The Gate Is Only as Honest as Its Contracts: ContractGuard for the Contract Layer of Risk-Aware Causal Gating
Pith reviewed 2026-06-26 20:56 UTC · model grok-4.3
The pith
ContractGuard enforces tool contract integrity to block effect forgery attacks that bypass Risk-Aware Causal Gating.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
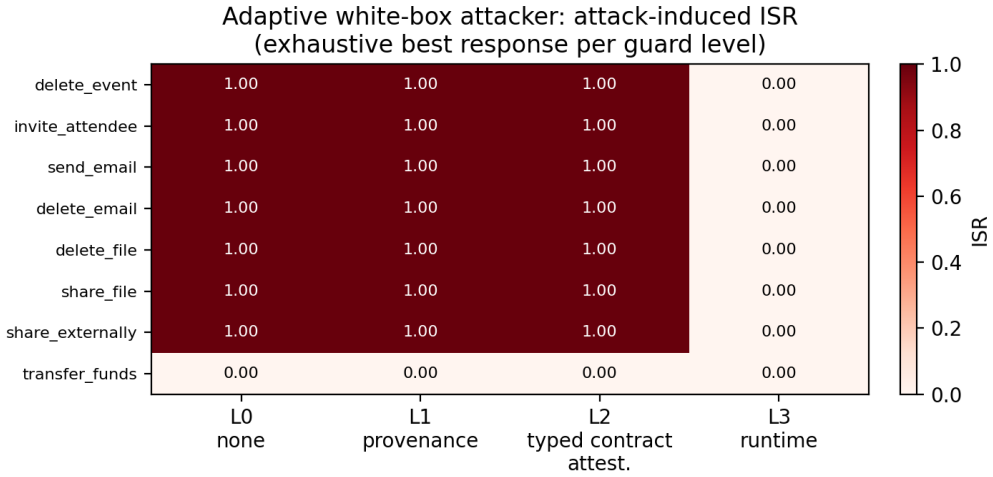
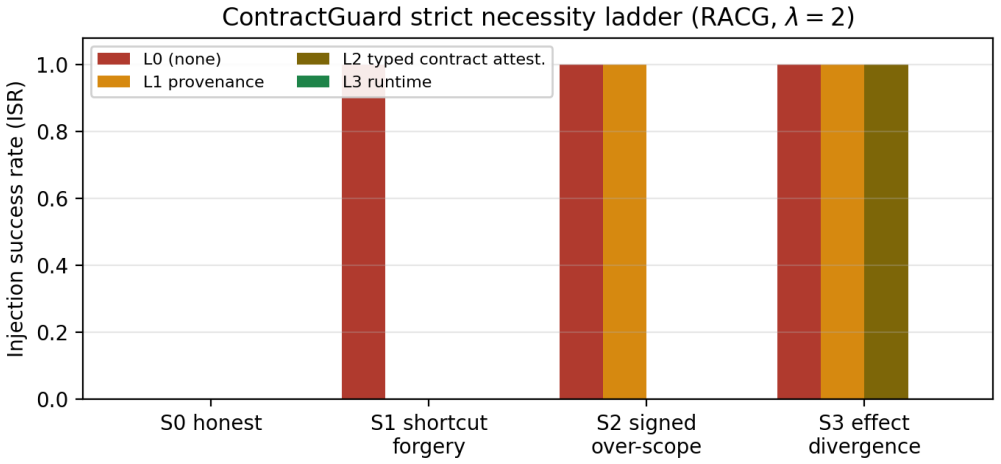
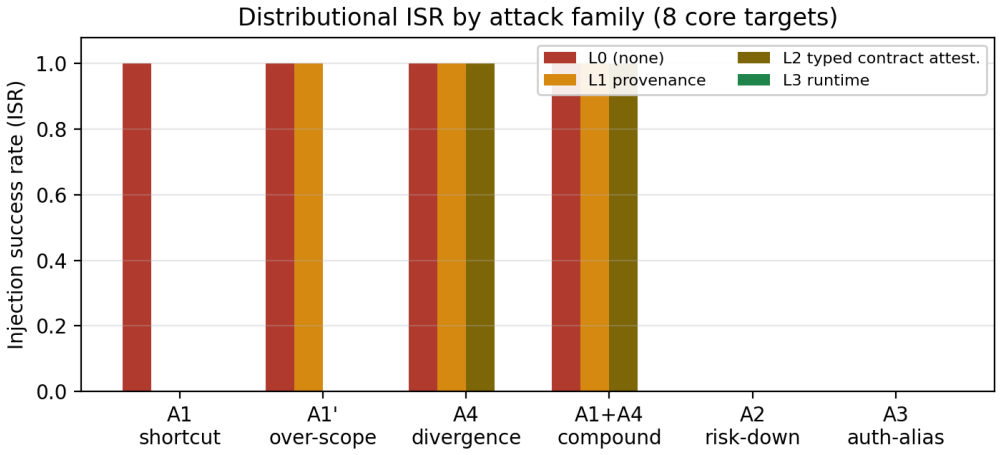
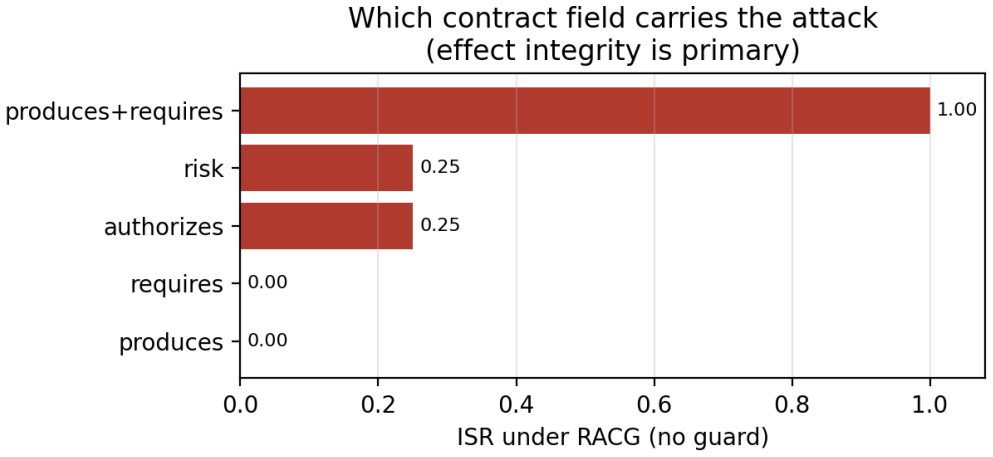
The structural guarantee of RACG relocates trust from the agent into the integrity of tool contracts; because the causal gate precedes the admissibility gate, an attacker who forges effects can place a dangerous tool on the visible path even if its risk label is correct, whereas risk-label tampering alone cannot. ContractGuard counters this by verifying signed provenance, attesting contract types, and checking runtime effects, eliminating successful injections on the benchmark and on the tested models without over-rejecting valid contracts.
What carries the argument
ContractGuard, the verifier that applies signed provenance, typed contract attestation, and runtime effect verification to protect the contracts read by the gate.
Load-bearing premise
The runtime effect verification and signed provenance mechanisms can be implemented and maintained without introducing bypassable vulnerabilities or requiring perfect trust in the contract signing authority.
What would settle it
A concrete attack in which an adversary forges a tool effect, passes ContractGuard's checks, and achieves injection success on one of the six evaluated models where the method previously reported zero success.
Figures
read the original abstract
Risk-Aware Causal Gating (RACG) defends tool-augmented LLM agents against indirect prompt injection by removing dangerous tools from the agent's visible action space, so that even a fully injection-compliant agent cannot call a tool it cannot see. We make three points. First, this structural guarantee does not eliminate the