Lingering Authority: Revocable Resource-and-Effect Capabilities for Coding Agents
Pith reviewed 2026-06-26 10:10 UTC · model grok-4.3
The pith
PORTICO prevents coding agents from reusing resources or causing forbidden effects after their justifying task episode closes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
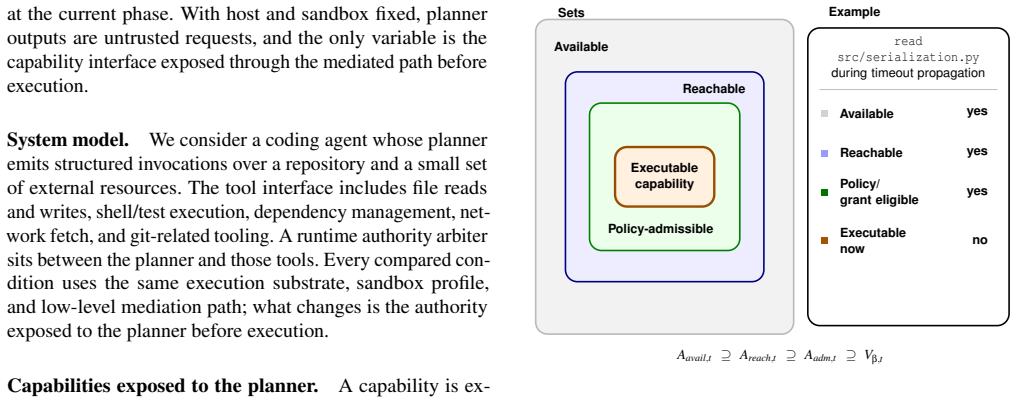
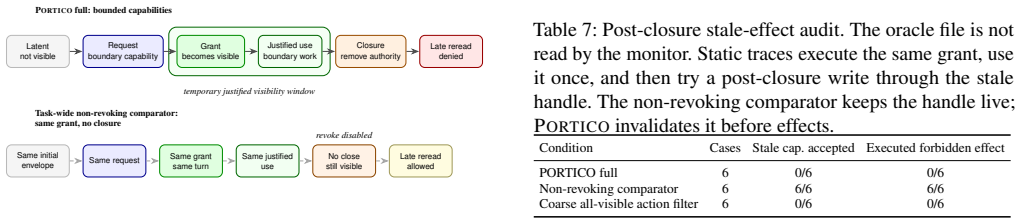
PORTICO is a reference monitor that materializes capability expansions as opaque, epoch-bound handles through a request-grant-invoke lifecycle. Closure removes those handles from the next planner interface and rejects stale replay before side effects. In controlled coding-agent tasks, PORTICO records no executed contract-forbidden effects, rejects 10/10 post-closure reuses, and shows 0/6 forbidden effects in a stale-write audit, while a non-revoking comparator permits 10/10 reuses and 6/6 forbidden effects; both systems match on task success, scope compliance, and all pre-closure decisions. Scripted traces and live model traces over file writes, git mutation, and network egress reproduce the
What carries the argument
The PORTICO reference monitor, which compiles an explicit task contract into initial capabilities, grant rules, trusted closure predicates, and global deny rules, then enforces revocation via epoch-bound handles.
If this is right
- Controlled grants recover boundary work that a fixed narrow envelope would block.
- On the closure slice, task success, scope compliance, and pre-closure decisions remain identical to the non-revoking comparator.
- PORTICO rejects all 10/10 post-closure reuses while the comparator permits all 10/10.
- A deterministic stale-write audit records 0/6 executed forbidden effects versus 6/6 for the comparator.
- Broad request exposure in a four-episode diagnostic preserves zero executed forbidden effects while raising blocked proposals from 67 to 84.
Where Pith is reading between the lines
- The same contract-driven revocation pattern could be tested on agents that interact with external services beyond file and git operations.
- Extending the closure predicates to handle concurrent subtasks might reduce the observed increase in blocked proposals.
- Real-repository runs suggest the lifecycle can be exercised on live project layouts without requiring changes to the underlying language model.
- The approach opens the possibility of policy evolution that tracks task progress rather than relying on static initial envelopes.
Load-bearing premise
The monitor assumes mediated tools and a sound typed catalog.
What would settle it
A controlled run in which PORTICO allows even one contract-forbidden effect to execute after the relevant closure would falsify the reported safety result.
