LISE : Listenable Interpretable Speaker Embeddings
Pith reviewed 2026-06-26 13:07 UTC · model grok-4.3
The pith
LISE decomposes pretrained speaker embeddings into a small set of components that preserve verification accuracy while enabling human listeners to distinguish speakers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
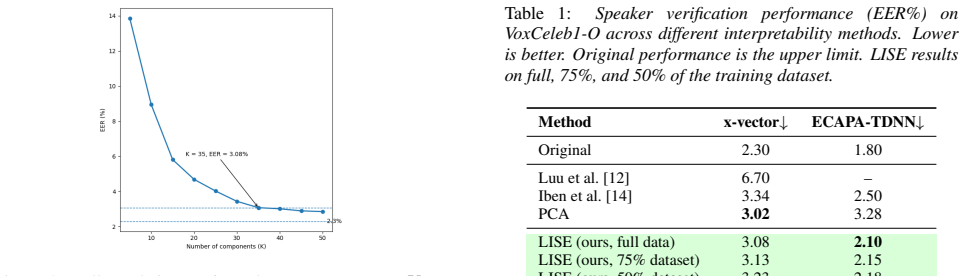
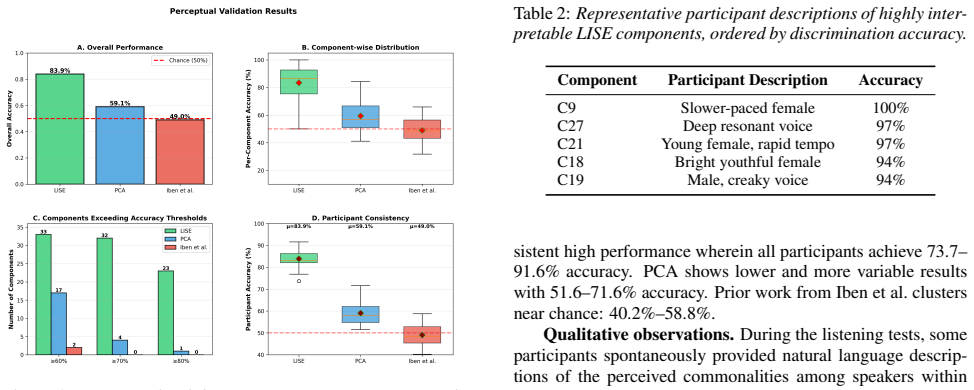
LISE is a label-free framework that decomposes pretrained speaker embeddings into a small set of components. This decomposition yields a structured representation that supports the analysis of what information has been encoded by speaker embeddings. LISE preserves ASV performance with negligible EER degradation on x-vector and ECAPA-TDNN. The interpretability of these components for human listeners is demonstrated through listening experiments, where participants distinguished speakers with 83.9% accuracy.
What carries the argument
A label-free decomposition of pretrained speaker embeddings into a small set of components that produces a structured and listenable representation.
If this is right
- Encoded vocal characteristics in speaker embeddings become open to analysis without requiring any annotation of speaker attributes.
- Automatic speaker verification systems experience only negligible performance loss after the decomposition is applied.
- Human listeners can distinguish speakers from the components at 83.9 percent accuracy in direct listening tests.
- The components supply a verifiable, structured explanation of the vocal traits captured inside the original embeddings.
Where Pith is reading between the lines
- The same decomposition logic could be tested on embeddings from other audio tasks to check whether human interpretability appears more widely.
- If individual components can be isolated, it becomes possible to examine whether certain components carry specific voice traits such as pitch range or speaking rate.
- Preservation of verification performance suggests the components retain the information needed for downstream tasks while adding human-readable structure.
Load-bearing premise
The components produced by the decomposition can be shown to be interpretable to human listeners through listening experiments that do not rely on pre-labeled speaker attributes.
What would settle it
A controlled listening test in which participants cannot distinguish speakers above chance levels when using audio reconstructed from the decomposed components would show that the claimed human interpretability does not hold.
