Using machine learning to build public policy agenda from social media conversations
Pith reviewed 2026-06-30 16:23 UTC · model grok-4.3
The pith
A five-stage human-augmented machine learning process can identify issues of public interest from social media conversations to form policy agendas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors describe a human-augmented machine learning approach with five stages: input data cleaning and preprocessing, keywords extraction and issue identification, narrative creation, narrative validation, and agenda validation. On a Twitter dataset, LDA and Top2Vec produced topics, GPT-2 generated narratives, and both similarity analysis and human evaluation produced very good and good inter-rater agreement on readability and coherence plus good agreement on agenda items, with above-average cosine similarity on at least three reference themes. The authors conclude these results show the approach is a promising methodology for identifying matters of public interest from social media conv
What carries the argument
The five-stage human-augmented pipeline that pairs topic modeling for issue detection with natural language generation for narrative creation, then applies similarity checks and human ratings for validation.
If this is right
- Agenda-setting work that now depends on costly manual data collection can be supplemented by automated processing of existing social media streams.
- The same sequence can be run over large geographic areas without proportional increases in labor or expense.
- Validation steps that combine inter-rater agreement with cosine similarity can serve as practical checks on output quality for policy use.
- The method can be rerun periodically to track shifts in public concerns without new data-collection campaigns.
Where Pith is reading between the lines
- The pipeline could be tested on data from other platforms to check whether platform-specific language affects the quality of generated agendas.
- Generated agendas could be compared directly with official government consultation documents to measure how well they align with stated policy priorities.
- Replacing or combining the topic models and generator with newer alternatives might raise the similarity and agreement scores further.
- Real-time versions of the pipeline could feed live dashboards that alert officials to emerging public issues before they appear in traditional channels.
Load-bearing premise
That human ratings of readability and coherence plus similarity to chosen reference texts are enough to prove the outputs capture genuine public interests rather than model artifacts or the references themselves.
What would settle it
Independent raters score the generated agenda items against separate public-opinion survey results on the same topics and find low overlap in the issues raised.
Figures







read the original abstract
Issue identification and agenda setting represents an important stage in the public policy making process. Traditional approaches for carrying out activities under this stage are time- and labor-intensive on data collection and analysis, in addition to being costly to scale over large geographic areas. In this work we propose a human-augmented machine learning (ML) approach for identifying matters of public interest from social media conversations. The approach consists of five stages namely, input data cleaning and preprocessing, keywords extraction and issue identification, narrative creation, narrative validation, and agenda validation. We implemented experiments to validate the output of our method based on a Twitter dataset and using Latent Dirichlet Allocation (LDA) and Top2Vec for topic modeling. Natural Language Generation (NLG) was achieved using GPT-2 while narrative and agenda validation were based on similarity analysis and human evaluation. We achieved "very good" and "good" inter-rater agreement (IRA) on readability and coherence of agenda narrative generation by our GPT-2 model. On the other hand, IRA was "good" for generated agenda items. We also achieved above average cosine similarity score on at least three out of five reference text (narrative) themes. These results demonstrate that the ML approach represents a promising methodology for identifying issues of public interest from social media conversations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a five-stage human-augmented ML pipeline (data cleaning/preprocessing, keywords/issue identification via LDA and Top2Vec, narrative creation with GPT-2, narrative validation, agenda validation) to extract public policy agendas from Twitter conversations; it reports 'very good'/'good' inter-rater agreement on readability/coherence of generated narratives and 'good' IRA on agenda items, plus above-average cosine similarity on at least three of five reference texts, and concludes that the approach is a promising methodology for identifying matters of public interest.
Significance. A method that reliably extracts policy-relevant issues at scale from social media would be a useful complement to traditional agenda-setting techniques, but the reported results only demonstrate surface fluency and overlap with chosen references rather than fidelity to the input corpus or external indicators of public interest.
major comments (3)
- [Abstract] Abstract (and narrative/agenda validation stages): the reported IRA scores and cosine similarities evaluate readability, coherence, and lexical overlap with five reference texts but supply no test of whether the generated narratives or agenda items accurately reflect issues present in the Twitter data (e.g., via ablation, corpus reconstruction, or comparison to contemporaneous polls/policy records), which is required to support the central claim.