Figures

read the original abstract
Coding agents often receive broad tool access for an entire task, even when a resource is needed only for one subgoal. We call this gap lingering authority: a temporary resource/effect capability remains exposed after the episode that justified it has closed. PORTICO is a reference monitor for revocable capabilities exposed to the planner. It compiles an explicit task contract into initial capabilities, grant rules, trusted closure predicates, and global deny rules. A request-grant-invoke lifecycle materializes expansions as opaque, epoch-bound handles. Closure removes those handles from the next planner interface and rejects stale replay before side effects. The monitor assumes mediated tools and a sound typed catalog. In controlled coding-agent tasks, PORTICO records no executed contract-forbidden effects in the evaluated runs, while controlled grants recover boundary work blocked by a fixed narrow envelope. A non-revoking comparator receives the same initial envelope and the same grants at the same turns. On the closure slice, both systems match task success, scope compliance, and all pre-closure decisions; PORTICO then rejects 10/10 post-closure reuses, while the comparator permits 10/10. A deterministic stale-write audit records 0/6 versus 6/6 executed forbidden effects. Scripted traces and six live model traces over file writes, git mutation, and network egress show the same split. In a four-episode same-policy diagnostic, broad request exposure preserves zero executed forbidden effects but raises blocked proposals from 67 to 84. Frozen real-repository runs, with commits and traces recorded, exercise the same lifecycle on real project layouts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PORTICO, a reference monitor that compiles task contracts into revocable, epoch-bound capabilities for coding agents. It enforces a request-grant-invoke lifecycle with closure predicates and deny rules to eliminate lingering authority after subgoals close. In controlled experiments on scripted traces and live model runs involving file writes, git mutations, and network egress, PORTICO records zero executed contract-forbidden effects post-closure (rejecting 10/10 reuses and 0/6 stale writes), while a non-revoking comparator permits all 10/10 reuses and 6/6 forbidden effects; task success and pre-closure compliance remain matched.
Significance. If the results hold under the stated assumptions, the work supplies a practical, contract-driven mechanism for limiting authority exposure in AI coding agents, directly addressing a security gap in tool-using planners. The controlled comparisons, including the deterministic stale-write audit and frozen real-repository runs with recorded commits and traces, provide concrete, falsifiable evidence of the revocation lifecycle's effect; the four-episode diagnostic further isolates the impact of broad request exposure on blocked proposals.
major comments (2)
- [Abstract] Abstract and experimental evaluation: the central claim that PORTICO produces zero executed forbidden effects (0/6 in the stale-write audit, 10/10 post-closure rejections) is conditioned on the unverified assumptions of complete tool mediation and a sound typed catalog. No coverage argument, proof, or audit is supplied showing that the catalog classifies every side-effect of the file, git, and network tools appearing in the scripted and live traces; if either assumption fails for a single operation, the observed split versus the comparator cannot be attributed to the revocation mechanism.
- [Experimental evaluation] Experimental setup (controlled tasks and live model traces): the methodology reports that both systems receive identical initial envelopes and grants, yet supplies no verification step or coverage metric confirming that all tool invocations in the evaluated runs were in fact mediated through the reference monitor. This verification is load-bearing for the claim that the zero forbidden effects result from PORTICO rather than from incomplete tool exposure in the test harness.
minor comments (1)
- [Abstract] The abstract states that 'controlled grants recover boundary work blocked by a fixed narrow envelope' but does not define the envelope construction or report the quantitative recovery rate; a brief clarification or table entry would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the importance of verifying the mediation assumptions in our experiments. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental evaluation: the central claim that PORTICO produces zero executed forbidden effects (0/6 in the stale-write audit, 10/10 post-closure rejections) is conditioned on the unverified assumptions of complete tool mediation and a sound typed catalog. No coverage argument, proof, or audit is supplied showing that the catalog classifies every side-effect of the file, git, and network tools appearing in the scripted and live traces; if either assumption fails for a single operation, the observed split versus the comparator cannot be attributed to the revocation mechanism.
