MagpieTTS-LF: Inference-Time Long-Form Speech Generation Without Training on Long-Form data
Pith reviewed 2026-06-26 22:26 UTC · model grok-4.3
The pith
MagpieTTS-LF produces coherent long-form speech from short-trained models by adding three inference-time changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MagpieTTS-LF shows that soft attention priors can steer monotonic alignment while retaining past and future context, a stateful inference algorithm can carry continuity across chunks, and history-aware text encoding can supply discourse-level information for prosody, together enabling coherent long-form output from a model never trained on long sequences.
What carries the argument
The three inference-time modifications—soft attention priors, stateful inference algorithm, and history-aware text encoding—that together preserve alignment context and prosodic information across chunks.
If this is right
- Long texts can be synthesized coherently without any additional training data or model updates.
- Prosodic continuity and speaker identity hold across sentence boundaries that would otherwise introduce artifacts.
- Discourse-level planning becomes possible even when the base model sees only isolated short inputs during training.
- The same base model can switch between short and long generation modes without retraining.
Where Pith is reading between the lines
- The same pattern of adding state and history at inference could reduce the need for longer context windows in other autoregressive models.
- This suggests that some apparent limits of short-trained models are actually limits of inference strategy rather than capacity.
- Deployed systems could adapt existing short models to book-length or multi-turn audio without new data collection.
Load-bearing premise
The three inference-time modifications are sufficient by themselves to remove prosodic drift and boundary artifacts from a model trained exclusively on short utterances.
What would settle it
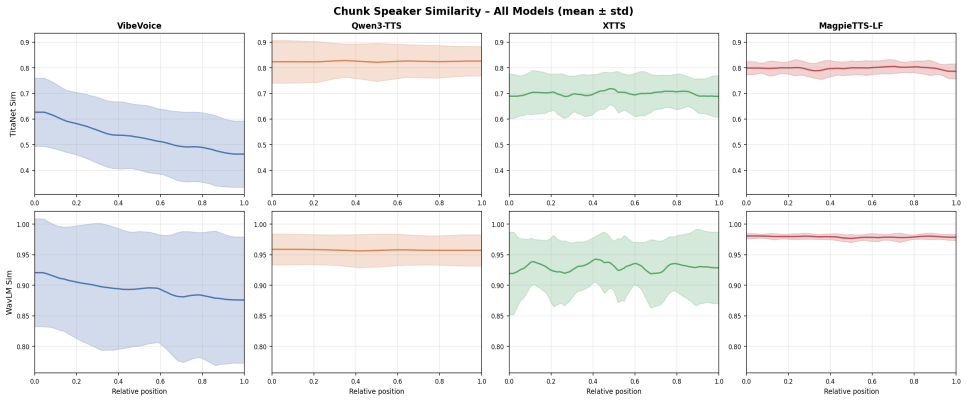
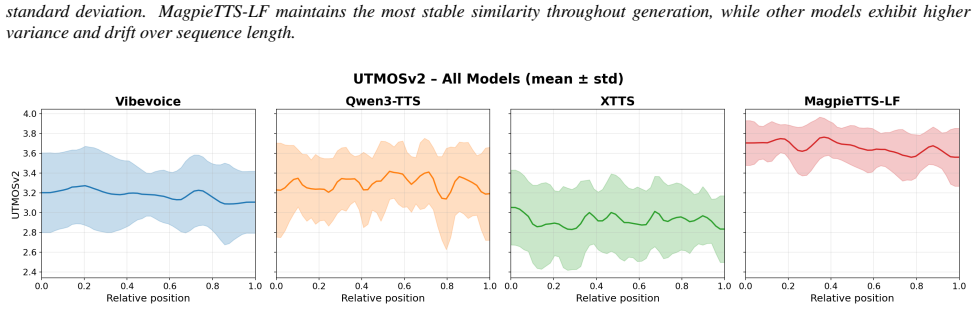
Long-form outputs generated with the three modifications show no improvement or worse scores than naive chunk concatenation on objective measures of long-range intelligibility and prosodic coherence.
