Improving Code-Switching ASR with Code-Mixing Guided Synthetic Speech
Pith reviewed 2026-06-27 04:16 UTC · model grok-4.3
The pith
A code-mixing guided preference-learning framework using the Code Mixing Index steers TTS output to produce synthetic speech that improves code-switching ASR fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
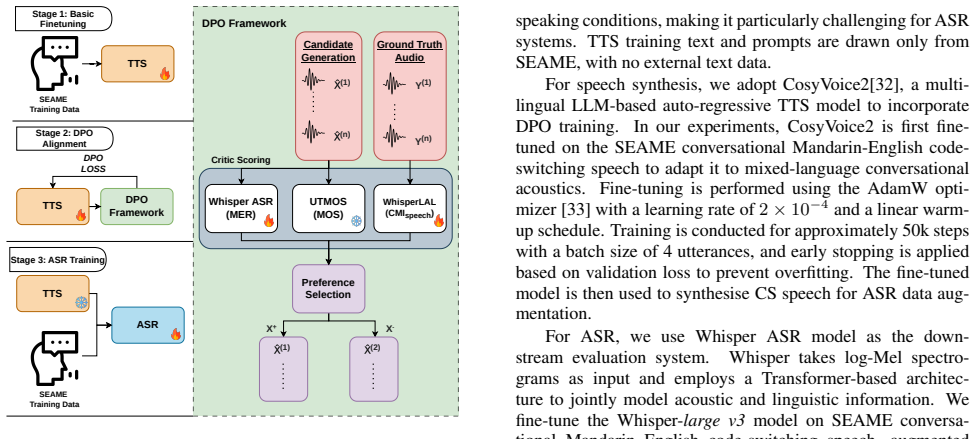
The authors propose a code-mixing guided preference-learning framework that steers synthetic speech generation toward improved code-switching fidelity using the Code Mixing Index (CMI). Experiments on the SEAME Mandarin-English conversational corpus demonstrate that the proposed method enhances the utility of synthetic data for ASR fine-tuning. Specifically, when fine-tuning Whisper Large, the proposed approach reduces Mixed Error Rate (MER) from 12.1%/17.8% to 8.9%/14.2% on the DevMAN and DevSGE sets, respectively.
What carries the argument
The code-mixing guided preference-learning framework, which applies the Code Mixing Index to rank TTS outputs and retain samples whose language-boundary statistics better match target code-switching patterns.
If this is right
- Synthetic speech for ASR augmentation can be optimized for language-boundary consistency in addition to acoustic fidelity.
- Preference learning provides a practical mechanism to enforce code-mixing statistics without retraining the underlying TTS model from scratch.
- Whisper Large fine-tuned on the resulting data achieves lower mixed error rates on conversational Mandarin-English test sets.
- The same preference loop can be applied to other code-switching language pairs where real paired data remain scarce.
Where Pith is reading between the lines
- The method may lower the cost of building ASR systems for additional low-resource code-switching pairs by substituting guided synthetic data for new recordings.
- Directly embedding CMI into the TTS training objective rather than using it only for post-generation selection could produce even stronger gains.
- The approach might transfer to other sequence tasks, such as machine translation of code-switched text, where boundary consistency also matters.
Load-bearing premise
The Code Mixing Index can be used inside a preference-learning loop to produce synthetic speech whose language-boundary properties measurably improve ASR fine-tuning utility.
What would settle it
Fine-tuning Whisper Large on CMI-guided synthetic data and observing no reduction (or an increase) in MER on both DevMAN and DevSGE would falsify the central claim.
