with linguistic characteristics, degrading generalization across languages. In multilingual training, embeddings often encode language cues with speaker identity, causing speakers to form language-specific clusters. We propose L-Proto, a language-aware episodic prototypical training strategy that constructs language-consistent episodes. By sampling speakers from a single language per episode, L-Proto reduces language-driven variation during training and encourages embeddings to focus more directly on speaker identity. Experiments on the TidyVoice Challenge benchmark demonstrate consistent performance improvements over conventional fine-tuning and random episodic sampling across multiple backbone architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes L-Proto, a language-aware episodic prototypical training strategy for multilingual speaker verification. It constructs episodes by sampling all speakers from a single language, thereby removing language as a within-episode cue in the prototypical loss and encouraging embeddings to focus on speaker identity rather than linguistic variability. Experiments on the TidyVoice Challenge benchmark report consistent improvements over conventional fine-tuning and random episodic sampling across multiple backbone architectures.
Significance. If the reported gains prove robust under standard controls, the method offers a lightweight, architecture-agnostic modification to episodic training that could improve cross-lingual generalization in speaker verification without extra data or explicit disentanglement losses. The simplicity of the episode construction is a practical strength.
major comments (2)
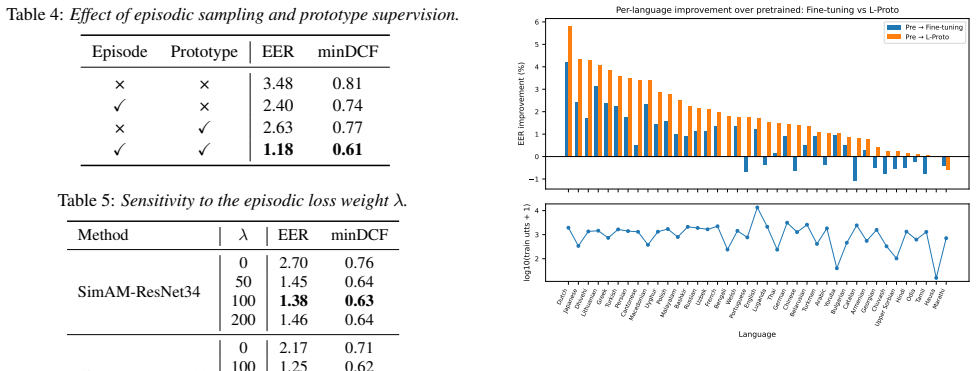
- [§3 (method) and §4 (experiments)] The central mechanism (language-consistent episodes) removes within-episode language shortcuts but never exposes the model to cross-lingual speaker pairs during training. This raises the risk that the learned embeddings remain partitioned by language rather than achieving true speaker invariance; the paper should provide direct evidence (e.g., same-speaker cross-language embedding distances or language-clustering metrics on the test set) that cross-lingual cues are retained rather than discarded.
- [Table 2] Table 2 (or equivalent results table): the reported improvements over random episodic sampling are presented without error bars, statistical significance tests, or dataset-size details. Given that the abstract itself contains no quantitative numbers, it is impossible to judge whether the gains survive conventional controls for hyperparameter sensitivity or data leakage.
minor comments (2)
- [Abstract] The abstract states 'consistent performance improvements' but supplies no numerical values, making it difficult for readers to assess effect size at a glance.
- [§3] Notation for the prototypical loss and episode construction should be introduced with explicit equations rather than prose descriptions only.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [§3 (method) and §4 (experiments)] The central mechanism (language-consistent episodes) removes within-episode language shortcuts but never exposes the model to cross-lingual speaker pairs during training. This raises the risk that the learned embeddings remain partitioned by language rather than achieving true speaker invariance; the paper should provide direct evidence (e.g., same-speaker cross-language embedding distances or language-clustering metrics on the test set) that cross-lingual cues are retained rather than discarded.