- [Abstract] Abstract: no dataset size, preprocessing steps, model hyperparameters, exclusion criteria, or statistical tests are described, so the 'very good' and 'good' IRA values and 'above average' cosine scores cannot be evaluated or reproduced.
- [Narrative validation and agenda validation stages] Narrative validation and agenda validation stages: reliance on human ratings of surface properties and similarity to external reference texts leaves open whether outputs are artifacts of the topic models or GPT-2 fine-tuning rather than genuine public-interest signals from the conversations.
minor comments (1)
- The five stages are named in the abstract but their concrete implementation details (e.g., exact keyword extraction procedure, how GPT-2 was prompted or fine-tuned) would benefit from an explicit methods subsection or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on validation and reproducibility. We address each major comment below and outline revisions to strengthen the paper's claims regarding fidelity to the Twitter corpus.
read point-by-point responses
-
Referee: [Abstract] Abstract (and narrative/agenda validation stages): the reported IRA scores and cosine similarities evaluate readability, coherence, and lexical overlap with five reference texts but supply no test of whether the generated narratives or agenda items accurately reflect issues present in the Twitter data (e.g., via ablation, corpus reconstruction, or comparison to contemporaneous polls/policy records), which is required to support the central claim.
Authors: We agree that the current validation focuses on surface properties and reference overlap rather than direct fidelity to the input corpus. In revision we will add an ablation experiment (topic modeling removed) and report cosine similarity between generated narratives and a sample of original tweets to demonstrate grounding in the data. We will also add a brief qualitative mapping of extracted agenda items to contemporaneous policy records where available. revision: yes
-
Referee: [Abstract] Abstract: no dataset size, preprocessing steps, model hyperparameters, exclusion criteria, or statistical tests are described, so the 'very good' and 'good' IRA values and 'above average' cosine scores cannot be evaluated or reproduced.
Authors: The Methods section contains the dataset size (Twitter corpus details), preprocessing pipeline, LDA/Top2Vec hyperparameters, and exclusion criteria; IRA was computed with Fleiss' kappa. We will expand the abstract to include these summary statistics and explicitly name the agreement metric and significance testing so that the reported scores can be evaluated from the abstract alone. revision: yes
-
Referee: [Narrative validation and agenda validation stages] Narrative validation and agenda validation stages: reliance on human ratings of surface properties and similarity to external reference texts leaves open whether outputs are artifacts of the topic models or GPT-2 fine-tuning rather than genuine public-interest signals from the conversations.
Authors: The topic models are trained exclusively on the Twitter corpus and GPT-2 is conditioned on the resulting topic keywords; human raters were shown the source tweets alongside generated text. To further rule out artifacts we will add a quantitative check (average embedding similarity between generated narratives and held-out tweets from the same topics) and report it in the validation section. revision: partial
Circularity Check
No significant circularity; pipeline and validation are independent of inputs
full rationale
The paper presents a five-stage pipeline (data cleaning, topic modeling with LDA/Top2Vec, GPT-2 narrative generation, similarity analysis, human evaluation) whose outputs are assessed via external human inter-rater agreement on readability/coherence and cosine similarity to chosen reference texts. No equations, fitted parameters, self-citations, or ansatzes are described that would reduce any reported performance metric or conclusion to the input data or model choices by construction. The central claim therefore rests on independent external checks rather than definitional equivalence or self-referential fitting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Using machine learning to build public policy agenda from social media conversations
INTRODUCTION Issue identification and agenda setting is the first, and one of the most important phases in the public policy making process. During this phase, important social problems affecting society are identified and considered for placement onto the public policy agenda. A public policy may be defined as the set of plans, courses of action, and dec...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
We propose an approach based on ML for building public policy agenda from social media conversations. A ma- jor benefit of the proposed approach is that it allows for efficient generation and processing of large quantities of policy-related input data from a wide range of sources from the Web. This work thus demonstrates that ML methods can be used to com...