Figures
read the original abstract
Code-switch (CS) Automatic Speech Recognition (ASR) remains challenging due to limited availability of high quality CS text-speech pairs for training. Although synthetic data augmentation via Text-to-speech (TTS) has been explored, existing CS TTS approaches primarily optimise reconstruction fidelity and do not explicitly enforce language-boundary consistency, thereby limiting their effectiveness for CS ASR augmentation. This paper proposes a code-mixing guided preference-learning framework that steers synthetic speech generation toward improved code-switching fidelity using the Code Mixing Index (CMI). Experiments on the SEAME Mandarin-English conversational corpus demonstrate that the proposed method enhances the utility of synthetic data for ASR fine-tuning. Specifically, when fine-tuning Whisper Large, the proposed approach reduces Mixed Error Rate (MER) from 12.1%/17.8% to 8.9%/14.2% on the DevMAN and DevSGE sets, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing CS TTS methods optimize for reconstruction fidelity but not language-boundary consistency, and proposes a code-mixing guided preference-learning framework that uses the Code Mixing Index (CMI) to steer synthetic speech generation. On the SEAME Mandarin-English corpus, fine-tuning Whisper Large with the resulting data is reported to reduce Mixed Error Rate from 12.1%/17.8% to 8.9%/14.2% on the DevMAN and DevSGE sets.
Significance. If the reported gains can be causally attributed to the CMI-guided preference loop rather than generic synthetic augmentation, the work would offer a concrete, metric-driven way to improve the utility of TTS data for code-switching ASR, addressing a known data-scarcity bottleneck. The approach combines an existing metric (CMI) with preference learning in a downstream-task-oriented manner.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the headline MER reductions (12.1%→8.9% on DevMAN, 17.8%→14.2% on DevSGE) are presented without any contrast to a plain TTS baseline or a non-CMI preference-learning baseline. Because the central claim is that CMI guidance specifically improves ASR utility, the absence of these controls makes it impossible to isolate the contribution of the proposed loop from the generic effect of adding more synthetic CS-like audio.
- [Method] Method section: the precise formulation of how CMI is turned into a preference reward or loss (e.g., the exact preference model, sampling strategy, or weighting) is not specified, preventing assessment of whether the framework is reproducible or whether the reported gains could be obtained with simpler CMI filtering rather than a full preference-learning loop.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The two major comments identify important gaps in experimental controls and methodological detail. We address each point below and will revise the manuscript to incorporate the requested baselines and clarifications.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the headline MER reductions (12.1%→8.9% on DevMAN, 17.8%→14.2% on DevSGE) are presented without any contrast to a plain TTS baseline or a non-CMI preference-learning baseline. Because the central claim is that CMI guidance specifically improves ASR utility, the absence of these controls makes it impossible to isolate the contribution of the proposed loop from the generic effect of adding more synthetic CS-like audio.
Authors: We agree that the current experiments do not isolate the contribution of CMI guidance from generic synthetic data augmentation. In the revised version we will add two controls: (1) a plain TTS baseline that generates code-switched speech without any preference learning, and (2) a non-CMI preference-learning baseline that uses a different reward signal. These additions will allow direct attribution of gains to the CMI-guided loop. revision: yes
-
Referee: [Method] Method section: the precise formulation of how CMI is turned into a preference reward or loss (e.g., the exact preference model, sampling strategy, or weighting) is not specified, preventing assessment of whether the framework is reproducible or whether the reported gains could be obtained with simpler CMI filtering rather than a full preference-learning loop.
Authors: We acknowledge that the current method description lacks the precise mathematical formulation and implementation details needed for reproducibility. In the revision we will expand the Method section to specify the preference model (including how CMI is converted to a scalar reward), the sampling strategy for preference pairs, and all weighting hyperparameters. We will also discuss why a full preference-learning loop is used rather than simple CMI filtering. revision: yes
Circularity Check
No significant circularity; derivation applies external CMI metric to TTS generation then measures downstream ASR utility
full rationale
The paper's core chain is: (1) apply existing Code Mixing Index (CMI) to rank or preference-tune TTS outputs for language-boundary properties, (2) use the resulting synthetic CS speech to fine-tune Whisper, (3) report MER on held-out DevMAN/DevSGE sets. CMI is an independently defined metric from prior literature, not redefined inside the paper; the ASR numbers are external evaluation metrics. No equation reduces a claimed prediction to a fitted parameter by construction, no self-citation is invoked as a uniqueness theorem, and no ansatz is smuggled via prior work by the same authors. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CMI scores correlate with downstream ASR utility when used to guide preference learning
Reference graph
Works this paper leans on
-
[1]
Introduction Code-Switching (CS), the alternation of multiple languages within a single utterance, is a phenomenon in multilingual com- munities [1, 2, 3]. Despite substantial advances in Automatic Speech Recognition (ASR), recognising conversational CS speech remains challenging due to language alternation, cross- lingual phonetic interference, and infor...
