SE-AGCNet: An End-to-End Framework for Joint Speech Enhancement and Loudness Control in Meeting Scenarios
Pith reviewed 2026-06-25 19:08 UTC · model grok-4.3
The pith
SE-AGCNet jointly optimizes speech enhancement and automatic gain control to reach target loudness while preserving quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SE-AGCNet is presented as an end-to-end framework that jointly optimizes speech enhancement and loudness control. The design exploits the fact that enhancement can preserve quiet speech, allowing the AGC component to perform effective volume adjustment without boosting noise. A dedicated simulation pipeline generates training data with realistic volume variations, and performance is measured with integrated loudness, short-term loudness, and loudness range metrics. Experiments demonstrate consistent achievement of target loudness together with gains in speech quality and ASR accuracy.
What carries the argument
SE-AGCNet, the end-to-end neural architecture that performs joint speech enhancement and automatic gain control.
Load-bearing premise
Training examples generated by SE-AGC-DataGen have volume statistics and noise properties sufficiently similar to real meeting recordings for the model to generalize.
What would settle it
Evaluating the trained SE-AGCNet on a collection of real, un-simulated meeting recordings and comparing loudness accuracy and quality metrics against the simulated test conditions.
Figures
read the original abstract
Conventional audio pipelines typically treat speech enhancement (SE) and automatic gain control (AGC) as discrete modules, which often limits overall performance. For instance, applying AGC before SE may inadvertently amplify background noise, while prioritizing SE tends to over-suppress low-volume speech. To address these limitations, we propose SE-AGCNet, an end-to-end framework that jointly optimizes SE and AGC. Tailored for meeting scenarios with significant volume variations, SE-AGCNet leverages the synergy between the two tasks: SE preserves quiet speech, thereby facilitating effective volume adjustment by the AGC component. Furthermore, we propose a specialized data simulation pipeline, SE-AGC-DataGen, and incorporate standardized loudness evaluation metrics: integrated loudness (LUFS), short-term loudness (St LUFS), and LRA. Experiments show that SE-AGCNet consistently achieves target loudness while improving speech quality and ASR accuracy over competitive baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SE-AGCNet, an end-to-end neural framework that jointly performs speech enhancement and automatic gain control (AGC) for meeting audio with large volume variations. It introduces the SE-AGC-DataGen simulation pipeline to generate training data and adopts standardized loudness metrics (integrated LUFS, short-term LUFS, LRA). The central claim is that the joint model consistently reaches target loudness while improving perceptual speech quality and ASR accuracy relative to competitive baselines.
Significance. Joint optimization of SE and AGC addresses a practical limitation in conventional pipelines for variable-volume meeting scenarios. If the reported gains are shown to be statistically robust, to generalize beyond simulation, and to be supported by proper ablations and real-data validation, the work could inform the design of audio front-ends in conferencing and transcription systems. The adoption of LUFS-based metrics is a constructive choice for the loudness-control objective.
major comments (2)
- [Abstract] Abstract: the claim that SE-AGCNet 'consistently achieves target loudness while improving speech quality and ASR accuracy over competitive baselines' is asserted without any numerical results, baseline definitions, statistical significance tests, or ablation studies. The central claim therefore cannot be evaluated from the supplied text.
- [Methods / Data simulation] SE-AGC-DataGen pipeline (described in the methods): the headline performance claims rest on the assumption that volume trajectories, LUFS distributions, and noise profiles in the simulated data are statistically close to real meeting recordings. No Kolmogorov-Smirnov tests, SNR histograms, or real-meeting hold-out evaluation are reported, leaving the simulation-to-real transfer unverified and load-bearing for all reported gains.
minor comments (2)
- [Model architecture] Clarify whether the joint training objective explicitly balances the SE and AGC losses or relies on a single combined loss; the current description leaves the optimization details ambiguous.
- [Evaluation metrics] Ensure that all loudness metrics (LUFS, St LUFS, LRA) are defined with their exact integration windows and reference levels on first use.
Simulated Author's Rebuttal
Thank you for reviewing our manuscript. We address the two major comments regarding the abstract and the data simulation pipeline. We believe the experimental results in the full paper support the claims, but we will make revisions where appropriate to clarify and strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that SE-AGCNet 'consistently achieves target loudness while improving speech quality and ASR accuracy over competitive baselines' is asserted without any numerical results, baseline definitions, statistical significance tests, or ablation studies. The central claim therefore cannot be evaluated from the supplied text.