-
[3]
The pipeline consists of five stages namely: data cleaning and pre-processing, key- words extraction, narrative text generation, narrative text validation, and agenda validation
An end-to-end ML pipeline is proposed for semi-automated (i.e., human-augmented) public policy agenda building based on social media data sets. The pipeline consists of five stages namely: data cleaning and pre-processing, key- words extraction, narrative text generation, narrative text validation, and agenda validation
-
[4]
A proof-of-concept ML model has been developed to vali- date the output of our proposed approach in 1) above. Based on input data from Twitter and using Uganda’s 2020 / 2021 general elections as case study, the model provides useful insight on social issues raised by members of the general public during the elections period. The rest of this paper is orga...
2020
-
[5]
Results, discussion, and conclusion are found in Sections 4, 5, and 6, respectively
-
[6]
In this section we review recent literature with a focus on three things: application domain and/or task, ML method(s) used, and data sources
RELATED WORK In the recent past, ML methods in conjunction with social media, Web, or other publicly available data sources have been applied on diverse tasks to solve real-world problems. In this section we review recent literature with a focus on three things: application domain and/or task, ML method(s) used, and data sources. Public health is one of t...
-
[7]
Uganda had a projected population of 41.5 million people as of year 2020 [57]
MATERIALS AND METHODS 3.1 Materials 3.1.1 Study area and context The study area for this work is Uganda, a low-income country in Sub-Sahara Africa. Uganda had a projected population of 41.5 million people as of year 2020 [57]. According to the website www.datareportal.com [25] there were 2.5 million social media users in Uganda by January 2020, putting pe...
2020
-
[8]
Unlike the latter two methods, top2vec has the benefit of discovering topics that are more informative and representative of the data set it is trained on
and doc2vec [30]. Unlike the latter two methods, top2vec has the benefit of discovering topics that are more informative and representative of the data set it is trained on. Training a top2vec model requires three configuration settings includ- ing document (the input corpus), workers (number of worker threads), and speed. The latter configuration determi...
-
[9]
Agriculture minis- ter intervenes as BHC asks government to consider increasing funding for the sector
and word clouds. Text generation (or narrative creation) The goal of this stage is to produce human interpretable text paragraphs (i.e., narratives or short stories) that convey mean- ingful sentiments about an issue of public concern. Our inter- est and strategy is that given a keyword or phrase, the model should be able to create grammatically correct a...
2020
-
[10]
Example tweets taken from our dataset are shown in Figure 2
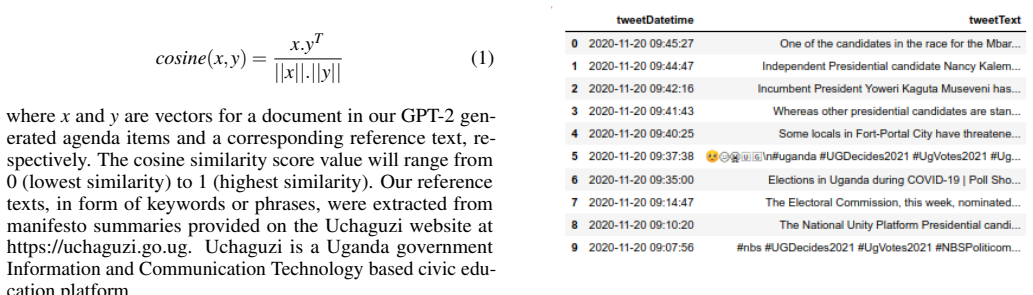
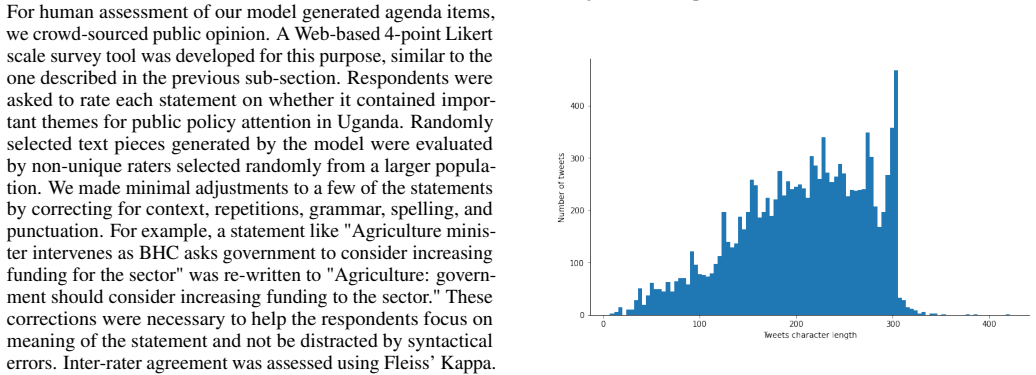
RESULTS 4.1 Dataset Our final data set consists of a total 12,272 uncleaned tweets after removing retweets i.e., tweets with the tag RT. Example tweets taken from our dataset are shown in Figure 2. As can be seen in the figure, the uncleaned tweets contain unwanted elements such as symbols, emoticons, numbers, punctuation marks, etc. These and other unwan...