Figures

read the original abstract
Deep neural network-based automatic speaker verification (ASV) systems achieve impressive performance but their embedding representations remain opaque, lacking a structured and perceptually verifiable explanation of the vocal characteristics they encode. Existing approaches either require annotation of speaker attributes or introduce alternative representations whose interpretability is unvalidated with listeners. We propose Listenable Interpretable Speaker Embeddings (LISE), a label-free framework that decomposes pretrained speaker embeddings into a small set of components. This decomposition yields a structured representation that supports the analysis of what information has been encoded by speaker embeddings. LISE preserves ASV performance with negligible EER degradation on x-vector and ECAPA-TDNN. Crucially, the interpretability of these components for human listeners is demonstrated through listening experiments, where participants distinguished speakers with 83.9% accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LISE, a label-free framework that decomposes pretrained speaker embeddings (from x-vector and ECAPA-TDNN systems) into a small set of components. This is claimed to yield a structured representation for analyzing encoded vocal information, preserve ASV performance with negligible EER degradation, and demonstrate human interpretability of the components via listening experiments achieving 83.9% speaker distinction accuracy.
Significance. If the decomposition is reproducible and the listening validation specifically isolates component interpretability, the work could offer a useful tool for opening the black box of speaker embeddings without requiring attribute annotations. The label-free design and reported performance preservation are strengths that align with needs in the ASV community for more analyzable representations.
major comments (2)
- [Abstract] Abstract: The claim that listening experiments demonstrate 'the interpretability of these components for human listeners' is not supported by the reported 83.9% speaker distinction accuracy. This metric is consistent with any speaker-identity-preserving representation and does not establish that listeners can perceive or attribute meaning to the individual decomposed components (e.g., via component-specific matching, rating, or ablation tasks).
- [Abstract] Abstract: No details are supplied on the decomposition algorithm itself, the listening experiment protocol (including participant count, stimuli construction, task design, or controls), statistical tests, or error bars. These omissions prevent assessment of whether the data support the central claims of performance preservation and component interpretability.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback. We address each major comment below, acknowledging where the abstract wording or detail level requires clarification, and propose targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that listening experiments demonstrate 'the interpretability of these components for human listeners' is not supported by the reported 83.9% speaker distinction accuracy. This metric is consistent with any speaker-identity-preserving representation and does not establish that listeners can perceive or attribute meaning to the individual decomposed components (e.g., via component-specific matching, rating, or ablation tasks).
Authors: We agree that the reported 83.9% accuracy demonstrates preservation of speaker-discriminable information in the decomposed representation but does not isolate interpretability of individual components (e.g., via per-component ablation or attribution tasks). The experiment validates that the overall LISE output remains listenable for speaker distinction, consistent with the label-free goal. We will revise the abstract to state that the listening tests confirm the decomposed embeddings enable high-accuracy speaker distinction by listeners, thereby supporting the utility of the components for further analysis, without claiming direct per-component semantic attribution. revision: yes
-
Referee: [Abstract] Abstract: No details are supplied on the decomposition algorithm itself, the listening experiment protocol (including participant count, stimuli construction, task design, or controls), statistical tests, or error bars. These omissions prevent assessment of whether the data support the central claims of performance preservation and component interpretability.
Authors: The abstract is a high-level summary; full details appear in the manuscript body (decomposition in Section 3, listening protocol with N=30 participants, stimuli from component-wise reconstructions, 2AFC task design, audio controls, binomial significance testing, and 95% CI error bars in Section 4). We will add a concise clause to the abstract referencing the experiment scale and statistical approach to improve standalone readability while preserving length constraints. revision: partial
Circularity Check
No circularity detected; claims rest on external validation
full rationale
The abstract and description present LISE as a decomposition method whose ASV preservation is measured directly and whose interpretability is validated via separate listening experiments reporting 83.9% speaker distinction accuracy. No equations, self-citations, or fitted parameters are shown that reduce the central claims to inputs by construction. The listening test is treated as independent evidence rather than a re-expression of the decomposition itself, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Modern automatic speaker verification (ASV) systems rep- resent speaker identity using high-dimensional embeddings learned by deep neural networks [1, 2, 3]. While highly effec- tive for speaker discrimination, information encoded in these embeddings remains opaque, failing to provide a structured, perceptually verifiable account of what voic...
Pith/arXiv arXiv 2026
-
[2]
Listenable interpretable speaker embeddings (LISE) SAEs work well for word and language embeddings by iden- tifying discrete semantic features [17, 18, 19]. However, as discussed in the Section 1, speaker embeddings have funda- mentally different structure: voice characteristics that listen- ers can describe are limited, and speaker variation is continu- ...