Figures

read the original abstract
Neural Text-to-Speech (TTS) systems achieve remarkable quality on short utterances but long-form speech generation shows prosodic drift, speaker inconsistencies and sentence boundary artifacts. Existing approaches either compress sequences, increase context length or naively concatenate independently synthesized chunks. We present an inference-time approach called MagpieTTS-LF that enables MagpieTTS to produce coherent long-form speech without model retraining. Our method introduces three key innovations: (1) soft attention priors to guide monotonic alignment while preserving past and future context; (2) a stateful inference algorithm that maintains context across sentence chunks, ensuring prosodic continuity; (3) history-aware text encoding that uses past text for discourse-level prosodic planning. Experiments on long texts show significant improvements in long-range intelligibility, prosodic coherence, speaker consistency, and boundary naturalness compared to other baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that MagpieTTS-LF enables coherent long-form speech generation from a model trained only on short utterances via three inference-time innovations: soft attention priors to guide monotonic alignment, a stateful inference algorithm to maintain context across chunks, and history-aware text encoding for discourse-level prosody. It asserts that experiments on long texts demonstrate significant gains in long-range intelligibility, prosodic coherence, speaker consistency, and boundary naturalness relative to baselines, all without model retraining.
Significance. If the empirical results hold, the work would be significant because it offers a practical, training-free route to long-form TTS that sidesteps the data scarcity and computational cost of long-form training, directly addressing prosodic drift and boundary artifacts that limit current short-trained systems.
major comments (2)
- [Abstract] Abstract: the claim of 'significant improvements' in intelligibility, coherence, consistency, and naturalness supplies no quantitative metrics, baseline details, dataset descriptions, or statistical tests. This is load-bearing for the central claim that the three modifications suffice to eliminate drift and artifacts.
- [Method (stateful inference and attention priors)] Description of the stateful inference algorithm and soft attention priors: the manuscript contains no analysis of error accumulation across many chunks, no demonstration that the priors remain effective as history length grows, and no test of whether the stateful algorithm avoids compounding inconsistencies known to arise in short-trained models. This directly bears on the sufficiency assumption highlighted in the skeptic note.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight areas where the presentation of results and methodological analysis can be strengthened. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'significant improvements' in intelligibility, coherence, consistency, and naturalness supplies no quantitative metrics, baseline details, dataset descriptions, or statistical tests. This is load-bearing for the central claim that the three modifications suffice to eliminate drift and artifacts.
Authors: We agree that the abstract would be strengthened by including specific quantitative details. In the revised manuscript we will update the abstract to report key metrics (e.g., WER for intelligibility, prosody coherence scores, speaker similarity measures, and boundary naturalness MOS), name the baselines and datasets used, and note any statistical significance tests performed. revision: yes
-
Referee: [Method (stateful inference and attention priors)] Description of the stateful inference algorithm and soft attention priors: the manuscript contains no analysis of error accumulation across many chunks, no demonstration that the priors remain effective as history length grows, and no test of whether the stateful algorithm avoids compounding inconsistencies known to arise in short-trained models. This directly bears on the sufficiency assumption highlighted in the skeptic note.
Authors: We acknowledge that the current manuscript does not contain an explicit analysis of error accumulation or scaling behavior with history length. In the revision we will add a dedicated subsection with ablation experiments that vary the number of chunks and history length, quantify error propagation, and demonstrate that the stateful algorithm combined with the soft attention priors limits compounding inconsistencies relative to naive chunking baselines. revision: yes
Circularity Check
No circularity: inference-time algorithmic modifications with no equations or fitted inputs
full rationale
The paper describes three inference-time modifications (soft attention priors, stateful inference algorithm, history-aware text encoding) applied to a pre-trained short-utterance model. No equations, parameter fitting, self-citations as load-bearing premises, or derivations are present in the abstract or described method. Claims rest on experimental comparisons rather than any quantity defined in terms of the target long-form outputs themselves. This is the common case of a self-contained algorithmic proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction While advancements in large-scale generative modeling in TTS has enabled unprecedented naturalness and speaker similarity, yet most of the methods suffer from hallucinations, prosodic drift, and boundary artifacts as generation length grows. State- of-the-art models like Tortoise TTS [1], V ALL-E 2 [2], V ALL- E R [3], NaturalSpeech 2/3 [4, 5...