Authors: The manuscript explicitly states that the monitor assumes mediated tools and a sound typed catalog. The experimental results, including the zero forbidden effects, are presented under these assumptions. We do not supply a coverage argument or proof because the contribution centers on the revocable capability lifecycle rather than exhaustive tool verification. In the test harness, tool invocations are mediated by construction for the evaluated operations. Since the comparator uses the identical harness, the performance split isolates the effect of revocation. We will revise the manuscript to expand the discussion of the catalog and mediation assumptions in the abstract and evaluation sections. revision: partial
-
Referee: [Experimental evaluation] Experimental setup (controlled tasks and live model traces): the methodology reports that both systems receive identical initial envelopes and grants, yet supplies no verification step or coverage metric confirming that all tool invocations in the evaluated runs were in fact mediated through the reference monitor. This verification is load-bearing for the claim that the zero forbidden effects result from PORTICO rather than from incomplete tool exposure in the test harness.
Authors: We agree that an explicit verification step would strengthen the attribution. The current description indicates that the harness provides the same envelopes and that tools are accessed via the monitor, but does not include a separate coverage metric or audit log. In revision, we will add details on the mediation layer in the experimental setup to confirm that all invocations in the scripted and live traces were routed through PORTICO, thereby supporting that the results stem from the revocation mechanism. revision: partial
Circularity Check
No circularity; experimental claims rest on direct comparisons without self-referential derivations or load-bearing self-citations
full rationale
The paper describes a reference monitor (PORTICO) and reports results from scripted traces, live model runs, and audits comparing it to a non-revoking comparator. No equations, fitted parameters, or derivation chains appear. The central claims (zero forbidden effects under PORTICO vs. 6/6 under comparator) are produced by the experimental setup itself rather than by any reduction to prior self-citations or definitional identities. The stated assumptions (mediated tools, sound catalog) are explicit preconditions but are not used to derive the observed split; they are simply the conditions under which the monitor operates. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption mediated tools and a sound typed catalog
invented entities (1)
-
PORTICO
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt in- jection
Sahar Abdelnabi, Kai Greshake, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt in- jection. InProceedings of the 16th ACM Workshop on Artificial Intelligence and Security, AISec ’23, pages 79–90, Copenhagen, Denmark, 2023. Association...
2023
-
[2]
Zico Kolter, Matt Fredrik- son, Yarin Gal, and Xander Davies
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, J. Zico Kolter, Matt Fredrik- son, Yarin Gal, and Xander Davies. AgentHarm: A benchmark for measuring harmfulness of LLM agents. InThe Thirteenth International Conference on Learning Representations, Singapore, 2025. OpenReview.net
2025
-
[3]
Con- tract2Tool: Learning preconditions and effects for reli- able tool-augmented LLM agents
Rahul Suresh Babu and Laxmipriya Ganesh Iyer. Con- tract2Tool: Learning preconditions and effects for reli- able tool-augmented LLM agents. arXiv:2606.07904, 2026
Pith/arXiv arXiv 2026
-
[4]
Tool- ChoiceConfusion: Causal minimal tool filtering for reli- able LLM agents
Rahul Suresh Babu and Laxmipriya Ganesh Iyer. Tool- ChoiceConfusion: Causal minimal tool filtering for reli- able LLM agents. arXiv:2606.06284, 2026
Pith/arXiv arXiv 2026
-
[5]
Design patterns for securing LLM agents against prompt injections
Luca Beurer-Kellner, Beat Buesser, Ana-Maria Cre¸ tu, Edoardo Debenedetti, Daniel Dobos, Daniel Fabian, Marc Fischer, David Froelicher, Kathrin Grosse, Daniel Naeff, Ezinwanne Ozoani, Andrew Paverd, Florian Tramèr, and Václav V olhejn. Design patterns for securing LLM agents against prompt injections. arXiv:2506.08837, 2025
arXiv 2025
-
[6]
Taylor, Krishnamurthy Dj Dvijotham, and Alexandre Lacoste
Rishika Bhagwatkar, Kevin Kasa, Abhay Puri, Gabriel Huang, Irina Rish, Graham W. Taylor, Krishnamurthy Dj Dvijotham, and Alexandre Lacoste. Indirect prompt injections: Are firewalls all you need, or stronger bench- marks? arXiv:2510.05244, 2025
arXiv 2025
-
[7]
AgentBound: Securing execution boundaries of AI agents.Proceedings of the ACM on Software Engineering, 3(FSE), 2026
Christoph Bühler, Matteo Biagiola, Luca Di Grazia, and Guido Salvaneschi. AgentBound: Securing execution boundaries of AI agents.Proceedings of the ACM on Software Engineering, 3(FSE), 2026
2026
-
[8]
LlamaFire- wall: An open source guardrail system for building se- cure AI agents
Sahana Chennabasappa, Cyrus Nikolaidis, Daniel Song, David Molnar, Stephanie Ding, Shengye Wan, Spencer Whitman, Lauren Deason, Nicholas Doucette, Abraham Montilla, Alekhya Gampa, Beto de Paola, Dominik Gabi, James Crnkovich, Jean-Christophe Testud, Kat He, Rash- nil Chaturvedi, Wu Zhou, and Joshua Saxe. LlamaFire- wall: An open source guardrail system fo...