Authors: The abstract is intended as a concise overview. The specific numerical results, baseline comparisons, statistical tests, and ablations are detailed in the Experiments section of the manuscript. We can revise the abstract to include example quantitative improvements to make the claim more concrete. revision: partial
-
Referee: [Methods / Data simulation] SE-AGC-DataGen pipeline (described in the methods): the headline performance claims rest on the assumption that volume trajectories, LUFS distributions, and noise profiles in the simulated data are statistically close to real meeting recordings. No Kolmogorov-Smirnov tests, SNR histograms, or real-meeting hold-out evaluation are reported, leaving the simulation-to-real transfer unverified and load-bearing for all reported gains.
Authors: We agree that demonstrating the fidelity of the simulated data to real meetings is important. The SE-AGC-DataGen pipeline incorporates volume trajectories and noise profiles derived from real meeting characteristics. In the revised manuscript, we will include additional analysis such as histograms of SNR and LUFS distributions. Real-meeting hold-out evaluation is not currently reported because the study focuses on the joint optimization framework under controlled conditions; we note this limitation. revision: partial
Circularity Check
No circularity: standard empirical ML pipeline with independent simulation and evaluation
full rationale
The paper proposes an end-to-end neural network (SE-AGCNet) trained on a custom simulation pipeline (SE-AGC-DataGen) and evaluated with standard metrics (LUFS, St LUFS, LRA) plus ASR accuracy. No equations, fitted parameters, or derivations are presented that reduce a claimed prediction or result to its own inputs by construction. No self-citation chains are invoked to justify uniqueness or ansatzes. The central claims rest on experimental comparisons against baselines, which are falsifiable on held-out data and do not rely on self-defined quantities. This is the normal non-circular case for an applied audio-processing paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction The audio front-end is traditionally characterized by the ”3A algorithms”: Acoustic Echo Cancellation (AEC), Noise Sup- pression (also referred to as speech enhancement), and Auto- matic Gain Control (AGC). Conventional audio pipelines typi- cally implement AGC [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12] and Speech Enhancement (SE) [13, 14, 15] a...
-
[2]
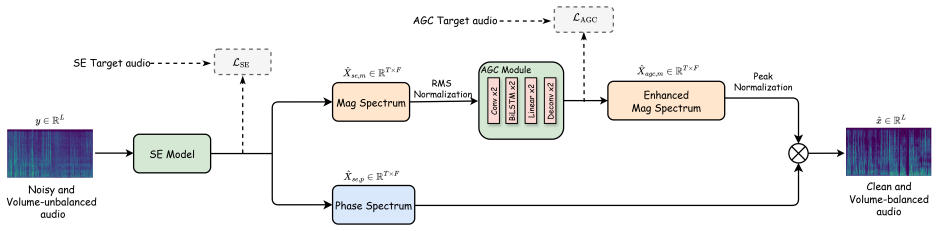
Proposed SE-AGCNet Figure 1 illustrates the SE-AGCNet architecture. Our approach employs a two-stage architecture that jointly optimizes speech enhancement and automatic gain control in the time-frequency domain, transforming a noisy and volume-unbalanced speech waveformy∈R L into a clean and volume-balanced output ˆx∈RL, whereLdenotes the waveform length...
Pith/arXiv arXiv 2026
-
[3]
We create one simulated dataset, LibriAGC, for training and evaluation
SE-AGC-DataGen Data Simulation Pipeline Since no publicly available dataset exists for AGC tasks, we de- velop a comprehensive data simulation pipeline that generates multi-speaker audio with realistic volume variations and acous- tic conditions. We create one simulated dataset, LibriAGC, for training and evaluation. LibriTTS [21] is used as our base data...
-
[4]
Experimental Setup and Results 4.1. Datasets We use the following datasets in our experiments:Voice- Bank+DEMAND[24], which is used in Section 4.2 as a clean- speech loudness reference (Table 1);LibriAGC, a simulated dataset described in Section 3; and two real-world datasets, MMCSG[25], a CHiME-8 challenge dataset with two-person conversation recordings ...
2020
-
[5]
Through end-to- end optimization, SE and AGC are trained to cooperate, al- lowing SE to preserve low-volume speech while AGC adjusts loudness
Conclusion This paper presents SE-AGCNet, a joint framework for speech enhancement (SE) and automatic gain control (AGC) that ad- dresses the limitations of cascaded pipelines. Through end-to- end optimization, SE and AGC are trained to cooperate, al- lowing SE to preserve low-volume speech while AGC adjusts loudness. We also introduce SE-AGC-DataGen for ...
