The Correctness Illusion in LLM-Generated GPU Kernels
Pith reviewed 2026-06-26 16:30 UTC · model grok-4.3
The pith
Fixed-shape allclose checks in LLM GPU kernel benchmarks pass transcription-error bugs that a fuzzing oracle detects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Benchmarks that judge LLM-generated GPU kernels correct via fixed-shape, small-sample allclose checks certify kernels containing transcription errors as correct; an alternative oracle that applies op-schema-aware seeded fuzzing, a high-precision fp64 CPU reference, and per-(op, dtype) absolute tolerances detects all nine seeded bugs while passing fifteen controls, with identical verdicts on RTX 3060, A10, L40S, A100, and H100 hardware.
What carries the argument
op-schema-aware seeded fuzzing with fp64 CPU reference and per-(op, dtype) absolute tolerances that replays every failure byte-for-byte from a stored seed.
If this is right
- Existing benchmarks (KernelBench, TritonBench, GEAK) overestimate correctness rates for LLM kernels.
- Transcription errors of the seeded kind survive single-shape allclose checks but are caught by shape- and input-diverse testing.
- The illusion is independent of GPU architecture: the same ten failures and sixteen passes appear on every tested device.
- Adding flash-attention to the corpus does not change the outcome.
Where Pith is reading between the lines
- Benchmarks could adopt fuzzing oracles to produce more trustworthy scores for generated kernels.
- The result points to a broader need for input-diverse testing whenever LLMs generate numerical or shape-sensitive code.
- The same seeding technique could be applied to evaluate correctness oracles in other code-generation domains.
Load-bearing premise
The nine seeded transcription errors are representative of the mistakes LLMs actually make when writing GPU kernels.
What would settle it
An experiment that shows real LLM outputs for the same kernels never contain the seeded transcription errors, or that the flagged bugs never produce wrong results on any practical workload.
Figures
read the original abstract
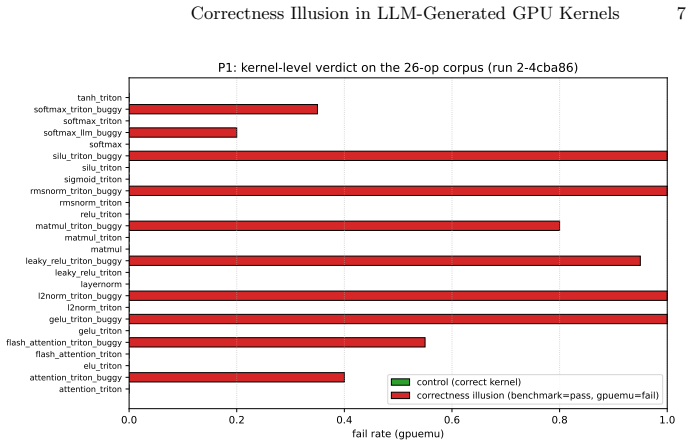
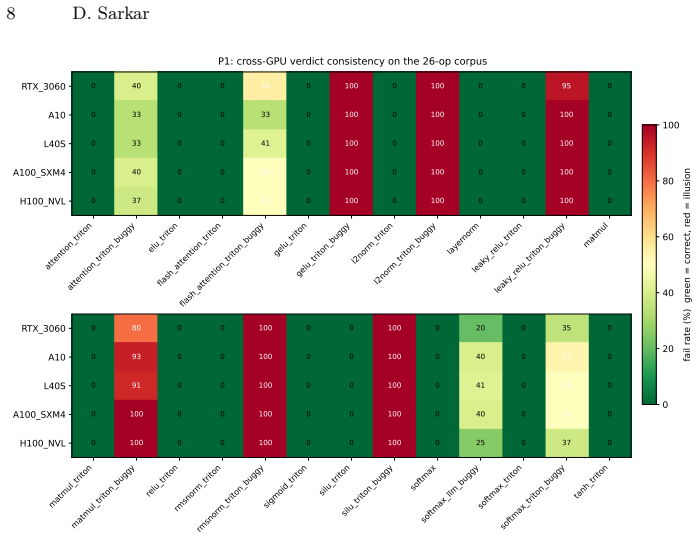
Benchmarks for LLM-generated GPU kernels (KernelBench, TritonBench, GEAK) score correctness through fixed-shape, small-sample allclose-style checks. The number of inputs varies between benchmarks. The shape, dtype, and tolerance are fixed for each kernel. We test that oracle empirically. We construct a controlled corpus of 24 Triton and CPU stand-in kernels (15 correct controls and 9 LLM-style buggy variants seeded with documented transcription errors) and re-evaluate it under op-schema-aware seeded fuzzing with a high-precision (fp64) CPU reference and per-(op, dtype) absolute tolerances. The seeded oracle flags 9 of 9 buggy kernels and passes 15 of 15 correct controls, at zero precision cost on controls. We extend the corpus to 26 ops (adding a flash-attention pair) and re-run the same protocol on five GPU classes (RTX 3060, A10, L40S, A100 SXM4, H100 NVL). The verdicts are identical across all five GPUs: 10 of 10 illusions caught and 16 of 16 controls clean. The corpus result is about LLM-style transcription bugs that the allclose-on-one-shape oracle certifies as correct, not about the bug rate of any specific deployed LLM. Every flagged failure replays byte-for-byte from a