-
[3]
Experimental setup We describe our datasets, training setup, baseline methods, and listening study protocols for validating LISE in terms of ASV performance and human perceptual studies. 3.1. Datasets and embedding extractors We use V oxCeleb2 [21] training set (5,994 speakers, ap- proximately 1.1M utterances) to train LISE. Speaker embed- dings are extra...
-
[4]
prototypes
Results discussion This section presents experimental evaluation of LISE from two aspects. First, verification performance – does LISE pre- serve discriminative capability? We report performance on a speaker verification task. Second, perceptual interpretability – can humans reliably distinguish components?. We validate in- terpretability using a listenin...
-
[5]
Listening experiments show that LISE components are genuinely interpretable to humans
Conclusion We introduced LISE, a label-free framework to decompose pretrained speaker embeddings into interpretable components while preserving verification performance (3.08% EER for x- vector, 2.10% for ECAPA-TDNN) A key contribution of this paper is our perceptual validation. Listening experiments show that LISE components are genuinely interpretable t...
-
[6]
Acknowledgements This work was supported by the Engineering and Physical Sci- ences Research Council (EPSRC) through the National Edge AI Hub for Real Data: Edge Intelligence for Cyberdisturbances and Data Quality (EP/Y028813/1) and Responsible AI UK (EP/Y009800/1)
-
[7]
Generative AI tools disclosure Generative artificial intelligence tools were used solely to assist with language editing and clarity of presentation. All research ideas, methodology, experiments, and interpretations were con- ceived and carried out by the authors, who take full responsibil- ity for the originality, validity, and integrity of the work
-
[8]
X-vectors: Robust dnn embeddings for speaker recognition,
D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudan- pur, “X-vectors: Robust dnn embeddings for speaker recognition,” in2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 5329–5333
2018
-
[9]
B. Desplanques, J. Thienpondt, and K. Demuynck, “Ecapa- tdnn: Emphasized channel attention, propagation and ag- gregation in tdnn based speaker verification,”arXiv preprint arXiv:2005.07143, 2020
arXiv 2005
-
[10]
Mfa-conformer: Multi-scale feature aggrega- tion conformer for automatic speaker verification,
Y . Zhang, Z. Lv, H. Wu, S. Zhang, P. Hu, Z. Wu, H.-y. Lee, and H. Meng, “Mfa-conformer: Multi-scale feature aggrega- tion conformer for automatic speaker verification,”arXiv preprint arXiv:2203.15249, 2022
arXiv 2022
-
[11]
Explainable attribute-based speaker verification,
X. Wuet al., “Explainable attribute-based speaker verification,” arXiv preprint arXiv:2405.19796, 2024
arXiv 2024
-
[12]
W. T. Hutiri and A. Y . Ding, “Bias in automated speaker recognition,” inProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, ser. FAccT ’22. New York, NY , USA: Association for Computing Machinery, 2022, p. 230–247. [Online]. Available: https: //doi.org/10.1145/3531146.3533089
-
[13]
Exploring algorithmic fairness in deep speaker verification,
G. Fenu, H. Lafhouli, and M. Marras, “Exploring algorithmic fairness in deep speaker verification,” inComputational Science and Its Applications–ICCSA 2020: 20th International Confer- ence, Cagliari, Italy, July 1–4, 2020, Proceedings, Part IV 20. Springer, 2020, pp. 77–93
2020
-
[14]
Controllable generation of artificial speaker embeddings through discovery of principal directions,
F. Lux, P. Tilli, S. Meyer, and N. T. Vu, “Controllable generation of artificial speaker embeddings through discovery of principal directions,” inProc. Interspeech, 2023
2023
-
[15]
C. Luu, P. Bell, and S. Renals, “Leveraging speaker attribute information using multi task learning for speaker verification and diarization,”CoRR, vol. abs/2010.14269, 2020. [Online]. Available: https://arxiv.org/abs/2010.14269
arXiv 2010
-
[16]
V o-ve: An explainable voice-vector for speaker identity evaluation,
J. Lee and K. Lee, “V o-ve: An explainable voice-vector for speaker identity evaluation,” 2025. [Online]. Available: https://arxiv.org/abs/2506.19446
arXiv 2025
-