-
[2]
Preference Learning Preference learning has recently emerged as a scalable prefer- ence alignment paradigm for generative models, offering an al- ternative to explicit reward modeling and reinforcement learn- ing [24, 25, 26, 27]. DPO is a methodology derived from preference learning that reformulates alignment as supervised learning over preferred and di...
Pith/arXiv arXiv 2026
-
[3]
Proposed Methodology 3.1. Acoustic-level CMI Speech In this paper, our proposed framework follows the language alignment strategy proposed in [29], generating pseudo frame- level language labels directly from the decoder cross-attention without requiring forced alignment or manual annotations. Specifically, averaged cross-attention from the last decoder l...
-
[4]
Experiment Setup The experiments in this paper are conducted on the SEAME corpus, a benchmark for conversational Mandarin-English code-switching speech recognition [31]. SEAME contains ap- proximately 192 hours of spontaneous conversational speech recorded from over 150 bilingual speakers in Singapore and Malaysia, where Mandarin and English are frequentl...
-
[5]
Results Table 1 shows how progressively adding critic signals to DPO better aligns CS TTS with our objective of generating better quality synthetic speech that effectively improves downstream CS-ASR. The table shows the results after DPO fine-tuning CosyV oice TTS on SEAME training set and reproducing Dev- Table 1:Cosyvoice TTS Performance Comparison Acro...
-
[6]
Our approach explicitly aligns syn- thetic speech with intelligibility, perceptual quality, and realis- tic language-mixing structure
Conclusion In this work, we presented a CS metric guided DPO framework for improving CS TTS. Our approach explicitly aligns syn- thetic speech with intelligibility, perceptual quality, and realis- tic language-mixing structure. By integrating∆ CMI for measur- ing synthesised CS complexity, we construct contrastive pref- erence pairs through normalized sco...
-
[7]
Generative AI Use Disclosure Generative AI tools were used for limited assistance with manuscript editing and presentation (e.g., grammatical valida- tion, removal of redundant sentences and phrases, preparing La- TeX equations and LaTeX formatting suggestions). The litera- ture review and all scientific contributions, including but not limited to problem...
-
[8]
A survey of code-switching: Linguistic and social perspectives for language technologies,
A. S. Do ˘gru¨oz, S. Sitaram, B. E. Bullock, and A. J. Toribio, “A survey of code-switching: Linguistic and social perspectives for language technologies,” inProc. ACL, 2021, pp. 1654–1666
2021
-
[9]
End-to-end language diarization for bilingual code-switching speech,
H. Liu, L. P. Garcia, X. Zhang, J. Dauwels, A. W. H. Khong, S. Khudanpur, and S. J. Styles, “End-to-end language diarization for bilingual code-switching speech,” inProc. Interspeech, 2021, pp. 1489–1493
2021
-
[10]
Reducing language confusion for code-switching speech recognition with token-level language diarization,
H. Liu, H. Xu, L. P. Garcia, A. W. H. Khong, Y . He, and S. Khu- danpur, “Reducing language confusion for code-switching speech recognition with token-level language diarization,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2023, pp. 1–5
2023
-
[11]
Decm: Evaluating bilin- gual asr performance on a code-switched speech dataset,
E. Y . Ugan, N.-Q. Pham, and A. Waibel, “Decm: Evaluating bilin- gual asr performance on a code-switched speech dataset,” inProc. LREC-COLING, 2024
2024
-
[12]
Enhancing code-switching speech recognition with interac- tive language biases,
H. Liu, L. P. Garcia, X. Zhang, A. W. Khong, and S. Khudan- pur, “Enhancing code-switching speech recognition with interac- tive language biases,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process.IEEE, 2024, pp. 10 886–10 890