arXiv 2025
-
[9]
Jian Cui, Zichuan Li, Luyi Xing, and Xiaojing Liao. Maris: A formally verifiable privacy policy enforce- ment paradigm for multi-agent collaboration systems. arXiv:2505.04799, 2025
Pith/arXiv arXiv 2025
-
[10]
Defeating prompt injections by design
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tramèr. Defeating prompt injections by design. InIEEE Con- ference on Secure and Trustworthy Machine Learning (SaTML), Munich, Germany, 2026
2026
-
[11]
AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents. InAd- vances in Neural Information Processing Systems, vol- ume 37, pages 82895–82920, Vancouver, BC, Canada,
-
[12]
Curran Associates, Inc
-
[13]
Mind2Web: Towards a generalist agent for the web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2Web: Towards a generalist agent for the web. InAdvances in Neural Information Processing Systems, volume 36, pages 28091–28114, New Orleans, LA, USA, 2023. Cur- ran Associates, Inc
2023
-
[14]
Laradji, Manuel Del Verme, Tom Marty, David Vázquez, Nicolas Chapados, and Alexandre Lacoste
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Is- sam H. Laradji, Manuel Del Verme, Tom Marty, David Vázquez, Nicolas Chapados, and Alexandre Lacoste. WorkArena: How capable are web agents at solving common knowledge work tasks? InForty-first Interna- tional Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 116...
2024
-
[15]
Gray and David R
Cary G. Gray and David R. Cheriton. Leases: An effi- cient fault-tolerant mechanism for distributed file cache 15 consistency. InProceedings of the Twelfth ACM Sympo- sium on Operating Systems Principles, pages 202–210, 1989
1989
-
[16]
MCPXKIT: The unified toolkit for analyzing model context protocol security
Yongjian Guo, Puzhuo Liu, Wanlun Ma, Zehang Deng, Xiaogang Zhu, Peng Di, Xi Xiao, and Sheng Wen. MCPXKIT: The unified toolkit for analyzing model context protocol security. arXiv:2508.12538, 2025
Pith/arXiv arXiv 2025
-
[17]
SMCP: Secure model context protocol
Xinyi Hou, Shenao Wang, Yifan Zhang, Ziluo Xue, Yan- jie Zhao, Cai Fu, and Haoyu Wang. SMCP: Secure model context protocol. arXiv:2602.01129, 2026
arXiv 2026
-
[18]
Model context protocol (MCP): Land- scape, security threats, and future research directions
Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. Model context protocol (MCP): Land- scape, security threats, and future research directions. arXiv:2503.23278, 2025
Pith/arXiv arXiv 2025
-
[19]
MalTool: Malicious tool attacks on LLM agents
Yuepeng Hu, Yuqi Jia, Mengyuan Li, Dawn Song, and Neil Gong. MalTool: Malicious tool attacks on LLM agents. arXiv:2602.12194, 2026
Pith/arXiv arXiv 2026
-
[20]
Laxmipriya Ganesh Iyer and Rahul Suresh Babu. Ca- pability minimization as a safety primitive: Risk- aware causal gating for least-privilege LLM agents. arXiv:2606.13884, 2026
arXiv 2026
-
[21]
Laxmipriya Ganesh Iyer and Rahul Suresh Babu. The gate is only as honest as its contracts: Contract- Guard for the contract layer of risk-aware causal gating. arXiv:2606.18550, 2026
Pith/arXiv arXiv 2026
-
[22]
Saeid Jamshidi, Arghavan Moradi Dakhel, Kawser Wazed Nafi, and Foutse Khomh. Se- mantic attacks on tool-augmented LLMs: Securing the model context protocol against descriptor-level manipulation. arXiv:2512.06556, 2025
Pith/arXiv arXiv 2025
-
[23]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InThe Twelfth International Conference on Learning Representations, Vienna, Aus- tria, 2024. OpenReview.net
2024
-
[24]
Prompt flow integrity to prevent privilege escalation in LLM agents
Juhee Kim, Woohyuk Choi, and Byoungyoung Lee. Prompt flow integrity to prevent privilege escalation in LLM agents. arXiv:2503.15547, 2025
arXiv 2025
-
[25]
Minbeom Kim, Mihir Parmar, Phillip Wallis, Lesly Mi- culicich, Kyomin Jung, Krishnamurthy Dj Dvijotham, Long T. Le, and Tomas Pfister. CausalArmor: Efficient indirect prompt injection guardrails via causal attribu- tion. arXiv:2602.07918, 2026
arXiv 2026
-
[26]
VisualWebArena: Evaluating multimodal agents on re- alistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neu- big, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. VisualWebArena: Evaluating multimodal agents on re- alistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 881–905...