-
[6]
They were not used to generate a substantial portion of the manuscript
Generative AI Use Disclosure Generative AI tools were used only for language editing and polishing. They were not used to generate a substantial portion of the manuscript. All AI-assisted edits were carefully reviewed and revised by the authors, who take full responsibility for the paper and approve its submission
-
[7]
Automatic speech recognition performance improvement for mandarin based on optimizing gain control strategy,
D. Wang, Y . Wei, K. Zhang, D. Ji, and Y . Wang, “Automatic speech recognition performance improvement for mandarin based on optimizing gain control strategy,”Sensors, vol. 22, no. 8, p. 3027, 2022
2022
-
[8]
Automatic gain control for enhanced hdr performance on audio,
D. E. Garcia, J. Hernandez, and S. Mann, “Automatic gain control for enhanced hdr performance on audio,” inProc. MMSP 2020, pp. 1–6
2020
-
[9]
Active volume control in smart phones based on user activ- ity and ambient noise,
V . Ambeth Kumar, S. Malathi, A. Kumar, P. M, and K. C. Velu- volu, “Active volume control in smart phones based on user activ- ity and ambient noise,”Sensors, vol. 20, no. 15, p. 4117, 2020
2020
-
[10]
Audio integrated active noise control system with auto gain controller,
K. Iwai and T. Nishiura, “Audio integrated active noise control system with auto gain controller,” inProc. APSIPA ASC 2019, pp. 1819–1823
2019
-
[11]
Multilayer adaptation based complex echo cancellation and voice enhancement,
J. Yang, “Multilayer adaptation based complex echo cancellation and voice enhancement,” inProc. ICASSP 2018, pp. 2131–2135
2018
-
[12]
Deep learn- ing based automatic volume control and limiter system,
J. Yang, P. Hilmes, B. Adair, and D. W. Krueger, “Deep learn- ing based automatic volume control and limiter system,” inProc. ICASSP 2017
2017
-
[13]
Automatic gain control with in- tegrated signal enhancement for specified target and background- noise levels,
A. Sugiyama and R. Miyahara, “Automatic gain control with in- tegrated signal enhancement for specified target and background- noise levels,” inProc. ICASSP 2017
2017
-
[14]
Adaptive gain control and time warp for enhanced speech intelligibility under reverberation,
P. N. Petkov and Y . Stylianou, “Adaptive gain control and time warp for enhanced speech intelligibility under reverberation,” in Proc. ICASSP 2017
2017
-
[15]
Speech enhancement based on auto gain control,
Y . Nagata, T. Fujioka, and M. Abe, “Speech enhancement based on auto gain control,”IEEE Transactions on Audio, Speech, and Language Processing, vol. 14, no. 1, pp. 177–190, 2005
2005
-
[16]
Software implementation of automatic gain con- troller for speech signal,
F. J. Archibald, “Software implementation of automatic gain con- troller for speech signal,”Texas Instruments SPRAAL1 White Pa- per, 2008
2008
-
[17]
Automatic gain control and multi-style training for ro- bust small-footprint keyword spotting with deep neural networks,
R. Prabhavalkar, R. Alvarez, C. Parada, P. Nakkiran, and T. N. Sainath, “Automatic gain control and multi-style training for ro- bust small-footprint keyword spotting with deep neural networks,” inProc. ICASSP 2015
2015
-
[18]
Webrtc technology overview and signaling solution design and implementation,
B. Sredojev, D. Samardzija, and D. Posarac, “Webrtc technology overview and signaling solution design and implementation,” in Proc. MIPRO 2015, 2015, pp. 1006–1009
2015
-
[19]
Explicit estimation of magni- tude and phase spectra in parallel for high-quality speech enhance- ment,
Y .-X. Lu, Y . Ai, and Z.-H. Ling, “Explicit estimation of magni- tude and phase spectra in parallel for high-quality speech enhance- ment,”Neural Networks, p. 107562, 2025
2025
-
[20]
Tridentse: Guid- ing speech enhancement with 32 global tokens,
D. Yin, Z. Zhao, C. Tang, Z. Xiong, and C. Luo, “Tridentse: Guid- ing speech enhancement with 32 global tokens,” inProc. Inter- speech 2023, pp. 3839–3843
2023
-
[21]
GenSE: Generative speech enhancement via language models using hierarchical modeling,