-
[2]
MagpieTTS-LF: Inference-Time Long-Form Speech Generation Without Training on Long-Form data
achieves a compression at 7.5 Hz, enabling up to 90 min- utes of speech generation in a single pass, however it sacrifices temporal resolution, representing each∼133msof audio with a single token. SpeechSSM [13] uses state-space models for theoretically infinite extrapolation. Streaming and block-wise methods such as CosyV oice 2 [14] employ block-wise at...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
In section2.1, we briefly go over the MagpieTTS model architecture
Methodology In this section, we present an inference-time approach for long- form speech generation that enables any chunk-based encoder- decoder TTS system to produce coherent speech without model retraining. In section2.1, we briefly go over the MagpieTTS model architecture. In section2.2, we describe the soft atten- tion priors that guide generation to...
-
[4]
Together, these metrics capture the major chal- lenges of long-form synthesis identified in our literature review
Experiments and Results We evaluate MagpieTTS-LF2 long-form generation against the state-of-the-art baselines across three dimensions: alignment robustness over long sequences, prosodic continuity at chunk boundaries, and speaker identity consistency, naturalness over long sequences. Together, these metrics capture the major chal- lenges of long-form synt...
1914
-
[5]
Conclusion We present MagpieTTS-LF, an inference-time approach to syn- thesize robust, coherent and natural sounding long-form speech without retraining on long-form data. Our method uses soft attention prior to guide monotonicity, a history-aware stateful chunk generation that helps maintain prosodic continuity and speaker consistency over the entirety o...
-
[6]
It was very minimally used to refine the lan- guage at some parts of the paper and with LATEXsyntax
Generative AI Use Disclosure Generative AI was used for checking grammar and spelling of the entire paper. It was very minimally used to refine the lan- guage at some parts of the paper and with LATEXsyntax
-
[7]
Better speech synthesis through scaling,
J. Betker, “Better speech synthesis through scaling,” https://github.com/neonbjb/tortoise-tts, 2023
2023
-
[8]
V ALL-E 2: Neural codec language models are hu- man parity zero-shot text to speech synthesizers,
S. Chen, S. Liu, L. Zhou, Y . Liu, X. Tan, J. Li, S. Zhao, Y . Qian, and F. Wei, “V ALL-E 2: Neural codec language models are hu- man parity zero-shot text to speech synthesizers,”arXiv preprint arXiv:2406.05370, 2024
-
[9]
Vall-e r: Robust and efficient zero-shot text-to-speech synthesis via monotonic alignment,
C. Zhang, S. Wanget al., “Vall-e r: Robust and efficient zero-shot text-to-speech synthesis via monotonic alignment,” arXiv preprint arXiv:2406.07855, 2024. [Online]. Available: https://arxiv.org/abs/2406.07855
-
[10]
Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers,
K. Shen, Z. Ju, X. Tan, Y . Liu, Y . Leng, L. He, T. Qin, S. Zhao, and J. Bian, “Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers,” inICLR 2024, April 2023
2024
-
[11]
Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, Y . Liu, Y . Leng, K. Song, S. Tang, Z. Wu, T. Qin, X.-Y . Li, W. Ye, S. Zhang, J. Bian, L. He, J. Li, and S. Zhao, “Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,” in ICML, June 2024
2024
-
[12]
V oicebox: Text-guided multilingual universal speech generation at scale,
M. Le, A. Vyas, B. Shi, B. Karrer, L. Sari, R. Moritz, M. Williamson, V . Manohar, Y . Adi, J. Mahadeokar, and W.-N. Hsu, “V oicebox: Text-guided multilingual universal speech generation at scale,” inAdvances in Neural Informa- tion Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, I...