-
[11]
brutality
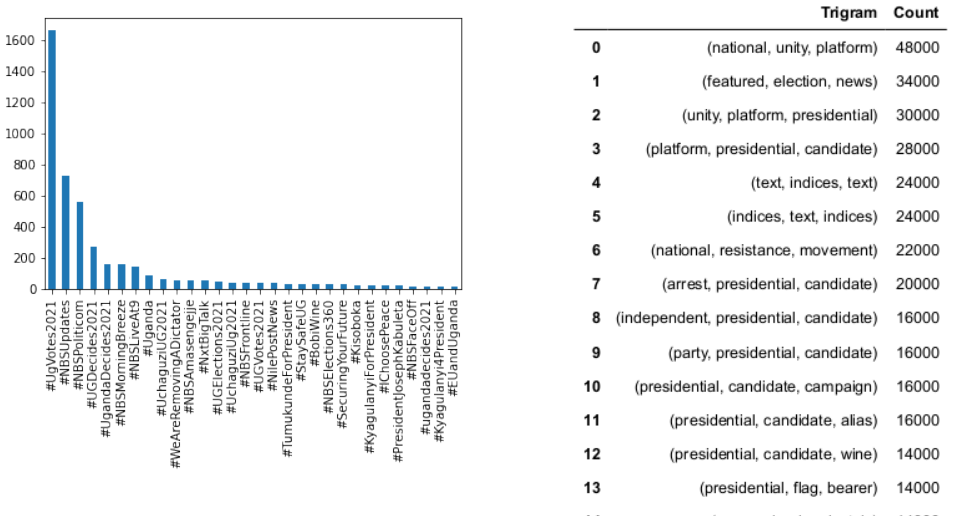
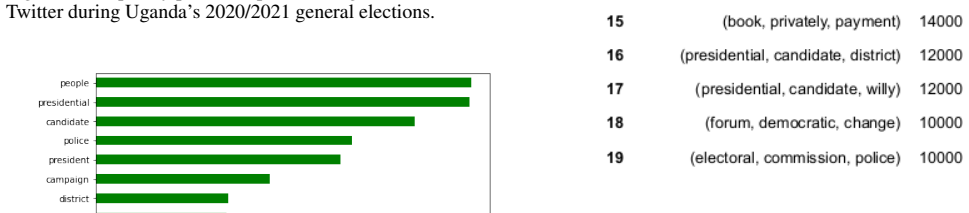
The top three hashtags in this dataset include #UgV otes2021, #NBSUpdates, and #NBSPoliticom. However, at least three hashtags associated with matters of public interest also trended in our dataset, for example #WearAMask, #StaySafeUG, and #COVID19. Figure 5 shows the bar plot for top 20 frequently used terms/words in our Twitter dataset. The results show...
2020
-
[12]
DISCUSSION The goal of this work was to apply machine learning methods to the task of identifying issues from social media conversa- tions for inclusion in public policy agenda. To achieve this goal, we proposed a 5-stage human-augmented ML pipeline that takes as input social media data that undergoes pre- processing before topic modeling is applied to ex...
-
[13]
CONCLUSION In this work we propose a ML-based human-augmented ap- proach for generating public policy agenda from social media conversations. The approach consists of 5 stages namely, input data cleaning and pre-processing, keyword extraction and is- sue identification, text generation, text validation, and agenda validation. Empirical results from our wo...