2024
-
[27]
Quyu Kong, Xu Zhang, Zhenyu Yang, Nolan Gao, Chen Liu, Panrong Tong, Chenglin Cai, Hanzhang Zhou, Jianan Zhang, Liangyu Chen, Zhidan Liu, Steven Hoi, and Yue Wang. MobileWorld: Benchmarking au- tonomous mobile agents in agent-user interactive and MCP-augmented environments. arXiv:2512.19432, 2025
arXiv 2025
-
[28]
Benchmarking mobile device control agents across di- verse configurations
Juyong Lee, Taywon Min, Minyong An, Dongyoon Hahm, Haeone Lee, Changyeon Kim, and Kimin Lee. Benchmarking mobile device control agents across di- verse configurations. arXiv:2404.16660, 2024
arXiv 2024
-
[29]
ACE: A security architecture for LLM-integrated app systems
Evan Li, Tushin Mallick, Evan Rose, William Robert- son, Alina Oprea, and Cristina Nita-Rotaru. ACE: A security architecture for LLM-integrated app systems. InNetwork and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 2026. The Internet Soci- ety
2026
-
[30]
MCP-ITP: An automated framework for implicit tool poisoning in MCP
Ruiqi Li, Zhiqiang Wang, Yunhao Yao, and Xiang-Yang Li. MCP-ITP: An automated framework for implicit tool poisoning in MCP. arXiv:2601.07395, 2026
arXiv 2026
-
[31]
Linux man-pages project, 2025
Linux man-pages project.seccomp(2) — Linux manual page. Linux man-pages project, 2025
2025
-
[32]
AgentBench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as agents. InThe Twelfth International Conference on Learn- ing...
2024
-
[33]
AgentBoard: An analytical evaluation board of multi-turn LLM agents
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yu- jiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. AgentBoard: An analytical evaluation board of multi-turn LLM agents. InAdvances in Neu- ral Information Processing Systems, volume 37, pages 74325–74362, Vancouver, BC, Canada, 2024. Curran Associates, Inc
2024
-
[34]
Narek Maloyan and Dmitry Namiot. Breaking the pro- tocol: Security analysis of the model context protocol specification and prompt injection vulnerabilities in tool- integrated LLM agents. arXiv:2601.17549, 2026. 16
arXiv 2026
-
[35]
Quantifying frontier LLM capabilities for container sandbox escape
Rahul Marchand, Art O Cathain, Jerome Wynne, Philip- pos Maximos Giavridis, Sam Deverett, John Wilkin- son, Jason Gwartz, and Harry Coppock. Quantifying frontier LLM capabilities for container sandbox escape. arXiv:2603.02277, 2026
arXiv 2026
-
[36]
ceLLMate: Sandboxing browser AI agents
Luoxi Meng, Henry Feng, Ilia Shumailov, and Earlence Fernandes. ceLLMate: Sandboxing browser AI agents. arXiv:2512.12594, 2025
arXiv 2025
-
[37]
GAIA: A bench- mark for general AI assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A bench- mark for general AI assistants. InThe Twelfth Interna- tional Conference on Learning Representations, Vienna, Austria, 2024. OpenReview.net
2024
-
[38]
Attractive metadata attack: Inducing LLM agents to invoke malicious tools
Kanghua Mo, Li Hu, Yucheng Long, and Zhihao Li. Attractive metadata attack: Inducing LLM agents to invoke malicious tools. arXiv:2508.02110, 2025
arXiv 2025
-
[39]
Formal policy enforcement for real-world agentic systems
Nils Palumbo, Sarthak Choudhary, Jihye Choi, Guy Amir, Prasad Chalasani, and Somesh Jha. Formal policy enforcement for real-world agentic systems. arXiv:2602.16708, 2026
Pith/arXiv arXiv 2026
-
[40]
The UCONABC usage control model.ACM Transactions on Information and System Security, 7(1):128–174, 2004
Jaehong Park and Ravi Sandhu. The UCONABC usage control model.ACM Transactions on Information and System Security, 7(1):128–174, 2004
2004
-
[41]
SWE-PolyBench: A multi-language benchmark for repository-level evaluation of coding agents