trust assumption behind safe tool use; it relocates it into the integrity of the tool contracts -- declared preconditions, effects, risk, and authorization -- that the gate reads, so an attacker who corrupts a contract can make the gate mis-decide without ever persuading the agent. Second, forging a tool's effects is strictly more dangerous than tampering with its risk label, because RACG applies a causal gate before its admissibility gate: an off-path tool is never exposed, so risk-relabeling alone fails, whereas effect forgery routes the dangerous tool onto the causal path and succeeds. Effect integrity, not the risk label, is the load-bearing assumption. Third, we introduce ContractGuard, a verifier between the registry and the gate that layers signed provenance, typed contract attestation, and runtime effect verification; on a controlled benchmark it restores injection success to zero against every modeled attack -- including an exhaustive white-box adaptive attacker -- without over-rejecting honest contracts, and the structural prediction is confirmed on six current-generation hosted models (Claude Opus 4.8, Sonnet 4.6, Haiku 4.5; Amazon Nova Premier and Nova 2 Lite; GPT-OSS-120B).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Risk-Aware Causal Gating (RACG) for tool-augmented LLM agents relocates the trust assumption from agent behavior to the integrity of tool contracts (preconditions, effects, risk, authorization). Effect forgery is strictly more dangerous than risk relabeling because the causal gate precedes the admissibility gate. ContractGuard is introduced as a verifier between registry and gate that layers signed provenance, typed attestation, and runtime effect verification; on a controlled benchmark it restores injection success to zero against all modeled attacks including an exhaustive white-box adaptive attacker, without over-rejecting honest contracts, with the structural prediction confirmed on six hosted models (Claude Opus 4.8, Sonnet 4.6, Haiku 4.5; Amazon Nova Premier and Nova 2 Lite; GPT-OSS-120B).