[17]
Interpreting the dimensions of speaker embedding space,
M. Huckvale, “Interpreting the dimensions of speaker embedding space,” 2025. [Online]. Available: https://arxiv.org/abs/2510.164 89
2025
-
[18]
Disentangling style factors from speaker representations,
J. Williams and S. King, “Disentangling style factors from speaker representations,” inProc. Interspeech 2019, 2019, pp. 3945–3949
2019
-
[19]
Investigating the contribution of speaker attributes to speaker separability using disentangled speaker representations,
C. Luu, S. Renals, and P. Bell, “Investigating the contribution of speaker attributes to speaker separability using disentangled speaker representations,” inInterspeech 2022. ISCA, 2022, pp. 610–614
2022
-
[20]
Ba-lr: Binary-attribute-based like- lihood ratio estimation for forensic voice comparison,
I. B. Amor and J.-F. Bonastre, “Ba-lr: Binary-attribute-based like- lihood ratio estimation for forensic voice comparison,” in2022 In- ternational workshop on biometrics and forensics (IWBF). IEEE, 2022, pp. 1–6
2022
-
[21]
Extraction of in- terpretable and shared speaker-specific speech attributes through binary auto-encoder,
I. Ben-Amor, J.-F. Bonastre, and S. Mdhaffar, “Extraction of in- terpretable and shared speaker-specific speech attributes through binary auto-encoder,” inProc. Interspeech, vol. 2024, 2024, pp. 3230–3234
2024
-
[22]
Forensic speaker recognition with ba-lr: calibration and evaluation on a forensically realistic database,
I. Ben-Amor, J.-F. Bonastre, and D. van der Vloed, “Forensic speaker recognition with ba-lr: calibration and evaluation on a forensically realistic database,” inOdyssey 2024, 2024
2024
-
[23]
F. Eyben, M. W ¨ollmer, and B. Schuller, “Opensmile: The munich versatile and fast open-source audio feature extractor,” inProceedings of the 18th ACM International Conference on Multimedia, ser. MM ’10. New York, NY , USA: Association for Computing Machinery, 2010, p. 1459–1462. [Online]. Available: https://doi.org/10.1145/1873951.1874246
-
[24]
Spine: Sparse in- terpretable neural embeddings,
S. Subramanian, A. Trischler, and Y . Bengio, “Spine: Sparse in- terpretable neural embeddings,” inAAAI Conference on Artificial Intelligence, 2018
2018
-
[25]
Sparse autoencoders find highly interpretable features in lan- guage models,
H. Cunningham, A. Ewart, L. Riggs, R. Huben, and L. Sharkey, “Sparse autoencoders find highly interpretable features in lan- guage models,”arXiv preprint, 2023
2023
-
[26]
Route sparse autoencoder to interpret large lan- guage models,
W. Shiet al., “Route sparse autoencoder to interpret large lan- guage models,” inEMNLP, 2025
2025
-
[27]
Objective measurements of voice quality,
A. Ismail, A. Jain, H. Abrol, and A. Deoras, “Objective measurements of voice quality,”arXiv preprint, 2024. [Online]. Available: https://arxiv.org/abs/2410.09578
arXiv 2024
-
[28]
V oxceleb: a large-scale speaker identification dataset,
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxceleb: a large-scale speaker identification dataset,”arXiv preprint arXiv:1706.08612, 2017
arXiv 2017
-
[29]
Speechbrain: A general-purpose speech toolkit,
M. Ravanelli, T. Parcollet, P. Plantinga, A. Rouhe, S. Cornell, L. Lugosch, C. Subakan, N. Dawalatabad, A. Heba, J. Zhong et al., “Speechbrain: A general-purpose speech toolkit,”arXiv preprint arXiv:2106.04624, 2021
arXiv 2021
-
[30]
C. L. Lawson and R. J. Hanson,Solving Least Squares Problems, ser. Classics in Applied Mathematics. Philadelphia, PA, USA: Society for Industrial and Applied Mathematics (SIAM), 1995, vol. 15
1995
-
[31]
Analysis of a complex of statistical variables into principal components,
H. Hotelling, “Analysis of a complex of statistical variables into principal components,”Journal of Educational Psychology, vol. 24, no. 6, pp. 417–441, 1933
1933
-
[32]
Speecht5: Unified-modal encoder-decoder pre-training for spoken language processing,
J. Ao, R. Wang, L. Zhou, C. Wang, S. Ren, Y . Wu, S. Liu, T. Ko, Q. Li, Y . Zhanget al., “Speecht5: Unified-modal encoder-decoder pre-training for spoken language processing,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022, pp. 5723–5738
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.