Authors: We agree that this is a valid concern: language-consistent episodes eliminate intra-episode language cues but do not directly optimize cross-lingual speaker pairs. While the multilingual training corpus still exposes the model to all languages across episodes, direct evidence of retained cross-lingual speaker structure is indeed missing. We will add the requested analyses (same-speaker cross-language distances and language-clustering metrics on the test set) to the revised manuscript. revision: yes
-
Referee: [Table 2] Table 2 (or equivalent results table): the reported improvements over random episodic sampling are presented without error bars, statistical significance tests, or dataset-size details. Given that the abstract itself contains no quantitative numbers, it is impossible to judge whether the gains survive conventional controls for hyperparameter sensitivity or data leakage.
Authors: We concur that error bars, significance testing, and dataset details are necessary for assessing robustness. We will revise Table 2 to report standard deviations over multiple runs, include statistical significance tests, and provide explicit dataset-size and split information. We will also add quantitative results to the abstract. revision: yes
Circularity Check
No significant circularity; empirical method with no self-referential derivations
full rationale
The paper describes a training strategy (language-consistent episodic sampling) and reports empirical gains on a benchmark. No equations, fitted parameters, or first-principles derivations appear in the abstract or description. The central claim is an empirical observation about performance improvements, not a mathematical reduction that equates outputs to inputs by construction. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing elements. This is a standard empirical proposal whose validity rests on external test results rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Speaker verification (SV) aims to determine whether two speech samples belong to the same speaker. Deep learn- ing has significantly advanced this task by learning speaker- discriminative representations directly from speech signals [1, 2, 3], achieving strong performance on standard benchmarks [4, 5, 6, 7]. However, multilingual speaker veri...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
By constructing language-consistent episodes, it stabilizes proto- type estimation during episodic learning
Method We propose L-Proto, a language-aware episodic prototypical training framework for multilingual speaker verification. By constructing language-consistent episodes, it stabilizes proto- type estimation during episodic learning. The framework con- sists of language-aware episode construction, streaming episode sampling, and episodic prototypical optim...
-
[3]
Experimental setup We evaluate SimAM-ResNet34 and SimAM-ResNet100 [27], ResNet-based speaker embedding encoders with simple atten- tion modules, using thewespeakertoolkit [28]
Experiments 3.1. Experimental setup We evaluate SimAM-ResNet34 and SimAM-ResNet100 [27], ResNet-based speaker embedding encoders with simple atten- tion modules, using thewespeakertoolkit [28]. The models are initialized from checkpoints pretrained on V oxBlink2 [7], fine-tuned on TidyV oiceX [11], and evaluated on the official TidyV oice Challenge develo...
-
[4]
By constructing single-language episodes, L-Proto reduces intra-episode linguistic variation and stabilizes prototype-based similarity learning
Conclusion This paper introduced L-Proto, a language-aware episodic pro- totypical training strategy for multilingual speaker verification. By constructing single-language episodes, L-Proto reduces intra-episode linguistic variation and stabilizes prototype-based similarity learning. Experiments on the TidyV oice Challenge benchmark show consistent improv...
-
[5]
All technical content and conclusions were de- veloped by the authors
Use of Generative AI Disclosure Generative AI tools (OpenAI GPT-5.2) were used for writing assistance, including language editing and minor revisions of the manuscript. All technical content and conclusions were de- veloped by the authors
-
[6]
RS-2019- II190079, Artificial Intelligence Graduate School Program (Ko- rea University); No
Acknowledgments This work was partly supported by Institute of Information & Communications Technology Planning & Evaluation (IITP) grants funded by the Korea government (MSIT) (No. RS-2019- II190079, Artificial Intelligence Graduate School Program (Ko- rea University); No. RS-2024-00336673, AI Technology for Interactive Communication of Language Impaired...