Muhammad Shihab Rashid, Christian Bock, Yuan Zhuang, Alexander Buccholz, Tim Esler, Simon Valentin, Luca Franceschi, Martin Wistuba, Prabhu Teja Sivaprasad, Woo Jung Kim, et al. SWE-PolyBench: A multi-language benchmark for repository-level evaluation of coding agents. arXiv:2504.08703, 2025
arXiv 2025
-
[42]
AndroidWorld: A dynamic benchmarking environment for autonomous agents
Chris Rawles, Sarah Clinckemaillie, Yifan Chang, Jonathan Waltz, Gabrielle Lau, Marybeth Fair, Alice Li, William Bishop, Wei Li, Folawiyo Campbell-Ajala, Daniel Toyama, Robert Berry, Divya Tyamagundlu, Tim- othy Lillicrap, and Oriana Riva. AndroidWorld: A dynamic benchmarking environment for autonomous agents. InThe Thirteenth International Conference on ...
2025
-
[43]
Maddison, and Tatsunori Hashimoto
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J. Maddison, and Tatsunori Hashimoto. ToolEmu: Iden- tifying the risks of LM agents with an LM-emulated sandbox. InThe Twelfth International Conference on Learning Representations, Vienna, Austria, 2024. Open- Review.net
2024
-
[44]
Saltzer and Michael D
Jerome H. Saltzer and Michael D. Schroeder. The pro- tection of information in computer systems.Proceed- ings of the IEEE, 63(9):1278–1308, 1975
1975
-
[45]
Prompt injec- tion attack to tool selection in LLM agents
Jiawen Shi, Zenghui Yuan, Guiyao Tie, Pan Zhou, Neil Zhenqiang Gong, and Lichao Sun. Prompt injec- tion attack to tool selection in LLM agents. InNetwork and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 2026. The Internet Society
2026
-
[46]
Pro- gent: Securing AI agents with privilege control
Tianneng Shi, Jingxuan He, Zhun Wang, Linyu Wu, Hongwei Li, Wenbo Guo, and Dawn Song. Pro- gent: Securing AI agents with privilege control. arXiv:2504.11703, 2025
Pith/arXiv arXiv 2025
-
[47]
PromptArmor: Simple yet effective prompt injection defenses
Tianneng Shi, Kaijie Zhu, Zhun Wang, Yuqi Jia, Will Cai, Weida Liang, Haonan Wang, Hend Alzahrani, Joshua Lu, Kenji Kawaguchi, Basel Alomair, Xuandong Zhao, William Yang Wang, Neil Gong, Wenbo Guo, and Dawn Song. PromptArmor: Simple yet effective prompt injection defenses. arXiv:2507.15219, 2025
arXiv 2025
-
[48]
SAGA: A security archi- tecture for governing AI agentic systems
Georgios Syros, Anshuman Suri, Jacob Ginesin, Cristina Nita-Rotaru, and Alina Oprea. SAGA: A security archi- tecture for governing AI agentic systems. InNetwork and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 2026. The Internet Society
2026
-
[49]
Poskitt, and Jun Sun
Haoyu Wang, Christopher M. Poskitt, and Jun Sun. AgentSpec: Customizable runtime enforcement for safe and reliable LLM agents. InProceedings of the IEEE/ACM International Conference on Software Engi- neering (ICSE 2026), pages 1–12, Rio de Janeiro, Brazil,
2026
-
[50]
Association for Computing Machinery
-
[51]
MCPTox: A benchmark for tool poisoning attack on real-world MCP servers
Zhiqiang Wang, Yichao Gao, Yanting Wang, Suyuan Liu, Haifeng Sun, Haoran Cheng, Guanquan Shi, Hao- hua Du, and Xiangyang Li. MCPTox: A benchmark for tool poisoning attack on real-world MCP servers. arXiv:2508.14925, 2025
arXiv 2025
-
[52]
Robert N. M. Watson, Jonathan Anderson, Ben Laurie, and Kris Kennaway. Capsicum: Practical capabilities for UNIX. In19th USENIX Security Symposium (USENIX Security 2010), pages 29–44, Washington, DC, USA,
2010
-
[53]
Robert N. M. Watson, Peter G. Neumann, Jonathan Woodruff, Simon W. Moore, Jonathan Anderson, David Chisnall, Nirav Dave, Brooks Davis, Khilan Gudka, and Ben Laurie. CHERI: A hybrid capability-system archi- tecture for scalable software compartmentalization. In 2015 IEEE Symposium on Security and Privacy, pages 20–37, San Jose, CA, USA, 2015. IEEE Computer...