-
[14]
Taufiq Ahmad, Aima Alvi, and Muhammad Ittefaq
-
[15]
The Use of Social Media on Political Participation Among University Students: An Analysis of Survey Results From Rural Pakistan.SAGE Open9, 3 (2019), 2158244019864484.DOI: http://dx.doi.org/10.1177/2158244019864484
-
[16]
Douglas G. Altman. 2006.Practical Statistics for Medical Research. Chapman & Hall/CRC
2006
-
[17]
David Alvarez-Melis and Martin Saveski. 2016. Topic Modeling in Twitter: Aggregating Tweets by Conversations. (2016). Association for the Advancement of ArtificialIntelligence
2016
-
[18]
Dimo Angelov. 2020. Top2Vec: Distributed Representations of Topics. (2020)
2020
-
[19]
Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. InProceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. Association for Computational Linguistics, Ann Arbor, Michigan, 65–72. https://www.aclweb.org/a...
2005
-
[20]
Anya Belz and Ehud Reiter. 2006. Comparing Automatic and Human Evaluation of NLG Systems
2006
-
[21]
Blei, Andrew Y
David M. Blei, Andrew Y . Ng, and Michael I. Jordan
-
[22]
https://jmlr.org/papers/volume3/blei03a/blei03a.pdf
Latent Dirichlet Allocation.Journal of machine Learning research3 (January 2003), 993–1022. https://jmlr.org/papers/volume3/blei03a/blei03a.pdf
2003
-
[23]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
2020
-
[24]
Joanna Burzy ´nska, Anna Bartosiewicz, and Magdalena R˛ ekas. 2020. The social life of COVID-19: Early insights from social media monitoring data collected in Poland.Health Informatics Journal26, 4 (2020), 3056–3065.DOI: http://dx.doi.org/10.1177/1460458220962652PMID: 33050772
-
[25]
Andrea Ceron, Luigi Curini, and Stefano M. Iacus. 2019. ISIS at Its Apogee: The Arabic Discourse on Twitter and What We Can Learn From That About ISIS Support and Foreign Fighters.SAGE Open9, 1 (2019), 2158244018789229.DOI: http://dx.doi.org/10.1177/2158244018789229
-
[26]
Matteo Cinelli, Walter Quattrociocchi, Alessandro Galeazzi, Carlo Michele Valensise, Emanuele Brugnoli, Ana Lucia Schmidt, Paola Zola, Fabiana Zollo, and Antonio Scala. 2020. The COVID-19 social media infodemic.Nature Scientific Reports10, 16598 (2020) (April 2020).DOI: http://dx.doi.org/10.1038/s41598-020-73510-5
-
[27]
Roger Cobb, Jennie-Keith Ross, and Marc Howard Ross
- [28]
-
[29]
Dearing and Everett Rogers
James W. Dearing and Everett Rogers. 1997. Agenda-Setting. V ol. 6. SAGE Publications, Inc
1997
-
[30]
Lei Deng, Bingying Xu, Lumin Zhang, Yi Han, Bin Zhou, and Peng Zou. 2013. Tracking the Evolution of Public Concerns in Social Media. InProceedings of the Fifth International Conference on Internet Multimedia Computing and Service (ICIMCS ’13). Association for Computing Machinery, New York, NY , USA, 353–357. DOI:http://dx.doi.org/10.1145/2499788.2499826
-
[31]
Anjie Fang, Philip Habel, Iadh Ounis, and Craig MacDonald. 2019. V otes on Twitter: Assessing Candidate Preferences and Topics of Discussion During the 2016 U.S. Presidential Election.SAGE Open9, 1 (2019), 2158244018791653.DOI: http://dx.doi.org/10.1177/2158244018791653
-
[32]
Fabio Gasparetti. 2017. Modeling User Interests from Web Browsing Activities.Data Min. Knowl. Discov.31, 2 (March 2017), 502–547.DOI: http://dx.doi.org/10.1007/s10618-016-0482-x
-
[33]
Albert Gatt and Emiel Krahmer. 2018. Survey of the State of the Art in Natural Language Generation: Core Tasks, Applications and Evaluation.J. Artif. Int. Res.61, 1 (Jan. 2018), 65–170
2018
-