Significance. If the mechanisms hold, the work usefully identifies that effect integrity (not risk labels) is the load-bearing assumption in contract-based gating and supplies a concrete layered defense. The empirical zero-success result against a modeled adaptive attacker on a controlled benchmark, plus confirmation across current models, would strengthen practical defenses for agent tool use. No machine-checked proofs or parameter-free derivations are present, but the structural distinction between attack vectors is a clear conceptual contribution.
major comments (1)
- [Abstract] Abstract: The central claim that ContractGuard 'restores injection success to zero against every modeled attack -- including an exhaustive white-box adaptive attacker' is load-bearing. The description of the three layers (signed provenance, typed attestation, runtime effect verification) supplies no formal argument, reduction, or security model showing that these layers resist adaptive corruption of the verifier, attestation forgery, or verification-oracle misuse; the controlled-benchmark result therefore does not address whether new attack surfaces are introduced.
minor comments (1)
- [Abstract] Abstract: The phrase 'six current-generation hosted models' is listed with version numbers but the manuscript does not state the exact evaluation protocol or what 'structural prediction is confirmed' means in quantitative terms.
Simulated Author's Rebuttal
We thank the referee for the careful review and the identification of the load-bearing claim in the abstract. We respond to the single major comment below, clarifying the empirical scope of our results while acknowledging the absence of a formal security model.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that ContractGuard 'restores injection success to zero against every modeled attack -- including an exhaustive white-box adaptive attacker' is load-bearing. The description of the three layers (signed provenance, typed attestation, and runtime effect verification) supplies no formal argument, reduction, or security model showing that these layers resist adaptive corruption of the verifier, attestation forgery, or verification-oracle misuse; the controlled-benchmark result therefore does not address whether new attack surfaces are introduced.
Authors: We agree that the manuscript supplies no formal argument, reduction, or security model proving that the three layers resist adaptive corruption of the verifier itself, attestation forgery beyond the modeled cases, or verification-oracle misuse. The central claim is strictly empirical and scoped to the controlled benchmark, which explicitly includes an exhaustive white-box adaptive attacker targeting contract forgery vectors. In that benchmark, the layered defenses (signed provenance, typed attestation, runtime effect verification) restored zero injection success without over-rejecting honest contracts. The evaluation therefore addresses the modeled contract-layer attacks but does not claim to close new attack surfaces introduced by the verifier component or oracle. We can revise the abstract and add a limitations paragraph to emphasize this empirical scope and the threat-model boundaries. revision: partial
Circularity Check
No significant circularity; new system proposal without self-referential derivations or fitted predictions
full rationale
The paper proposes ContractGuard as a new verifier architecture layering signed provenance, typed attestation, and runtime effect verification between registry and gate. No equations, parameters, or derivations appear in the abstract or described claims. The assertion that it restores injection success to zero is presented as an empirical benchmark outcome on controlled setups and hosted models, not as a mathematical prediction that reduces to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The central claim rests on the described mechanisms rather than circular reduction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Lingering Authority: Revocable Resource-and-Effect Capabilities for Coding Agents
PORTICO is a revocable capability reference monitor for coding agents that enforces task contracts via grant-invoke-closure lifecycles and rejects post-closure reuses while preserving task success.