2019
-
[7]
Generalized end- to-end loss for speaker verification,
L. Wan, Q. Wang, A. Papir, and I. L. Moreno, “Generalized end- to-end loss for speaker verification,” inIEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 4879–4883
2018
-
[8]
ECAPA- TDNN: Emphasized channel attention, propagation and aggrega- tion in tdnn based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA- TDNN: Emphasized channel attention, propagation and aggrega- tion in tdnn based speaker verification,” inInterspeech, 2020, pp. 3830–3834
2020
-
[9]
Pushing the limits of raw waveform speaker recogni- tion,
J. weon Jung, Y . Kim, H.-S. Heo, B.-J. Lee, Y . Kwon, and J. S. Chung, “Pushing the limits of raw waveform speaker recogni- tion,” inInterspeech, 2022, pp. 2228–2232
2022
-
[10]
V oxceleb: Large-scale speaker verification in the wild,
A. Nagrani, J. S. Chung, W. Xie, and A. Zisserman, “V oxceleb: Large-scale speaker verification in the wild,”Computer Speech & Language, vol. 60, p. 101027, 2020
2020
-
[11]
V oxCeleb2: Deep speaker recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxCeleb2: Deep speaker recognition,” inInterspeech, 2018, pp. 1086–1090
2018
-
[12]
V oxblink: A large scale speaker verification dataset on camera,
Y . Lin, X. Qin, G. Zhao, M. Cheng, N. Jiang, H. Wu, and M. Li, “V oxblink: A large scale speaker verification dataset on camera,” inIEEE International Conference on Acoustics, Speech and Sig- nal Processing (ICASSP), 2024, pp. 10 271–10 275
2024
-
[13]
V oxBlink2: A 100k+ speaker recognition corpus and the open- set speaker-identification benchmark,
Y . Lin, M. Cheng, F. Zhang, Y . Gao, S. Zhang, and M. Li, “V oxBlink2: A 100k+ speaker recognition corpus and the open- set speaker-identification benchmark,” inInterspeech, 2024, pp. 4263–4267
2024
-
[14]
Cross- Lingual Speaker Verification with Domain-Balanced Hard Proto- type Mining and Language-Dependent Score Normalization,
J. Thienpondt, B. Desplanques, and K. Demuynck, “Cross- Lingual Speaker Verification with Domain-Balanced Hard Proto- type Mining and Language-Dependent Score Normalization,” in Interspeech 2020, 2020, pp. 756–760
2020
-
[15]
Language depen- dency in text-independent speaker verification,
R. Auckenthaler, M. Carey, and J. Mason, “Language depen- dency in text-independent speaker verification,” inIEEE Interna- tional Conference on Acoustics, Speech, and Signal Processing (ICASSP), vol. 1, 2001, pp. 441–444 vol.1
2001
-
[16]
Cross-lingual speaker verification: Evaluation on x-vector method,
H. Mandalapu, T. M. Elbo, R. Ramachandra, and C. Busch, “Cross-lingual speaker verification: Evaluation on x-vector method,” inIntelligent Technologies and Applications, S. Yildirim Yayilgan, I. S. Bajwa, and F. Sanfilippo, Eds. Cham: Springer International Publishing, 2021, pp. 215–226
2021
-
[17]
Tidyvoice: A curated multilingual dataset for speaker verification derived from common voice,
A. Farhadipour, J. Marquenie, S. Madikeri, and E. Chodroff, “Tidyvoice: A curated multilingual dataset for speaker verification derived from common voice,”arXiv preprint arXiv:2601.16358, 2026
-
[18]
Investigating language variability on the performance of speaker verification systems,
A. Vaheb, A. J. Choobbasti, S. H. E. M. Najafabadi, and S. Safavi, “Investigating language variability on the performance of speaker verification systems,” inSpeech and Computer, A. Kar- pov, O. Jokisch, and R. Potapova, Eds. Cham: Springer Interna- tional Publishing, 2018, pp. 718–727
2018
-
[19]
Speaker verification using end-to-end adversarial lan- guage adaptation,
J. Rohdin, T. Stafylakis, A. Silnova, H. Zeinali, L. Burget, and O. Plchot, “Speaker verification using end-to-end adversarial lan- guage adaptation,” inIEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2019, pp. 6006– 6010
2019
-
[20]
Cross-lingual text- independent speaker verification using unsupervised adversarial discriminative domain adaptation,
W. Xia, J. Huang, and J. H. Hansen, “Cross-lingual text- independent speaker verification using unsupervised adversarial discriminative domain adaptation,” inIEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), 2019, pp. 5816–5820
2019
-
[21]