stored seed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fixed-shape allclose-style oracles in benchmarks for LLM-generated GPU kernels (e.g., KernelBench) can certify certain transcription-error bugs as correct, creating a 'correctness illusion.' This is shown via a controlled corpus of 24 Triton/CPU stand-in kernels (15 correct controls + 9 LLM-style buggy variants seeded with documented transcription errors) where a new op-schema-aware seeded-fuzzing oracle using fp64 CPU reference and per-(op, dtype) absolute tolerances flags all 9 bugs while passing all 15 controls at zero precision cost; the result replicates identically on an extended 26-op corpus across five GPU classes (RTX 3060 to H100), with all failures replayable from stored seeds. The claim is explicitly limited to LLM-style transcription bugs on the constructed corpus rather than measured LLM bug rates.
Significance. If the result holds, the work provides a reproducible empirical demonstration of a concrete weakness in current benchmark oracles, with perfect separation on the corpus, multi-GPU consistency, and seed-based replayability as notable strengths. This could directly inform improved evaluation protocols for LLM kernel generation without relying on fitted parameters or post-hoc exclusions.
minor comments (2)
- [Abstract] Abstract: the qualifier 'LLM-style' is used consistently, but a single concrete example of one seeded transcription error (e.g., the specific dtype or indexing mistake) would help readers immediately grasp the bug class without needing the full corpus details.
- [§3 (method)] The description of how per-(op, dtype) absolute tolerances are chosen could be expanded with one sentence on their derivation (e.g., from fp64 reference statistics or literature values) to make the protocol fully self-contained.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation to accept. The report correctly captures the scope and limitations of our work. There are no major comments to address.
Circularity Check
No circularity: empirical corpus evaluation stands on independent construction and measurement
full rationale
The paper constructs an explicit corpus of 15 correct controls plus 9 seeded transcription-error variants, then measures oracle behavior under two protocols (standard allclose vs. fp64 seeded fuzzing). The reported outcome (standard oracle passes all 9 bugs; new oracle flags all 9 while preserving controls) follows directly from running the defined tests on the defined inputs. No parameters are fitted, no equations reduce the result to prior self-citations, and the paper explicitly disclaims any claim about actual LLM bug distributions. The derivation chain contains no self-definitional, fitted-prediction, or self-citation-load-bearing steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Seeded transcription errors represent the kinds of mistakes LLMs make when generating kernels
- domain assumption The high-precision fp64 CPU reference provides correct ground truth for detecting GPU kernel discrepancies
Forward citations
Cited by 1 Pith paper
-
Test-Input Generation for Tensor Programs: What Actually Finds Kernel Bugs
Boundary shape sampling for tensor kernel testing achieves 78% recall on seeded bugs with 0% false positives on correct kernels, while adversarial value sampling reaches 99% recall at the cost of 94% false positives.