Reference graph
Works this paper leans on
-
[1]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models,” inInternational Conference on Learning Representations, 2023. [Online]. Available: https://arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[2]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” inAdvances in Neural Information Processing Systems, 2023. [Online]. Available: https://arxiv.org/abs/2302.04761
Pith/arXiv arXiv 2023
-
[3]
Toolllm: Facilitating large language models to master 16000+ real-world apis,
Y. Qin, S. Liang, Y. Ye, K. Zhu, L. Yan, Y. Lu, Y. Lin, X. Cong, X. Tang, B. Qian, S. Zhao, R. Tian, R. Xie, J. Zhou, M. Gerstein, D. Li, Z. Liu, and M. Sun, “Toolllm: Facilitating large language models to master 16000+ real-world apis,” inInternational Conference on Learning Representations,
-
[4]
Available: https://arxiv.org/abs/2307.16789
[Online]. Available: https://arxiv.org/abs/2307.16789
-
[5]
L. G. Iyer and R. S. Babu, “Capability minimization as a safety primitive: Risk-aware causal gating for least-privilege llm agents,” 2026. [Online]. Available: https://arxiv.org/abs/2606.13884
arXiv 2026
-
[6]
The protection of information in computer systems,
J. H. Saltzer and M. D. Schroeder, “The protection of information in computer systems,”Proceedings of the IEEE, vol. 63, no. 9, pp. 1278–1308, 1975
1975
-
[7]
Toolchoiceconfusion: Causal minimal tool filtering for reliable llm agents,
R. S. Babu and L. G. Iyer, “Toolchoiceconfusion: Causal minimal tool filtering for reliable llm agents,” 2026. [Online]. Available: https://arxiv.org/abs/2606.06284
Pith/arXiv arXiv 2026
-
[8]
Contract2tool: Learning preconditions and effects for reliable tool-augmented llm agents,
L. G. Iyer and R. S. Babu, “Contract2tool: Learning preconditions and effects for reliable tool-augmented llm agents,” 2026. [Online]. Available: https://arxiv.org/abs/2606.07904
Pith/arXiv arXiv 2026
-
[9]
Identifying the risks of lm agents with an lm-emulated sandbox,
Y. Ruan, H. Dong, A. Wang, S. Pitis, Y. Zhou, J. Ba, Y. Dubois, C. J. Maddison, and T. Hashimoto, “Identifying the risks of lm agents with an lm-emulated sandbox,”International Conference on Learning Representations, 2024. [Online]. Available: https://arxiv.org/abs/2309.15817
Pith/arXiv arXiv 2024
-
[10]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,
E. Debenedetti, J. Zhang, M. Balunović, L. Beurer-Kellner, M. Fischer, and F. Tramèr, “Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,”Advances in Neural Information Processing Systems, 2024. [Online]. Available: https://arxiv.org/abs/2406.13352
Pith/arXiv arXiv 2024
-
[11]
InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents,
Q. Zhan, Z. Liang, Z. Ying, and D. Kang, “InjecAgent: Benchmarking indirect prompt injections in tool-integrated large language model agents,” in Findings of the Association for Computational Linguistics: ACL 2024, 2024. [Online]. Available: https://arxiv.org/abs/2403.02691
Pith/arXiv arXiv 2024
-
[12]
in-toto: Providing farm-to-table guarantees for bits and bytes,
S. Torres-Arias, H. Afzali, T. K. Kuppusamy, R. Curtmola, and J. Cappos, “in-toto: Providing farm-to-table guarantees for bits and bytes,” in28th USENIX Security Symposium, 2019. [Online]. Available: https://www.usenix.org/conference/usenixsecurity19/presentation/torres-arias
2019
-
[13]
SLSA: Supply-chain levels for software artifacts,
Open Source Security Foundation, “SLSA: Supply-chain levels for software artifacts,” 2023, slsa.dev. [Online]. Available: https://slsa.dev/
2023
-
[14]
Robust composition: Towards a unified approach to access control and concurrency control,
M. S. Miller, “Robust composition: Towards a unified approach to access control and concurrency control,” inPhD thesis, Johns Hopkins University, 2006
2006
-
[15]
The Joe-E language specification (draft),