[34]
Sarah Giest and Annemarie Samuels. 2020. ’For good measure’: data gaps in a big data world.Policy Sciences 53, 2020 (April 2020), 559–569.DOI: http://dx.doi.org/10.1007/s11077-020-09384-1
-
[35]
Jeremy Ginsberg, Matthew H. Mohebbi, Rajan S. Patel, Lynnette Brammer, Mark S. Smolinski, and Larry Brilliant. 2009. Detecting influenza epidemics using search engine query data.Nature457 (Feb. 2009).DOI: http://dx.doi.org/10.1038/nature07634
-
[36]
Daniel Hunt. 2020. How food companies use social media to influence policy debates: a framework of Australian ultra-processed food industry Twitter data. Public Health Nutrition(2020), 1–12.DOI: http://dx.doi.org/10.1017/S1368980020003353
-
[37]
Karoliina Isoaho, Daria Gritsenko, and Eetu Mäkelä
-
[38]
Topic Modeling and Text Analysis for Qualitative Policy Research.Policy Studies Journal49, 1 (2021), 300–324.DOI: http://dx.doi.org/https://doi.org/10.1111/psj.12343
-
[39]
Zhiwei Jin, Juan Cao, Han Guo, Yongdong Zhang, Yu Wang, and Jiebo Luo. 2017. Detection and Analysis of 2016 US Presidential Election Related Rumors on Twitter. InInternational Conference on Social Computing, Behavioral-Cultural Modeling and Prediction and Behavior Representation in Modeling and Simulation, V ol. 10354. Springer, Cham, 14–24. DOI:http://dx...
-
[40]
Kayla N. Jordan, James W. Pennebaker, and Chase Ehrig. 2018. The 2016 U.S. Presidential Candidates and How People Tweeted About Them.SAGE Open8, 3 (2018), 2158244018791218.DOI: http://dx.doi.org/10.1177/2158244018791218
-
[41]
Fatemeh Kaveh-Yazdy and Sajjad Zarifzadeh. 2021. Track Iran’s national COVID-19 response committee’s major concerns using two-stage unsupervised topic modeling.International Journal of Medical Informatics 145 (2021), 104309.DOI:http://dx.doi.org/https: //doi.org/10.1016/j.ijmedinf.2020.104309
-
[42]
Simon Kemp. 2020. Digital 2020: Uganda. Website. (February 2020). https://datareportal.com/reports/digital-2020-uganda
2020
-
[43]
Masha Krupenkin, David Rothschild, Shawndra Hill, and Elad Yom-Tov. 2019. President Trump Stress Disorder: Partisanship, Ethnicity, and Expressive Reporting of Mental Distress After the 2016 Election. SAGE Open9, 1 (2019), 2158244019830865.DOI: http://dx.doi.org/10.1177/2158244019830865
-
[44]
Wojciech Kry ´sci´nski, Nitish Shirish Keskar, Bryan McCann, Caiming Xiong, and Richard Socher. 2019. Neural Text Summarization: A Critical Evaluation. (2019)
2019
-
[45]
Richard J. Landis and Gary G. Koch. 1977. The measurement of observer agreement for categorical data. Biometrics33, 1 (March 1977), 159–174.DOI: http://dx.doi.org/10.2307/2529310
-
[46]
Alon Lavie and Abhaya Agarwal. 2007. Meteor: An Automatic Metric for MT Evaluation with High Levels of Correlation with Human Judgments. InProceedings of the Second Workshop on Statistical Machine Translation (StatMT ’07). Association for Computational Linguistics, USA, 228–231
2007
-
[47]
Le and Tomas Mikolov
Quoc V . Le and Tomas Mikolov. 2014. Distributed Representations of Sentences and Documents. (2014)
2014
-
[48]
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2019. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension.CoRRabs/1910.13461 (2019). http://arxiv.org/abs/1910.13461
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[49]
Chia-Wei Liu, Ryan Lowe, Iulian Serban, Mike Noseworthy, Laurent Charlin, and Joelle Pineau. 2016. How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguist...