2024
-
[13]
Seame: a mandarin- english code-switching speech corpus in south-east asia,
D.-C. Lyu, T.-P. Tan, E. S. Chng, and H. Li, “Seame: a mandarin- english code-switching speech corpus in south-east asia,” inProc. Interspeech, 2010, pp. 1986–1989
2010
-
[14]
Conformer: Convolution-augmented transformer for speech recognition,
A. Gulati, J. Qin, C.-C. Chiu, N. Parmar, Y . Zhang, J. Yuet al., “Conformer: Convolution-augmented transformer for speech recognition,” inProc. Interspeech, 2020, pp. 5036–5040
2020
-
[15]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProc. ICML, 2023
2023
-
[16]
Adapting whisper for parameter-efficient code-switching speech recognition via soft prompt tuning,
H. Yang, Y . Peng, H. Huang, and S. Li, “Adapting whisper for parameter-efficient code-switching speech recognition via soft prompt tuning,” inProc. Interspeech, 2025
2025
-
[17]
Enhancing low-resource asr through versatile tts: Bridging the data gap,
G. Yang, F. Yu, Z. Ma, Z. Du, Z. Gao, S. Zhang, and X. Chen, “Enhancing low-resource asr through versatile tts: Bridging the data gap,”arXiv preprint arXiv:2410.16726, 2024
arXiv 2024
-
[18]
Text-to-speech data augmentation for low resource speech recognition,
R. Zevallos, “Text-to-speech data augmentation for low resource speech recognition,”arXiv preprint arXiv:2204.00291, 2022
arXiv 2022
-
[19]
Data augmentation for asr using tts via a discrete representation,
S. Ueno, K. Kawakami, H. Inaguma, and S. Nakamura, “Data augmentation for asr using tts via a discrete representation,” inProc. IEEE Autom. Speech Recognit. Understand. Workshop, 2021
2021
-
[20]
Asr model adaptation for rare words using synthetic data generated by multiple text-to- speech systems,
K. C. Yuen, L. Haoyang, and C. E. Siong, “Asr model adaptation for rare words using synthetic data generated by multiple text-to- speech systems,” inProc. APSIPA ASC, 2023, pp. 1771–1778
2023
-
[21]
Asr data augmentation in low-resource settings using cross-lingual multi-speaker tts and cross-lingual voice conversion,
E. Casanova, C. Shulby, A. Korolev, A. C. Junior, A. da Silva Soares, S. Alu ´ısio, and M. A. Ponti, “Asr data augmentation in low-resource settings using cross-lingual multi-speaker tts and cross-lingual voice conversion,” inProc. Interspeech, 2023, pp. 1244–1248
2023
-
[22]
Neu- ral codec language models are zero-shot text to speech synthesiz- ers,
C. Wang, S. Chen, Y . Wu, Z. Zhang, L. Zhou, S. Liu,et al., “Neu- ral codec language models are zero-shot text to speech synthesiz- ers,”arXiv preprint arXiv:2301.02111, 2023
Pith/arXiv arXiv 2023
-
[23]
Stepaudio 2.5 technical report,
B. Lin, B. Zhao, B. Wu, C. Yan, C. Wu, C. Yi, C. Yao, D. Liu, F. Tian, F. Tianet al., “Stepaudio 2.5 technical report,”arXiv preprint arXiv:2605.23463, 2026
Pith/arXiv arXiv 2026
-
[24]
Improving code-switching speech recognition with tts data aug- mentation,
Y . H. Yeo, Y . Hu, S. Gopal, Y . Peng, H. Liu, and E. S. Chng, “Improving code-switching speech recognition with tts data aug- mentation,” inProc. APSIPA ASC, 2025
2025
-
[25]
T. Nguyen and H.-D. Tran, “Can we train asr systems on code- switch without real code-switch data? case study for singapore’s languages,”arXiv preprint arXiv:2506.14177, 2025
arXiv 2025
-
[26]
Cs-fleurs: A massively multilingual and code-switched speech dataset,
B. Yan, I. Hamed, S. Shimizu, V . Lodagala, W. Chen, O. Iakovenkoet al., “Cs-fleurs: A massively multilingual and code-switched speech dataset,” inProc. Interspeech, 2025, pp. 743–747
2025
-
[27]
On measuring the complexity of code- mixing,
B. Gamb ¨ack and A. Das, “On measuring the complexity of code- mixing,” inProc. ICON, Goa, India, 2014, pp. 1–7
2014
-
[28]