A. Mettler and D. Wagner, “The Joe-E language specification (draft),” inTechnical Report, UC Berkeley, 2010. [Online]. Available: https://www2.eecs.berkeley.edu/Pubs/TechRpts/2008/EECS-2008-91.html
2010
-
[16]
Protecting privacy using the decentralized label model,
A. C. Myers and B. Liskov, “Protecting privacy using the decentralized label model,”ACM Transactions on Software Engineering and Methodology, vol. 9, no. 4, pp. 410–442, 2000
2000
-
[17]
Agentbench: Evaluating llms as agents,
X. Liu, H. Yu, H. Zhang, Y. Xu, X. Lei, H. Lai, Y. Gu, H. Ding, K. Men, K. Yang, S. Zhang, X. Deng, A. Zeng, Z. Du, C. Zhang, S. Shen, T. Zhang, Y. Su, H. Sun, M. Huang, Y. Dong, and J. Tang, “Agentbench: Evaluating llms as agents,” inInternational Conference on Learning Representations,
-
[18]
Available: https://arxiv.org/abs/2308.03688
[Online]. Available: https://arxiv.org/abs/2308.03688
-
[19]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection,” inProceedings of the 16th ACM Workshop on Artificial Intelligence and Security, 2023. [Online]. Available: https://arxiv.org/abs/2302.12173
Pith/arXiv arXiv 2023
-
[20]
Ignore previous prompt: Attack techniques for language models,
F. Perez and I. Ribeiro, “Ignore previous prompt: Attack techniques for language models,” inNeurIPS ML Safety Workshop, 2022. [Online]. Available: https://arxiv.org/abs/2211.09527
Pith/arXiv arXiv 2022
-
[21]
The dual LLM pattern for building ai assistants that can resist prompt injection,
S. Willison, “The dual LLM pattern for building ai assistants that can resist prompt injection,” 2023, simonwillison.net. [Online]. Available: https://simonwillison.net/2023/Apr/25/dual-llm-pattern/
2023
-
[22]
Defeating prompt injections by design,
E. Debenedetti, I. Shumailov, T. Fan, J. Hayes, N. Carlini, D. Fabian, C. Kern, C. Shi, A. Terzis, and F. Tramèr, “Defeating prompt injections by design,” inarXiv preprint arXiv:2503.18813, 2025. [Online]. Available: https://arxiv.org/abs/2503.18813
Pith/arXiv arXiv 2025
-
[23]
R-judge: Benchmarking safety risk awareness for llm agents,
T. Yuan, Z. He, L. Dong, Y. Wang, R. Zhao, T. Xia, L. Xu, B. Zhou, F. Li, Z. Zhang, R. Wang, and G. Liu, “R-judge: Benchmarking safety risk awareness for llm agents,”Findings of the Association for Computational Linguistics: EMNLP 2024, 2024. [Online]. Available: https://arxiv.org/abs/2401.10019
arXiv 2024
-
[24]
The confused deputy: (or why capabilities might have been invented),
N. Hardy, “The confused deputy: (or why capabilities might have been invented),”ACM SIGOPS Operating Systems Review, vol. 22, no. 4, pp. 36–38, 1988
1988
-
[25]
Language-based information-flow security,
A. Sabelfeld and A. C. Myers, “Language-based information-flow security,”IEEE Journal on Selected Areas in Communications, vol. 21, no. 1, pp. 5–19, 2003
2003
-
[26]
Model cards for model reporting,
M. Mitchell, S. Wu, A. Zaldivar, P. Barnes, L. Vasserman, B. Hutchinson, E. Spitzer, I. D. Raji, and T. Gebru, “Model cards for model reporting,” in Proceedings of the Conference on Fairness, Accountability, and Transparency, 2019. [Online]. Available: https://arxiv.org/abs/1810.03993
Pith/arXiv arXiv 2019
-
[27]
Function calling and the Chat Completions api,
OpenAI, “Function calling and the Chat Completions api,” 2023, platform.openai.com. [Online]. Available: https://platform.openai.com/docs/guides/ function-calling
2023
-
[28]
Tool use (function calling) with the Claude api,
Anthropic, “Tool use (function calling) with the Claude api,” 2024, docs.anthropic.com. [Online]. Available: https://docs.anthropic.com/en/docs/ build-with-claude/tool-use
2024
-
[29]
Model context protocol,
——, “Model context protocol,” 2024, modelcontextprotocol.io. [Online]. Available: https://modelcontextprotocol.io
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.