-
[50]
Edward Loper and Steven Bird. 2002. NLTK: The Natural Language Toolkit. InProceedings of the ACL-02 Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics - Volume 1 (ETMTNLP ’02). Association for Computational Linguistics, USA, 63–70. DOI:http://dx.doi.org/10.3115/1118108.1118117
-
[51]
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient Estimation of Word Representations in Vector Space. (2013)
2013
-
[52]
Ehsan Montahaei, Danial Alihosseini, and Mahdieh Soleymani Baghshah. 2019. Jointly Measuring Diversity and Quality in Text Generation Models.CoRR abs/1904.03971 (2019). http://arxiv.org/abs/1904.03971
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[53]
Zeynab Mottaghinia, Mohammad-Reza Feizi-Derakhshi, Leili Farzinvash, and Pedram Salehpour. 2020. A review of approaches for topic detection in Twitter.Journal of Experimental & Theoretical Artificial Intelligence0, 0 (2020), 1–27.DOI: http://dx.doi.org/10.1080/0952813X.2020.1785019
-
[54]
Jekaterina Novikova, Ond ˇrej Dušek, Amanda Cercas Curry, and Verena Rieser. 2017. Why We Need New Evaluation Metrics for NLG. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Copenhagen, Denmark, 2241–2252.DOI: http://dx.doi.org/10.18653/v1/D17-1238
-
[55]
Jekaterina Novikova, Ond ˇrej Dušek, and Verena Rieser
-
[56]
DOI:http://dx.doi.org/10.18653/v1/n18-2012
RankME: Reliable Human Ratings for Natural Language Generation.Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers)(2018). DOI:http://dx.doi.org/10.18653/v1/n18-2012
-
[57]
Catherine Ordun, Sanjay Purushotham, and Edward Raff. 2020. Exploratory Analysis of Covid-19 Tweets using Topic Modeling, UMAP, and DiGraphs. (2020)
2020
-
[58]
Salvatore Pirri, Valentina Lorenzoni, Gianni Andreozzi, Marta Mosca, and Giuseppe Turchetti. 2020. Topic Modeling and User Network Analysis on Twitter during World Lupus Awareness Day.International Journal of Environmental Research and Public Health17, 15 (2020).DOI:http://dx.doi.org/10.3390/ijerph17155440
-
[59]
Uganda Governance Monitoring Platform. 2015. Power belongs to the people: The citizens manifesto, 2016-2021. Report. (2015). https://www.kituochakatiba.org/sites/default/files/ publications/Citizen-Manifesto-2016-2021LR.pdf
2015
-
[60]
Juho Pääkkönen and Petri Ylikoski. 2020. Humanistic interpretation and machine learning.Sythese2020 (September 2020).DOI: http://dx.doi.org/10.1007/s11229-020-02806-w
-
[61]
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2018. Language Models are Unsupervised Multitask Learners. (2018). https://d4mucfpksywv.cloudfront.net/ better-language-models/language-models.pdf
2018
-
[62]
Michael Röder, Andreas Both, and Alexander Hinneburg. 2015. Exploring the Space of Topic Coherence Measures. InProceedings of the Eighth ACM International Conference on Web Search and Data Mining (WSDM ’15). Association for Computing Machinery, New York, NY , USA, 399–408.DOI: http://dx.doi.org/10.1145/2684822.2685324
-
[63]
Sai, Akash Kumar Mohankumar, and Mitesh M
Ananya B. Sai, Akash Kumar Mohankumar, and Mitesh M. Khapra. 2020. A Survey of Evaluation Metrics Used for NLG Systems. (2020)
2020
-
[64]
Sashank Santhanam and Samira Shaikh. 2019. Towards Best Experiment Design for Evaluating Dialogue System Output. (2019)
2019
-
[65]
Zhan Shi, Xinchi Chen, Xipeng Qiu, and Xuanjing Huang. 2018. Toward Diverse Text Generation with Inverse Reinforcement Learning. (2018)
2018
-
[66]