J. Yao, H. Liu, C. Chen, Y . Hu, E. Chng, and L. Xie, “GenSE: Generative speech enhancement via language models using hierarchical modeling,” inProc. ICLR 2025. [Online]. Available: https://openreview.net/forum?id=1p6xFLBU4J
2025
-
[22]
Nn3a: Neural network supported acoustic echo cancellation, noise suppression and au- tomatic gain control for real-time communications,
Z. Wang, Y . Na, B. Tian, and Q. Fu, “Nn3a: Neural network supported acoustic echo cancellation, noise suppression and au- tomatic gain control for real-time communications,” inProc. ICASSP 2022
2022
-
[23]
Neurale- cho: Hybrid of full-band and sub-band recurrent neural network for acoustic echo cancellation and speech enhancement,
M. Yu, Y . Xu, C. Zhang, S.-X. Zhang, and D. Yu, “Neurale- cho: Hybrid of full-band and sub-band recurrent neural network for acoustic echo cancellation and speech enhancement,” inProc. ASRU 2023
2023
-
[24]
Recommendation itu-r bs.1770: Algorithms to measure audio programme loudness and true-peak audio level,
International Telecommunication Union, Radiocommunication Sector, “Recommendation itu-r bs.1770: Algorithms to measure audio programme loudness and true-peak audio level,” Available: https://www.itu.int/rec/R-REC-BS.1770
-
[25]
Ebu r 128: Loudness normalisa- tion and permitted maximum level of audio signals,
European Broadcasting Union, “Ebu r 128: Loudness normalisa- tion and permitted maximum level of audio signals,” Available: https://tech.ebu.ch/publications/r128
-
[26]
V oicefilter-lite: Streaming targeted voice separation for on-device speech recog- nition,
Q. Wang, I. L. Moreno, M. Saglam, K. Wilson, A. Chiao, R. Liu, Y . He, W. Li, J. Pelecanos, M. Nikaet al., “V oicefilter-lite: Streaming targeted voice separation for on-device speech recog- nition,” inProc. Interspeech 2020, pp. 2677–2681
2020
-
[27]
Libritts: A corpus derived from librispeech for text- to-speech,
H. Zen, V . Dang, R. Clark, Y . Zhang, R. J. Weiss, Y . Jia, Z. Chen, and Y . Wu, “Libritts: A corpus derived from librispeech for text- to-speech,” inProc. Interspeech 2019
2019
-
[28]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inProc. ICML 2023, pp. 28 492–28 518
2023
-
[29]
Nemo: a toolkit for building ai applications using neural modules,
O. Kuchaiev, J. Li, H. Nguyen, O. Hrinchuk, R. Leary, B. Gins- burg, S. Kriman, S. Beliaev, V . Lavrukhin, J. Cooket al., “Nemo: a toolkit for building ai applications using neural modules,”arXiv preprint arXiv:1909.09577, 2019
arXiv 1909
-
[30]
Inves- tigating rnn-based speech enhancement methods for noise-robust text-to-speech,
C. V . Botinhao, X. Wang, S. Takaki, and J. Yamagishi, “Inves- tigating rnn-based speech enhancement methods for noise-robust text-to-speech,” inProc. ISCA SSW 2016, pp. 159–165
2016
-
[31]
The chime- 8 mmcsg challenge: Multi-modal conversations in smart glasses,
K. Zmolikova, S. Merello, K. Kalgaonkar, J. Lin, N. Moritz, P. Ma, M. Sun, H. Chen, A. Saliou, S. Petridiset al., “The chime- 8 mmcsg challenge: Multi-modal conversations in smart glasses,” inProc. CHiME-8 2024, pp. 7–12
2024
-
[32]
M2MeT: The ICASSP 2022 multi-channel multi-party meeting transcription challenge,
F. Yu, S. Zhang, Y . Fu, L. Xie, S. Zheng, Z. Du, W. Huang, P. Guo, Z. Yan, B. Ma, X. Xu, and H. Bu, “M2MeT: The ICASSP 2022 multi-channel multi-party meeting transcription challenge,” inProc. ICASSP 2022
2022
-
[33]
Icassp 2024 speech signal improvement challenge,
N.-C. Ristea, B. Naderi, A. Saabas, R. Cutler, S. Braun, and S. Branets, “Icassp 2024 speech signal improvement challenge,” IEEE Open Journal of Signal Processing, 2025
2024
-
[34]
Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise sup- pressors,
C. K. Reddy, V . Gopal, and R. Cutler, “Dnsmos: A non-intrusive perceptual objective speech quality metric to evaluate noise sup- pressors,” inProc. ICASSP 2021, pp. 6493–6497
2021
-
[35]
Time-frequency automatic gain control (agc),
D. Ellis, “Time-frequency automatic gain control (agc),” MATLAB Central File Exchange. Available: https://www.mathworks.com/matlabcentral/fileexchange/28472- time-frequency-automatic-gain-control-agc, 2026, retrieved March 3, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.