Challenges and limitations with the metrics measuring the com- plexity of code-mixed text,
V . Srivastava, M. Singh, M. Shrivastava, and D. M. Sharma, “Challenges and limitations with the metrics measuring the com- plexity of code-mixed text,” inProc. Workshop Comput. Ap- proaches Linguist. Code-Switching, 2021
2021
-
[29]
Automatic detec- tion of code-switching style from acoustics,
S. K. Rallabandi, S. Sitaram, and A. W. Black, “Automatic detec- tion of code-switching style from acoustics,” inProc. Interspeech, 2018
2018
-
[30]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Man- ning, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,”arXiv preprint arXiv:2305.18290, 2023
Pith/arXiv arXiv 2023
-
[31]
Training language models to follow instruc- tions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin,et al., “Training language models to follow instruc- tions with human feedback,” inProc. NeurIPS, 2022
2022
-
[32]
Gentse: Enhancing target speaker extraction via a coarse-to-fine generative language model,
H. Li, X. Zhuang, A. Adnan, Y . Ni, W. Rao, S. Gopal, and E. S. Chng, “Gentse: Enhancing target speaker extraction via a coarse-to-fine generative language model,”arXiv preprint arXiv:2512.20978, 2025
Pith/arXiv arXiv 2025
-
[33]
Aligning generative speech enhancement with human preferences via direct preference optimization,
H. Li, N. Hou, Y . Hu, J. Yao, S. M. Siniscalchi, and E. S. Chng, “Aligning generative speech enhancement with human preferences via direct preference optimization,”arXiv preprint arXiv:2507.09929, 2025
arXiv 2025
-
[34]
Mind-paced speaking: A dual- brain approach to real-time reasoning in spoken language mod- els,
D. Wu, H. Zhang, J. Chen, H. Liu, E. S. Chng, F. Tian, X. Yang, X. Zhang, D. Jiang, G. Yuet al., “Mind-paced speaking: A dual- brain approach to real-time reasoning in spoken language mod- els,”arXiv preprint arXiv:2510.09592, 2025
Pith/arXiv arXiv 2025
-
[35]
Preference alignment improves language model-based tts,
J. Tian, C. Zhang, J. Shi, H. Zhang, J. Yu, S. Watanabe, and D. Yu, “Preference alignment improves language model-based tts,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2025, pp. 1–5
2025
-
[36]
Aligning speech to languages to enhance code-switching speech recognition,
H. Liu, X. Zhang, H. Zhang, L. P. Garcia-Perera, A. W. H. Khong, E. S. Chng, and S. Watanabe, “Aligning speech to languages to enhance code-switching speech recognition,”IEEE Trans. Audio, Speech, Lang. Process., vol. 33, pp. 4712–4725, 2025
2025
-
[37]
Utmos: Utokyo-sarulab system for voicemos challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “Utmos: Utokyo-sarulab system for voicemos challenge 2022,” inProc. Interspeech, 2022
2022
-
[38]
Code-switching speech recognition under the lens: Model- and data-centric perspectives,
H. Liu, H. Zhang, Q. Zhang, X. Zhang, D. Shi, E. S. Chng, and H. Li, “Code-switching speech recognition under the lens: Model- and data-centric perspectives,”IEEE Trans. Audio, Speech, Lang. Process., vol. 34, pp. 1853–1865, 2026
2026
-
[39]
Cosyvoice 2: Scalable streaming speech synthesis with large lan- guage models,
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao,et al., “Cosyvoice 2: Scalable streaming speech synthesis with large lan- guage models,”arXiv preprint arXiv:2412.10117, 2024
Pith/arXiv arXiv 2024
-
[40]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” inProc. ICLR, 2019
2019
-
[41]
Adam: A method for stochastic opti- mization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic opti- mization,” inProc. ICLR, 2015
2015
-
[42]
ESPnet: End-to-End Speech Processing Toolkit,
S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y . Unno et al., “ESPnet: End-to-End Speech Processing Toolkit,” inProc. Interspeech, 2018, pp. 2207–2211
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.