Sarah Shugars and Nicholas Beauchamp. 2019. Why Keep Arguing? Predicting Engagement in Political Conversations Online.SAGE Open9, 1 (2019), 2158244019828850.DOI: http://dx.doi.org/10.1177/2158244019828850
-
[67]
Carson Sievert and Kenneth Shirley. 2014. LDAvis: A method for visualizing and interpreting topics. In Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces. Association for Computational Linguistics, Baltimore, Maryland, USA, 63–70.DOI:http://dx.doi.org/10.3115/v1/W14-3110
-
[68]
StatCounter. 2021. Social Media Stats in Uganda - January 2021. Report. (2021).https: //gs.statcounter.com/social-media-stats/all/uganda
2021
-
[69]
Laerd Statistics. 2019. Fleiss’ kappa using SPSS Statistics. Statistical tutorials and software guides.. (2019).https://statistics.laerd.com/spss-tutorials/ fleiss-kappa-in-spss-statistics.php
2019
-
[70]
Asbjørn Steinskog, Jonas Therkelsen, and Björn Gambäck. 2017. Twitter Topic Modeling by Tweet Aggregation. InProceedings of the 21st Nordic Conference on Computational Linguistics. Association for Computational Linguistics, Gothenburg, Sweden, 77–86.https://www.aclweb.org/anthology/W17-0210
2017
-
[71]
Jost, and Curtis D
Joanna Sterling, John T. Jost, and Curtis D. Hardin
-
[72]
DOI:http://dx.doi.org/10.1177/2158244019846211
Liberal and Conservative Representations of the Good Society: A (Social) Structural Topic Modeling Approach.SAGE Open9, 2 (2019), 2158244019846211. DOI:http://dx.doi.org/10.1177/2158244019846211
-
[73]
Denis Stukal, Sergey Sanovich, Joshua A. Tucker, and Richard Bonneau. 2019. For Whom the Bot Tolls: A Neural Networks Approach to Measuring Political Orientation of Twitter Bots in Russia.SAGE Open9, 2 (2019), 2158244019827715.DOI: http://dx.doi.org/10.1177/2158244019827715
-
[74]
Xing, and Zhiting Hu
Bowen Tan, Zichao Yang, Maruan AI-Shedivat, Eric P. Xing, and Zhiting Hu. 2020. Progressive Generation of Long Text. (2020)
2020
-
[75]
Shu-Feng Tsao, Helen Chen, Therese Tisseverasinghe, Yang Yang, Lianghua Li, and Zahid A Butt. 2021. What social media told us in the time of COVID-19: a scoping review.The Lancet Digital Health(2021).DOI: http://dx.doi.org/10.1016/S2589-7500(20)30315-0
-
[76]
2016.The National Population and Housing Census 2014 - Main Report, Kampala, Uganda
UBoS. 2016.The National Population and Housing Census 2014 - Main Report, Kampala, Uganda. Technical Report. Uganda Bureau of Statistics
2016
-
[77]
Cristian Vaccari and Augusto Valeriani. 2018. Digital Political Talk and Political Participation: Comparing Established and Third Wave Democracies.SAGE Open 8, 2 (2018), 2158244018784986.DOI: http://dx.doi.org/10.1177/2158244018784986
-
[78]
Vladimir Vargas-Calderón and Jorge Camargo. 2019. Characterization of citizens using word2vec and latent topic analysis in a large set of tweets.CoRR abs/1904.08926 (2019). http://arxiv.org/abs/1904.08926
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[79]
Lloyd George Waller. 2013. Enhancing Political Participation in Jamaica: The Use of Facebook to “Cure” the Problem of Political Talk Among the Jamaican Youth.SAGE Open3, 2 (2013), 2158244013486656. DOI:http://dx.doi.org/10.1177/2158244013486656
-
[80]
Hao Wang, Dogan Can, Abe Kazemzadeh, François Bar, and Shrikanth Narayanan. 2012. A System for Real-time Twitter Sentiment Analysis of 2012 U.S. Presidential Election Cycle. InProceedings of the ACL 2012 System Demonstrations. Association for Computational Linguistics, Jeju Island, Korea, 115–120. https://www.aclweb.org/anthology/P12-3020
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.