2023
-
[13]
XTTS: a massively multilingual zero- shot text-to-speech model,
E. Casanova, C. Shulby, A. Aljafari, J. Meyer, R. Morais, S. Olayemi, and J. Weber, “XTTS: a massively multilingual zero- shot text-to-speech model,” inProc. Interspeech, 2024
2024
-
[14]
H. Huet al., “Qwen3-TTS technical report,”arXiv preprint arXiv:2601.15621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Improving Robustness of LLM-based Speech Synthesis by Learning Monotonic Alignment,
P. Neekhara, S. Hussain, S. Ghosh, J. Li, R. Valle, R. Badlani, and B. Ginsburg, “Improving Robustness of LLM-based Speech Synthesis by Learning Monotonic Alignment,” inProc. INTER- SPEECH 2024, 2024, pp. –
2024
-
[16]
Koel-TTS: Enhancing LLM based speech generation with preference alignment and classifier free guidance,
S. S. Hussain, P. Neekhara, X. Yang, E. Casanova, S. Ghosh, R. Fejgin, M. T. Desta, R. Valle, and J. Li, “Koel-TTS: Enhancing LLM based speech generation with preference alignment and classifier free guidance,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . ...
2025
-
[17]
Z. Du, Q. Chen, S. Zhang, K. Hu, H. Lu, Y . Yang, H. Hu, S. Zheng, Y . Gu, Z. Maet al., “CosyV oice: A scalable multi- lingual zero-shot text-to-speech synthesizer based on supervised semantic tokens,”arXiv preprint arXiv:2407.05407, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Z. Peng, J. Yu, W. Wang, Y . Chang, Y . Sun, L. Dong, Y . Zhu, W. Xu, H. Bao, Z. Wanget al., “VibeV oice technical report,”arXiv preprint arXiv:2508.19205, 2025
-
[19]
Structured state space decoder for speech recognition and synthesis,
K. Miyazaki, M. Murata, and T. Kosaka, “Structured state space decoder for speech recognition and synthesis,” inAPSIPA Annual Summit and Conference, 2022
2022
-
[20]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wanget al., “CosyV oice 2: Scalable stream- ing speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
HiGNN-TTS: Hierarchical prosody modeling with graph neural networks for expressive long-form TTS,
D. Guo, X. Zhu, L. Xue, T. Li, Y . Lv, Y . Jiang, and L. Xie, “HiGNN-TTS: Hierarchical prosody modeling with graph neural networks for expressive long-form TTS,” inProc. IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2023, pp. 1–7
2023
-
[22]
Long-Context Speech Synthesis with Context-Aware Memory,
Z. Li, X. Xing, J. Xing, H. Hu, H. Lu, and X. Xu, “Long-Context Speech Synthesis with Context-Aware Memory,” inInterspeech 2025, 2025, pp. 2455–2459
2025
-
[23]
Nanocodec: Towards high-quality ultra fast speech llm inference,
E. Casanova, P. Neekhara, R. Langman, S. Hussain, S. Ghosh, X. Yang, A. Jukic, J. Li, and B. Ginsburg, “Nanocodec: Towards high-quality ultra fast speech llm inference,” inProc. Interspeech 2025, 2025
2025
-
[24]
MLS: A large-scale multilingual dataset for speech research,
V . Pratap, Q. Xu, A. Sriram, G. Synnaeve, and R. Collobert, “MLS: A large-scale multilingual dataset for speech research,” in Proc. Interspeech, 2020, pp. 2757–2761
2020
-
[25]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProc. International Conference on Machine Learn- ing (ICML), 2023
2023
-
[26]
TitaNet: Neural model for speaker representation with 1D depth-wise separable convolu- tions and global context,
N. R. Koluguri, T. Park, and B. Ginsburg, “TitaNet: Neural model for speaker representation with 1D depth-wise separable convolu- tions and global context,” inICASSP 2022 – IEEE International Conference on Acoustics, Speech and Signal Processing, 2022, pp. 8102–8106
2022
-
[27]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, p. 1505–1518, Oct. 2022. [Online]....
-
[28]
UTMOS: UTokyo-SaruLab system for V oice- MOS challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab system for V oice- MOS challenge 2022,” inProc. Interspeech, 2022, pp. 4521– 4525
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.