2015
-
[54]
IsolateGPT: An execution iso- lation architecture for LLM-based systems
Yuhao Wu, Franziska Roesner, Tadayoshi Kohno, Ning Zhang, and Umar Iqbal. IsolateGPT: An execution iso- lation architecture for LLM-based systems. InNetwork and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 2025. The Internet Society. 17
2025
-
[55]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real com- puter environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhou- jun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yi- heng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmarking multimodal agents for open-ended tasks in real com- puter environments. InAdvances in Neural Informa...
2024
-
[56]
MCPSecBench: A sys- tematic security benchmark and playground for testing model context protocols
Yixuan Yang, Cuifeng Gao, Daoyuan Wu, Yufan Chen, Yingjiu Li, and Shuai Wang. MCPSecBench: A sys- tematic security benchmark and playground for testing model context protocols. arXiv:2508.13220, 2025
arXiv 2025
-
[57]
Multi-agent memory from a computer ar- chitecture perspective: Visions and challenges ahead
Zhongming Yu, Naicheng Yu, Hejia Zhang, Wentao Ni, Mingrui Yin, Jiaying Yang, Yujie Zhao, and Jishen Zhao. Multi-agent memory from a computer ar- chitecture perspective: Visions and challenges ahead. arXiv:2603.10062, 2026
arXiv 2026
-
[58]
InjecAgent: Benchmarking indirect prompt injec- tions in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. InjecAgent: Benchmarking indirect prompt injec- tions in tool-integrated large language model agents. In Findings of the Association for Computational Linguis- tics: ACL 2024, pages 10471–10506, Bangkok, Thai- land, 2024. Association for Computational Linguistics
2024
-
[59]
Agent security bench (ASB): For- malizing and benchmarking attacks and defenses in LLM-based agents
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (ASB): For- malizing and benchmarking attacks and defenses in LLM-based agents. InThe Thirteenth International Conference on Learning Representations, Singapore,
-
[60]
Jinchuan Zhang, Lu Yin, Yan Zhou, and Songlin Hu. AgentAlign: Navigating safety alignment in the shift from informative to agentic large language models. arXiv:2505.23020, 2025
arXiv 2025
-
[61]
AgentCgroup: Under- standing and controlling OS resources of AI agents
Yusheng Zheng, Jiakun Fan, Quanzhi Fu, Yiwei Yang, Wei Zhang, and Andi Quinn. AgentCgroup: Under- standing and controlling OS resources of AI agents. arXiv:2602.09345, 2026
arXiv 2026
-
[62]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neu- big
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neu- big. WebArena: A realistic web environment for build- ing autonomous agents. InThe Twelfth International Conference on Learning Representations, Vienna, Aus- tria, 2024. OpenReview.net
2024
-
[63]
Patil, Vivian Fang, and Raluca Ada Popa
Jinhao Zhu, Kevin Tseng, Gil Vernik, Xiao Huang, Shishir G. Patil, Vivian Fang, and Raluca Ada Popa. MiniScope: A least privilege framework for authorizing tool calling agents. arXiv:2512.11147, 2025. A Representative Trace Witnesses The main text uses compact running examples. This appendix records the corresponding checked-in witnesses and the tran- sit...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.