Reference graph
Works this paper leans on
-
[1]
PyTorch blog (2022), https://pytorch.org/blog/what-every-u ser-should-know-about-mixed-precision-training-in-pytorch/ , updated November 2024
Ahmed, S., et al.: What every user should know about mixed precision training in PyTorch. PyTorch blog (2022), https://pytorch.org/blog/what-every-u ser-should-know-about-mixed-precision-training-in-pytorch/ , updated November 2024
2022
-
[2]
Deng, Y., Yang, C., Wei, A., Zhang, L.: Fuzzing deep-learning libraries via auto- mated relational API inference. In: Proc. 30th ACM Joint Eur. Softw. Eng. Conf. and Symp. Found. Softw. Eng. (ESEC/FSE) (2022). https://doi.org/10.1145/ 3540250.3549085,https://doi.org/10.1145/3540250.3549085
-
[3]
arXiv preprint (2025), https://arxiv.org/abs/2510.16996
Dong, S., Yang, Y., Liu, Y., Wang, H., Qi, Y., Tarokh, V., Rangadurai, K., Yang, Y.: STARK: Strategic team of agents for refining kernels. arXiv preprint (2025), https://arxiv.org/abs/2510.16996
arXiv 2025
-
[4]
arXiv preprint (2019), https://arxiv.org/abs/1905.12322
Kalamkar, D., Mudigere, D., Mellempudi, N., Das, D., Banerjee, K., Avancha, S., Vooturi, D.T., Jammalamadaka, N., Huang, J., Yuen, H., Yang, J., Park, J., Heinecke, A., Georganas, E., Srinivasan, S., Kundu, A., Smelyanskiy, M., Kaul, B., Dubey, P.: A study of BFLOAT16 for deep learning training. arXiv preprint (2019), https://arxiv.org/abs/1905.12322
Pith/arXiv arXiv 2019
-
[5]
arXiv preprint (2026), https://arxi v.org/abs/2602.10478
Li, Z., Lu, Y., Guo, H., Zhang, M., Wang, Y., Zhang, L.: GPU-Fuzz: Finding memory errors in deep learning frameworks. arXiv preprint (2026), https://arxi v.org/abs/2602.10478
arXiv 2026
-
[6]
Ouyang, A., Guo, S., Arora, S., Zhang, A.L., Hu, W., R´ e, C., Mirhoseini, A.: KernelBench: Can LLMs write efficient GPU kernels? arXiv preprint (2025), https: //arxiv.org/abs/2502.10517
Pith/arXiv arXiv 2025
-
[7]
arXiv preprint (2025), https://arxiv.org/ abs/2511.18868
Ran, H., Xie, S., Ji, H., Liu, Y., Wu, Y., Cao, H., Guo, A., Yu, Y., Li, L., Hu, W., Yang, D., Xie, T.: KernelBand: Steering LLM-based kernel optimization via hardware-aware multi-armed bandits. arXiv preprint (2025), https://arxiv.org/ abs/2511.18868
arXiv 2025
-
[8]
Sarkar, D.: Operator-aware mixed-precision tolerance calibration for tensor kernels (2026), manuscript in preparation
2026
-
[9]
Sarkar, D.: Test-input generation for tensor programs: What actually finds kernel bugs (2026), manuscript in preparation
2026
-
[10]
arXiv preprint (2023),https://arxiv.org/abs/2310.06912
Shiri Harzevili, N., Pham, H.V., Wang, S.: Benchmarking deep learning fuzzers. arXiv preprint (2023),https://arxiv.org/abs/2310.06912
arXiv 2023
-
[11]
Shiri Harzevili, N., Pham, H.V., Wang, S.: Evaluating API-level deep learning fuzzers: A comprehensive benchmarking study. ACM Trans. Softw. Eng. Methodol. (TOSEM) (2025). https://doi.org/10.1145/3729533, https://dl.acm.org/doi /10.1145/3729533 10 D. Sarkar
-
[12]
arXiv preprint (2026),https://arxiv.org/abs/2605.04956
Wang, H., Zhang, Y., Jiang, W., Wang, X., Chen, L., Zhu, Y.: KernelBench-X: A comprehensive benchmark for evaluating LLM-generated GPU kernels. arXiv preprint (2026),https://arxiv.org/abs/2605.04956
Pith/arXiv arXiv 2026
-
[13]
arXiv preprint (2025),https://arxiv.org/abs/2507.23194
Wang, J., Joshi, V., Majumder, S., Chao, K., Ding, Y., Liu, K., Brahma, P., Li, Y., Liu, J., Barsoum, E.: GEAK: Introducing Triton kernel AI agent & evaluation benchmarks. arXiv preprint (2025),https://arxiv.org/abs/2507.23194
arXiv 2025
- [14]
-
[15]
Xie, D., Li, Y., Kim, M., Pham, H.V., Tan, L., Zhang, X., Godfrey, M.W.: DocTer: Documentation-guided fuzzing for testing deep learning API functions. In: Proc. 31st ACM SIGSOFT Int. Symp. Software Testing and Analysis (ISSTA) (2022). https: //doi.org/10.1145/3533767.3534220,https://arxiv.org/abs/2109.01002
-
[16]
Automated program repair in the era of large pre- trained language models
Yang, C., Deng, Y., Yao, J., Tu, Y., Li, H., Zhang, L.: Fuzzing automatic dif- ferentiation in deep-learning libraries. In: Proc. 45th Int. Conf. Software Engi- neering (ICSE) (2023). https://doi.org/10.1109/ICSE48619.2023.00105 , https://arxiv.org/abs/2302.04351
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.