Adversarial domain adaptation for speaker verification using partially shared network,
Z. Chen, S. Wang, and Y . Qian, “Adversarial domain adaptation for speaker verification using partially shared network,” inInter- speech, 2020, pp. 3017–3021
2020
-
[22]
Domain-adversarial training of neural networks,
Y . Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. March, and V . Lempitsky, “Domain-adversarial training of neural networks,”Journal of Machine Learning Re- search, vol. 17, no. 59, pp. 1–35, 2016
2016
-
[23]
Laspa: Language agnostic speaker disentanglement with prefix- tuned cross-attention,
A. Srinivas Menon, R. P. Gohil, K. Tripathi, and P. Wasnik, “Laspa: Language agnostic speaker disentanglement with prefix- tuned cross-attention,” inInterspeech, 2025, pp. 3623–3627
2025
-
[24]
Causally disentangled contrastive learning for multilingual speaker embed- dings,
M. Olijslager, S. S. M. Ziabari, and A. M. M. Alsahag, “Causally disentangled contrastive learning for multilingual speaker embed- dings,”arXiv preprint arXiv:2602.01363, 2026
-
[25]
Meta-generalization for domain-invariant speaker verification,
H. Zhang, L. Wang, K. A. Lee, M. Liu, J. Dang, and H. Meng, “Meta-generalization for domain-invariant speaker verification,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 31, pp. 1024–1036, 2023
2023
-
[26]
Bayesian Learning for Domain-Invariant Speaker Verification and Anti-Spoofing,
J. Li, M.-W. Mak, J. Rohdin, K. A. Lee, and H. Hermansky, “Bayesian Learning for Domain-Invariant Speaker Verification and Anti-Spoofing,” inInterspeech 2025, 2025, pp. 1123–1127
2025
-
[27]
Domain Agnos- tic Few-shot Learning for Speaker Verification,
S. Yang, D. Das, J. Cho, H. Park, and S. Yun, “Domain Agnos- tic Few-shot Learning for Speaker Verification,” inInterspeech, 2022, pp. 595–599
2022
-
[28]
Tackling the score shift in cross-lingual speaker verification by exploiting lan- guage information,
J. Thienpondt, B. Desplanques, and K. Demuynck, “Tackling the score shift in cross-lingual speaker verification by exploiting lan- guage information,” inIEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2022, pp. 7187– 7191
2022
-
[29]
XLS-R: Self-supervised cross-lingual speech representation learning at scale,
A. Babu, C. Wang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P. von Platen, Y . Saraf, J. Pino, A. Baevski, A. Con- neau, and M. Auli, “XLS-R: Self-supervised cross-lingual speech representation learning at scale,” inInterspeech, 2022, pp. 2278– 2282
2022
-
[30]
WavLM: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “WavLM: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[31]
Prototypical networks for small footprint text-independent speaker verification,
T. Ko, Y . Chen, and Q. Li, “Prototypical networks for small footprint text-independent speaker verification,” inIEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 6804–6808
2020
-
[32]
Improved meta-learning training for speaker verification,
Y . Chen, W. Guo, and B. Gu, “Improved meta-learning training for speaker verification,” inInterspeech, 2021, pp. 1049–1053
2021
-
[33]
Simple attention mod- ule based speaker verification with iterative noisy label detection,
X. Qin, N. Li, C. Weng, D. Su, and M. Li, “Simple attention mod- ule based speaker verification with iterative noisy label detection,” inIEEE International Conference on Acoustics, Speech and Sig- nal Processing (ICASSP), 2022, pp. 6722–6726
2022
-
[34]
Advancing speaker embedding learning: Wespeaker toolkit for research and produc- tion,
S. Wang, Z. Chen, B. Han, H. Wang, C. Liang, B. Zhang, X. Xi- ang, W. Ding, J. Rohdin, A. Silnovaet al., “Advancing speaker embedding learning: Wespeaker toolkit for research and produc- tion,”Speech Communication, vol. 162, p. 103104, 2024
2024
-
[35]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
2016
-
[36]
CAM++: A fast and efficient network for speaker verification using context- aware masking,
H. Wang, S. Zheng, Y . Chen, L. Cheng, and Q. Chen, “CAM++: A fast and efficient network for speaker verification using context- aware masking,” inInterspeech, 2023, pp. 5301–5305
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.